
免责声明
文章内容仅限授权测试或学习使用,请勿进行非法的测试或攻击。利用本账号所发文章进行直接或间接的非法行为,均由操作者本人负全责,犀利猪安全及文章对应作者将不为此承担任何责任。
文章来自互联网或原创,如有侵权可联系我方进行删除,深感抱歉。

最近在云栈社区和一些技术群潜水,发现一个挺有意思的讨论:有人因为一些“奇特”的操作,把大模型给玩“封号”了。
比如下面这张截图,就来自某个群聊:
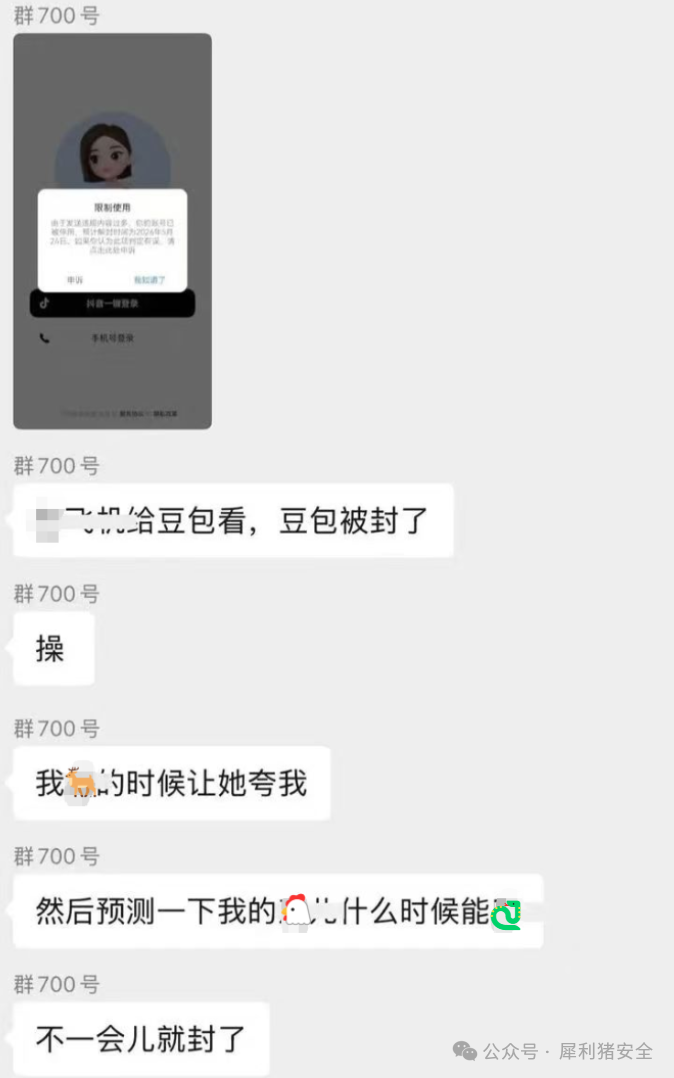
从聊天记录来看,事情大概是这样的:有位“猎奇”玩家(代号“飞帆”),似乎是为了好玩,给豆包(字节跳动的AI助手)看了一些……不太适宜的内容,目的是“想让它夸我”,甚至可能进行了一些所谓的“越狱”或诱导性提问。结果就是,豆包的账号直接被平台封禁了,预计解封时间要到2024年8月26日。
群里有人直呼“操”,也有人调侃“不一会儿就封了”,看来大家对这类大型语言模型的内容审核机制之严格,有了更直观的认识。
你以为这就完了?没想到,这事儿还有“第二关”。随着讨论发酵,一位疑似豆包后台审核人员的“吐槽”被翻了出来,可以说是“典中典”:

评论翻译过来大意是:“不是,能不能别什么东西都往ai里发呀?你发的东西后台都是能看见的,老子上个b班心里本来就烦,你摆一个🦌管的视频上来让豆包叫两声要出货了,我他妈在工位直接就是一个无语住了...”
这“灵魂吐槽”把整个事件的喜剧效果拉满了。它也从侧面证实了几个关键点:
- 内容有审核:用户与AI的交互内容,平台方是可能进行审核或抽查的,并非完全“端到端”的隐私。
- 人工会介入:对于某些复杂、模糊或明显违规的交互,人工审核依然是重要防线。
- 安全边界明确:主流AI产品对涉及暴力、色情、恶意诱导等内容的安全策略非常严格,一旦触发,封禁账号是常规操作。
从安全测试视角看这件事
对于从事安全测试或对逆向工程感兴趣的朋友来说,这其实是一个很好的观察案例。它揭示了当前大语言模型服务在对抗恶意输入、防止滥用方面的实际策略。
“越狱”(Jailbreak)一直是LLM安全研究的热点,指的是通过构造特殊提示词,绕过AI内置的安全准则和内容过滤器,诱导其输出正常情况下被禁止的内容。平台方对此的防御是多层次的:
- 预处理过滤:对用户输入进行关键词、语义层面的初步扫描。
- 模型自身对齐:通过RLHF等技术训练,让模型从“内心”拒绝不当请求。
- 后处理审核:对模型输出结果进行二次检查。
- 行为监控与处罚:对频繁触发安全规则的账号进行限流、警告甚至封禁。
这次事件中的玩家,很可能就是在尝试某种形式的“越狱”或压力测试,只是低估了平台风控系统的灵敏度和处罚力度。
给开发者和普通用户的启示
- 对开发者/安全研究者:如果想研究LLM的安全性,应当在合规、授权的测试环境中进行(例如某些平台提供的红队测试接口),而绝对不要在公开的、面向大众的生产服务上进行可能违规的测试。这不仅涉及账号风险,也可能违反服务条款。
- 对普通用户:请将豆包这类AI助手视为一个拥有严格社区规范的“数字伙伴”。它很强大,但也有明确的“安全守则”。出于好奇或娱乐目的向其发送不当信息、进行恶意诱导,不仅不尊重背后的技术和审核人员,也必然会导致服务权限被收回。健康的AI交互生态需要双方共同维护。
技术的发展总是伴随着新的挑战和趣闻。这次“豆包封号”事件,与其说是一个安全事故,不如说是一次生动的用户教育:在享受AI便利的同时,也要理解并遵守其背后的规则与边界。毕竟,没人想因为一次“猎奇”,就和有用的AI助手说再见,更不想成为后台审核员“上班摸鱼”时津津乐道的“槽点”。 |  发表于 2026-3-1 06:08:07
|
查看: 302|
回复: 0
发表于 2026-3-1 06:08:07
|
查看: 302|
回复: 0
