在嵌入式系统开发中,自定义通信协议是连接不同硬件模块、实现可靠数据交换的核心基础设施。一个设计良好的协议库,不仅能提升通信效率,更能增强系统的稳定性和可维护性。本文将深入探讨一种高度实用且具备良好扩展性的自定义协议设计思路,并提供完整的C语言实现与测试案例。
1. 简易自定义协议设计
1.1 协议设计原则
在进行具体设计前,我们需确立几个核心原则,以确保协议的健壮性和通用性:
- 字节序一致性:在跨平台或跨芯片架构的通信中,必须明确字节序。本实现采用小端序(Little-Endian)。
- 固定宽度类型:严格使用
uint8_t、uint16_t 等C99标准固定宽度整数类型,杜绝因编译器差异导致的数据长度问题。
- 静态内存分配:针对嵌入式环境资源受限的特点,避免使用动态内存(malloc/free),防止内存碎片和分配失败的风险。
- 流式解析支持:实际通信中(如串口),数据往往以字节流形式到达,协议库必须具备状态机来处理粘包和断包问题。
- 完善的错误处理:建立统一的错误码体系,便于在通信异常时快速定位问题根源。
1.2 ITLV字段定义
一种经典且简洁的协议设计思路是ITLV(ID-Type-Length-Value)格式。它将一帧数据划分为几个逻辑部分:
| 字段 |
含义 |
典型长度 |
说明 |
| I |
ID/Index |
1~2 字节 |
数据标识符,用于区分不同的业务指令或数据类型。 |
| T |
Type |
1 字节 |
数据类型(如uint8、int32、float、string等),告知接收方如何解释Value。 |
| L |
Length |
1~4 字节 |
Value字段的确切字节长度。 |
| V |
Value |
N 字节 |
实际的数据负载(Payload)。 |
其中,I、T、L属于固定长度的头部字段。在项目初期设计协议时,需要评估:业务数据的种类有多少(决定I的位宽)、单条数据的最大可能长度是多少(决定L的位宽)。预留适当的扩展空间能保证协议的长期通用性。通常,I设为1~2字节,T为1字节,L为1~4字节是较为常见的选择。
只用ITLV四个字段就足够了吗?
这完全取决于具体的应用场景:
- 场景一:物联网端云通信。在基于MQTT/TCP等上层协议的应用中,仅使用ITLV是可行的。因为TCP协议本身提供了可靠的传输、校验和重传机制;而物联网平台SDK通常会自动处理消息边界。开发者只需关注业务数据的ITLV封装即可。
- 场景二:嵌入式板间通信。在串口、CAN、I2C等底层通信中,缺乏TCP那样的可靠保障,且易受电磁干扰。此时必须在ITLV之外增加:
- 包头(Header):用于帧同步,让接收方能从字节流中准确识别一帧的开始。
- 校验字段(CRC):用于检测数据传输过程中是否发生位错误。
此外,根据需求还可能扩展包序号(用于分包重传)、目标地址(用于多设备通信)等字段。
1.3 协议帧格式
基于上述分析,我们为一个典型的嵌入式板间串口通信场景设计协议帧格式如下:
| 字段 |
长度 |
说明 |
| Head |
2 字节 |
帧同步头,固定为 0x55, 0xAA。 |
| ID |
1 字节 |
协议标识符,对应ITLV中的 I。 |
| Type |
1 字节 |
数据类型,对应ITLV中的 T。 |
| Length |
1 字节 |
Payload长度(0-255字节),对应ITLV中的 L。 |
| Value/Payload |
N 字节 |
实际数据,对应ITLV中的 V。 |
| CRC16 |
2 字节 |
CRC16-X25校验值(小端序),校验范围从Head到Payload。 |
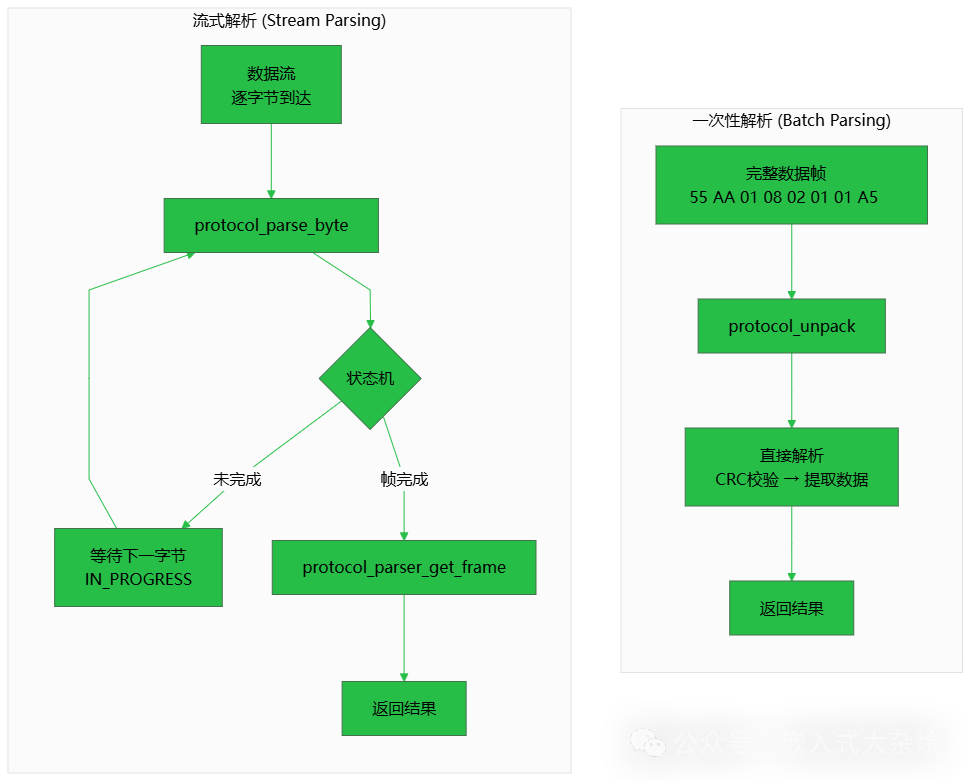
1.4 流式解析与一次性解析
根据数据来源的不同,我们的协议库需要提供两种解析方式以适应不同场景。
| 对比维度 |
一次性解析 |
流式解析 |
| 输入数据 |
完整的数据帧 |
逐字节到达的数据流 |
| 状态管理 |
无状态,函数调用即用即走 |
由状态机驱动,内部维护解析进度 |
| 缓冲区 |
依赖调用者提供完整缓冲区 |
解析器内部维护缓冲区 |
| 粘包/断包 |
不支持,要求输入必须为一整帧 |
自动处理,能应对数据粘连或分次到达 |
| 适用场景 |
UDP数据包、从文件读取的协议数据 |
串口、TCP Socket等流式接口 |
- 一次性解析:当你能确定已经拿到了一个完整的数据帧时使用。例如,从UDP报文或已经存储好的数据文件中读取。其优点是API调用简单、无状态;缺点是调用方必须确保输入数据的完整性。
- 流式解析:当数据是“一点一点”到达时使用。例如,在串口中断服务函数中,每次只能收到1个字节。解析器内部的状态机会“记住”当前已经收到了哪些部分,自动处理粘包(多帧数据粘连在一起到达)和断包(一帧数据被拆分成多次到达)。这种设计在 网络/系统 层面的流式数据处理中非常常见。
1.5 数据结构设计
1.5.1 跨平台打包属性
为了确保结构体在内存中紧密排列,消除编译器自动添加的填充字节,我们需要定义跨编译器的打包属性。
#if defined(__GNUC__) || defined(__clang__)
#define PACKED_STRUCT __attribute__((packed))
#elif defined(_MSC_VER)
#define PACKED_STRUCT
#pragma pack(push, 1)
#else
#define PACKED_STRUCT
#warning "Unknown compiler, packed attribute may not work correctly"
#endif
1.5.2 类型定义(使用固定宽度类型)
TLV中的Type字段我们使用固定宽度的uint8_t来定义,避免使用enum,因为枚举类型的大小是编译器相关的。
typedef uint8_t tlv_type_t;
#define TLV_TYPE_UINT8 ((tlv_type_t)0x00) // 无符号8位整数
#define TLV_TYPE_INT8 ((tlv_type_t)0x01) // 有符号8位整数
#define TLV_TYPE_UINT16 ((tlv_type_t)0x02) // 无符号16位整数
#define TLV_TYPE_INT16 ((tlv_type_t)0x03) // 有符号16位整数
#define TLV_TYPE_UINT32 ((tlv_type_t)0x04) // 无符号32位整数
#define TLV_TYPE_INT32 ((tlv_type_t)0x05) // 有符号32位整数
#define TLV_TYPE_STRING ((tlv_type_t)0x06) // 字符串类型
#define TLV_TYPE_FLOAT ((tlv_type_t)0x07) // 浮点类型
#define TLV_TYPE_BYTES ((tlv_type_t)0x08) // 字节数组
1.5.3 协议数据结构
这是用于组包和解包的核心数据容器,业务层数据最终被拷贝到payload字段中。
typedef struct
{
protocol_id_t id; // 协议ID
tlv_type_t type; // 数据类型
uint8_t length; // 数据长度
uint8_t payload[PROTOCOL_VALUE_MAX_LEN]; // 负载数据
} protocol_data_t;
1.5.4 错误码定义
统一的错误码有助于调试和问题定位。
typedef enum
{
PROTO_OK = 0, // 操作成功
PROTO_ERR_NULL_PTR = -1, // 空指针错误
PROTO_ERR_BUF_TOO_SMALL = -2, // 缓冲区太小
PROTO_ERR_INVALID_HEAD = -3, // 无效的包头
PROTO_ERR_CRC_MISMATCH = -4, // CRC校验失败
PROTO_ERR_INVALID_ID = -5, // 无效的协议ID
PROTO_ERR_PAYLOAD_SIZE = -6, // 负载大小错误
PROTO_ERR_IN_PROGRESS = -7, // 解析进行中
PROTO_ERR_INVALID_LEN = -8, // 无效的数据长度
} protocol_err_e;
1.5.5 流式解析器定义
流式解析的核心是一个状态机。每接收一个字节,状态机根据当前状态决定下一步动作,并迁移到新的状态。
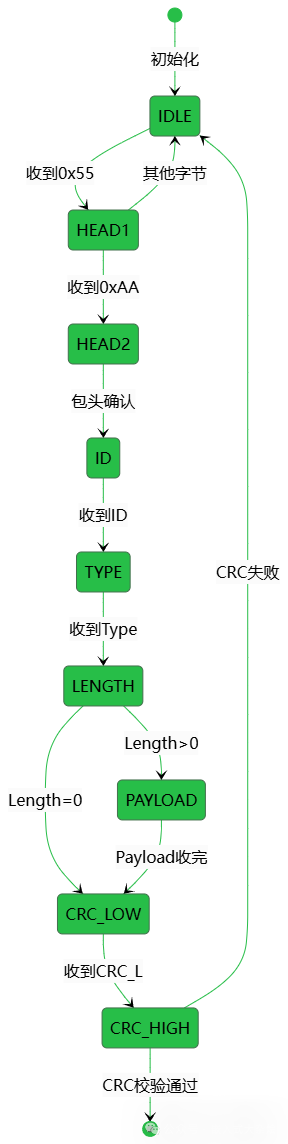
关键点:当收到的字节与预期不符时(例如在等待包头时收到了其他数据),状态机会自动回退到IDLE状态重新开始寻找帧头,这实现了简单的噪声过滤。
typedef enum
{
PARSE_STATE_IDLE = 0, // 空闲状态,等待帧头
PARSE_STATE_HEAD1, // 等待包头第一字节 0x55
PARSE_STATE_HEAD2, // 等待包头第二字节 0xAA
PARSE_STATE_ID, // 接收ID字段
PARSE_STATE_TYPE, // 接收Type字段
PARSE_STATE_LENGTH, // 接收Length字段
PARSE_STATE_PAYLOAD, // 接收Payload字段
PARSE_STATE_CRC_LOW, // 接收CRC低字节
PARSE_STATE_CRC_HIGH, // 接收CRC高字节
} parse_state_e;
typedef struct
{
parse_state_e state; // 当前解析状态
uint8_t buffer[PROTOCOL_MAX_LEN]; // 接收缓冲区
uint16_t index; // 缓冲区当前写入索引
uint8_t payload_len; // 当前帧期望的负载长度
} protocol_parser_t;
1.6 CRC16校验
CRC(循环冗余校验)用于检测数据传输或存储中可能出现的错误。本协议采用CRC16-X25算法,并使用查表法实现以提高在嵌入式设备上的运算效率。
校验范围:从帧头(0x55)开始,到Payload的最后一个字节结束,不包括CRC字段本身。
1.7 API接口设计
协议库的API主要分为三类:组包、一次性解包、流式解析。清晰的 后端 & 架构 层面的接口设计是模块化的关键。
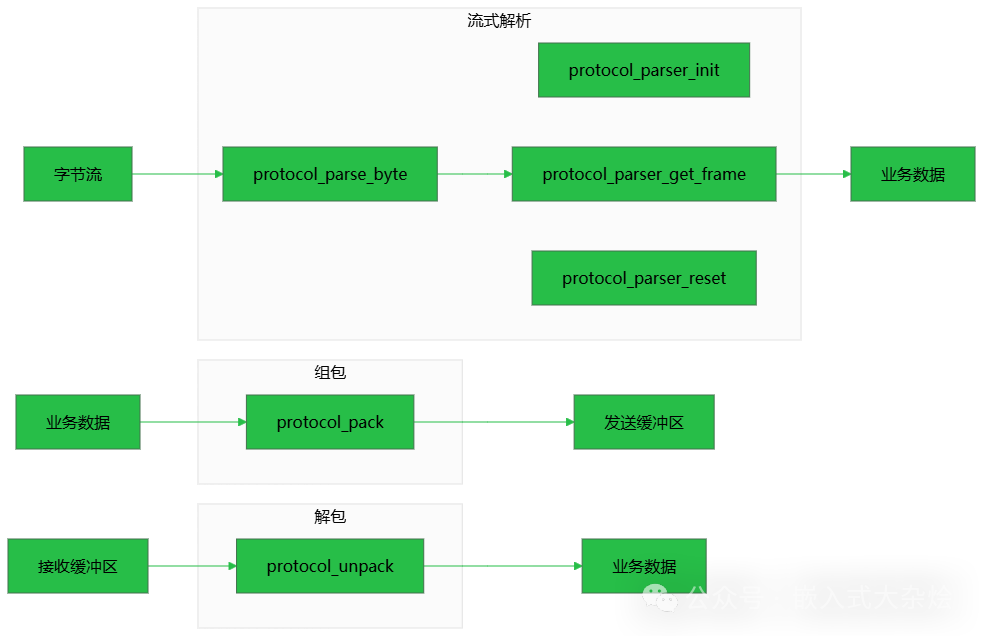
1.7.1 组包(Pack)
将业务数据(protocol_data_t)按照协议格式封装成二进制帧。
/**
* @brief 协议数据组包
* @param buf 输出缓冲区指针
* @param buf_size 缓冲区大小
* @param data 协议数据结构
* @param out_len 实际输出长度(输出参数)
* @return PROTO_OK: 成功, 其他: 错误码
*/
protocol_err_e protocol_pack(uint8_t *buf,
size_t buf_size,
const protocol_data_t *data,
size_t *out_len);
1.7.2 一次性解包(Unpack)
将接收到的完整二进制帧解析还原成业务数据结构。
/**
* @brief 一次性解包
* @param buf 输入缓冲区指针(完整帧)
* @param len 数据长度
* @param data 协议数据结构(输出参数)
* @return PROTO_OK: 成功, 其他: 错误码
*/
protocol_err_e protocol_unpack(const uint8_t *buf,
size_t len,
protocol_data_t *data);
1.7.3 流式解析(Stream Parsing)
提供初始化和逐字节喂数据的接口,由内部状态机管理解析过程。
/**
* @brief 初始化解析器
* @param parser 解析器实例指针
* @return PROTO_OK: 成功
*/
protocol_err_e protocol_parser_init(protocol_parser_t *parser);
/**
* @brief 重置解析器状态(清空缓冲区,回到IDLE)
* @param parser 解析器实例指针
*/
void protocol_parser_reset(protocol_parser_t *parser);
/**
* @brief 流式解析 - 逐字节输入
* @param parser 解析器实例指针
* @param byte 输入字节
* @return PROTO_OK: 帧完成, PROTO_ERR_IN_PROGRESS: 解析中, 其他: 错误码
*/
protocol_err_e protocol_parse_byte(protocol_parser_t *parser, uint8_t byte);
/**
* @brief 从解析器提取已解析完成的帧数据
* @param parser 解析器实例指针
* @param data 协议数据结构(输出参数)
* @return PROTO_OK: 成功
*/
protocol_err_e protocol_parser_get_frame(const protocol_parser_t *parser,
protocol_data_t *data);
2. ITLV组包、解包测试
下面通过两个典型测试场景来演示协议库的使用方法。
2.1 业务数据定义
首先,我们定义业务层需要用到的数据结构。注意使用 #pragma pack 确保结构体紧凑,这与协议层面的 C/C++ 内存布局紧密相关。
// 业务协议ID定义
#define CMD_ID_LED_CTRL (protocol_id_t)0x01
#define CMD_ID_DATE_TIME (protocol_id_t)0x02
#pragma pack(push, 1)
typedef struct
{
uint8_t led_id; // LED编号
uint8_t on_off; // 0=关闭, 1=打开
} led_ctrl_t;
typedef struct
{
uint16_t year;
uint8_t month;
uint8_t day;
uint8_t hour;
uint8_t minute;
uint8_t second;
uint8_t reserved;
} datetime_t;
#pragma pack(pop)
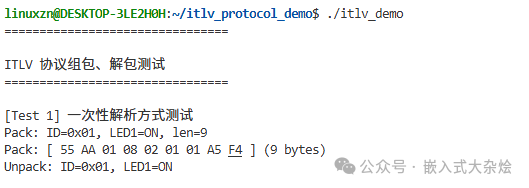
2.2 一次性解析测试
模拟已经收到完整数据帧的场景进行解包。
核心代码:
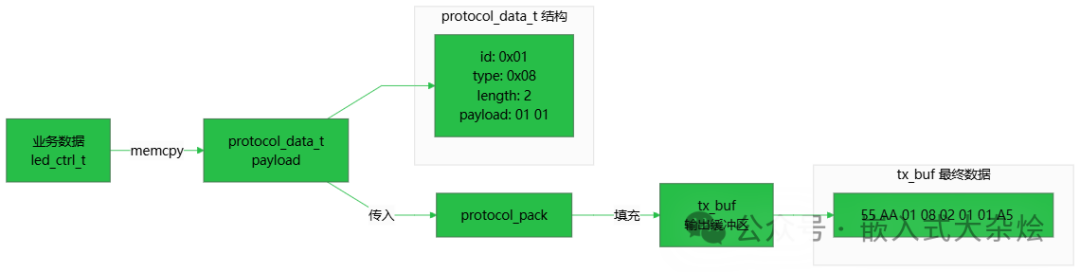
// 1. 准备业务数据
led_ctrl_t led_cmd = { .led_id = 1, .on_off = 1 };
protocol_data_t tx_data;
tx_data.id = CMD_ID_LED_CTRL;
tx_data.type = TLV_TYPE_BYTES;
tx_data.length = sizeof(led_cmd);
memcpy(tx_data.payload, &led_cmd, sizeof(led_cmd));
// 2. 组包
uint8_t tx_buf[256];
size_t frame_len = 0;
protocol_pack(tx_buf, sizeof(tx_buf), &tx_data, &frame_len);
printf("Pack: ID=0x%02X, LED%d=%s, len=%zu\n",
tx_data.id, led_cmd.led_id,
led_cmd.on_off ? "ON" : "OFF", frame_len);
printf("Pack: ");
protocol_print_hex(tx_buf, frame_len);
// 3. 解包
protocol_data_t rx_data;
protocol_err_e ret = protocol_unpack(tx_buf, frame_len, &rx_data);
if (ret == PROTO_OK)
{
led_ctrl_t *rx_led = (led_ctrl_t*)rx_data.payload;
printf("Unpack: ID=0x%02X, LED%d=%s\n\n",
rx_data.id, rx_led->led_id,
rx_led->on_off ? "ON" : "OFF");
}
运行结果:
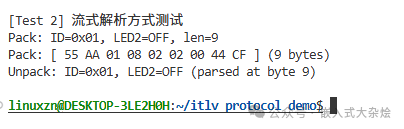
2.3 流式解析测试
模拟数据通过串口逐字节到达的场景,测试状态机解析。
核心代码:
protocol_parser_t parser;
protocol_parser_init(&parser);
// 模拟逐字节接收数据流
for (size_t i = 0; i < frame_len; i++)
{
protocol_err_e ret = protocol_parse_byte(&parser, tx_buf[i]);
if (ret == PROTO_OK)
{
// 一帧数据接收并解析完成
protocol_parser_get_frame(&parser, &rx_data);
led_ctrl_t *rx_led = (led_ctrl_t*)rx_data.payload;
printf("Unpack: ID=0x%02X, LED%d=%s (parsed at byte %zu)\n\n",
rx_data.id, rx_led->led_id,
rx_led->on_off ? "ON" : "OFF", i + 1);
break;
}
// 如果返回 PROTO_ERR_IN_PROGRESS,则继续接收下一个字节
}
运行结果:
3. 局限性与优化方向
本文实现的ITLV协议是一个轻量级的最小实现,其优点是简洁、高效,非常适合短距离、低误码率的嵌入式板间通信(如串口、SPI)。但如果要应用于更复杂或要求更高的场景,它也存在一些局限性,以下是一些可考虑的优化方向。
3.1 字段容量限制
| 字段 |
当前设计 |
局限性 |
优化方向 |
| ID |
1字节 (0~255) |
最多支持256种指令类型 |
扩展为2字节,支持65536种指令,满足更复杂系统。 |
| Length |
1字节 (0~255) |
单帧最大255字节,传输大文件受限 |
扩展为2字节(64KB),或设计分包/组帧机制传输超大文件。 |
| Type |
1字节 |
目前仅作为数据标记,未进行强制校验或转换 |
可深入利用,接收方根据Type字段自动进行大小端转换、浮点格式转换等。 |
3.2 可靠性机制不够完善
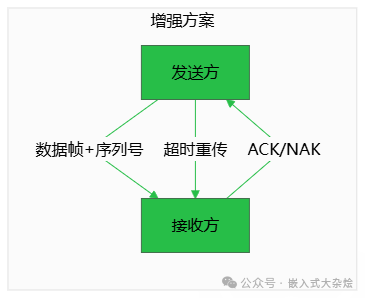
当前协议是一个简单的“发送即忘”模型,缺乏确认和重传机制。
优化方向:引入类似停等(Stop-and-Wait)ARQ的确认重传机制,提升在不可靠信道下的通信成功率。
3.3 状态机健壮性
当前状态机没有引入超时机制。如果发送方在传输中途断电或通信线路中断,接收方的状态机可能永远停留在某个中间状态,无法自动恢复。
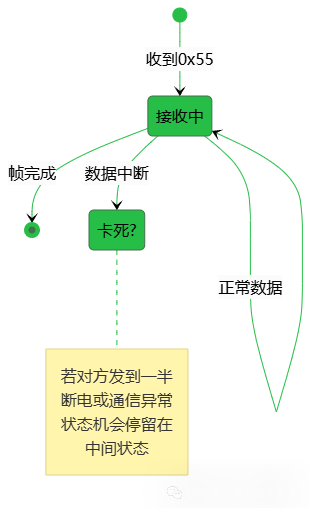
优化方向:为每个状态(特别是PARSE_STATE_PAYLOAD)增加超时计时器。超时后自动调用protocol_parser_reset()复位状态机,使其能够继续处理后续数据。
4. 总结
本文详细介绍的ITLV自定义协议库,具备以下核心特点:
| 特性 |
说明 |
| 简洁高效 |
最小帧仅7字节(Head+ID+Type+Length+CRC),协议开销小。 |
| 静态内存 |
全程无动态内存分配,避免碎片,确定性高,适合资源受限的嵌入式环境。 |
| 流式解析 |
内置状态机自动处理粘包和断包,非常适合串口等流式设备。 |
| CRC校验 |
提供数据完整性验证,抵抗传输过程中的偶发错误。 |
| 跨平台设计 |
使用固定宽度类型和编译器打包属性,确保在不同平台间的一致行为。 |
适用场景:短距离、低误码率的嵌入式板间通信,如单片机之间的UART、SPI、I2C通信。
不适用场景:对可靠性要求极高的关键通信、需要传输GB级大文件的场合、大型多设备组网、或涉及敏感数据需要加密的安全通信。
希望这份从设计原则到代码实现的详细解析,能为你构建自己的嵌入式通信协议提供扎实的参考。在实际项目中,你可以以此为基础,根据具体需求进行裁剪或扩展。更多关于嵌入式开发、系统架构的深入讨论,欢迎关注 云栈社区 的相关技术板块。
 发表于 2026-1-10 10:03:50
|
查看: 198|
回复: 0
发表于 2026-1-10 10:03:50
|
查看: 198|
回复: 0
