摘要
深度学习模型从训练环境迁移至实际芯片部署时,常因计算图优化、算子实现差异及量化误差等复合因素导致显著精度损失。本文系统阐述推理环境感知训练方法:在训练阶段对目标部署环境的完整计算图结构、算子实现细节及量化策略进行高保真模拟,实现训练与推理的比特级一致性。该方法超越传统量化感知训练,是一种以终为始的模型开发范式,能有效解决模型部署“最后一公里”的精度下降问题。
目录
- 问题深度剖析:部署精度损失的根源
- 推理环境感知训练的核心内涵
- 三大技术支柱详解
- 系统工程实施路径
- 实现推理环境感知训练的核心难点
- 总结
1. 问题深度剖析:部署精度损失的根源
深度学习模型在部署阶段的精度下降是多种因素系统性耦合的结果,而非单一原因所致。这些因素在部署流水线中相互叠加,形成误差累积的放大器。
1.1 误差来源的多维度分析
下表系统梳理了从训练到部署过程中主要的精度损失来源及其特征:
| 误差类别 |
具体表现 |
对精度的影响机制 |
传统缓解方法的局限 |
| 量化误差 |
FP32 转 INT8 的数值舍入与截断 |
1. 信息丢失与分布偏移 2. 动态范围与分辨率矛盾 3. 误差在网络中逐层传播累积 |
QAT 仅模拟理想量化,未考虑芯片具体实现 |
| 图优化误差 |
Conv-BN-ReLU 等算子融合 |
1. 改变计算顺序导致浮点舍入误差累积 2. 中间表示消除改变梯度传播路径 |
训练后优化导致模型未“见过”优化后结构 |
| 算子实现差异 |
同一算子在不同硬件/库中的细微差异 |
1. 浮点运算顺序不同(不满足结合律) 2. 特殊函数(如 exp)的近似算法不同 3. 并行归约与累加器使用差异 |
训练框架与推理引擎实现各自独立,缺乏一致性保证 |
| 预处理不一致 |
图像解码、缩放、归一化实现差异 |
输入数据分布的微小偏移被网络多层非线性放大 |
常被忽视,调试困难 |
1.2 误差累积的级联效应
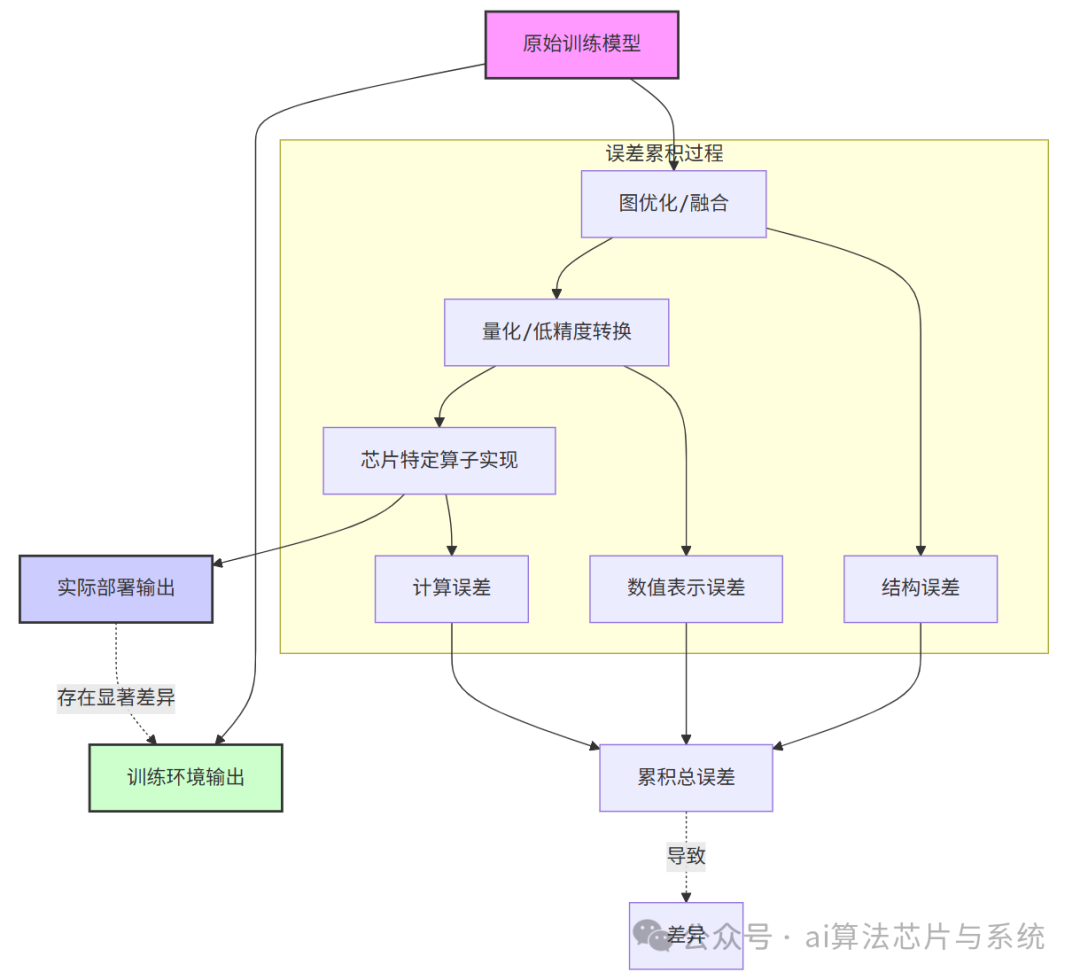
如图所示,误差在部署流水线的每个阶段不断引入并累积。更重要的是,这些误差源并非独立:图优化改变了计算图结构,进而影响量化节点的最佳插入位置和参数;量化后的低精度数值又会放大不同算子实现间的细微差异。这种耦合效应使得事后调试极为困难。
2. 推理环境感知训练的核心内涵
推理环境感知训练是一种系统性的解决方案,其核心理念可概括为:在模型训练阶段,创建一个与目标部署环境在功能与数值上完全等效的仿真环境,使模型在此环境中完成最终优化。
这类训练方法常用于对精度极其敏感的 人工智能 落地场景:你不是在“尽量接近”推理结果,而是在训练里就把推理链路“复刻出来”。
2.1 与传统方法的对比
| 对比维度 |
传统训练后优化 |
量化感知训练 |
推理环境感知训练 |
| 优化时机 |
训练完成后 |
训练中模拟量化 |
训练中模拟全链路 |
| 覆盖范围 |
单一/部分环节 |
主要针对量化 |
全链路:图优化 + 算子 + 量化 |
| 一致性保证 |
无 |
数值表示一致 |
比特级计算一致 |
| 工程复杂度 |
中(事后调试) |
中(需插入伪量化) |
高(需构建仿真环境) |
| 精度恢复潜力 |
有限 |
良好 |
最优 |
2.2 方法论的三大转变
- 从“训练后适应”到“训练中内嵌”:不再将部署优化视为训练后的独立步骤,而是将其作为训练框架的内在组成部分。
- 从“局部模拟”到“全栈仿真”:不仅模拟量化,还仿真芯片特定的计算图优化和算子实现细节。
- 从“功能正确”到“数值一致”:目标从“能运行出大致正确结果”提升为“与部署环境输出比特级匹配”。
3. 三大技术支柱详解
推理环境感知训练的有效性建立在三个相互支撑的技术支柱之上,下图展示了它们之间的协同关系:
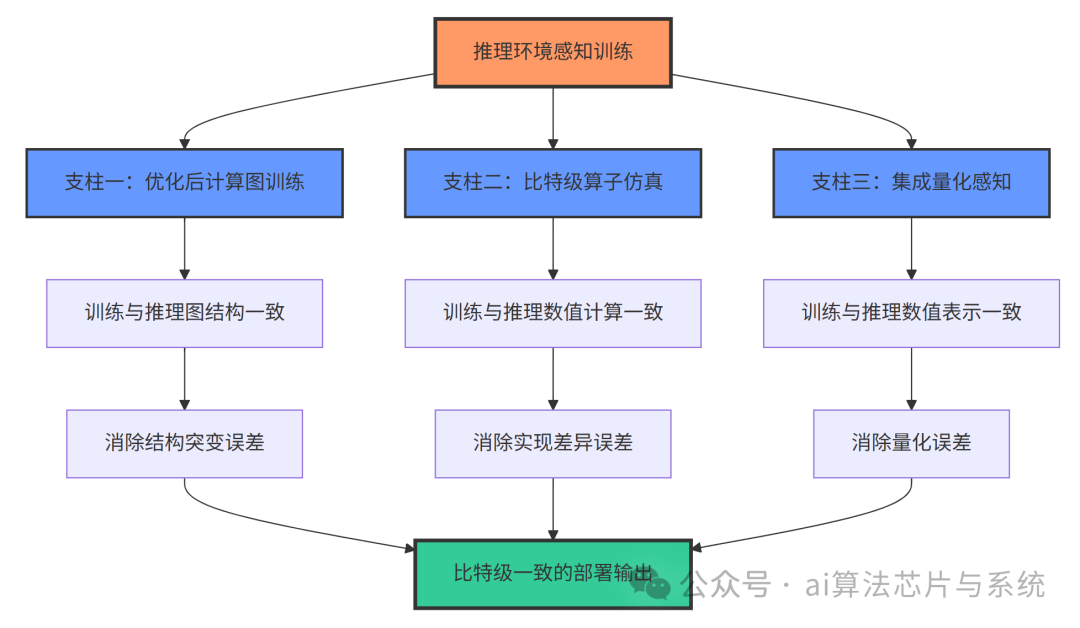
3.1 支柱一:基于优化后计算图的训练
这一支柱的核心是:让模型从始至终都在最终部署时的计算图结构上进行学习。
关键实施步骤:
-
提前分析与应用优化 Pass:
- 使用目标推理引擎(如 TensorRT、OpenVINO)对模型进行分析,提取其完整的优化策略,包括融合规则、常量折叠条件和子图替换模式。
- 在训练开始前,通过可微分的图转换技术(如 PyTorch FX),将同样的优化策略应用到训练计算图上。
-
可微分融合的实现:
- 例如,Conv-BN 融合在数学上是固定的线性变换:将 BN 的缩放、平移参数吸收进 Conv 的权重和偏置中。
- 在训练框架中实现此融合时,必须确保融合操作本身是可微的,允许梯度通过融合后的算子回传到原始参数。
-
优势:
- 消除结构切换冲击:模型权重直接学习在优化后结构上的协同工作方式,避免了从训练结构到部署结构的“切换成本”。
- 提升训练稳定性:反向传播直接在最终结构上进行,梯度流向与实际部署时一致,优化过程更加稳定。
3.2 支柱二:比特级一致的推理算子模拟
这是工程上最具挑战性但也是最关键的一环,目标是:完全复现目标芯片上算子的数值行为。
实现深度分析:
-
算子行为的精确逆向工程:
- 计算顺序:确定归约、卷积等操作在芯片上的具体循环顺序和并行策略。
- 数据类型转换点:明确在计算的哪个阶段进行 FP32 到 INT8 的转换,中间累加器使用何种精度。
- 特殊函数近似:获取芯片库中
exp、log、sigmoid 等函数的低精度近似多项式或查找表实现。
- 舍入模式:确认是向零舍入、就近舍入还是其他硬件特定模式。
-
仿真模式架构:
- 双前向模式:训练系统需支持两种前向传播模式:“标准训练模式”(使用框架原生高效算子)和“仿真模式”(使用与芯片一致的算子)。
- 梯度流设计:在“仿真模式”下进行前向传播以计算损失,但反向传播可使用标准算子(或经过验证的近似)来计算梯度,以平衡精确性与训练效率。
一致性验证协议:在完成仿真算子实现后,必须进行严格的数值验证:
- 准备一组代表性输入数据。
- 分别在仿真算子和目标芯片上执行前向计算。
- 逐层、逐张量比较输出,确保最大绝对误差(MAE)和均方误差(MSE)低于可接受阈值(如 1e-6 量级)。
3.3 支柱三:与量化感知训练的深度集成
此支柱要求将量化模拟无缝嵌入到已优化和仿真的计算环境中。
集成的关键方面:
| 量化特性 |
传统 QAT 的典型处理 |
推理环境感知训练的集成要求 |
| 量化粒度 |
通常逐层(每层一套参数) |
支持逐通道量化(每通道一套参数) |
| 对称性 |
默认对称量化 |
支持非对称量化(含零点 zero-point) |
| 校准方法 |
最大最小值、移动平均 |
与芯片校准算法一致(如熵校准、百分位数校准) |
| 混合精度 |
人工预设或简单启发式 |
与部署工具链的自动混合精度策略协同 |
| 伪量化节点位置 |
基于原始图结构 |
基于优化后图结构插入 |
校准过程的前移:在推理环境感知训练中,量化参数(scale 和 zero-point)不应仅通过简单的统计后处理获得,而应:
- 在“仿真模式”下,使用来自实际部署场景的数据分布。
- 运行完整的校准算法(与目标芯片一致)。
- 将得到的量化参数作为可微训练的一部分或固定前置条件。
4. 系统工程实施路径
实施推理环境感知训练需要严谨的工程流程,下图概括了从准备到验证的完整工作流:
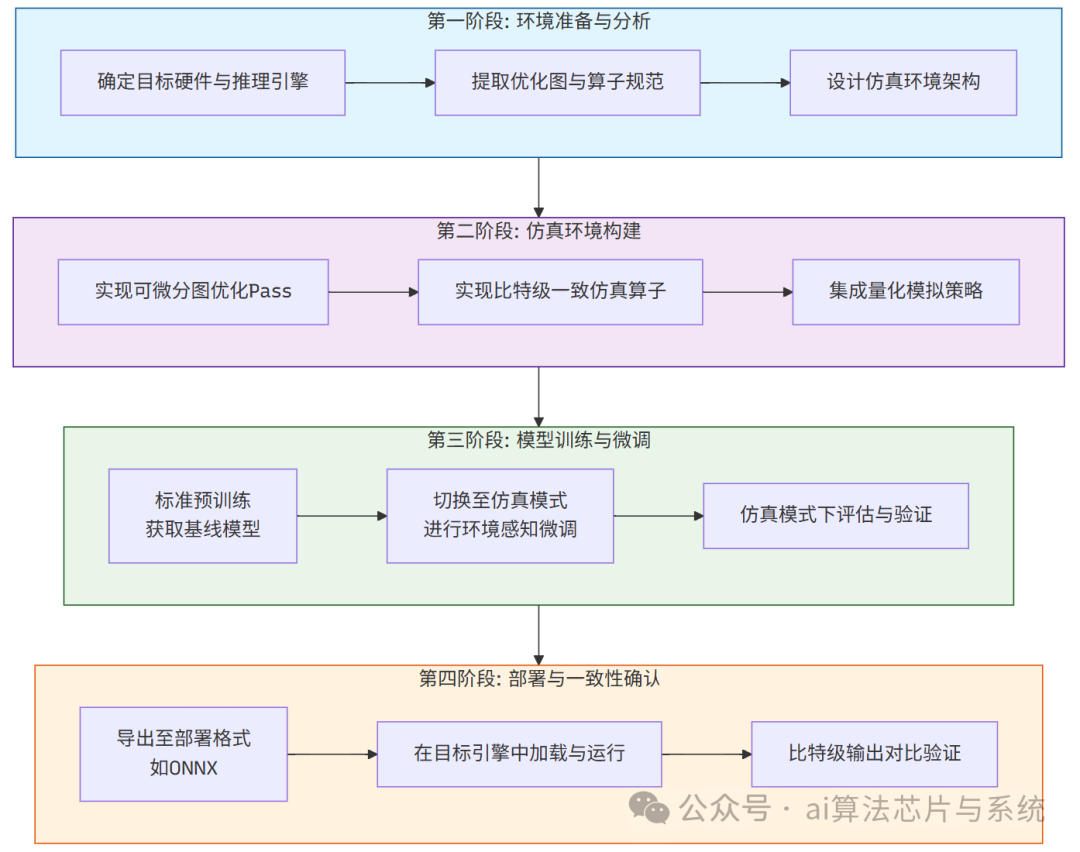
4.1 分阶段实施详解
阶段一:环境准备与分析(约占总工作量 30%)
此阶段是基础,决定了后续所有工作的方向。
- 目标栈锁定:明确芯片型号、推理引擎版本、驱动版本。版本一致性至关重要,不同版本间行为可能有差异。
- 优化策略提取:使用引擎提供的工具(如
trtexec for TensorRT)或 API,深入分析引擎对模型所做的每一处优化,并记录所有融合规则和条件。
- 算子基准测试:编写微基准测试程序,量化关键算子在目标平台上的数值行为,为后续仿真提供黄金标准。
阶段二:仿真环境构建(约占总工作量 40%)
这是技术核心,需要深厚的框架底层知识和数值计算知识。
- 可微分图转换框架选择:PyTorch FX 是当前最灵活的选择,允许对计算图进行细粒度干预和转换。
- 仿真算子的实现策略:
- 纯 Python 实现:适用于验证概念和简单算子,但执行慢。
- C++/CUDA 扩展:对于性能关键的算子(如卷积),必须实现与芯片库同等效率的仿真版本,这是最大的工程挑战。
- 量化模拟器的扩展:修改现有 QAT 框架(如
torch.ao.quantization),使其支持目标引擎特有的量化特性。
阶段三:模型训练与微调(约占总工作量 20%)
采用两阶段训练策略以平衡效率与效果:
- 标准预训练:使用标准的高精度算子和原始图结构,在目标任务上训练至收敛,获得高质量的基线模型。
- 环境感知微调:
- 加载预训练权重。
- 将模型切换到“仿真模式”(一键切换是良好设计的标志)。
- 使用更小的学习率(通常为预训练的 1/5 到 1/10),更少的训练轮数(通常为预训练的 1/10 到 1/5)进行微调。
- 数据预处理流水线必须与部署环境完全一致。
阶段四:部署与一致性确认(约占总工作量 10%)
- 导出与转换:将微调后的模型(包含所有量化参数)导出为中间表示(如 ONNX),并使用目标推理引擎的工具链转换为最终部署格式。
- 系统性验证:
- 输出层对比:比较引擎输出与训练时仿真模式输出的最终结果差异。
- 中间层对比(可选但推荐):在可能的情况下,比较关键中间层的输出,以便快速定位不一致的源头。
- 统计指标:记录平均绝对误差、相关系数等量化指标,而不仅是目测检查。
若你的训练/部署链路运行在容器、集群或多环境切换中,建议把版本锁定、驱动一致性、镜像追溯纳入 云原生/IaaS 的工程规范,否则“同一份模型在不同机器上结果不一致”的问题会被进一步放大。
5. 实现推理环境感知训练的核心难点
实现推理环境感知训练在工程上面临一系列深刻挑战,其本质在于弥合为训练优化的动态框架与为推理优化的静态引擎之间的结构性鸿沟。以下是四大核心难点。
难点一:图优化 Pass 的精确对齐与逆向工程
问题实质:训练框架(如 PyTorch)通常按算子粒度动态执行,而推理引擎(如 TensorRT、TensorFlow Lite)会对计算图进行全局分析与改写。二者优化策略的出发点(训练速度 vs. 推理速度与功耗)和实现完全不同。
具体挑战:
- 闭源引擎的“黑盒”优化:对于闭源推理引擎,其内部的算子融合规则、子图替换条件、常量折叠策略均不透明。开发者只能通过输入/输出比对进行逆向工程,通过大量实验推测其优化规则,过程繁琐且难以保证完备。
- 可微分化的要求:训练框架中的融合 Pass 必须是可微分的,以确保梯度能正确回传至融合前的原始参数。例如,将卷积(Conv)、批归一化(BN)和激活函数(ReLU)融合为单个算子时,必须确保融合操作的数学变换在反向传播中是可导的,这要求自定义融合算子的实现。
难点二:比特级一致算子仿真的工程浩大
问题实质:在训练框架中复现推理芯片算子的精确数值行为,是一项需要深入硬件指令集和数值计算库的底层工作。
具体挑战:
- 计算顺序与精度的复现:推理芯片为追求极致性能,会使用特定的指令集(如 SIMD)和并行归约顺序,导致浮点运算结果与 CPU 或 GPU 训练环境存在不可避免的舍入误差。完全模拟这些行为,可能需要在训练框架中重新实现一整套对应芯片的底层计算内核。
- 特殊函数的低精度近似:芯片上对
exp、log、sigmoid 等函数常采用低精度近似(如查找表或分段多项式)。在训练框架中模拟这些非标准、有时甚至是非光滑的近似函数,可能引入数值不稳定,影响训练收敛。
- 性能与保真度的权衡:高保真的仿真算子通常以牺牲计算速度为代价。在训练中全程使用仿真算子,可能使训练时间增长数倍至数十倍,难以承受。
难点三:量化策略的深度耦合与模拟
问题实质:量化感知训练(QAT)与图优化、芯片算子是深度耦合的,而非独立模块。
具体挑战:
- 量化节点位置的动态性:图优化(如算子融合)会改变计算图结构,导致伪量化节点的插入位置必须动态调整。例如,在 Conv-BN 融合后,量化节点应插入在融合算子之前/后,而非原始 Conv 或 BN 的旁边。
- 复杂量化模式的模拟:推理芯片可能支持混合精度量化(如部分层 INT8、部分层 FP16)、非对称量化或逐通道量化。在训练框架中模拟这种复杂、异构的量化策略,需要大幅扩展现有 QAT 框架的配置和运行时管理逻辑。
- 校准过程的一致性:芯片的量化校准算法(如熵校准、百分位校准)可能未在训练框架中实现。需要将其移植并集成至训练循环,确保量化参数从与推理环境一致的激活分布中产生。
难点四:工程路径的选择与资源困境
面对上述难点,团队通常面临三条工程路径的艰难抉择,其核心权衡如下表所示:
| 工程路径 |
核心思路 |
优势 |
劣势与风险 |
| 扩展现有开源框架 |
修改 PyTorch/TensorFlow,添加自定义 Pass、算子、量化模拟器 |
生态完善,可利用自动微分等基础设施 |
需深入框架内核,改动复杂,框架升级可能导致兼容性问题 |
| 构建轻量专用训练器 |
基于 ONNX Runtime Training 等,构建仅支持微调的小型框架 |
目标聚焦,与 ONNX 推理生态对齐较好 |
功能有限,可能无法支持复杂模型结构或训练技巧 |
| 重实现训练框架 |
针对特定芯片,从头实现一套精简的、与推理引擎同源的训练框架 |
可实现最大程度的比特级一致 |
工程成本极高,需实现完整的优化器、分布式训练等,不切实际 |
实现推理环境感知训练的本质,是在精度、效率、工程成本之间寻找最优点。成功的关键在于精确识别自身业务的核心瓶颈(是某一类算子误差过大,还是量化损失主导?),然后集中资源进行针对性、渐进式的改进,而非追求一次性的完美解决方案。
6. 总结
推理环境感知训练代表了一种更为严谨和彻底的模型部署精度保障方法。它通过将训练环境与部署环境在结构、数值和表示三个维度上对齐,从根本上减少了精度损失的不确定性。
核心价值:
- 可预测的部署结果:消除了从训练到部署的“黑盒”转换过程,使得部署精度变得高度可预测。
- 降低调试成本:通过前期系统性的对齐,避免了后期耗时的、试错式的精度调试。
- 释放硬件潜力:让开发者能够更自信地使用芯片提供的所有优化(如激进的算子融合、低精度计算),而无需因精度担忧而保守。
适用场景:
- 对精度损失极为敏感的应用(如自动驾驶感知、医疗影像分析)。
- 使用复杂或非标准模型架构、容易受到优化影响的应用。
- 部署在具有独特计算特性硬件(如特定 NPU、FPGA)上的场景。
实施建议:尽管推理环境感知训练需要显著的工程投入,但采用渐进式策略可以降低风险:首先在最关键的模型和最容易出错的环节(如自定义算子、特殊融合)实施,然后逐步扩展到全模型。对于高度标准化的模型(如 ResNet 分类网络)和成熟部署组合(如 PyTorch -> TensorRT on NVIDIA GPU),标准 QAT 可能已足够。但对于前沿模型和边缘硬件,推理环境感知训练是确保部署成功的关键技术保障。
如需更多推理落地、量化与部署排障的资料,可在 云栈社区 的 技术文档 板块延伸阅读。
 发表于 2026-1-13 18:56:26
|
查看: 158|
回复: 0
发表于 2026-1-13 18:56:26
|
查看: 158|
回复: 0
