DeepSeek 于 12 日晚发布新论文《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》(基于可扩展查找的条件记忆:大型语言模型稀疏性的新维度)。
论文地址:https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf
该论文为北京大学与 DeepSeek 共同完成,合著作者署名中出现梁文锋。论文提出条件记忆(conditional memory),通过引入可扩展的查找记忆结构,在等参数、等算力条件下显著提升模型在知识调用、推理、代码、数学等任务上的表现。同时,DeepSeek 开源了相关的 Engram 记忆模块。
01 动机
当前的大语言模型需要依靠计算来模拟知识检索,这导致模型需要在早期层中消耗大量计算资源来重建静态知识,从而浪费了宝贵的模型深度和计算能力。
针对这个问题,论文提出了一种实时知识检索的方法,来减轻模型依靠计算来模拟知识检索产生的负担。
02 实现
a. 整体方法介绍
论文在原有 Transformer 架构上增加了一个 Engram 模块,其核心是可学习的知识嵌入,以及相应的知识检索和上下文融合机制。
给定当前序列,在预测下一个 token 前,使用当前序列的最后几个 gram 作为查询,这几个 gram 经过多个哈希头进行哈希计算之后,检索出对应的知识嵌入向量。这些被检索到的知识嵌入向量被动态地融合进上下文当中。
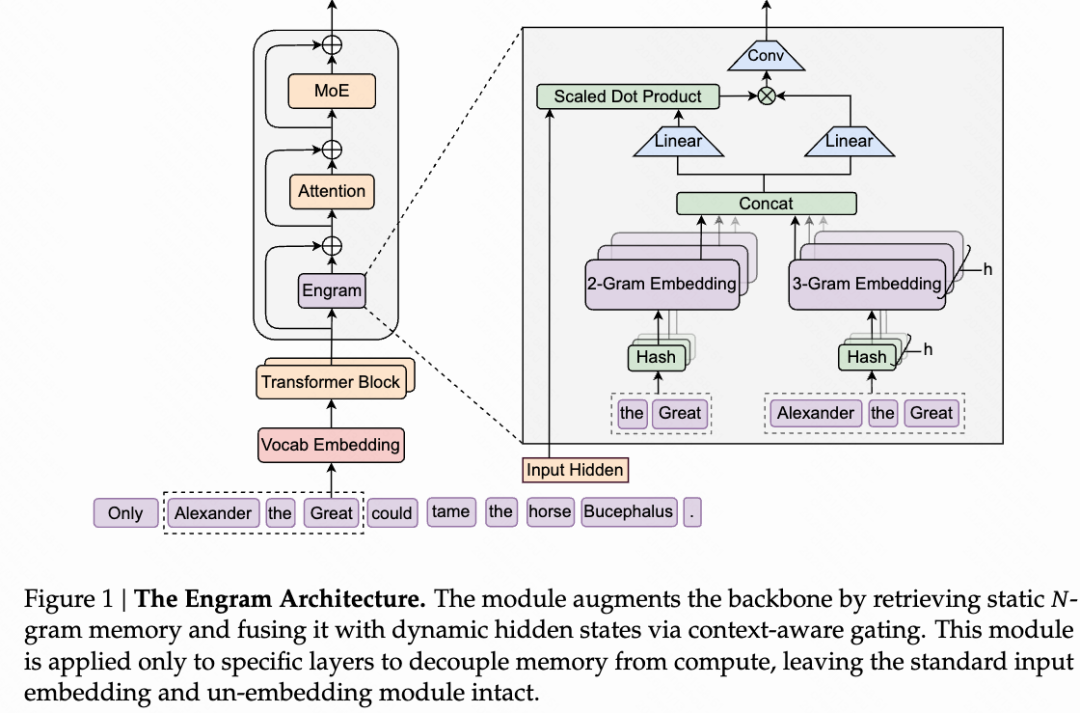
b. 具体实现细节
- 给定上下文,例如“2019 年美国纽约市”
- 提取最后的 2-gram(当然,也可以是 3-gram),也就是“美国 纽约市”。将 N-gram 中的 token 映射到规范化的 ID。
- 使用 k 个 hash 函数,将“美国 纽约市”映射为 k 个整数序号。
- 依据这 k 个整数序号,从 k 个知识嵌入向量表中检索得到 k 个知识嵌入向量。
- 将检索得到 k 个知识嵌入向量拼接为一个长向量。
- 使用门控方法调节知识向量的强度。

- 对知识向量进行卷积。

- 将知识向量加入上下文。

03 实验
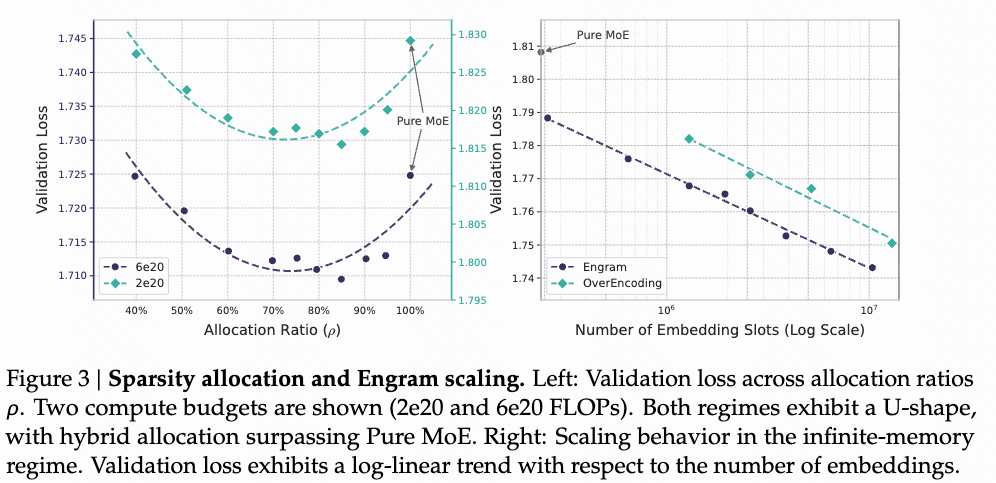
a. 知识嵌入与模型主参数之间参数量的平衡
左图:当总参数量一定时,知识嵌入-主模型参数分配比例与验证损失的关系。
右图:模型主参数不变,扩增知识嵌入参数量,可以显著降低验证损失。(无痛 scaling)
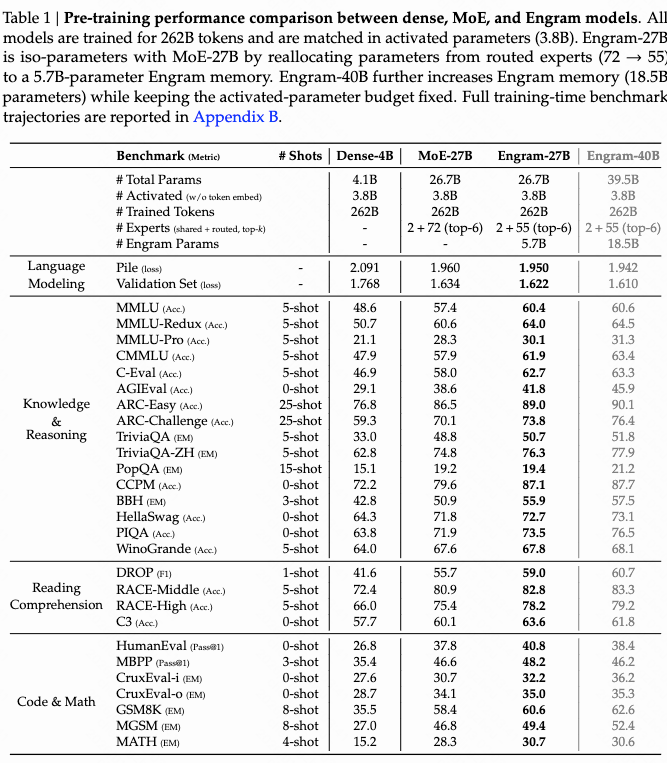
b. benchmark 测试结果
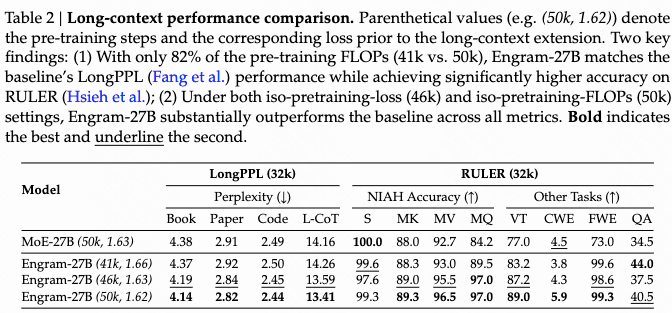
04 分析性实验
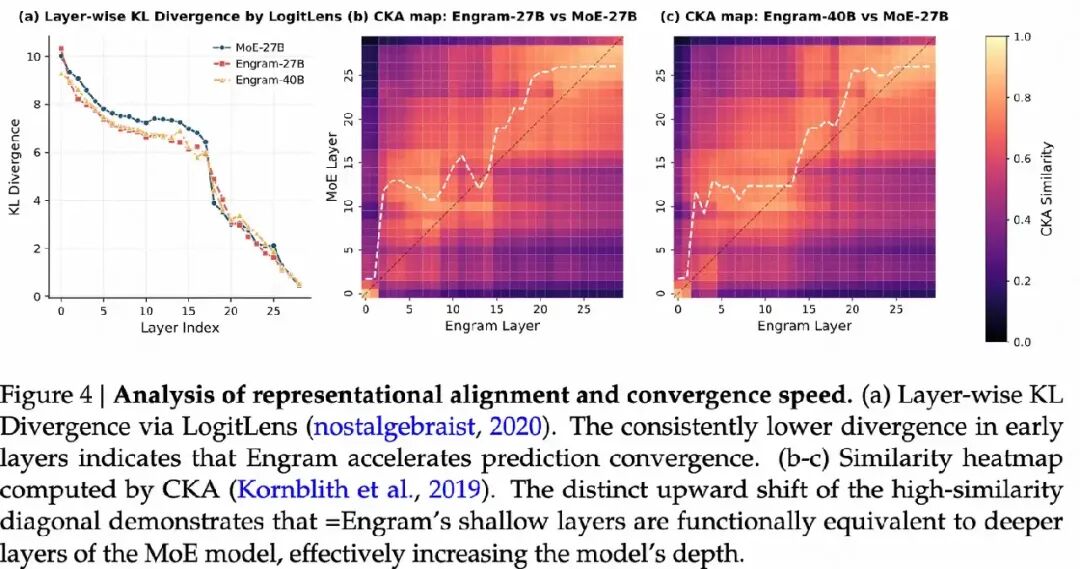
1. Engram 是否增加了模型的有效深度?
加速预测收敛:
- 分析方法: 使用 LogitLens 工具,通过计算每一层隐藏状态与最终输出分布之间的 Kullback-Leibler 散度(KL 散度),来衡量每一层的预测置信度。
- 结果: Engram 模型在早期层的 KL 散度显著低于 MoE 基线模型,表明 Engram 模型能够更快地完成特征组合,更早地达到高置信度的预测结果。
- 结论: Engram 通过显式的知识检索能力,减少了模型早期阶段的计算步骤,从而加速了预测收敛。
表示对齐与有效深度:
- 分析方法: 使用 Centered Kernel Alignment(CKA)分析 Engram 模型与 MoE 模型各层之间的表示结构相似性。
- 结果: Engram 模型的早期层(如第 5 层)的表示与 MoE 模型的深层(如第 12 层)表示高度相似,呈现出明显的“向上偏移”。
- 结论: Engram 通过显式的知识检索,跳过了早期的静态特征组合任务,使得模型在更浅的层次上就能达到与 MoE 模型深层相似的表示,从而有效地增加了模型的有效深度。
2. 结构消融与层敏感性
内存注入的最佳位置:
- 实验设计: 在 3B MoE 模型中插入 Engram 模块,固定参数预算(1.6B),改变 Engram 的插入位置(从第 1 层到第 12 层)。
- 结果: Engram 在第 2 层插入时表现最佳(验证损失最低)。将 Engram 分成两个模块分别插入第 2 层和第 6 层时,性能进一步提升。
- 结论: 早期注入 Engram 可以更有效地卸载静态模式的重建任务,但过早注入会导致上下文信息不足,影响门控机制的精度。因此,最佳位置需要在早期干预和上下文信息之间进行权衡。
关键组件的重要性:
- 实验设计: 在参考配置基础上,逐个移除 Engram 的关键组件(如多分支融合、上下文感知门控、分词器压缩等)。
- 结果: 移除这些组件会导致显著的性能下降,表明这些组件对 Engram 的有效性至关重要。
- 结论: 多分支融合、上下文感知门控和分词器压缩是 Engram 模型的关键设计,它们共同提升了模型的性能。
敏感性分析:
- 实验设计: 在推理过程中完全抑制 Engram 模块的输出,观察模型在不同任务上的表现。
- 结果: 在事实知识任务中,性能大幅下降(如 TriviaQA 只保留 29% 的性能),而在阅读理解任务中,性能几乎不受影响(如 C3 保留了 93% 的性能)。
- 结论: Engram 主要负责存储和检索事实知识,而阅读理解任务更多依赖于模型的注意力机制和上下文理解能力。
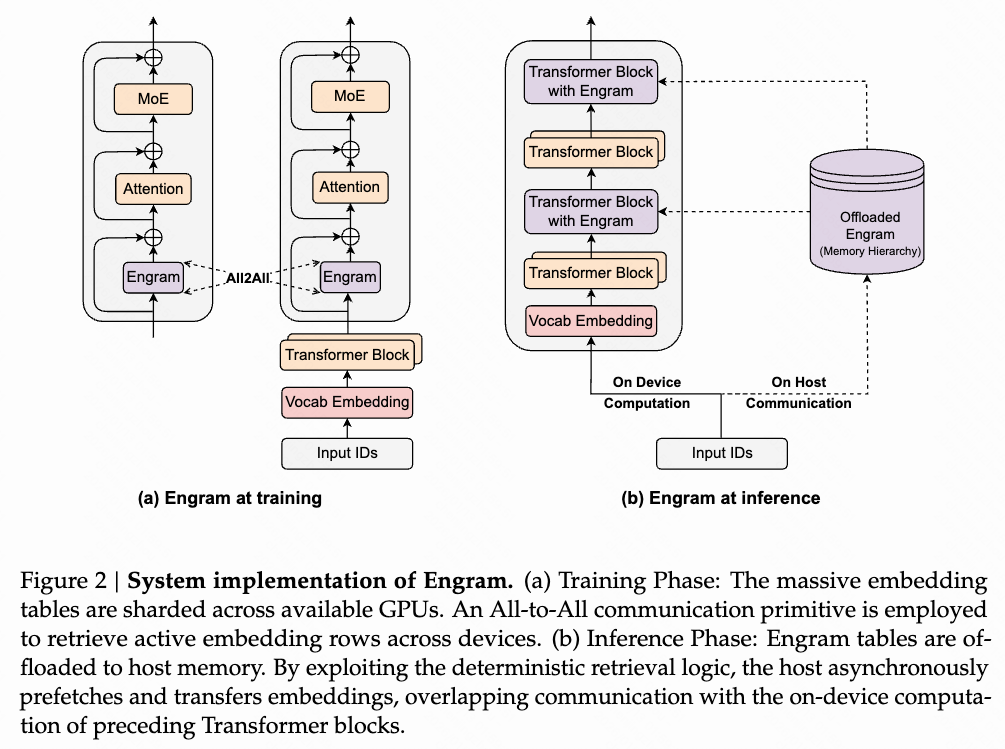
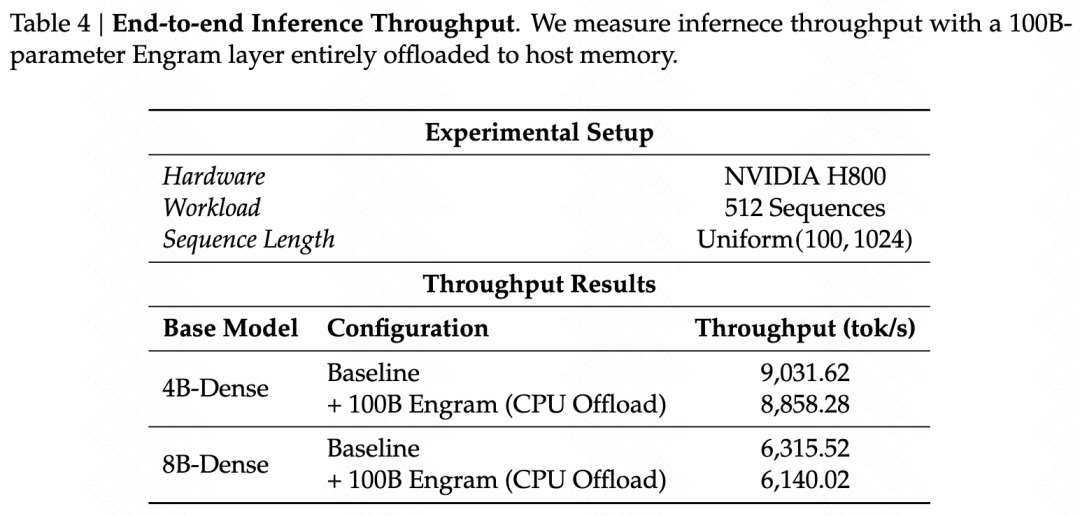
系统效率:
- 实验设计: 将一个 100B 参数的 Engram 层完全卸载到主机内存,在推理过程中异步预取嵌入向量,观察对吞吐量的影响。
- 结果: 在 4B 和 8B 模型中,吞吐量下降分别仅为 2% 和 2.8%,表明 Engram 的内存访问对推理效率的影响微乎其微。
- 结论: Engram 的确定性寻址机制允许在推理过程中高效地预取和传输嵌入向量,即使将大量参数存储在主机内存中,也不会显著影响推理速度。
案例研究:门控可视化
- 分析方法: 可视化 Engram 模型在不同样本上的门控标量(α),观察其对静态模式的激活情况。
- 结果: Engram 在识别多词实体(如“Alexander the Great”)和固定短语(如“By the way”)时表现出强烈的激活,表明其成功地识别并检索了这些静态模式。
- 结论: Engram 的上下文感知门控机制能够动态地调节检索到的静态知识与动态特征的融合,有效减轻了 Transformer 主干网络的负担。

05 其他值得关注的点
论文在训练中使用了 Muon 优化器。
作者:Spectre
来源:https://zhuanlan.zhihu.com/p/1994229955983324990
|  发表于 2026-1-14 01:36:11
|
查看: 225|
回复: 0
发表于 2026-1-14 01:36:11
|
查看: 225|
回复: 0
