看简历时,发现一个有趣的现象:几乎每位Java开发者都写着“精通高并发”、“熟悉分布式架构”。这两句话似乎成了技术简历的标配。
但真的掌握了吗?我们不妨模拟一个典型的面试场景:
面试官:“我们的系统现在面临百万级并发流量,后端有数十台服务器,你会如何应对?”
你(自信满满):“很简单,使用Nginx做负载均衡。”
面试官:“那么,Nginx底层具体使用了什么负载均衡算法?”
你(支支吾吾):“呃……轮询?”
面试官:“如果后端机器配置不统一怎么办?用户Session如何保持?扩容时导致缓存雪崩又该如何解决?”
你:(开始语塞,汗流浃背)……
如果你对负载均衡的理解仅停留在“轮询”层面,那么在高阶面试中很容易败下阵来。今天,我们就系统性地剖析负载均衡这层“洋葱”,从基础到进阶,彻底搞懂其核心算法与适用场景。
第一层:理想化的起点——轮询与随机
在最理想的情况下,假设后端所有服务器的配置和性能完全一致,我们可以采用最简单的分发策略。
- 轮询 (Round Robin):依次将每个新请求分配给下一台服务器,循环往复,实现绝对的平均分配。
- 随机 (Random):完全随机地将请求分发到任意一台服务器。
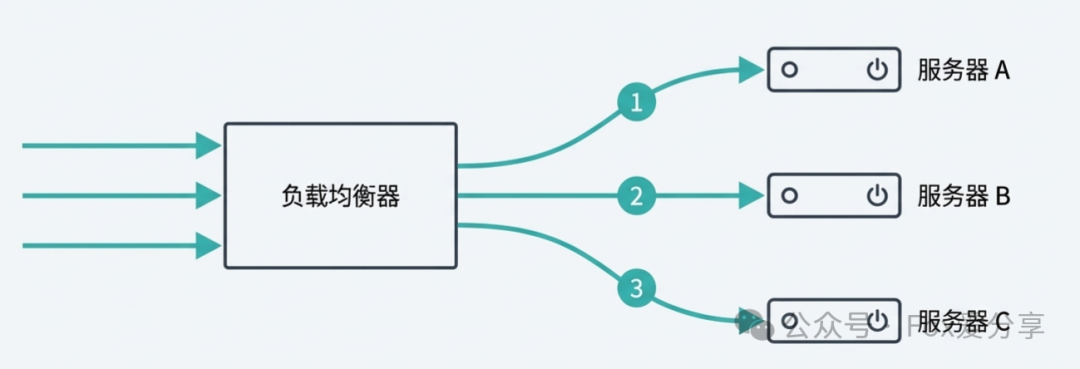
关键思考:这种策略看起来完美且公平,但它建立在“服务器同质化”的脆弱假设上。面试官的陷阱往往就在这里:“你确定线上所有服务器的配置和性能都是一样的吗?”
第二层:打破“大锅饭”——加权轮询
现实往往比理想骨感。一个典型的服务器集群中,可能同时存在新采购的“性能怪兽”(例如8核16G)和几年前的“老旧机型”(例如2核4G)。
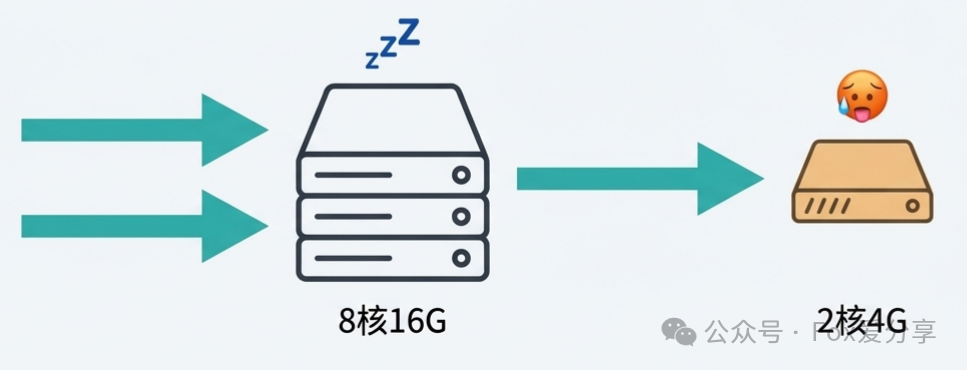
如果继续使用简单的轮询,结果就是高性能机器利用率不足,而低性能机器因不堪重负导致CPU 100%而宕机。这非但没有均衡负载,反而成了对弱者的“定点清除”。
解决方案:引入权重 (Weight) 的概念,实现“能者多劳”。以Nginx为例,其 weight 参数正是为此设计。
- 8核16G服务器:设置
weight = 4
- 2核4G服务器:设置
weight = 1
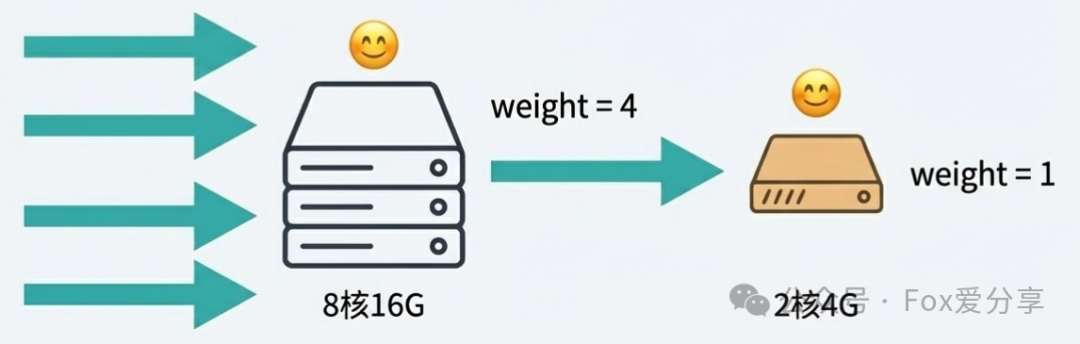
这样,在每5个请求中,高性能机器处理4个,低性能机器处理1个,实现了基于服务器能力的合理分配。这是构建稳定高并发系统的基本功。
第三层:用户体验的守护者——源地址哈希
解决了服务器性能不均的问题,面试官的下一个问题接踵而至:“用户的Session状态如何保持?”
设想一个场景:用户在服务器A登录,Session信息被创建并保存在A的内存或本地缓存中。当该用户的下一个请求被负载均衡器分发到了服务器B时,B服务器上并没有该用户的Session,系统会判定用户未登录,导致需要重新登录。
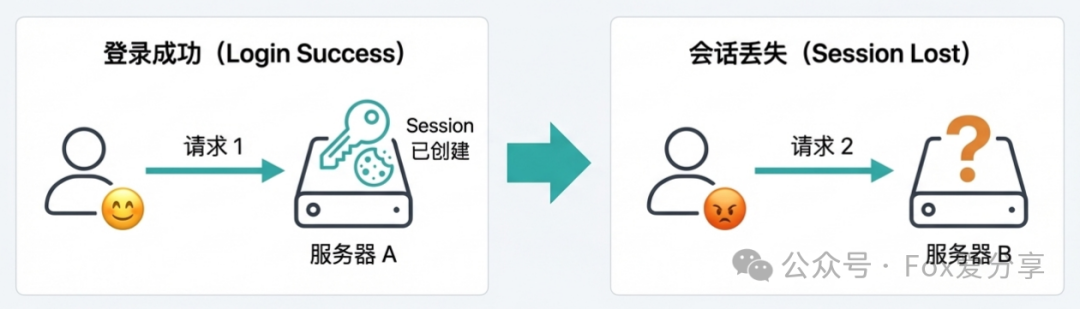
用户刚刚填完的长表单因此丢失,体验极差。这就是典型的会话丢失 (Session Lost) 问题。
解决方案:确保来自同一用户的请求,始终被定向到同一台后端服务器。源地址哈希 (IP Hash) 算法正是为此而生。
算法核心:hash(client_ip) % N (其中N为服务器总数)。
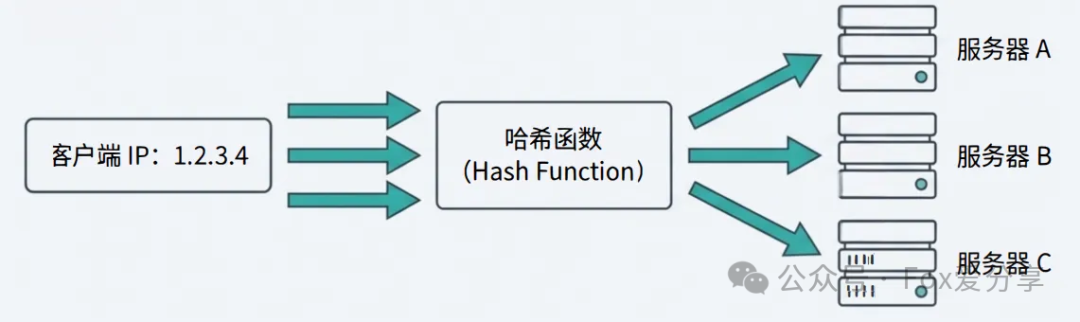
只要客户端的IP地址不变,哈希取模的结果就是固定的,该用户的所有请求就会被“粘滞”在特定的服务器上,从而完美保持会话状态。
第四层:规避系统性风险——一致性哈希
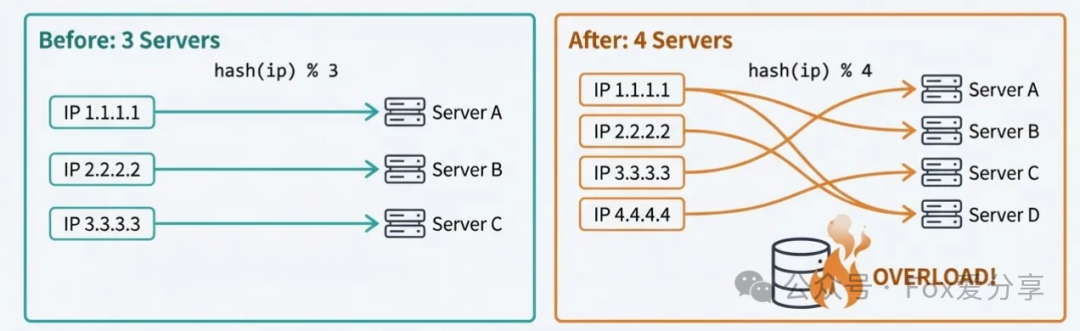
许多开发者认为IP Hash已是终极方案,但真正的挑战往往出现在系统变动时。
当业务增长需要扩容(增加服务器),或服务器故障需要缩容(减少服务器)时,回顾IP Hash公式:hash(client_ip) % N。分母N发生了变化,这意味着几乎所有IP的取模结果都会改变!
灾难性后果:原本存储在服务器A上的用户Session和本地缓存,在N变动后,其请求可能被路由到服务器B或C。这会导致全局性的Session失效和缓存击穿,海量请求直接涌向数据库,极易引发缓存雪崩,致使整个服务不可用。在分布式系统的运维中,这是一个需要极力避免的风险。
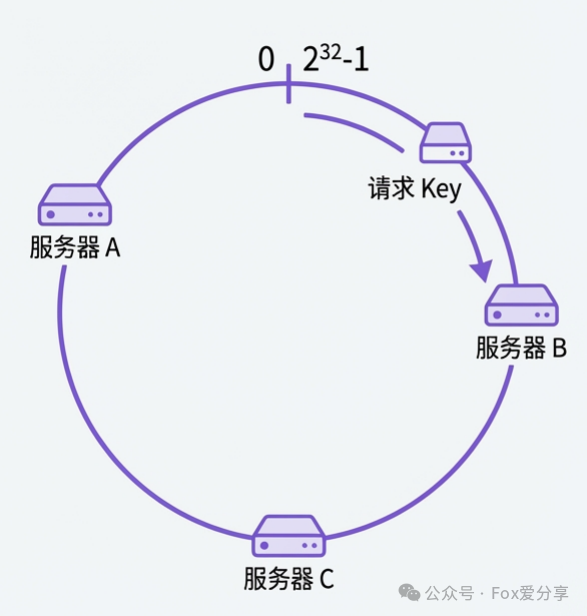
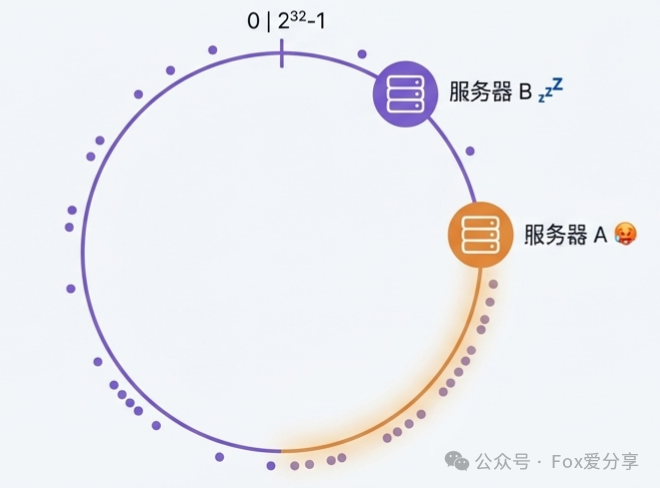
解决方案:一致性哈希 (Consistent Hashing)。它不再对服务器数量N取模,而是对一个固定的大数(例如2^32)取模。
- 构建哈希环:想象一个范围为
[0, 2^32-1] 的环形空间。
- 映射服务器节点:对每个服务器的唯一标识(如IP)进行哈希,将其映射到环上的某个位置。
- 路由请求:对请求的键(如用户ID或IP)进行哈希,同样映射到环上。然后从此位置出发,顺时针找到的第一个服务器节点,即为该请求的目标服务器。
其精髓在于:当增加或删除节点时,只会影响环上变动节点相邻一小部分区间的请求,而绝大部分请求的映射关系保持不变,从而极大地抑制了缓存雪崩的范围。
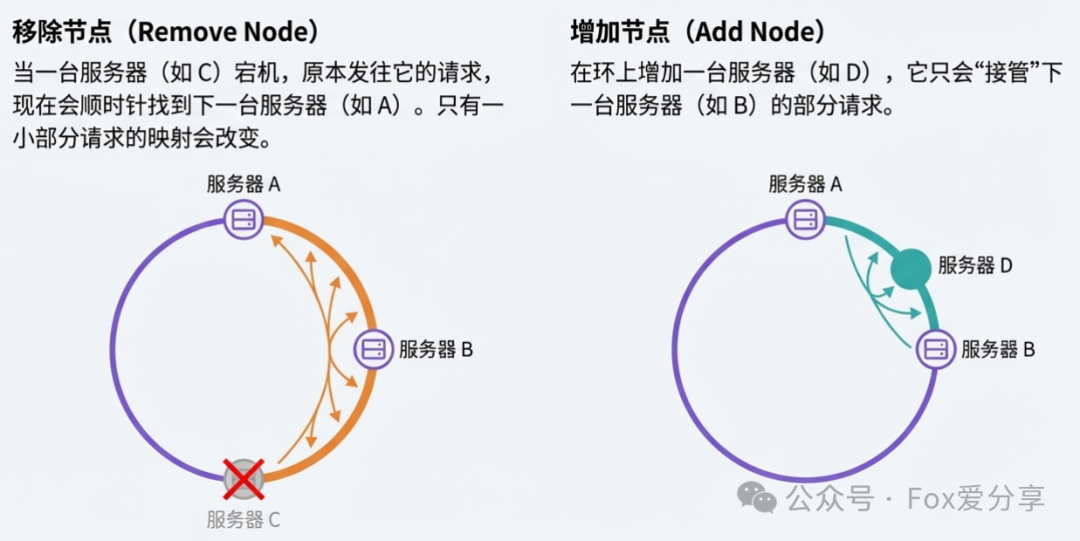
第五层:解决数据倾斜——虚拟节点
一致性哈希并非完美。如果集群规模很小,例如只有两台服务器A和B,且它们经过哈希后在环上的位置靠得很近,那么环上大部分区域(顺时针)的请求都会落到服务器A,导致严重的数据倾斜 (Data Skew),A服务器过载而B服务器闲置。
解决方案:引入虚拟节点 (Virtual Nodes)。不再将每个物理服务器映射到环上的一个点,而是为其生成大量的虚拟节点(例如,为服务器A生成1000个虚拟节点A1,A2,...,A1000),并将这些虚拟节点均匀地散布在哈希环上。
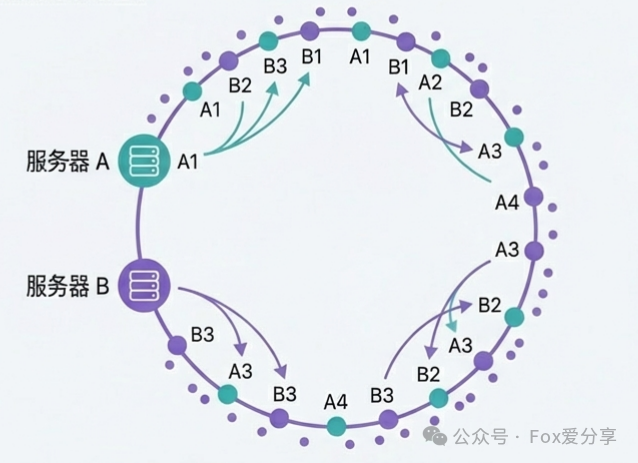
这样,即使物理节点很少,通过大量的虚拟节点也能使请求在环上得到近乎均匀的分布。Redis集群的槽位分配、Dubbo等框架的负载均衡都采用了这一思想。
进阶策略与总结
除了上述经典算法,在实际生产环境中,还有更智能的动态策略:
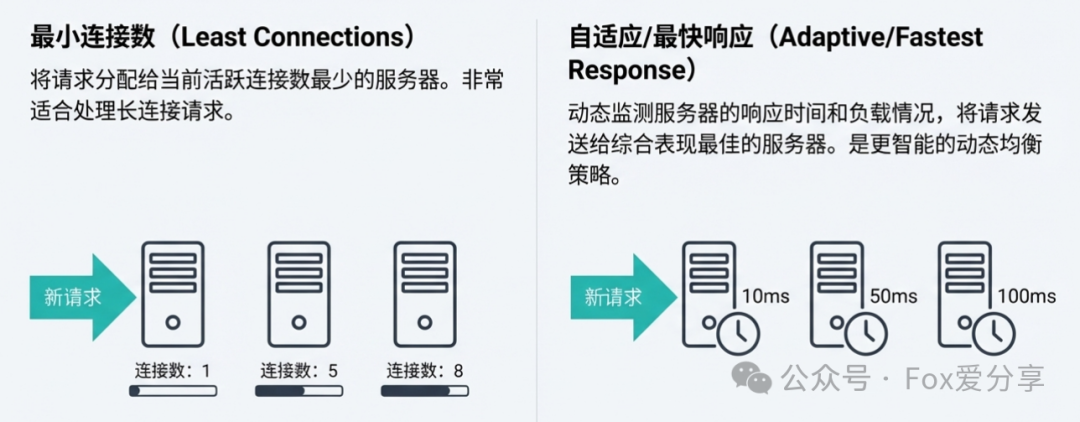
- 最小连接数 (Least Connections):将新请求发送给当前活跃连接数最少的服务器,非常适合处理长连接(如WebSocket)或请求处理耗时不均的场景。
- 自适应/最快响应 (Adaptive/Fastest Response):动态监测服务器的响应时间、负载率等指标,将请求分发给综合性能最佳的节点,是一种更智能的动态均衡策略。
面对面试官关于负载均衡的提问,不应只停留在概念背诵。你可以系统地阐述不同场景下的解决方案选择,展现你对技术深度的理解。下表可以作为你的知识脉络图:
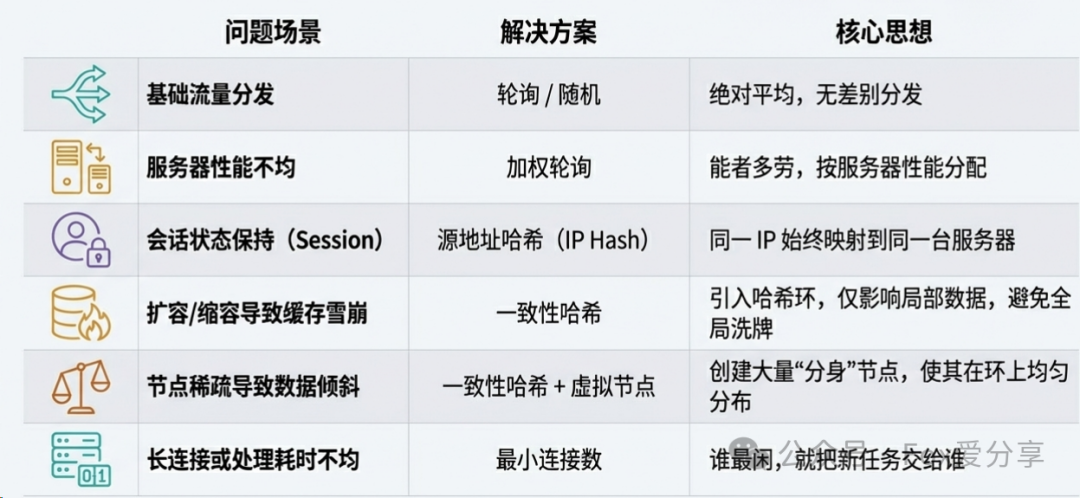
技术没有银弹,只有最适合场景的方案。掌握这些负载均衡算法的原理与取舍,是设计高可用、可扩展分布式架构的基石。希望这篇文章能帮助你更从容地应对相关技术讨论。如果你想与更多开发者交流这些实战心得,欢迎来云栈社区一起探讨。
 发表于 2026-1-12 08:12:23
|
查看: 184|
回复: 0
发表于 2026-1-12 08:12:23
|
查看: 184|
回复: 0
