像我这样的菜鸟,总会有各种疑问,刚开始是对 JDK API 的疑问,对 NIO 的疑问,对 JVM 的疑问,当工作几年后,对服务的可用性、可扩展性也有了新的疑问。其实就是那个老生常谈的话题:服务的扩容问题,真的像想象中那么简单吗?
正常情况下的服务演化之路
让我们从技术演进的起点开始回顾。
-
单体应用
每个创业公司基本都是从类似 SSM 和 SSH 这种架构起步的,这几乎是每个程序员的必经之路,没什么好讲的。
-
RPC 应用
当业务规模逐渐扩大,我们需要对服务进行水平扩容。扩容的原则很简单,只要保证服务本身是无状态的就可以了。架构演进如下图所示:
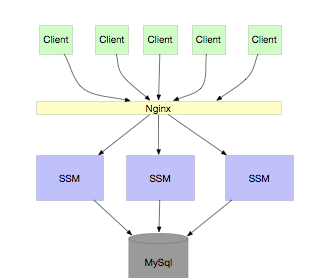
当业务继续膨胀,服务间的调用关系变得错综复杂。同时,我们会发现很多服务请求其实并不需要直接连接数据库(DB),访问缓存即可满足。这时,我们就可以将数据库连接分离出来,以减轻数据库宝贵的连接资源压力。架构进一步演变为:
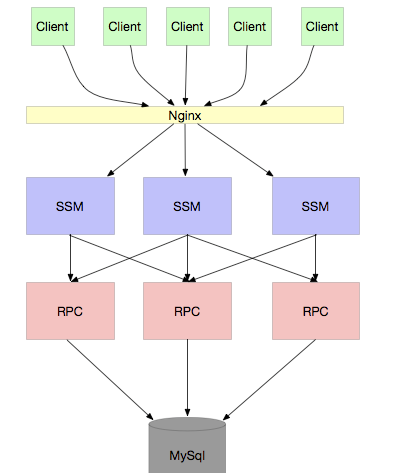
我相信大部分公司都处于或曾经处于这个阶段。像 Dubbo 这类 RPC 框架,正是为了解决服务间的复杂通信问题而诞生的。
如果你的公司产品持续受欢迎,业务保持高速增长,数据量暴增导致 SQL 操作越来越慢,那么数据库就会成为新的瓶颈。此时,你自然会想到 分库分表 —— 无论是通过 ID 哈希还是范围(range)的方式都可以。架构看起来会变成这样:
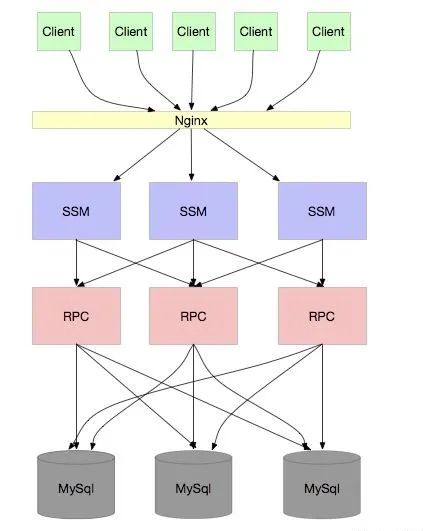
这下应该没问题了吧?看起来,任凭用户再多,并发再高,我只要无限扩容应用和数据库实例,似乎就能应对一切。
这也是本文希望探讨的核心:分库分表真的就能实现无限扩容吗?
实际上,采用上面这种架构,并不能彻底解决问题。
这里的瓶颈,和早期 RPC 面临的问题有点类似:数据库连接数过多!
通常,我们的 RPC 应用是通过中间件(如 Sharding-JDBC)来访问数据库的。应用本身并不知道具体要访问哪个数据库分片,访问规则由中间件决定。这就导致了一个后果:每个应用实例都必须和所有的数据库分片建立连接。
就像上面的架构图所示,一个 RPC 应用需要连接 3 个 MySQL 实例。如果我们有 30 个 RPC 应用实例,每个应用的数据库连接池大小设置为 8,那么每个 MySQL 实例就需要维护 240 个连接。
我们知道,MySQL 的默认最大连接数(max_connections)是 16384。也就是说,假设每个应用的连接池大小是 8,那么当应用实例数超过 2048 个时(16384 / 8 = 2048),就无法再建立新的数据库连接了,扩容也就走到了尽头。
注意,考虑到每个物理数据库上可能创建了多个逻辑库(schema),再加上微服务拆分愈演愈烈,服务实例数很容易膨胀,这个“2048”的极限并没有看起来那么遥远。
你可能会想:我可以在数据库前加一个代理(Proxy)来聚合连接,从而解决连接数问题。但代理本身的连接数同样受操作系统和硬件限制(通常也无法超过万级)。如果系统总并发连接需求从 16384 增长到 163840,那么单靠 Proxy 也是无力回天的。
怎么办?让我们再次审视上面的架构图:
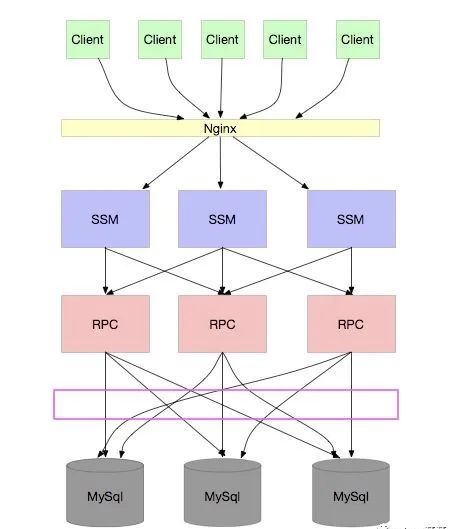
我们发现,问题的根源在于 “每个 RPC 应用都要连接所有的库”。这导致在扩容应用实例的同时,每个数据库实例需要支撑的连接数也线性增长。即使我们增加数据库实例数量,也只是分摊了数据存储和计算压力,但每个库需要应对的连接数问题依然存在。
那到底有什么办法可以破解这个困局呢?
单元化
“单元化”听起来是一个高大上的概念,通常与“两地三中心”、“异地多活”等复杂的容灾架构一同出现。这里我们不讨论那么宏大的场景,仅聚焦于解决 “数据库连接数过多” 这个具体问题。
其实思路很直接:我们不让一个应用实例连接所有的数据库分片不就行了?
假设我们根据用户 ID 的 range 范围将数据分成了 10 个库。同时,我们有 10 个应用实例。我们让每个应用实例只固定连接其中一个库。
当业务增长,需要将应用实例扩容到 20 个时,数据库连接不够用了。我们的操作是:将这 10 个库进一步拆分成 20 个库。然后让扩容后的20个应用实例,各自连接拆分后的一个新库。
这样,无论你的应用实例扩容到多少,都可以通过同步增加和拆分数据库实例,保证 “一个应用实例只连接一个数据库实例” 的关系,从而从根本上解决连接数过多的问题。
核心前提:你必须保证,访问某个特定应用实例的请求,其需要操作的数据一定是在该实例所连接的数据库分片内的。
换句话说,当一个用户请求通过负载均衡(如 DNS)进入系统时,系统在到达具体应用之前,就已经根据某种规则(比如用户ID哈希)确定了他应该访问哪个数据库分片,进而将其路由到连接了该分片的那个应用实例上去。
因此,这通常需要一套清晰的、全局一致的路由规则。例如,通过用户 ID 进行哈希,并由一个统一的配置中心将这个哈希规则广播给所有相关组件(如网关、服务本身)。这样,所有组件都能依据同一套规则,将请求正确地路由到对应的应用单元和数据库单元。架构示意图如下:
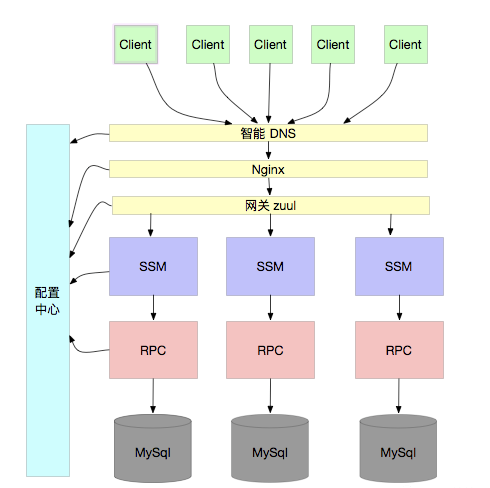
走到这一步,我们才真正解决了 “无限扩容” 的理论瓶颈。
总结
本文从单体应用开始,逐步梳理了一个典型后端系统在用户量与数据量增长压力下的架构演进历程。我们认识到,简单的分库分表虽然能解决数据存储和单点性能问题,但无法根治由连接数引发的 “无限扩容” 瓶颈。
只有引入 “单元化” 架构思想,将数据、应用、路由进行一体化设计与拆分,才能突破这一限制。当然,单元化也带来了更高的系统复杂性,例如路由规则的管理、数据的迁移与均衡、跨单元调用的处理等。但其带来的系统水平扩展能力的巨大提升,价值是不言而喻的。
单元化也为解决高可用问题提供了新的思路。虽然我们通过单元化解决了无限扩容的问题,但上图中的每个数据库单元目前仍是单点,服务的可用性尚未得到保障。如何在此基础上构建“异地多活”等更高阶的高可用架构,则是另一个值得深入探讨的话题。
对于分布式系统架构的更多思考和讨论,欢迎来到 云栈社区 与广大开发者一同交流。
 发表于 2026-1-11 19:57:00
|
查看: 208|
回复: 0
发表于 2026-1-11 19:57:00
|
查看: 208|
回复: 0
