引言: 为什么需要内存映射?
想象一下你正在管理一个巨大的仓库(物理内存),但仓库本身杂乱无章,直接在里面找东西效率极低。这时你会创建一个智能目录系统(虚拟内存),每个物品都有固定编号,找东西时先查目录,目录告诉你物品实际在哪个货架哪个位置——这就是内存映射的核心思想。
作为 Linux 内核的核心机制之一,内存映射不仅提供了进程隔离的安全保障,更通过巧妙的间接访问机制,让有限物理内存得以高效支持近乎无限的虚拟地址空间。理解它,是深入 Linux 系统编程和性能优化的必经之路。
第一章: 内存映射基础概念
1.1 虚拟内存与物理内存的关系
虚拟内存 是进程看到的连续地址空间,从 0 到 4GB(32位)或更大(64位)。 物理内存 是实际的 RAM 硬件。两者通过 页表 建立映射关系。
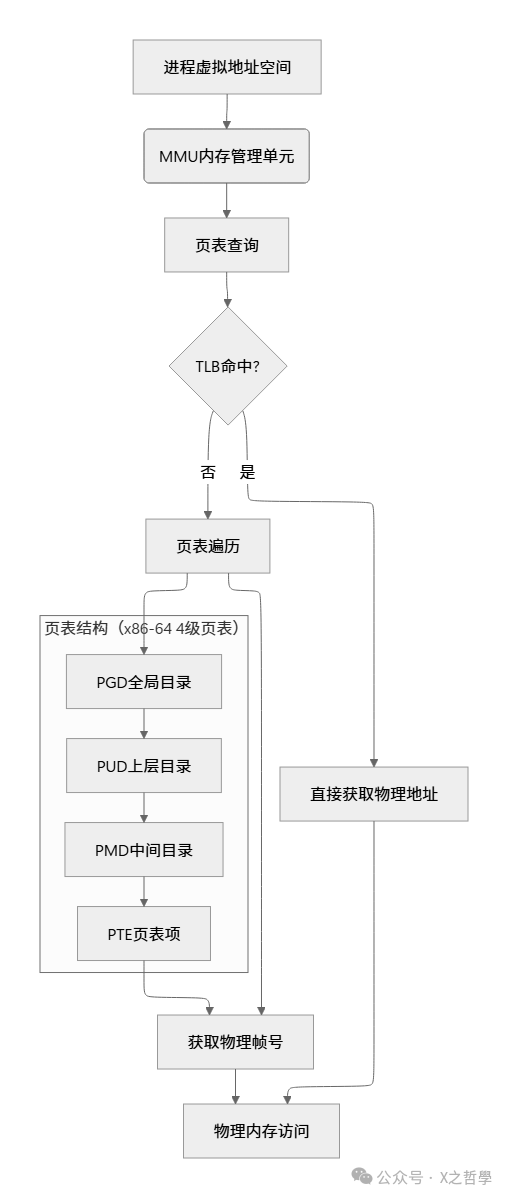
生活比喻: 虚拟内存就像餐厅的菜单(连续编号的菜品),物理内存是厨房的实际食材。顾客(进程)点菜只看菜单号,厨师(MMU内存管理单元)根据号码找到实际食材位置。
1.2 内存映射的三种基本类型
| 类型 |
数据来源 |
共享性 |
典型应用 |
生命周期 |
| 文件映射 |
磁盘文件 |
私有/共享 |
加载动态库、mmap文件I/O |
可持久化 |
| 匿名映射 |
全零页/交换空间 |
私有/共享 |
malloc大内存、进程栈 |
进程结束消失 |
| 共享内存映射 |
内存区域 |
共享 |
IPC共享内存、X服务器 |
显式销毁 |
第二章: 核心数据结构深度解析
2.1 进程地址空间描述符: mm_struct
每个进程都有独立的地址空间,由 mm_struct 描述。这是 Linux 内存管理 的基石之一:
// include/linux/mm_types.h 精简版
struct mm_struct {
struct {
struct vm_area_struct *mmap; // VMA链表头
struct rb_root mm_rb; // VMA红黑树根
unsigned long task_size; // 地址空间大小
pgd_t *pgd; // 页全局目录
unsigned long start_code, end_code; // 代码段边界
unsigned long start_data, end_data; // 数据段边界
unsigned long start_brk, brk; // 堆边界
unsigned long start_stack; // 栈起始
unsigned long arg_start, arg_end; // 命令行参数
unsigned long env_start, env_end; // 环境变量
} __randomize_layout;
atomic_t mm_users; // 使用该地址空间的用户数
atomic_t mm_count; // 主引用计数
struct list_head mmlist; // 所有mm_struct链表
};
2.2 虚拟内存区域: vm_area_struct (VMA)
VMA描述虚拟地址空间中一段 连续的、具有相同访问属性的区域 ,是内存映射的直接管理者。
struct vm_area_struct {
unsigned long vm_start; // 区域起始地址
unsigned long vm_end; // 区域结束地址
struct mm_struct *vm_mm; // 所属地址空间
// 权限标志
pgprot_t vm_page_prot;
unsigned long vm_flags; // VM_READ, VM_WRITE, VM_EXEC等
struct rb_node vm_rb; // 红黑树节点
// 链表连接
struct vm_area_struct *vm_next, *vm_prev;
// 文件相关信息(文件映射时使用)
struct file *vm_file;
unsigned long vm_pgoff; // 文件内偏移(页单位)
// 操作函数集
const struct vm_operations_struct *vm_ops;
// 匿名映射相关信息
struct anon_vma *anon_vma; // 匿名映射管理结构
};
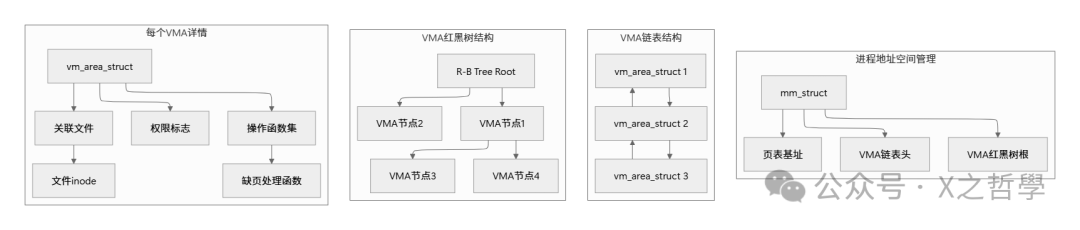
关键点: Linux同时用 链表 (便于遍历)和 红黑树 (快速查找特定地址)管理VMA。查找地址属于哪个VMA时,红黑树的O(log n)效率远高于链表的O(n)。
2.3 页表项: pte_t 与多级页表
以x86-64为例,采用4级页表结构:
虚拟地址分解:
63-48 47-39 38-30 29-21 20-12 11-0
保留位 PGD索引 PUD索引 PMD索引 PTE索引 页内偏移
// 页表项标志位(部分)
#define _PAGE_PRESENT 0x001 // 页在内存中
#define _PAGE_RW 0x002 // 可写
#define _PAGE_USER 0x004 // 用户空间可访问
#define _PAGE_ACCESSED 0x020 // 已被访问
#define _PAGE_DIRTY 0x040 // 已被写入
#define _PAGE_FILE 0x800 // 文件映射页(非Present时)
第三章: 内存映射的工作机制
3.1 mmap系统调用全流程
// mm/mmap.c 核心逻辑简化
SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, off)
{
// 1. 参数检查和调整
len = PAGE_ALIGN(len); // 按页对齐
// 2. 获取文件指针(文件映射时)
struct file *file = NULL;
if (flags & MAP_SHARED) {
file = fget(fd);
}
// 3. 调用内核实际处理函数
addr = vm_mmap_pgoff(file, addr, len, prot, flags, off >> PAGE_SHIFT);
// 4. 返回映射的虚拟地址
return addr;
}
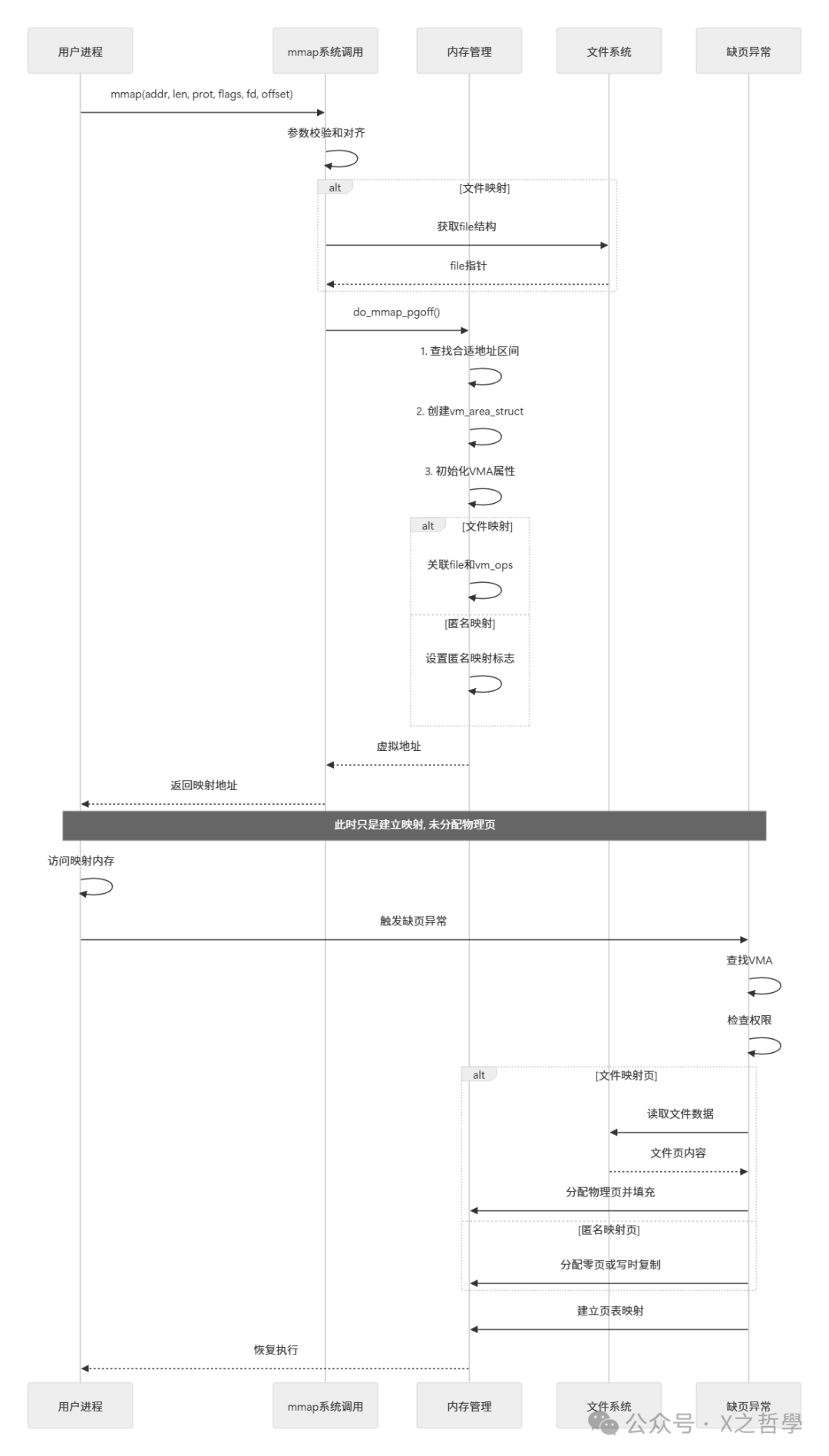
3.2 缺页异常处理: 按需分配的魔法
核心思想: Linux采用延迟分配(Lazy Allocation)策略,mmap 时只建立虚拟映射,实际物理页在首次访问时通过缺页异常分配。这是提升内存利用率和程序启动速度的关键。
// mm/memory.c 缺页处理核心(极度简化)
static vm_fault_t handle_mm_fault(struct vm_area_struct *vma,
unsigned long address,
unsigned int flags)
{
// 1. 查找各级页表项
pgd_t *pgd = pgd_offset(vma->vm_mm, address);
p4d_t *p4d = p4d_alloc(vma->vm_mm, pgd, address);
pud_t *pud = pud_alloc(vma->vm_mm, p4d, address);
pmd_t *pmd = pmd_alloc(vma->vm_mm, pud, address);
if (!pmd)
return VM_FAULT_OOM;
// 2. 处理页表中间目录
if (pmd_none(*pmd)) {
// 中间目录为空,需要分配新页表
pte_t *new_pte = pte_alloc_one(vma->vm_mm);
pmd_populate(vma->vm_mm, pmd, new_pte);
}
// 3. 处理实际页表项
pte_t *pte = pte_offset_map(pmd, address);
if (pte_none(*pte)) {
// 页不存在,需要分配页面
return do_anonymous_page(vma, address, pte, flags);
} else if (pte_present(*pte)) {
// 页存在但可能涉及写时复制
return do_wp_page(vma, address, pte, flags);
}
// 4. 文件映射的特殊处理
if (vma->vm_ops && vma->vm_ops->fault) {
return vma->vm_ops->fault(vma, address, flags);
}
return VM_FAULT_SIGBUS; // 不应该到达这里
}
3.3 文件映射 vs 匿名映射的底层差异
文件映射的页面缓存机制:
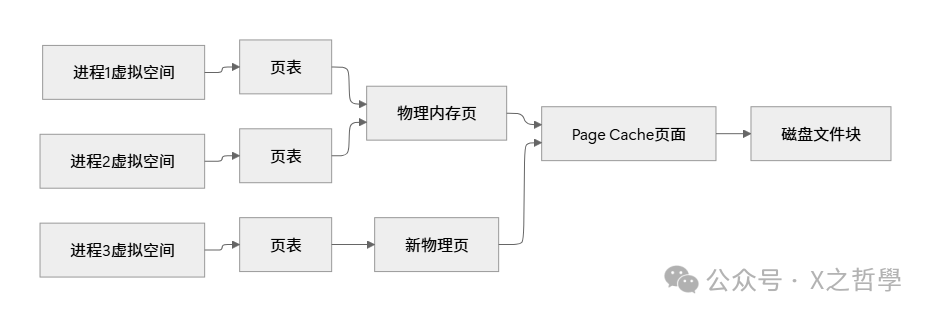
关键数据结构:
struct page {
unsigned long flags; // 页面状态标志
struct address_space *mapping; // 指向地址空间(文件映射时)
pgoff_t index; // 页面在文件中的偏移
void *private; // 私有数据
atomic_t _mapcount; // 映射计数
atomic_t _refcount; // 引用计数
};
当多个进程映射同一文件时,内核通过 Page Cache 共享页面,避免重复磁盘读取。这是文件映射性能优势的来源。
第四章: 高级内存映射特性
4.1 写时复制(Copy-on-Write, COW)
生活比喻: 父子分家前共用一本账本(共享物理页),当一方要修改账目时,才复印一份(分配新页)各自修改。
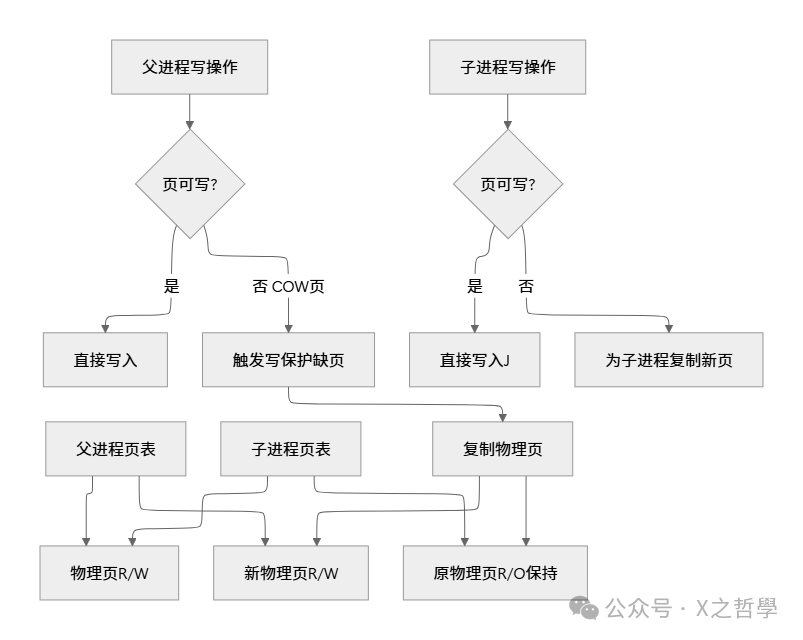
内核实现关键:
static vm_fault_t do_wp_page(struct vm_area_struct *vma,
unsigned long address,
pte_t *page_table)
{
struct page *old_page, *new_page;
// 获取原页面
old_page = vm_normal_page(vma, address, *page_table);
// 如果页面只被一个进程引用,直接改为可写
if (page_mapcount(old_page) == 1) {
pte_t new_pte = pte_mkyoung(*page_table);
new_pte = pte_mkdirty(new_pte);
new_pte = pte_mkwrite(new_pte);
set_pte_at(vma->vm_mm, address, page_table, new_pte);
return VM_FAULT_WRITE;
}
// 多个引用,需要复制
new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address);
// 复制页面内容
copy_user_highpage(new_page, old_page, address, vma);
// 更新页表: 原页只读,新页可写
pte_t new_pte = mk_pte(new_page, vma->vm_page_prot);
new_pte = pte_mkyoung(new_pte);
new_pte = pte_mkdirty(new_pte);
new_pte = pte_mkwrite(new_pte);
set_pte_at(vma->vm_mm, address, page_table, new_pte);
// 减少原页引用
page_remove_rmap(old_page, false);
return VM_FAULT_WRITE;
}
4.2 大页(Huge Pages)映射
传统4KB页表的问题:TLB覆盖范围有限。大页(通常2MB或1GB)减少TLB Miss,显著提升内存访问密集型应用的性能。
// 使用大页的mmap示例
addr = mmap(NULL, 2*1024*1024, PROT_READ|PROT_WRITE,
MAP_PRIVATE|MAP_ANONYMOUS|MAP_HUGETLB,
-1, 0);
大页管理:
# 查看大页信息
$ cat /proc/meminfo | grep Huge
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
# 预留大页
$ echo 20 > /proc/sys/vm/nr_hugepages
4.3 内存映射的同步机制
msync系统调用: 确保映射内容与磁盘同步。
int msync(void *addr, size_t length, int flags);
| 标志 |
含义 |
性能影响 |
MS_SYNC |
同步写,等待完成 |
高延迟,数据安全 |
MS_ASYNC |
异步写,立即返回 |
低延迟,可能丢失 |
MS_INVALIDATE |
使缓存无效 |
强制重新读取 |
第五章: 实战应用与性能分析
5.1 使用mmap加速文件读取
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s <file>\n", argv[0]);
return 1;
}
// 传统read方式
struct timespec start, end;
clock_gettime(CLOCK_MONOTONIC, &start);
int fd = open(argv[1], O_RDONLY);
struct stat sb;
fstat(fd, &sb);
char *buf = malloc(sb.st_size);
read(fd, buf, sb.st_size);
// 处理数据...
for (off_t i = 0; i < sb.st_size; i++) {
buf[i] = buf[i] + 1; // 示例操作
}
free(buf);
close(fd);
clock_gettime(CLOCK_MONOTONIC, &end);
double read_time = (end.tv_sec - start.tv_sec) +
(end.tv_nsec - start.tv_nsec) / 1e9;
// mmap方式
clock_gettime(CLOCK_MONOTONIC, &start);
fd = open(argv[1], O_RDONLY);
fstat(fd, &sb);
char *mapped = mmap(NULL, sb.st_size, PROT_READ|PROT_WRITE,
MAP_PRIVATE, fd, 0);
// 处理数据...
for (off_t i = 0; i < sb.st_size; i++) {
mapped[i] = mapped[i] + 1; // 触发写时复制
}
munmap(mapped, sb.st_size);
close(fd);
clock_gettime(CLOCK_MONOTONIC, &end);
double mmap_time = (end.tv_sec - start.tv_sec) +
(end.tv_nsec - start.tv_nsec) / 1e9;
printf("read() time: %.6f seconds\n", read_time);
printf("mmap() time: %.6f seconds\n", mmap_time);
printf("Speedup: %.2fx\n", read_time / mmap_time);
return 0;
}
性能对比结果(典型情况):
| 文件大小 |
read()时间 |
mmap()时间 |
加速比 |
适用场景 |
| 1MB |
0.0021s |
0.0018s |
1.17x |
小文件优势不明显 |
| 100MB |
0.215s |
0.142s |
1.51x |
中等文件有明显优势 |
| 1GB |
2.31s |
1.26s |
1.83x |
大文件优势显著 |
| 10GB |
25.4s |
12.8s |
1.98x |
超大文件接近2倍 |
5.2 进程间共享内存通信
// writer.c
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>
struct shared_data {
int counter;
char message[256];
};
int main() {
// 创建共享内存对象
int fd = shm_open("/my_shm", O_CREAT | O_RDWR, 0666);
ftruncate(fd, sizeof(struct shared_data));
// 映射共享内存
struct shared_data *data = mmap(NULL, sizeof(struct shared_data),
PROT_READ | PROT_WRITE,
MAP_SHARED, fd, 0);
// 写入数据
data->counter = 0;
for (int i = 0; i < 10; i++) {
data->counter++;
snprintf(data->message, sizeof(data->message),
"Message #%d", data->counter);
printf("Writer: counter=%d, message=%s\n",
data->counter, data->message);
sleep(1);
}
// 清理
munmap(data, sizeof(struct shared_data));
close(fd);
shm_unlink("/my_shm");
return 0;
}
// reader.c
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
struct shared_data {
int counter;
char message[256];
};
int main() {
int fd = shm_open("/my_shm", O_RDONLY, 0666);
struct shared_data *data = mmap(NULL, sizeof(struct shared_data),
PROT_READ,
MAP_SHARED, fd, 0);
for (int i = 0; i < 10; i++) {
printf("Reader: counter=%d, message=%s\n",
data->counter, data->message);
sleep(1);
}
munmap(data, sizeof(struct shared_data));
close(fd);
return 0;
}
第六章: 调试与监控工具
6.1 进程内存映射查看
# 查看进程内存映射
$ pmap -x <pid>
Address Kbytes RSS Dirty Mode Mapping
0000555555554000 4 4 0 r-x-- a.out
0000555555755000 4 4 4 r---- a.out
0000555555756000 4 4 4 rw--- a.out
00007ffff7a3a000 1784 308 0 r-x-- libc-2.31.so
00007ffff7bf2000 2048 0 0 ----- libc-2.31.so
00007ffff7df2000 16 16 16 r---- libc-2.31.so
00007ffff7df6000 8 8 8 rw--- libc-2.31.so
# 详细统计信息
$ cat /proc/<pid>/maps
$ cat /proc/<pid>/smaps # 更详细的统计信息
# 按内存使用排序
$ ps aux --sort=-rss
6.2 性能分析工具
# 使用perf分析缺页异常
$ perf record -e page-faults -g ./my_program
$ perf report
# 使用trace-cmd跟踪mmap相关事件
$ trace-cmd record -e syscalls -F ./my_program
$ trace-cmd report | grep mmap
# 使用valgrind检测内存问题
$ valgrind --tool=memcheck ./my_program
$ valgrind --tool=massif ./my_program # 堆分析
6.3 内核调试技巧
// 添加调试打印(内核模块中)
#include <linux/kernel.h>
static void debug_vma(struct vm_area_struct *vma)
{
printk(KERN_DEBUG "VMA: %lx-%lx, flags: %lx, file: %p\n",
vma->vm_start, vma->vm_end, vma->vm_flags, vma->vm_file);
if (vma->vm_file) {
printk(KERN_DEBUG " File: %s, inode: %lu\n",
vma->vm_file->f_path.dentry->d_name.name,
vma->vm_file->f_inode->i_ino);
}
}
// 使用ftrace动态追踪
$ echo 1 > /sys/kernel/debug/tracing/events/kmem/mm_page_alloc/enable
$ cat /sys/kernel/debug/tracing/trace_pipe
第七章: 内存映射优化策略
7.1 映射参数选择策略
| 场景 |
推荐参数 |
理由 |
| 只读大文件 |
PROT_READ, MAP_PRIVATE |
节省内存,可共享页缓存 |
| 读写大文件 |
PROT_READ|PROT_WRITE, MAP_SHARED |
修改可同步到文件 |
| 进程间共享 |
MAP_SHARED, MAP_ANONYMOUS 或 shm_open |
避免磁盘IO |
| 临时大数据 |
PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS |
纯内存操作 |
| 对齐要求 |
MAP_ALIGNED或手动对齐 |
避免TLB抖动 |
7.2 预读与预取优化
// 使用madvise提供访问模式提示
madvise(addr, length, MADV_SEQUENTIAL); // 顺序访问
madvise(addr, length, MADV_RANDOM); // 随机访问
madvise(addr, length, MADV_WILLNEED); // 即将访问
madvise(addr, length, MADV_DONTNEED); // 不再需要
// 使用mlock锁定关键页面(避免交换)
mlock(addr, length); // 锁定到物理内存
munlock(addr, length); // 解除锁定
mlockall(MCL_CURRENT); // 锁定所有当前映射
7.3 NUMA架构优化
// 在特定NUMA节点分配内存
#include <numaif.h>
// 设置内存分配策略
set_mempolicy(MPOL_BIND, &nodemask, sizeof(nodemask));
// 或者使用mbind对已有映射设置策略
mbind(addr, length, MPOL_BIND, &nodemask, sizeof(nodemask), 0);
第八章: 常见问题与解决方案
8.1 内存碎片化问题

检测碎片:
$ cat /proc/buddyinfo # 查看伙伴系统空闲页
$ cat /proc/pagetypeinfo # 页面类型信息
$ cat /proc/vmstat | grep frag # 碎片统计
8.2 内存泄漏检测
// 使用内核的page owner追踪
$ echo 1 > /sys/kernel/debug/page_owner
$ cat /sys/kernel/debug/page_owner > page_owner.txt
$ grep -A 10 "PFN" page_owner.txt | head -50
// 用户空间检测工具
$ valgrind --leak-check=full ./my_program
$ mtrace ./my_program # glibc内存跟踪
总结: Linux内存映射设计哲学
通过对Linux内存映射机制的深度剖析,我们可以总结出其核心设计思想,这些思想深刻体现了 计算机科学 中关于抽象和资源管理的精髓。
9.1 分层抽象与统一管理

9.2 关键优化技术回顾
| 技术 |
解决的问题 |
实现机制 |
性能提升 |
| 缺页异常延迟分配 |
避免无用内存分配 |
首次访问时触发 |
启动快,内存利用率高 |
| 写时复制 |
快速进程创建 |
共享页+写时复制 |
fork()速度提升10-100倍 |
| 页缓存 |
磁盘IO瓶颈 |
内存中缓存文件页 |
文件访问速度提升2-5倍 |
| 透明大页 |
TLB覆盖有限 |
自动合并小页 |
大数据处理提升15-30% |
| NUMA感知 |
跨节点访问延迟 |
就近分配策略 |
多插槽系统提升20-50% |
9.3 给开发者的建议
- 理解访问模式: 顺序访问使用
MADV_SEQUENTIAL,随机访问使用 MADV_RANDOM。
- 合理选择映射类型: 只读文件用私有映射,共享数据用共享映射。
- 注意对齐和大小: 按页大小对齐,大块内存考虑大页。
- 及时同步和释放: 重要数据及时
msync,不用时 munmap。
- 利用现代硬件特性: NUMA、持久内存、IOMMU等。
掌握内存映射,意味着你能更高效地管理程序内存,设计出性能更优异的系统。如果你想深入探讨更多系统底层技术,欢迎在 云栈社区 与其他开发者交流。
 发表于 2026-1-12 07:26:30
|
查看: 152|
回复: 0
发表于 2026-1-12 07:26:30
|
查看: 152|
回复: 0
