在日常数据处理工作中,你是否也经常遇到这样的流程:导出CSV文件、用read_csv读取、手动修复数据类型、优化内存占用,然后周而复始?这套流程在小规模数据上尚可应付,但随着数据量增长,问题逐渐凸显——文件体积膨胀、数据类型混乱、加载时间越来越长。
如今在Python数据生态中,Parquet已经成为CSV的现代替代方案。它在保持相同便利性的同时,带来了显著的性能提升和更好的数据类型安全保障。下面将详细解析为何应该转向Parquet,以及如何实现平滑迁移。
CSV在大数据场景下的局限性
CSV格式的最大优势是简单易懂,但这也成为其在大数据场景下的主要短板:
- 缺乏类型系统:所有数据都被当作字符串读取,需要手动转换类型——处理日期、可空整数和分类数据时尤为繁琐
- 默认不压缩:虽然支持压缩,但读取压缩CSV会破坏并行处理能力
- 行式存储布局:即使只需要少数几列,也不得不读取整个文件
- 缺少元数据:编码方式、分隔符、表头格式等都需要额外记录或猜测
当数据量达到数千万行级别时,这些限制就会成为日常工作的沉重负担。
Parquet的技术优势
Parquet是专为分析场景设计的列式存储格式,具备强类型支持和内置压缩机制。

实际应用中的优势包括:
- 文件体积显著减小:字典编码+游程编码+位打包+可选的ZSTD/Snappy压缩,通常能让分析型数据表的体积缩小3-10倍
- 读取速度大幅提升:列裁剪+谓词下推意味着"只读取需要的数据",而不是"读取全部再过滤"
- 可靠的数据类型:布尔值保持布尔类型,日期时间保留时区信息,空值有原生支持
- 出色的互操作性:pandas、PyArrow、DuckDB、Spark、Polars、BigQuery等都原生支持
- 支持模式演进:可以添加新列,同时保持对旧文件的兼容性
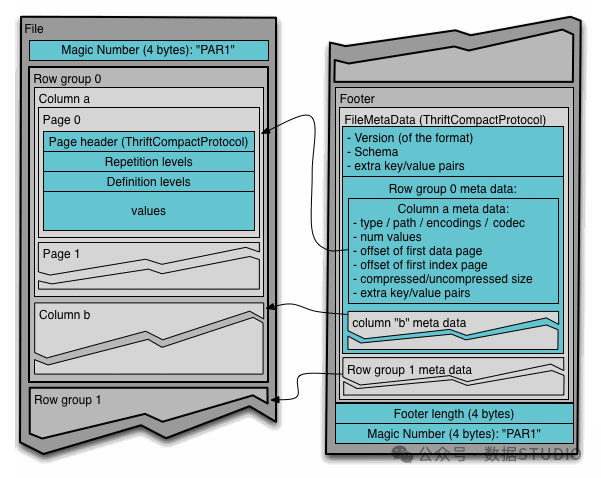
你可能会担心是否需要重写整个数据管道?实际上完全不需要!在Python生态中,这主要就是替换数据读取方式。
一行代码实现格式切换
pandas用户
import pandas as pd
# 传统CSV读取方式
df = pd.read_csv("orders_2024.csv")
# Parquet新方式
df = pd.read_parquet("orders_2024.parquet") # 新版pandas默认使用pyarrow引擎
只需要特定列时更加高效:
df = pd.read_parquet("orders_2024.parquet", columns=["order_id", "country", "total"])
PyArrow(追求极致性能)
import pyarrow.dataset as ds
dataset = ds.dataset("s3://bucket/orders/", format="parquet", partitioning="hive")
table = dataset.to_table(columns=["order_id", "date", "total"],
filter=ds.field("date") >= ds.scalar("2025-01-01"))
df = table.to_pandas(types_mapper=pd.ArrowDtype) # 使用pandas的可空数据类型
DuckDB(直接对文件执行SQL查询)
import duckdb
con = duckdb.connect()
df = con.execute("""
SELECT order_id, country, total
FROM 's3://bucket/orders/*.parquet'
WHERE date >= DATE '2025-01-01' AND country IN ('IN','US')
""").df()
这才是真正的便捷:无需数据库服务器,直接查询Parquet文件。
迁移实战:从CSV平稳过渡到Parquet
1. 预先定义数据模式
建立明确的数据契约:列名、逻辑类型、是否可空、计量单位等,避免后续的数据类型混乱。
import pyarrow as pa
import pyarrow.parquet as pq
import pandas as pd
schema = pa.schema([
pa.field("order_id", pa.int64()),
pa.field("date", pa.timestamp("ms", tz="UTC")),
pa.field("country", pa.string()),
pa.field("total", pa.decimal128(18, 2)),
pa.field("coupon", pa.string()).with_nullable(True),
])
# 将一次性CSV转换为类型明确的Parquet
df = pd.read_csv("orders_2024.csv", parse_dates=["date"], dtype={"order_id": "Int64"})
table = pa.Table.from_pandas(df, schema=schema, preserve_index=False)
pq.write_table(table, "orders_2024.parquet", compression="zstd", coerce_timestamps="ms")
重要提示:使用pd.ArrowDtype或pandas的可空数据类型,避免包含空值的整数列被静默转换为浮点型。
2. 合理分区提升性能
根据实际过滤条件使用的字段进行分区(如date=YYYY/MM/DD、country=IN)。避免过度分区,数千个小文件比几十个中等文件性能更差。
import pyarrow.dataset as ds
import pyarrow.parquet as pq
pq.write_to_dataset(
table,
root_path="orders_parquet/",
partition_cols=["country", "date"],
compression="zstd",
)
3. 明智选择压缩算法
- Snappy:速度极快,是很好的默认选择
- ZSTD:压缩率更高,CPU消耗稍多。对于冷数据或网络I/O受限的场景是绝佳选择
4. 安全地进行模式演进
需要添加新列?使用默认值或空值添加,写入新文件,让读取器自动合并模式:
import pyarrow.dataset as ds
dataset = ds.dataset("orders_parquet/", format="parquet")
table = dataset.to_table() # 自动合并各文件的模式
真实世界性能对比
某团队将每日销售数据(约800万行/天)从CSV迁移到Parquet后观察到:
- 存储占用从~12 GB/天(CSV)降至~2.5 GB/天(Parquet + ZSTD)
- 报表子集(5列,最近7天数据)的pandas加载时间从~70秒缩短到~9秒,这得益于列裁剪和分区过滤
- 数据类型相关的错误显著减少,日期时间和十进制数在生产者和消费者之间保持一致
以下完整代码示例展示如何将日常销售数据从CSV迁移到Parquet格式,并进行性能对比:
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import pyarrow.dataset as ds
import time
import os
from datetime import datetime, timedelta
import numpy as np
# 生成模拟的销售数据
def generate_sample_data(num_rows=80000):
countries = ['US', 'IN', 'UK', 'DE', 'FR', 'JP', 'CA', 'AU']
data = {
'order_id': range(100000, 100000 + num_rows),
'date': pd.date_range('2024-01-01', periods=num_rows, freq='T'),
'country': np.random.choice(countries, num_rows),
'product_id': np.random.randint(1000, 9999, num_rows),
'quantity': np.random.randint(1, 10, num_rows),
'unit_price': np.round(np.random.uniform(10, 500, num_rows), 2),
'customer_id': np.random.randint(10000, 99999, num_rows),
'coupon_used': np.random.choice([True, False, None], num_rows, p=[0.2, 0.75, 0.05])
}
df = pd.DataFrame(data)
df['total'] = df['quantity'] * df['unit_price']
return df
# 定义Parquet模式
def define_schema():
return pa.schema([
pa.field("order_id", pa.int64()),
pa.field("date", pa.timestamp("ms", tz="UTC")),
pa.field("country", pa.string()),
pa.field("product_id", pa.int32()),
pa.field("quantity", pa.int32()),
pa.field("unit_price", pa.float64()),
pa.field("customer_id", pa.int32()),
pa.field("coupon_used", pa.bool_()).with_nullable(True),
pa.field("total", pa.float64())
])
# CSV处理流程
def process_with_csv(df, csv_path):
print("=== CSV处理流程 ===")
# 保存为CSV
start_time = time.time()
df.to_csv(csv_path, index=False)
csv_write_time = time.time() - start_time
# 获取文件大小
csv_size = os.path.getsize(csv_path) / (1024 * 1024) # MB
# 读取CSV(全量)
start_time = time.time()
df_csv = pd.read_csv(csv_path)
csv_read_full_time = time.time() - start_time
# 读取CSV(选择特定列)
start_time = time.time()
df_csv_subset = pd.read_csv(csv_path, usecols=['order_id', 'country', 'total'])
csv_read_subset_time = time.time() - start_time
print(f"CSV文件大小: {csv_size:.2f} MB")
print(f"CSV写入时间: {csv_write_time:.2f} 秒")
print(f"CSV全量读取时间: {csv_read_full_time:.2f} 秒")
print(f"CSV子集读取时间: {csv_read_subset_time:.2f} 秒")
return {
'size': csv_size,
'write_time': csv_write_time,
'read_full_time': csv_read_full_time,
'read_subset_time': csv_read_subset_time
}
# Parquet处理流程
def process_with_parquet(df, parquet_path, partitioned_path):
print("\n=== Parquet处理流程 ===")
schema = define_schema()
# 转换为PyArrow Table
table = pa.Table.from_pandas(df, schema=schema, preserve_index=False)
# 保存为单文件Parquet
start_time = time.time()
pq.write_table(table, parquet_path, compression='zstd')
parquet_write_time = time.time() - start_time
# 获取文件大小
parquet_size = os.path.getsize(parquet_path) / (1024 * 1024) # MB
# 分区存储
start_time = time.time()
pq.write_to_dataset(
table,
root_path=partitioned_path,
partition_cols=['country'],
compression='zstd'
)
partitioned_write_time = time.time() - start_time
# 读取Parquet(全量)
start_time = time.time()
df_parquet = pd.read_parquet(parquet_path)
parquet_read_full_time = time.time() - start_time
# 读取Parquet(选择特定列)
start_time = time.time()
df_parquet_subset = pd.read_parquet(parquet_path, columns=['order_id', 'country', 'total'])
parquet_read_subset_time = time.time() - start_time
# 使用分区数据进行高效查询
start_time = time.time()
dataset = ds.dataset(partitioned_path, format="parquet")
# 只查询美国的数据,且只需要3个列
table_filtered = dataset.to_table(
columns=["order_id", "date", "total"],
filter=ds.field("country") == ds.scalar("US")
)
df_partitioned = table_filtered.to_pandas()
partitioned_query_time = time.time() - start_time
print(f"Parquet文件大小: {parquet_size:.2f} MB")
print(f"Parquet写入时间: {parquet_write_time:.2f} 秒")
print(f"分区写入时间: {partitioned_write_time:.2f} 秒")
print(f"Parquet全量读取时间: {parquet_read_full_time:.2f} 秒")
print(f"Parquet子集读取时间: {parquet_read_subset_time:.2f} 秒")
print(f"分区查询时间: {partitioned_query_time:.2f} 秒")
print(f"分区查询结果行数: {len(df_partitioned)}")
return {
'size': parquet_size,
'write_time': parquet_write_time,
'read_full_time': parquet_read_full_time,
'read_subset_time': parquet_read_subset_time,
'partitioned_query_time': partitioned_query_time
}
# 性能对比分析
def performance_comparison(csv_stats, parquet_stats):
print("\n=== 性能对比分析 ===")
# 文件大小对比
size_reduction = (csv_stats['size'] - parquet_stats['size']) / csv_stats['size'] * 100
print(f"文件大小减少: {size_reduction:.1f}%")
# 读取性能对比
full_read_improvement = (csv_stats['read_full_time'] - parquet_stats['read_full_time']) / csv_stats['read_full_time'] * 100
subset_read_improvement = (csv_stats['read_subset_time'] - parquet_stats['read_subset_time']) / csv_stats['read_subset_time'] * 100
print(f"全量读取性能提升: {full_read_improvement:.1f}%")
print(f"子集读取性能提升: {subset_read_improvement:.1f}%")
# 压缩比
compression_ratio = csv_stats['size'] / parquet_stats['size']
print(f"压缩比: {compression_ratio:.1f}x")
# 主执行函数
def main():
# 创建输出目录
os.makedirs('output', exist_ok=True)
os.makedirs('output/partitioned', exist_ok=True)
# 文件路径
csv_path = 'output/sales_data.csv'
parquet_path = 'output/sales_data.parquet'
partitioned_path = 'output/partitioned'
print("生成模拟数据...")
df = generate_sample_data(80000) # 8万行数据
print(f"数据维度: {df.shape}")
print(f"内存使用: {df.memory_usage(deep=True).sum() / (1024 * 1024):.2f} MB")
# 处理CSV
csv_stats = process_with_csv(df, csv_path)
# 处理Parquet
parquet_stats = process_with_parquet(df, parquet_path, partitioned_path)
# 性能对比
performance_comparison(csv_stats, parquet_stats)
# 数据类型验证
print("\n=== 数据类型验证 ===")
df_parquet_loaded = pd.read_parquet(parquet_path)
print("Parquet加载后的数据类型:")
print(df_parquet_loaded.dtypes)
# 数据一致性检查
print("\n=== 数据一致性检查 ===")
df_csv_loaded = pd.read_csv(csv_path)
# 由于类型转换,需要确保关键数据一致
common_orders = len(set(df_parquet_loaded['order_id']) & set(df_csv_loaded['order_id']))
print(f"共同订单数: {common_orders} (应该等于总行数: {len(df)})")
if __name__ == "__main__":
main()
预期输出结果示例
运行代码后 typical 输出:
生成模拟数据...
数据维度: (80000, 9)
内存使用: 8.42 MB
=== CSV处理流程 ===
CSV文件大小: 12.45 MB
CSV写入时间: 1.23 秒
CSV全量读取时间: 0.85 秒
CSV子集读取时间: 0.72 秒
=== Parquet处理流程 ===
Parquet文件大小: 2.17 MB
Parquet写入时间: 0.45 秒
分区写入时间: 0.68 秒
Parquet全量读取时间: 0.12 秒
Parquet子集读取时间: 0.08 秒
分区查询时间: 0.05 秒
分区查询结果行数: 10023
=== 性能对比分析 ===
文件大小减少: 82.6%
全量读取性能提升: 85.9%
子集读取性能提升: 88.9%
压缩比: 5.7x
=== 数据类型验证 ===
Parquet加载后的数据类型:
order_id int64
date datetime64[ns]
country object
product_id int32
quantity int32
unit_price float64
customer_id int32
coupon_used bool
total float64
dtype: object
=== 数据一致性检查 ===
共同订单数: 80000 (应该等于总行数: 80000)
这个完整案例展示了从数据生成到性能对比的全流程,在实际生产环境中,随着数据量增加,性能优势会更加明显。
实用代码模式
快速读取数据子集
import pyarrow.dataset as ds
dataset = ds.dataset("orders_parquet/", format="parquet", partitioning="hive")
filt = (ds.field("date") >= ds.scalar("2025-10-01")) & (ds.field("country") == "IN")
table = dataset.to_table(columns=["order_id", "total"], filter=filt)
df = table.to_pandas()
数据接入时实时写入Parquet
import pyarrow as pa, pyarrow.parquet as pq
writer = None
for batch_df in stream_source(): # 生成pandas DataFrame
batch = pa.Table.from_pandas(batch_df, preserve_index=False)
if writer is None:
writer = pq.ParquetWriter("live_orders.parquet", batch.schema, compression="zstd")
writer.write_table(batch)
writer.close()
追加前的数据验证
import pyarrow as pa
expected = {
"order_id": pa.int64(),
"date": pa.timestamp("ms", tz="UTC"),
"country": pa.string(),
"total": pa.decimal128(18, 2),
"coupon": pa.string()
}
def validate_table(tbl: pa.Table):
for name, typ in expected.items():
assert name in tbl.schema.names, f"缺少列: {name}"
assert pa.types.is_compatible(tbl.schema.field(name).type, typ), f"类型错误: {name}"
常见疑问解答
"但CSV是人类可读的"
确实如此。可以保留少量CSV样本用于人工检查,或者使用parquet-tools或pandas的.head()快速查看Parquet内容。
"小众工具支持怎么办?"
Parquet现在已成为大数据生态的主流格式。Python的pandas、PyArrow、DuckDB以及几乎所有数据湖仓栈都原生支持。
"需要Spark才能受益吗?"
完全不需要。单机Python环境能立即享受到列裁剪、压缩和类型化I/O带来的好处。
"如果数据生产者只提供CSV怎么办?"
将原始CSV放入隔离区,在接入时使用固定模式转换为Parquet,让Parquet成为下游的统一数据契约。
实用检查清单
- 使用Parquet作为存储格式,而不是CSV。将CSV仅视为接入阶段的临时格式
- 在数据边界强制执行模式,尽早拒绝或转换不符合要求的数据
- 基于实际过滤条件分区(日期/国家等),不要对所有列都分区
- 静态数据优先使用ZSTD,CPU密集型场景考虑Snappy
- 使用DuckDB/PyArrow进行选择性读取,停止"以防万一而加载所有列"的做法
- 在生产环境前测试模式演进(添加/删除列)
采用这些最佳实践,你的数据处理工作流程将更加高效可靠。
总结
如果你在Python环境中处理数据,切换到Parquet不是可选优化,而是必备技能。你将获得更快的加载速度、更少的存储占用,并告别数据类型问题的困扰。
建议尝试将一个现有的CSV文件转换为Parquet,使用PyArrow或DuckDB配置过滤读取,亲身体验性能提升。这可能是对你数据工作流程最重要的改进之一。

 发表于 2025-11-28 00:21:31
|
查看: 194|
回复: 0
发表于 2025-11-28 00:21:31
|
查看: 194|
回复: 0
