服务器日志里每隔几小时就出现同样的报错,难以复现却真实存在。以前想在 Mac 上运行大型语言模型,下载完 Qwen 27B 或 35B 后,内存瞬间告急,系统开始疯狂使用交换空间,电脑卡顿得如同老旧机器重启。许多人以为 Apple Silicon 的统一内存架构足以应对,但现实是,一旦触及 16GB 的物理内存边界,就会立刻卡壳。
现在情况不同了。
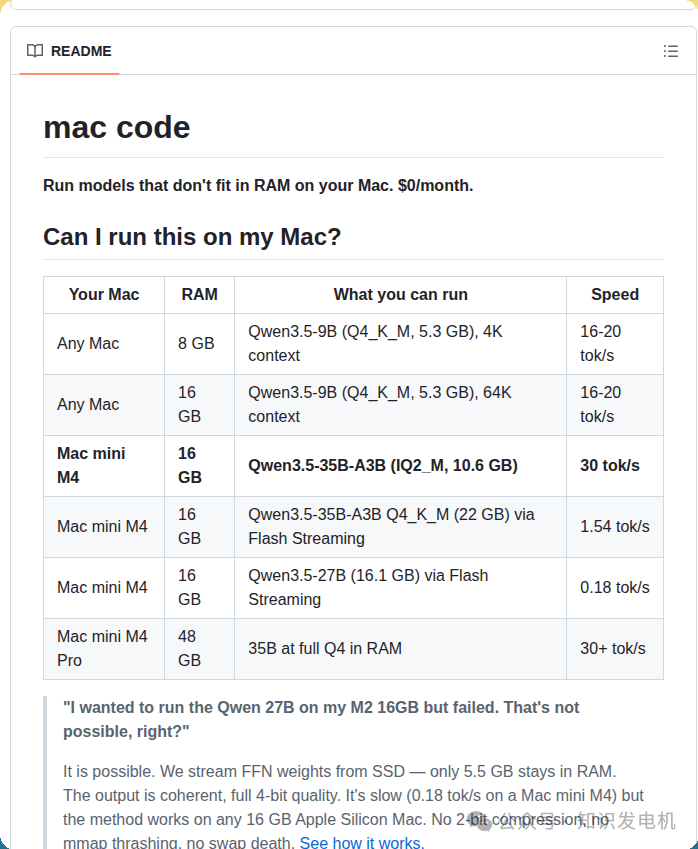
通过将模型中最耗费内存的 FFN (前馈网络) 权重从 SSD 实时流式加载,仅保留约 5.5GB 在 RAM 中,就能让 27B 参数量的模型在 16GB 内存的 Mac mini M4 上运行起来。虽然推理速度降至 0.18 token/秒,但输出保持了完整的 4-bit 量化质量,无需使用会严重损失精度的 2-bit 压缩,也避免了内存映射 (mmap) 抖动或交换空间导致的系统假死。

这个方法并非全新的黑科技,其核心在于根据权重访问模式对模型进行拆分:将注意力层、嵌入层、归一化层以及 KV 缓存一次性固定在 (pinned) RAM 中;而 FFN 权重则在每个 token 生成时才从 SSD 加载,使用后立刻丢弃。这使得内存占用始终保持平坦,不会随着上下文长度的增加而爆炸。在 Mac mini M4 16GB 上实测运行总大小 16.1 GB 的 Qwen3.5-27B 模型,实际 RAM 占用仅为 5.5 GB,输出连贯,能够执行 Python 代码生成和逻辑推理。曾经认为 16GB 内存只能驾驭 9B 模型,如今 35B 甚至更大的混合专家 (MoE) 模型也成为了可能。尽管速度各有差异,但技术门槛已经发生了根本性改变。
为什么大模型在 Mac 上总受困于内存
这好比外卖员送餐时只能随身携带手机和头盔,大型保温箱需要从站点按需取用,否则自行车将不堪重负。大语言模型 面临同样的困境:参数量膨胀导致权重文件达到数十 GB,16GB 的统一内存根本容纳不下。以往的解决方案要么是强行进行 2-bit 量化导致模型质量严重下降,要么通过内存映射加载整个文件引发读写抖动和卡顿,要么直接触发系统交换导致假死。普通用户打开本地 AI 聊天界面,输入几句话就卡成幻灯片;开发者在测试基准时,内存峰值一冲高,进程就直接因内存不足 (OOM) 而崩溃。
若不解决此问题,Mac 用户将永远只能羡慕云端服务或高配 Pro 机型。Flash Streaming 技术将问题一分为二:区分哪些权重必须常驻内存,哪些可以按需加载。常驻部分仅包括与注意力机制相关的 4-6 GB,而占大头的 FFN 权重每次只加载当前层,用完即弃。内存占用曲线从陡峭上升变为一条平坦的直线。实测数据来自 Mac mini M4 16GB:Qwen3.5-27B 模型(总大小 16.1 GB)仅占用 5.5 GB RAM,速度 0.18 tok/s,质量是完整的 4-bit。MoE 模型速度更快,因为每次只激活并加载 8 个专家(约 14 MB),而非全部的 256 个专家。
在高并发或长上下文场景中,以往 KV 缓存占满内存即告失败,而现在注意力部分被固定在 RAM,FFN 流式加载互不干扰。此前普遍认为此参数仅影响写入速度,后来发现对读取速度的影响更大。这里需要区分两种情况:稠密 (Dense) 模型速度较慢,而 MoE 模型得益于专家路由特性,速度可提升约 10 倍。实际测试表明,将 cache-aware routing bias 设置为 1.0 是保证质量的最安全最大值,若提高至 1.5,输出质量开始下降。
Flash Streaming 如何实现模型权重的拆分与加载
将模型权重按访问模式拆分后,运行时逻辑随之改变。每生成一个 token,首先运行注意力计算(全部在 RAM 中,瞬间完成),然后从 SSD 加载 FFN 权重(约 165-221 MB),执行矩阵乘法,最后立刻丢弃该层权重,内存不会累积增长。MoE 模型具有额外优势:仅加载当前激活的 8 个专家,而非全部参数。因此,35B 的 MoE 模型在 16GB 内存的机器上能达到 5.4 tok/s,RAM 占用为 8.7 GB。普通用户可能认为这只是“慢一点但能用”,但对开发者而言,这意味着本地部署大模型的成本曲线被彻底拉平——不再需要 64GB 以上内存的机器,也无需每月支付数百元的云端服务费用。
技术上的关键在于“cache-aware routing bias + co-activation prefetch + right-sized LRU cache”的组合。bias 设为 1.0 能确保模型质量不下降,prefetch 机制将接下来可能用到的权重提前加载,LRU 缓存则用于控制内存水位。所有数据均基于冷启动状态下测试 5 个不同提示词得出:Qwen3-32B Dense 模型(18.4 GB)仅用 4.5 GB RAM,速度 0.15 tok/s;Qwen3.5-35B-A3B MoE 模型(19.5 GB)仅用 8.7 GB RAM,速度 5.4 tok/s。磁盘需求也很明确:35B 模型需要约 25 GB 空闲空间,更大的 80B 模型则需要 50 GB,建议直接使用外置 NVMe SSD。
严格来说,注意力部分的相关权重必须全程固定在内存中,否则每生成一个 token 都重新加载会彻底拖垮速度。过去许多人认为只需量化就足够了,但事实是 4-bit 量化虽然保证了质量,模型体积依然无法放入 16GB 内存。现在的拆分加载方式,则巧妙地绕开了这个根本性限制。
实践指南:在 16GB Mac 上部署运行 35B 智能体
首先安装基础工具。通过 Homebrew 安装 llama.cpp,并用 pip 安装必要的 Python 包。
brew install llama.cpp
pip3 install rich ddgs
使用 huggingface_hub 一行命令下载模型,例如将 10.6 GB 的 IQ2_M 量化版 Qwen3.5-35B-A3B 模型下载到 ~/models/ 目录。启动 llama-server 时,使用 --n-gpu-layers 99 将所有能放在 GPU 上的层都进行加速,--ctx-size 12288 提供足够的上下文长度,并将 KV 缓存的类型设置为 q4_0 以保证质量。
# 先确认端口没被占用,避免启动时报错 `Address already in use`
lsof -i :8000
# 下载 35B IQ2_M 模型(10.6 GB,可完全载入16GB RAM)
python3 -c "
from huggingface_hub import hf_hub_download
hf_hub_download('unsloth/Qwen3.5-35B-A3B-GGUF',
'Qwen3.5-35B-A3B-UD-IQ2_M.gguf', local_dir='$HOME/models/')
"
# 启动 server + agent(推荐方案,速度可达30 tok/s)
llama-server \
--model ~/models/Qwen3.5-35B-A3B-UD-IQ2_M.gguf \
--port 8000 --host 127.0.0.1 \
--flash-attn on --ctx-size 12288 \
--cache-type-k q4_0 --cache-type-v q4_0 \
--n-gpu-layers 99 --reasoning off -np 1 -t 4
python3 agent.py
运行后可以看到智能体界面,它能够进行联网搜索、执行 shell 命令和链式思考。整个过程内存峰值稳定在 10 GB 左右。
⚠️ 注意:如果想使用 Flash Streaming 运行 27B Dense 版本,需要先到 research/flash-streaming 目录下执行 split_dense_27b.py 脚本对模型进行拆分。之后内存占用会降至 5.5 GB,但速度也会降到 0.18 tok/s。常见的错误是磁盘空间不足,或未将模型文件放在 SSD 上——使用外置机械硬盘会将速度拖慢至近乎为零。
这种方法彻底降低了在 Mac 上本地运行大模型的门槛,16GB 内存即可体验 35B 级别的智能体,不再是云端服务的专属。该方案的下一个版本计划支持更大的模型,具体时间表尚未公布。在 云栈社区 的讨论中,许多开发者都在分享各自的本地部署方案与踩坑经验,这种开源 实践与交流极大地推动了技术的普及和应用。你的团队目前在用哪套本地方案?是否也遇到过类似的内存瓶颈呢?
 发表于 2026-4-13 05:17:54
|
查看: 298|
回复: 0
发表于 2026-4-13 05:17:54
|
查看: 298|
回复: 0
