在嵌入式系统开发中,如何高效、可靠地从SPI从设备接收数据是一个常见挑战。对于恩智浦的i.MXRT系列,尤其是RT600平台,利用其DMA(直接内存访问)的链式传输功能,可以实现SPI从设备接收速率的上限(高达50Mbps),同时最大限度地降低CPU负载。本文将深入分析为何DMA是必选项,并展示如何改造SDK驱动以启用链式传输,从而让数据接收从“匆匆忙忙”变得“游刃有余”。
Note1:本文方法主要针对RT500/600上的DMA(又称LPC_DMA),其来自于恩智浦LPC系列。
Note2:RT700/RT4digits上的eDMA与LPC_DMA完全不同,其来自于原飞思卡尔Kinetis系列(KL25 DMA是第一代,K60 eDMA算第二代)。
一、Flexcomm SPI速率
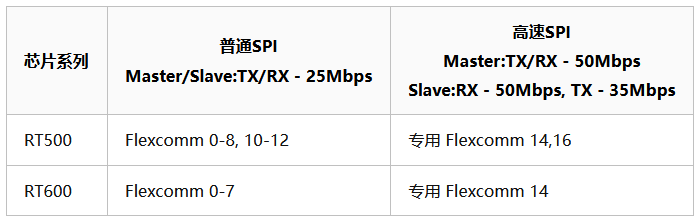
在探讨具体优化方法前,我们先了解一下RT500/600平台上SPI外设的理论性能。该系列芯片采用了名为Flexcomm的灵活外设模块(类似于RT4digits上的FlexIO),它可以根据需求被配置为USART、SPI、I2C或I2S等不同功能。
RT3digits芯片内部通常集成多个Flexcomm接口,并分为普通型和专用型两类:普通Flexcomm功能灵活但性能稍逊;专用Flexcomm为特定高速功能优化,牺牲了灵活性以换取更高的传输性能。根据芯片数据手册,不同系列的SPI速率上限如下:
二、为什么必须要用DMA?
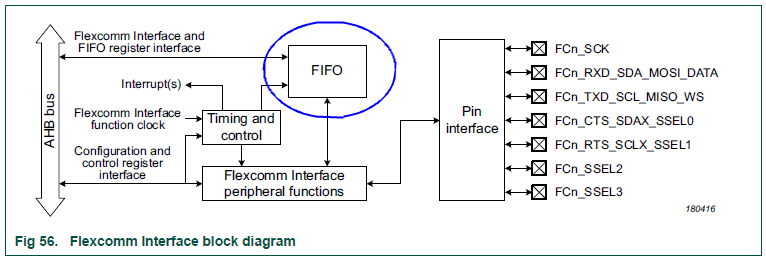
下图是Flexcomm接口的模块框图,其内部为收发数据分别配备了深度为8 entries的FIFO。这里的entry以SPI帧长度为单位,硬件支持4至16位的帧长。若配置为最常用的8位帧,则FIFO可缓存8字节数据。这提供了一定的缓冲能力,但不足以完全解决CPU响应延迟导致的数据丢失问题。
接收SPI从设备数据通常有三种方法,我们逐一分析其优劣:
- 轮询方式:CPU定期查询SPI RX FIFO状态寄存器,一旦有数据就立即读取。这种方法理论上可以达到50Mbps的速率上限,但代价是CPU(运行在275/300MHz)需要持续高负载地执行查询操作,极大地浪费了计算资源,且编程稍有不慎就容易漏数据,显得“匆匆忙忙”,通常不适用于实际应用。
- 中断方式:预先设置SPI RX FIFO的触发水位(1-8 entries),当数据量达到阈值时触发中断,在中断服务程序(ISR)中读取数据。该方法降低了CPU的平均负载,但由于Cortex-M33内核的中断延迟以及ISR本身的执行时间,往往难以稳定达到50Mbps的速率上限(理想情况需精细设置FIFO触发点为4 entries,并在ISR中一次性读取4个entry)。编程时需要“小心翼翼”,因此也不够理想。
- DMA方式:利用DMA自动将SPI RX FIFO中的数据搬运到指定的内存缓冲区中,整个过程无需CPU干预。这种方式能最大程度地降低CPU负载,并能轻松达到50Mbps的速率上限,堪称“游刃有余”。唯一的挑战在于单次DMA传输长度有限制,需要通过DMA链式传输来规避数据接收间隙,这正是多线程与高并发设计中常用的思想——将CPU从繁重的I/O任务中解放出来。
三、LPC_DMA功能介绍
既然DMA是必由之路,我们有必要简单了解RT500/600上的LPC_DMA。下图是其功能框图。该DMA控制器包含多个通道(RT600为33个,RT500为37个),各通道可独立或协同工作。对于单通道,需要理解四个核心概念:
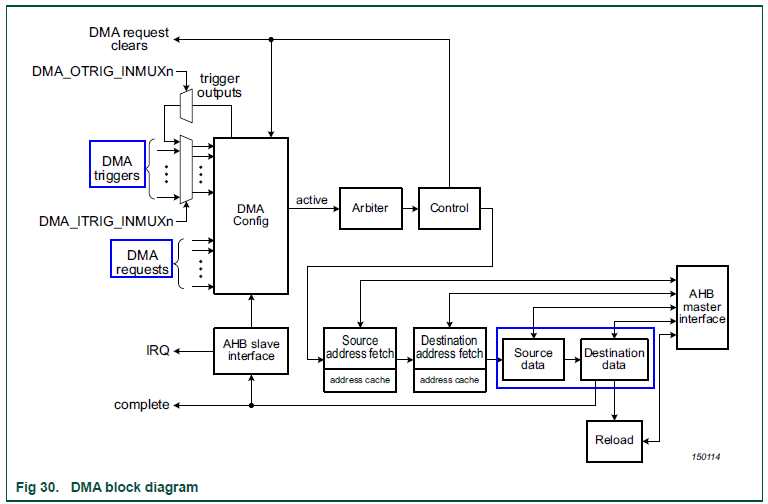
- 源/目标数据(src/dest data):DMA的本质是数据搬运。源地址和目标地址可以是内存或外设寄存器,因此产生了内存到内存、内存到外设、外设到内存等传输类型(外设到外设类型通常需要特殊设计,RT3digits不直接支持)。
- 传输计数(XFER Count):单次DMA传输搬运的数据量,可配置。在RT500/600上,上限为1024个单位(单位长度可配置为8/16/32位)。
- DMA请求(DMA requests):当搬运涉及外设寄存器时,需要指定具体的外设请求源。每个DMA通道对应的请求源是固定的,例如RT600的DMA0通道26仅能接收来自Flexcomm 14 SPI的RX请求。
- DMA触发器(DMA triggers):启动DMA工作的条件。除了软件触发,每个通道还可配置多种硬件触发条件(RT600有25种,RT500有27种),包括各种外设中断或其他DMA通道的输出触发信号。
理解了基础概念,还需了解DMA的几种数据传输模式(针对单通道):
- 单缓冲区(Single buffer):最基本的单次传输模式,源和目标地址通常线性递增,常用于内存间拷贝。
- 链式传输(Linked transfers):将多个DMA传输描述符链接起来,一次传输结束后自动跳转到下一个描述符开始新的传输。链接数量理论上仅受内存容量限制。一个典型应用是链接两个传输描述符,在双缓冲区之间循环工作,即“乒乓传输(Ping-pong Transfer)”。
- 交错传输(Interleaved transfers):一种特殊模式,可建立在链式传输之上,其源/目标地址可按特定步长增长。适用于处理音频、图像等具有特定结构的数据(例如从二维图像数据中提取特定行或列)。
基于上述模式,我们还可以将多个DMA通道串联工作(Channel chaining),即一个通道完成传输后触发另一个通道开始。此外,虽然多个通道可以并行工作,但在总线带宽紧张或内存访问冲突时,可以通过优先级仲裁(RT500/600支持8级优先级)来协调。
四、使能SPI DMA链式传输方法
SDK中提供了DMA链式传输的基础例程(路径:SDK_25_09_00_EVK-MIMXRT685\boards\evkmimxrt685\driver_examples\dma\linked_transfer),它清晰地演示了如何链接两个传输描述符,将两个源缓冲区的数据循环搬运到目标缓冲区。如果不在回调函数中干预,搬运将无限循环。
#include "fsl_dma.h"
static dma_handle_t s_DMA_Handle;
SDK_ALIGN(dma_descriptor_t s_dma_table[2], 16U);
SDK_ALIGN(uint32_t s_srcBuffer1[4], sizeof(uint32_t));
SDK_ALIGN(uint32_t s_srcBuffer2[4], sizeof(uint32_t));
SDK_ALIGN(uint32_t s_destBuffer[8], sizeof(uint32_t));
// 一次 DMA 传输结束用户回调(对应一个 DMA 传输描述符里的工作)
void DMA_Callback(dma_handle_t *handle, void *param, bool transferDone, uint32_t tcds)
{
// Do someting
}
// 初始化 DMA0 通道 0
DMA_Init(DMA0);
DMA_CreateHandle(&s_DMA_Handle, DMA0, 0);
DMA_EnableChannel(DMA0, 0);
DMA_SetCallback(&s_DMA_Handle, DMA_Callback, NULL);
// DMA 传输属性配置(uint大小为4bytes,源和目标地址均按1个unit自增,一次传输16bytes,使能reload特性和INTB)
uint32_t xferCfg = DMA_SetChannelXferConfig(true, false, false, true, 4U, kDMA_AddressInterleave1xWidth, kDMA_AddressInterleave1xWidth, 16U);
// 初始化两个 DMA 传输描述符,并且将其互相链接
DMA_SetupDescriptor(&(s_dma_table[0]), xferCfg, s_srcBuffer1, &s_destBuffer[0], &(s_dma_table[1]));
DMA_SetupDescriptor(&(s_dma_table[1]), xferCfg, s_srcBuffer2, &s_destBuffer[4], &(s_dma_table[0]));
// 将第一个 DMA 传输描述符赋给 DMA0 通道 0
DMA_SubmitChannelDescriptor(&s_DMA_Handle, &(s_dma_table[0]));
// 软件触发 DMA0 通道 0 开始工作
DMA_StartTransfer(&s_DMA_Handle);
然而,SDK中并没有现成的SPI从设备接收数据的DMA链式传输示例。唯一的SPI DMA例程(dma_b2b_transfer/slave)仅启动了单次传输。究其原因,是fsl_spi_dma.c驱动(V2.2.2)在设计上未对链式传输提供原生支持。
SPI_SlaveTransferDMA() -> SPI_MasterTransferDMA() ->
SPI_TransferSetupRxContextDMA(handle, xfer);
SPI_EnableRxDMA(base, true);
SPI_TransferSubmitNextRxDMA(base, handle); // 问题出在这个函数设计上
handle->rxInProgress = true;
DMA_StartTransfer(handle->rxHandle);
关键函数SPI_TransferSubmitNextRxDMA()默认使用内部的s_dma_descriptor_table,每次仅提交一次性的DMA传输,且禁用了reload功能。该函数的设计初衷是被多次调用来处理连续数据流,但这会在传输间隙引入延迟。因此,要实现真正的无间隙链式传输,必须改造此函数。

具体的改造过程涉及对驱动文件的修改,核心思想是预先配置好链接在一起的多个DMA传输描述符,并提交给DMA通道,使其能够自动循环搬运。在此过程中,开发者需要注意以下几个调试中容易遇到的“坑”:
- 坑1:链式传输时,在
DMA_SubmitTransfer()函数内部不应判断DMA_ChannelIsActive()状态,否则在初始化提交第二个及以后的DMA描述符时会因通道“繁忙”而直接返回失败。
- 坑2:链式传输模式下,
SPI_TransferRxHandlerDMA()中断处理程序的逻辑需要重新设计。不能简单地依据rxInProgress、rxRemainingBytes等状态来决定是否调用用户回调,而应基于每个链式描述符完成时触发的中断来进行处理。
- 坑3:链式传输时,不应在中断处理程序中将
spiHandle->state状态改为kSPI_Idle,否则SPI_MasterTransferGetCountDMA()等查询函数将无法正常工作。
详细的驱动改造代码可以参考痞子衡提供的GitHub仓库。通过实施这些改造,我们最终能够在i.MXRT600平台上,使SPI从设备的数据接收稳定达到50Mbps的理论上限,同时保持极低的CPU占用率,实现了高效可靠的系统设计。这种优化思路对于处理高速数据流的嵌入式应用具有广泛的参考价值。
 发表于 2026-1-10 19:10:43
|
查看: 201|
回复: 0
发表于 2026-1-10 19:10:43
|
查看: 201|
回复: 0
