Redis作为现代分布式系统的核心缓存与存储组件,其高性能是支撑海量请求的关键。本文将深入解析Redis如何利用四大核心技术,构建起能够从容应对百万级QPS(每秒查询率)的高性能架构。
1. 纯内存操作:极致速度的基石
Redis性能卓越的首要原因,是其将所有数据驻留在内存中,并辅以高效的内存管理策略。
内存操作绕过了传统数据库中最耗时的磁盘I/O环节,将访问延迟从毫秒级降至微秒甚至纳秒级。为什么内存决定了性能上限?传统数据库的瓶颈通常集中在以下几点:
从硬件层面看,内存(RAM)的读写延迟在100纳秒级别,而目前最快的SSD也在10-100微秒级别,两者性能相差数百至上千倍。这种数量级的速度差异,是Redis能够实现超高吞吐量的物理基础。

2. 多实例分片集群:水平扩展之道
单节点性能总有极限,因此,通过多实例分片与集群化部署来分散数据和请求压力,是支撑百万QPS的必经之路。
这种架构将负载分摊到多个节点或进程上,使得系统整体处理能力可以随着节点数量的增加而线性扩展,从而轻松突破单点瓶颈。一个简单的估算模型是:
1 个实例 ≈ 10 万 QPS
10 个实例 ≈ 100 万 QPS
常见的分片与集群方案包括:
- Redis Cluster:基于16384个哈希槽(Hash Slot)实现数据分片,具备去中心化和高可用特性。
- 代理分片:通过如Twemproxy或Codis这样的代理中间件,实现客户端无感知的分片路由。
3. I/O多路复用机制:高效处理海量连接
Redis采用基于事件驱动的I/O多路复用模型(在Linux下为epoll,在BSD下为kqueue),这是其能以单线程模型处理数万并发连接的核心。
这个机制的核心思想是:一个线程通过系统调用同时监控大量网络连接的文件描述符(fd),只有那些真正有数据到达的“活跃”连接才会被处理。这完美避免了为每个连接创建线程所带来的巨大内存开销和上下文切换成本。
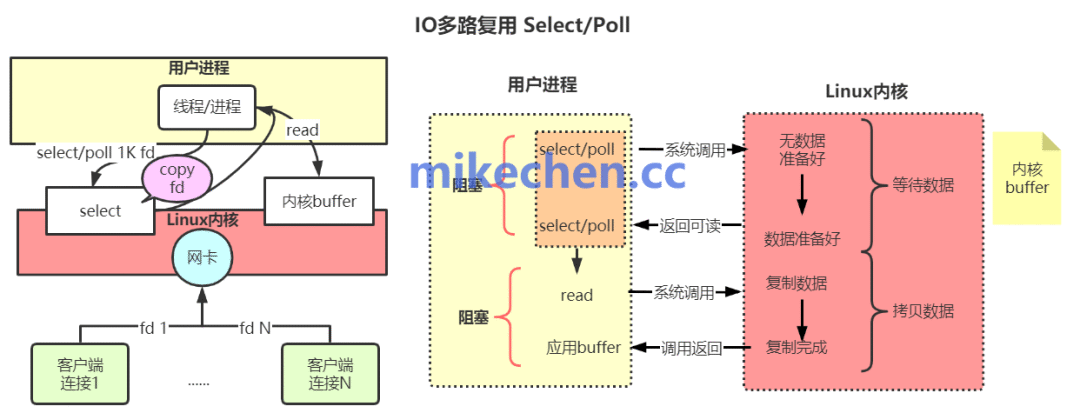
现代进化 (Threaded I/O):自Redis 6.0引入多线程I/O后,性能瓶颈得到了进一步优化。网络报文的读取、解析和写回等CPU密集型操作,可以由多个I/O线程并行处理;而核心的内存数据操作(命令执行)依然保持单线程,确保了原子性和极致速度。这种高并发处理模型,是现代网络编程的典范。
4. 精妙的数据结构:效率与空间的平衡
Redis的性能优势不仅源于内存和架构,更在于其对每种数据类型都精心设计了底层数据结构。它并非直接使用C语言的原生结构,而是针对不同场景做了深度优化。
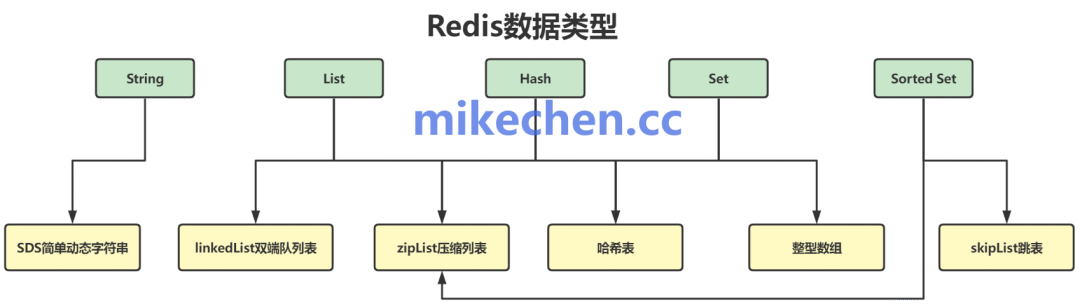
这些定制化结构带来了多重好处:
- SDS (Simple Dynamic String):预分配内存,获取字符串长度的时间复杂度为 O(1),并有效避免了缓冲区溢出和频繁的内存重分配。
- 跳表 (SkipList):使有序集合(ZSet)即使在数据量极大时,也能维持 O(log N) 的高效查询、插入和删除操作。
- 紧凑型结构 (ZipList / ListPack):当哈希、列表等元素数量较少时,采用连续内存存储。这不仅节省了内存,更重要的是大幅提高了CPU缓存(L1/L2 Cache)的命中率,减少了内存碎片,从微观层面提升了执行效率。
总结
综上所述,Redis能支撑百万级QPS并非依靠单一“黑科技”,而是纯内存操作、水平分片集群、高效的I/O多路复用以及精妙的数据结构四大核心技术协同作用的结果。理解这些底层原理,对于进行系统性能调优和分布式系统架构设计至关重要。希望本文的解析能为你带来启发,更多深度技术讨论,欢迎访问云栈社区进行交流。 |  发表于 2026-1-13 02:30:20
|
查看: 273|
回复: 0
发表于 2026-1-13 02:30:20
|
查看: 273|
回复: 0
