本文为你拆解大模型(LLM)应用的核心概念,包括提示词工程(PE)、检索增强生成(RAG)、工具调用(Function Calling)和模型上下文协议(MCP),是零基础开发者快速上手的实战指引。
近年来,AI发展迅猛,越来越多的业务希望借助AI实现升级。面对这个看似神秘的“黑盒”,很多研发人员会感到困惑:“我需要学习神经网络算法吗?我要懂 Transformer 架构吗?”
其实,对于非算法背景的工程师而言,目标并非成为研发“发动机”的科学家,而是成为能驾驭“赛车”的AI工程师。我们无需深究底层的复杂数学,但必须清楚它的能力边界,懂得如何将这个强大的“黑盒能力”高效、稳定地集成到业务系统中。
一. 大模型:从规则到概率的“涌现”智能
传统编程:显式的逻辑规则
作为研发,我们的日常工作本质是在定义函数。在传统软件工程中,这些函数的逻辑是确定性的。例如判断一个人是否成年,我们可以写出明确的函数:
def is_adult(age):
return age >= 18
在这个模式下,输入什么参数,经过怎样的判断,一定会得到确定的输出。
但是,当面对“识别图片中是猫还是狗”或“总结一篇文档”这类任务时,规则变得极其复杂且模糊,我们无法再编写一个确定性的函数来完成。
机器学习:拟合复杂的函数
既然无法手写复杂规则,机器学习便放弃了“直接定义逻辑”的思路,转而通过算法让机器在大规模数据中自动寻找规律,从而拟合出那个极其复杂的函数。
具体而言,机器学习会构建一个庞大的数学模型(如神经网络),通过训练来修正模型内部的权重和偏差。这个过程,本质是一个迭代“试错”的闭环:
- 预测:模型基于当前参数对输入数据做出预测(初始阶段几乎是随机“瞎猜”)。
- 反馈:当发现预测值与真实标签不符时(例如将猫误认为狗),算法会计算两者之间的误差。
- 微调:利用数学方法(如反向传播)回溯并微调内部的权重参数,目标是减小误差,让下一次预测更准。
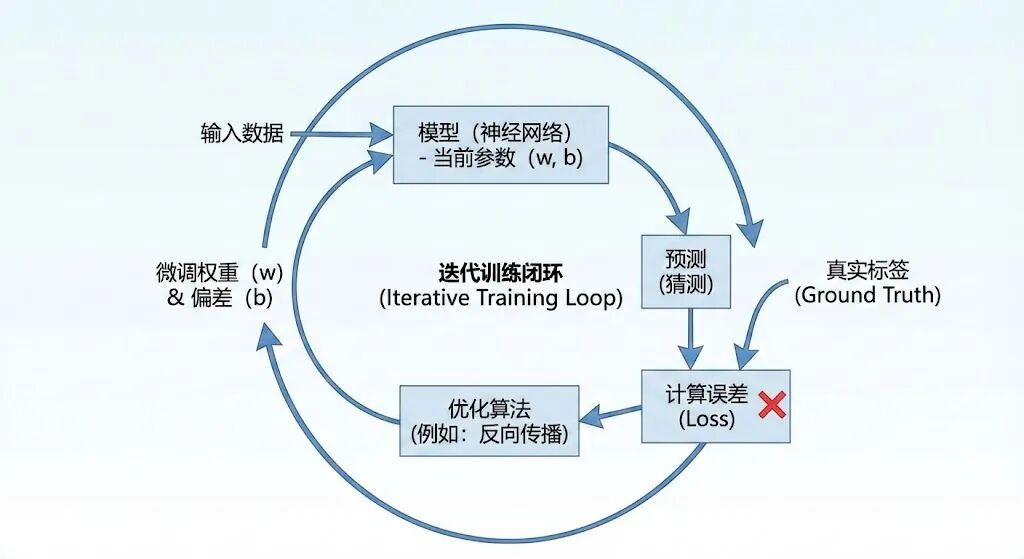
经过数百万次的重复训练,模型最终能基本精准地将输入映射到输出。此时,我们就得到了一个拟合好的函数。即使面对从未见过的数据,它也能根据从海量样本中提取的特征规律,给出相应的判断。
需要注意的是:机器学习得到的函数是一个概率模型。它不像传统代码那样保证100%的绝对准确,而是在统计学上不断逼近正确答案。因此它天然存在出错的可能——即便是一张清晰的猫,模型仍有极小的概率产生偏差,将其识别成狗。
大模型(LLM):量变引起的“涌现”
在传统机器学习时代,模型参数量通常在几百万到几亿级别,且大多是专用型的:识图模型无法处理翻译任务,翻译模型无法编写代码。
然而,当参数量和训练数据突破临界点(如GPT-3达到千亿级参数)时,发生了神奇的“涌现现象”,模型的能力发生了质的飞跃(这类大参数量模型被称为大模型):
- 通用性:在学习预测万亿级语料的过程中,它自然而然地掌握了摘要、翻译、代码编写等多种能力,成为了一个可以处理几乎所有自然语言任务的“通用大脑”。
- 上下文学习:不需要修改模型参数,只需在提示词(Prompt)里给出几个示例(Few-Shot),模型就能凭借强大的学习能力,快速适配新任务并执行。
以GPT (Generative Pre-trained Transformer) 为例,尽管其功能看似复杂,但底层核心机制十分纯粹,类似于“成语接龙”:
- 输入:用户的提示词 + 模型已经生成的上文(比如 “床前明月”)。
- 预测:模型在词表中计算下一个最可能出现的词的概率分布(就像接龙时想 “床前明月” 后面该接 “光”)。
- 输出:模型通常选取概率最高的词(例如输出 “光”),将该词拼接到原有输入中,形成新的上下文(“床前明月光”),再进入下一轮预测,直至触发结束标志。
二. 提示词工程:如何让AI“听话”地为你工作
什么是提示词工程(PE)?
我们已经知道 LLM 本质上是一个 “概率预测机” ,它读取文本,计算概率,预测下一个词,循环往复。在这个过程中,我们给 LLM 的所有输入统称为 Prompt(提示词)。
但这里有个工程难题:如果输入是发散的,输出必然也是发散的。
举个例子,我们想让 LLM 判断用户反馈是正面还是负面:
写法 A:这条评论是正面的还是负面的?用户说界面太丑了,卸载了。
LLM 可能这样回答:
- “是负面的。”
- “负面情绪”
- “这条评论表达了用户的负面情绪,因为他说界面太丑,还卸载了应用。”
三种回答都对,但格式完全不同。这在聊天时没问题,但如果你的程序需要解析这个结果(比如存入数据库、触发告警),这种不统一的格式简直是开发者的噩梦。
写法B:
你是一个情感分析专家。请判断以下用户反馈的情感倾向,只返回"正面"或"负面",不要输出任何解释:
用户反馈:"界面太丑了,卸载了!"
这一次 LLM 的输出就很稳定:负面。
为什么? 因为写法 A 模棱两可,LLM 不知道你想要什么格式;写法 B 明确了角色、任务和输出要求。
这就是 提示词工程(Prompt Engineering) 的核心:通过精心设计 Prompt,让 LLM 的输出更稳定、更准确、更符合业务需求。
在聊天场景下,对话是“发散”的。但一旦要把 LLM 接入业务系统,程序就需要解析返回结果,一个格式不对的 JSON 就能让整个系统崩溃。因此,PE 的核心目标是从“自由对话”转向“工程化协议”,就像调用 API 需要构造请求参数、定义返回格式一样,Prompt 就是这个“人机接口的协议”。
如何写好提示词?
写 Prompt 就像给实习生布置任务:你说得越清楚,他干得越靠谱。我们继续用“判断用户反馈情感”这个例子,看看如何逐步优化。
(1) 明确角色和任务:先把话说清楚
第一步是“定义人设”,告诉 LLM:你是谁,要做什么。这通常通过 System Prompt(系统提示词) 来实现。
- 角色定义:“你是一个情感分析专家”——这样 LLM 会自动调整“专业程度”,知道要从用户反馈中提取情感信号。
- 任务指令:“请判断用户反馈的情感倾向”——不要让 LLM 去猜你想干什么,直接说清楚。
# 角色
你是一个情感分析专家,擅长从用户反馈中识别情绪。
# 任务
请判断用户反馈的情感倾向,只返回"正面"或"负面":
(2) 提供示例模板:让 LLM 照着做
直接下指令,LLM 有时仍会“放飞自我”。比如你要求“只返回正面或负面”,它可能会输出“这条反馈是负面的”。这时候,给他几个示例最有效,这叫 少样本学习(Few-Shot Learning)。
# 角色
你是一个情感分析专家,擅长从用户反馈中识别情绪。
# 任务
请判断用户反馈的情感倾向,只返回"正面"或"负面":
# 示例
## 示例1输入:
这个APP太棒了!
## 示例1输出:
正面
## 示例2输入:
用了一天就崩了,垃圾软件。
## 示例2输出:
负面
就像给实习生一个“参考答案模板”,它看了几个例子,自然就明白该怎么干了。这完全依赖于LLM强大的上下文学习能力。
(3) 引导逐步推理:让它“慢下来”思考
在处理复杂情感时(比如阴阳怪气、转折句),LLM容易直接“跳步”给错答案。例如,用户评论:“界面漂亮但反应慢、想卸载”。LLM可能看到“漂亮”就直觉式地判断为“正面”。
如果加一句话:“请逐步思考(Let‘s think step by step)”,准确率会显著提升。这就是 CoT(Chain of Thought,思维链)。
LLM 的内部逻辑流会变为:
- 关键词提取:“界面漂亮”(正)、“反应慢”(负)、“想卸载”(极负)。
- 意图分析:虽然有视觉上的夸赞,但最终行为是卸载,表达了强烈的挫败感。
- 最终结论:负面。
核心逻辑:强迫 LLM 先把推理过程写出来,这个过程会成为后续生成的“上下文”,相当于模型在 “自我检查”,确保结论是推导出来的,而不是“猜”出来的。
# 角色
你是一个情感分析专家,擅长从用户反馈中识别情绪。
# 任务
请判断用户反馈的情感倾向。请逐步思考后再输出结果。只返回"正面"或"负面":
...
(4) 格式约束:让程序能轻松解析
前面解决的是“答得对”,但在代码场景下,关键是:让 LLM “答得能被程序解析”。
业务系统中,我们希望 LLM 返回 JSON 这种结构化数据。但 LLM 可能随口回一句:“好的,这是你要的结果:{...}”。这多出来的几个字,就会导致 json.loads() 直接报错。
为了解决这个问题,工程上通常采用“事前约束 + 事后纠错”的组合拳:
1. 结构化 Prompt(事前约束)
直接给模型一个标准的 JSON 模板,并约束它不要输出多余的解释。
# 角色
你是一个情感分析专家,擅长从用户反馈中识别情绪。
# 任务
请判断用户反馈的情感倾向并分析原因。请逐步思考后再输出结果。
# 输入格式
{
"feedback": "<用户反馈内容>"
}
# 输出格式
{
"sentiment": "正面/负面",
"reason": "<原因分析>"
}
# 约束
1. 必须仅返回 JSON 数据,禁止任何解释性文字
2. sentiment 字段只能是 "正面" 或 "负面"
# 示例
## 示例1输入
{"feedback": "这个APP太棒了!"}
## 示例1输出
{"sentiment": "正面", "reason": "用户对产品表示满意"}
## 示例2输入
{"feedback": "用了一天就崩了,垃圾软件。"}
## 示例2输出
{"sentiment": "负面", "reason": "用户遇到稳定性问题"}
2. 工程化鲁棒性(事后纠错)
在实际业务中,单靠 Prompt 依然会有概率遇到非法格式。研发通常会引入以下兜底方案:
- 原生 JSON 模式:调用 API 时开启模型自带的
response_format: { "type": "json_object" } 模式,强制模型输出(如果平台支持)。
- 自动修复(Repair):使用类似
json_repair 的库。这些库利用算法修复模型输出中缺失的引号、括号或多余的解释语。
- 重试机制(Retry):如果解析失败,自动进行 2-3 次重试,或者在重试时把错误信息返还给模型(“你刚才返回的格式错了,请修正”)。
三. 检索增强生成(RAG):给AI外挂一个“知识库”
提示词工程解决了让大模型“更听话”的问题,但即便再会写 Prompt,大模型本质上仍是一个静态的知识库(它的记忆停留在训练结束的那一天)。它有两大无法克服的缺陷:幻觉和知识滞后。
- 幻觉(一本正经的胡说八道):无论输入什么,它都会通过“概率预测”生成一段回答,这段回答可能看起来专业,但完全是错误的。
- 知识滞后(不知道最新的事):LLM 无法实时获取信息,比如无法查询公司最新的内部文档或今天的实时销售数据。
为了解决这些问题,就诞生了 RAG (Retrieval-Augmented Generation,检索增强生成) ,它将大模型的“生成能力”与传统数据检索的“准确性”结合起来,给大模型外挂一个“实时更新的知识库”。
如果把大模型直接回答问题比作 “闭卷考试” ,那么 RAG 就是让它变成一个 “开卷考试” 的学生。
- 闭卷模式:由于模型没学过公司的私有文档,它只能凭直觉“编造”。
- 开卷模式(RAG):
- 翻书(检索):当用户提问时,系统先去内部文档库里搜索相关的段落。
- 摘抄(增强):把找到的准确信息“抄”在 Prompt 里,作为背景参考资料。
- 作答(生成):最后让大模型根据这些“参考资料”来组织语言回答。
这样,AI 就不再是凭空想象,而是“有据可查”。这套“开卷考试”系统需要经历以下核心步骤:
第一步:准备阶段 —— 语义向量化
计算机读不懂文字,它只懂数字。我们需要把文字转换成一种数学表达,这就是 Embedding(词嵌入)。
- Embedding 模型:一种特殊的模型,能把文本映射成一串高维数组(向量)。
- 核心逻辑:语义相近的文本,在数学空间里的“距离”也更近。 比如,“猫”和“小猫”的向量距离,会比“猫”和“挖掘机”近得多。这使得“语义搜索”成为可能。
第二步:检索阶段 —— 向量数据库
有了向量,我们需要一个专门的“仓库”来存储和查询它们。
- 入库:将公司文档切割成一个个小段(Chunking),算出向量,存入向量数据库。
- 查询:当用户提问时,系统先算出这个问题的向量。
- 搜索:向量数据库会瞬间找出仓库里和该问题“空间距离最近”的文档段落(这就是 Top-K 检索)。
第三步:生成阶段 —— Prompt 增强
这是最关键的一步。当系统从向量数据库中检索出相关的文档段落后,需要把这些资料嵌入到 Prompt 里,作为“上下文”。这样,大模型在回答问题时,就能看到“参考资料”,而不是“凭空编造”。
四. 工具调用:给AI一双能“干活”的手脚
如果说提示词工程让大模型学会了“说话”,RAG 让大模型拥有了 “知识” ,那么此时的大模型更像是一个“军师”,只能在对话框里指点江山,却无法替你出门办事。
例如,问它:“今天北京天气怎么样?”它会说:“我无法获取实时信息。”;让它发封邮件,它会抱歉地说:“我没有操作权限。”
为了解决这个问题,就诞生了 Function Calling(函数调用),相当于给大模型装了一双 “手脚” ,让它从只会聊天的机器人,进化为能够干活的智能助手。
Function Calling 的核心机制,是让大模型具备 意图识别 和 参数生成 的能力:
- 意图识别:用户的问题需要调用什么工具?
- 参数生成:调用这个工具需要什么参数?
需要澄清一个误解:大模型本身不会“执行”任何函数,它只是告诉服务端:“我觉得应该调用这个函数,参数是这样的”。真正的执行,依然是由你的服务端程序去完成的。
一个完整的 Function Calling 流程,包括四个步骤:
1. 工具注册
在让大模型使用工具之前,开发者需要先告诉它有哪些工具可以用。开发者会向大模型 注册 它能使用的函数,并提供一个 严格的 JSON Schema。这个 Schema 定义了函数名、功能、所需参数及其类型。这就像给大模型一本“工具说明书”。
2. 模型的意图识别
当用户提问时,大模型会做两件事:
- 判断是否需要调用工具。
- 如果需要,生成调用哪个函数及参数是什么。
关键是:大模型 不再生成自然语言回答,而是生成一个 符合 Schema 的 JSON 结构。
- 用户提问:“今天北京天气怎么样?”
- 大模型输出:
{
"function": "get_weather",
"parameters": {
"city": "北京"
}
}
这就是 Function Call 的核心,大模型扮演的是“调度员”,它负责理解意图、提取参数,但不真正执行操作。
3. 执行函数与结果回传
服务端接收到这个 JSON 后,执行真正的业务函数(如调用天气 API),拿到实时数据:“北京今天 15°C,晴。” 然后,这个执行结果被打包成文本,作为 新的 Prompt 上下文,重新喂回给大模型。
4. 最终回复
现在,大模型有了实时数据,它可以根据这些信息,生成最终的自然语言回答:“北京今天天气不错,温度是 15°C,晴朗。”
五. 模型上下文协议(MCP):AI世界的“Type-C”接口
Function Calling 赋予了大模型执行任务的能力,但在实际工程中,开发者面临着一个巨大的痛点:协议碎片化。
想象一下,你为 OpenAI 的模型写了一套查天气的工具,但换到 Google 的模型上,这套工具完全不能用,你需要重新写一遍。这就像每家手机厂商都有自己的充电接口。
为了实现大规模协作和生态互联,需要统一的标准和高效的工具。这时就诞生了 MCP(Model Context Protocol,模型上下文协议) ,可以将其理解为 AI 时代的 Type-C 接口 或 TCP/IP 协议。
MCP 的核心目标是实现 “一次开发,到处可用”。它将 LLM(大脑)与 Context/Tools(知识与工具)彻底解耦。
- 之前(模型绑定):工具和数据源往往与特定的模型厂商深度绑定。你想让模型读取你的本地文件或数据库,必须为每个模型量身定制适配层。
- 现在(通用标准):无论是哪个模型(大脑),只要它支持 MCP 标准,就能像插拔 Type-C 设备一样,无缝调用任何遵守 MCP 协议的数据源或工具。
对于开发者和企业来说,MCP 协议的出现具有里程碑式的意义:
- 统一的标准协议: MCP 就像是 AI 领域的 TCP/IP 协议。它定义了一套通用的语言,让模型能够以统一的方式发现工具(Tools)、读取资源(Resources)和查看提示词模板(Prompts)。
- 极低的适配成本:
- 以前:如果你有 10 个数据源(数据库、GitHub、Slack等)和 3 个主流模型,你可能需要维护 30 套适配逻辑。
- 现在:你只需要让这 10 个数据源支持 MCP 协议,任何支持 MCP 的模型(如 Claude Desktop 或各类 AI IDE)都能立即接管并使用它们。
- 生态互联的基石: MCP 为 AI 生态的爆发奠定了基础。开发者可以像拼乐高积木一样,将来自不同供应商的 MCP 服务器(数据源)组合在一起,构建出极其复杂的自动化工作流。有关 MCP 及其在构建智能体(Agent)工作流中的具体实践,你可以探索更多相关资源和开源项目。
总结
AI 不是一个神秘的黑盒,它是一个有概率、需要被控制、需要知识、需要执行能力,并最终需要互联的复杂工程系统。本文旨在为你构建一个清晰的认知地图:
- 提示词工程(PE):解决了“如何让 AI 听话”。
- 检索增强生成(RAG):解决了“如何让 AI 有知识”。
- 函数调用(Function Calling):解决了“如何让 AI 能干活”。
- 模型上下文协议(MCP):解决了“如何让 AI 生态互联”。
希望这篇指南能帮助你快速入门,在云栈社区这样的技术交流平台,与更多同行一起探索,成为一名真正能驾驭“赛车”的 AI 工程师。
 发表于 2026-3-1 08:16:13
|
查看: 146|
回复: 0
发表于 2026-3-1 08:16:13
|
查看: 146|
回复: 0
