本文旨在梳理网络安全漏洞挖掘中,信息收集这一基础且关键环节的系统性方法与实用工具,适合初学者构建知识框架,也供有经验的从业者查漏补缺。
对漏洞挖掘基础的重新思考
网上关于漏洞挖掘步骤的文章不少,但很少深入探讨进行有效挖掘所需的前提条件。我认为,在动手之前,以下几点认知至关重要:
-
对漏洞本质的理解
第一步,是学习各类漏洞是如何产生的,以及常规的修复方案是什么。更重要的是,思考这些修复是否存在被绕过的可能。
举个例子:SQL注入的产生,往往是因为代码将用户可控的输入直接拼接到数据库查询语句中,且未进行有效过滤。那么,它的常见触发点就在“增、删、改、查”这些与数据库交互的操作上。了解这一点,我们才能有目的地去测试网站中涉及这些功能的位置。
-
建立清晰的挖掘流程
面对一个目标网站,我们应该能依据已有知识,在脑海中勾勒出一个基本的测试步骤图。
例如,面对一个电商网站和面对一个登录系统,第一步的切入点可能完全不同。如果拿到目标后毫无头绪,不知从何测起,那么挖掘工作将难以开展。
-
具备绕过防护的思维
很多人遇到WAF(Web应用防火墙)就选择放弃。但为什么不思考一下如何绕过它呢?
比如,某网站WAF的策略是在单位时间内拦截请求频率过高的IP。这时,除了放弃,我们是否可以考虑使用代理池来分散请求?再进一步,如果对方是基于请求头中的 X-Forwarded-For 或 User-Agent 来识别和封禁,我们是否可以尝试伪造这些信息来绕过黑名单策略?
前期:广撒网,多维度资产搜集
我十分认同“漏洞挖掘的本质是信息搜集”这一观点。你所能发现的漏洞质量,在很大程度上取决于你掌握的资产广度和深度。以下是一些行之有效的资产搜集途径:
- 天眼查/企查查
从这些企业信息查询平台的知识产权栏目中,常常可以发现目标公司申请注册的商标、软件著作权等,其中可能包含未公开的网站名称或项目资产。

- ICP备案查询
通过接口查询企业ICP备案信息,可以获取在该企业名下备案的所有网站,这是发现关联资产的有效方法。以下是一个基于 icp.chinaz.com 接口的Python查询脚本示例:
import requests
import threading
import re
targets = []
names = []
def icp_info(host):
url = "https://icp.chinaz.com/ajaxsync.aspx?at=beiansl&callback=jQuery111305329118231795913_1554378576520&host=%s&type=host"%host
html = requests.get(url,timeout=(5,10)).text
pattern = re.compile('SiteName:"(.*?)",MainPage:"(.*?)"',re.S)
info = re.findall(pattern,html)
for i in range(0,32):
try:
name = info[i][0]
target = info[i][1]
print("%s:%s"%(name,target))
if target not in targets:
targets.append(target)
with open("icp_info.txt","a+") as f:
f.write("%s:%s"%(name,target) + "\n")
except:
continue
def start():
with open("url.txt","r+") as a:
for b in a:
b = b.strip()
icp_info(host=b)
a.close()
def main():
thread = threading.Thread(target=start,)
thread.start()
if __name__ == '__main__':
main()
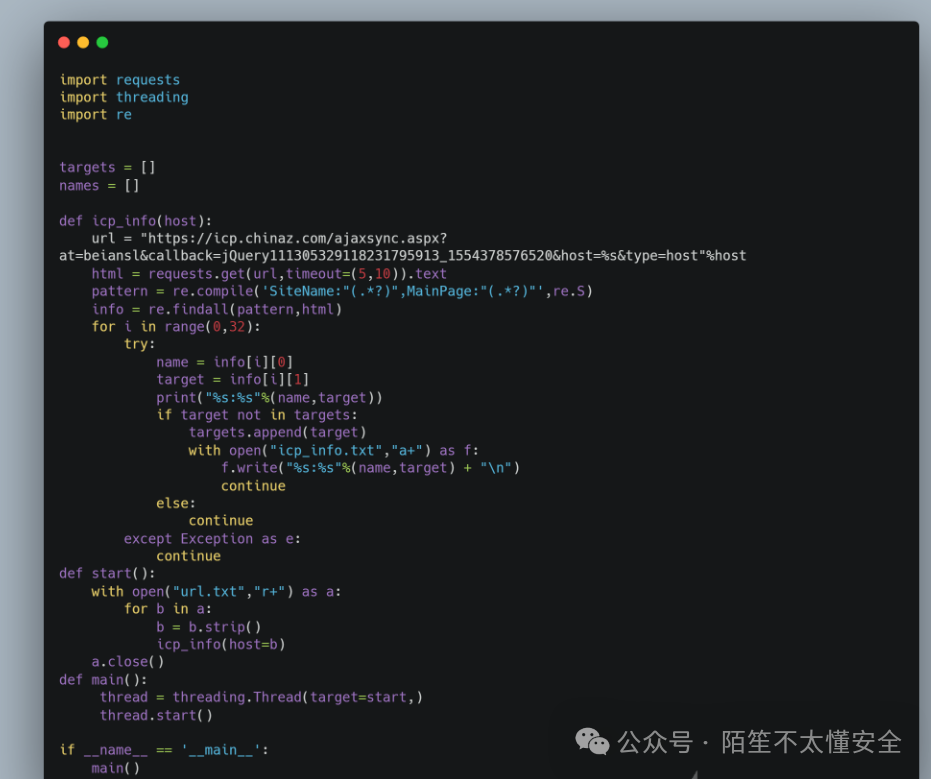
使用方法:将待查询的根域名放入 url.txt,运行脚本即可,程序会自动去重。
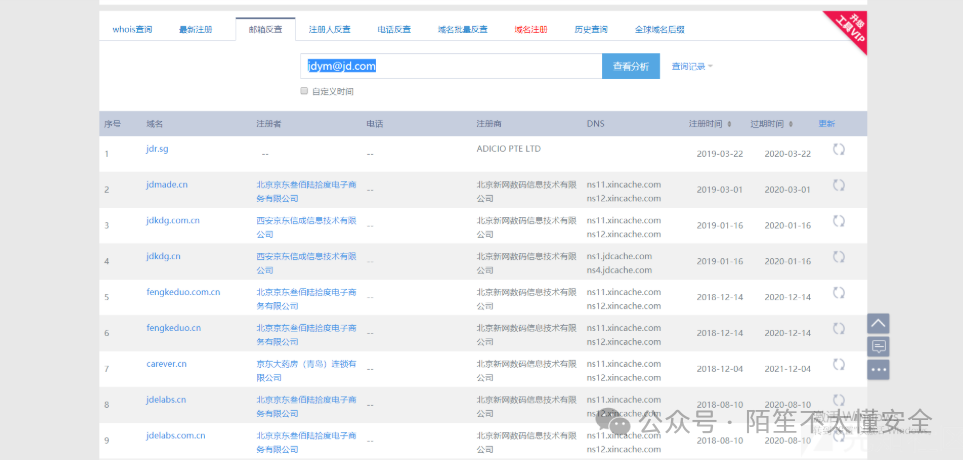
- Whois信息反查
对已知域名进行Whois查询,获取注册人、邮箱、电话等信息,再利用这些信息进行反查,往往能发现同一注册主体下的其他关联域名。一些在线平台(如微步)提供历史Whois查询功能,价值更大。

- 网络空间搜索引擎
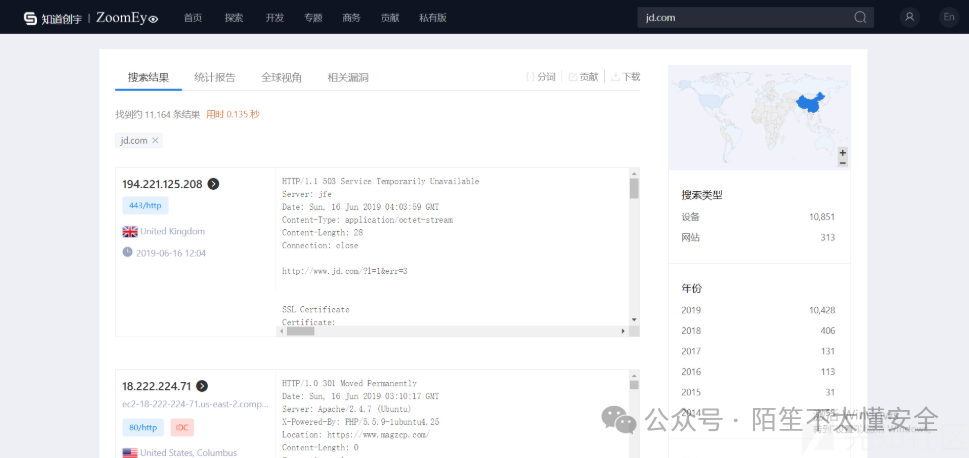
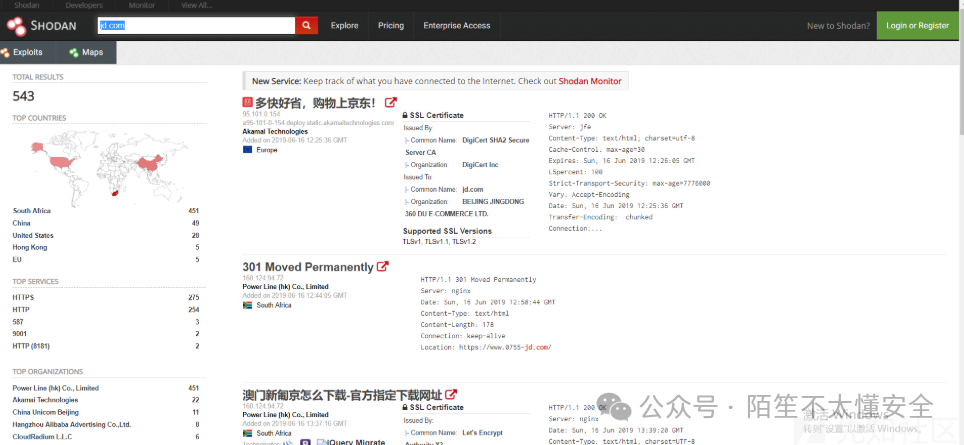
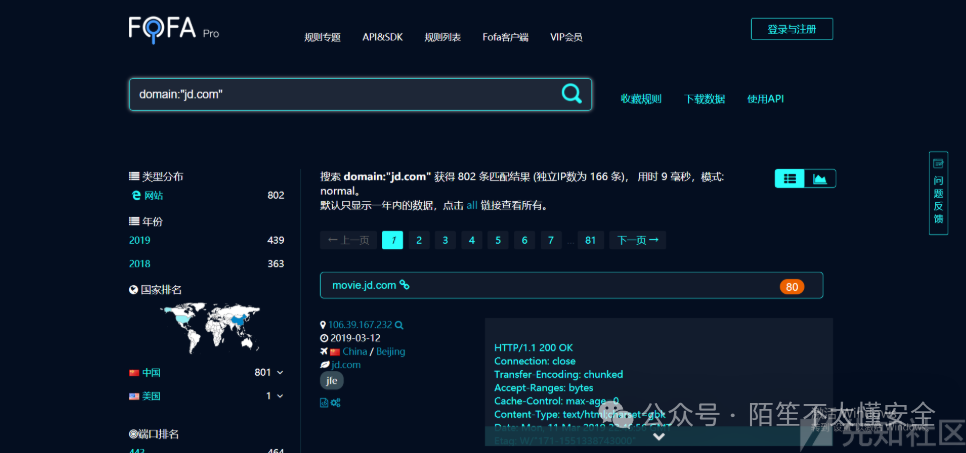
如 Shodan、 ZoomEye、 FOFA 等,是资产搜集的利器。
- 直接搜索:搜索公司名、域名,可以发现标题、证书、HTTP响应中包含关键词的资产。
- 利用特定语法:
Shodan 可搜索特定组织 (org:)、利用网站icon的哈希值 (http.favicon.hash) 来定位资产。FOFA 可使用 domain="jd.com" 直接搜索子域名。ZoomEye 可使用 hostname:”jd.com” 搜索主机名。
-
GitHub
GitHub不仅是代码托管平台,也是敏感信息和资产发现的重要来源。除了直接搜索域名、项目名,更可以利用自动化工具监控代码推送中的敏感信息泄露。
-
微信公众号与小程序
企业的公众号和小程序也是资产的重要组成部分,其后台往往与Web端接口互通,可能成为一个独特的测试入口。
-
移动端APP
从应用商店搜索企业名称,或通过已知APP的开发者账号顺藤摸瓜,常能发现一些未公开宣传的内测或边缘应用。对这些APP进行逆向分析,能提取出隐藏的API接口。
-
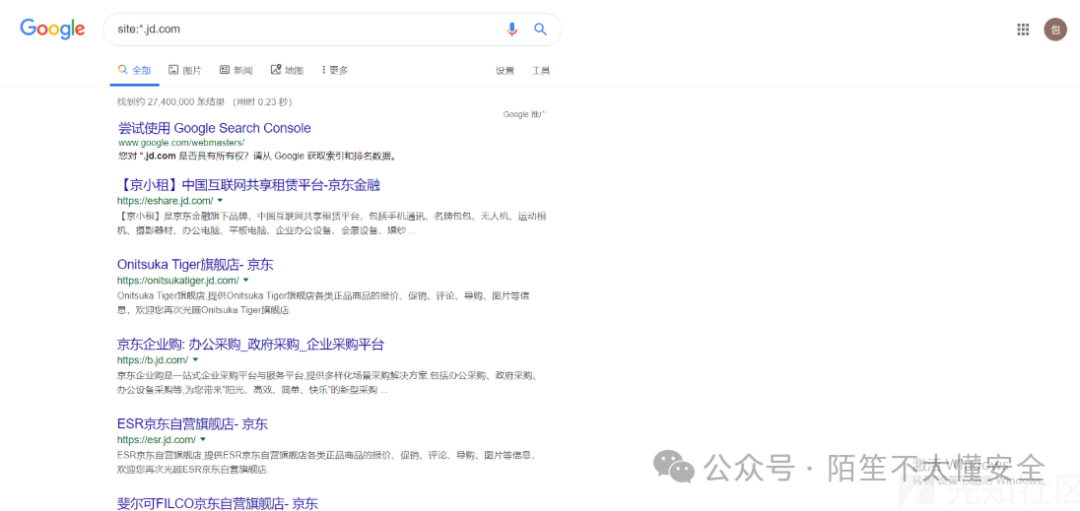
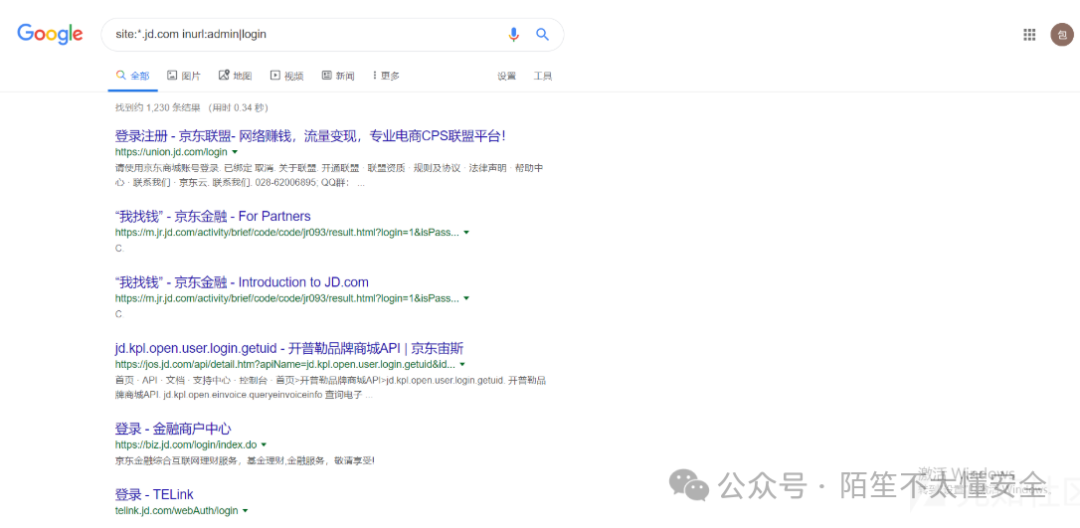
传统搜索引擎的高级语法
使用 Google、Bing、Baidu 的 site:、inurl:、intitle: 等高级搜索语法,可以精准定位目标资产,尤其是管理后台、登录入口等。
- APK/JS文件分析
- APK分析:对APP进行反编译,可以从代码中提取出硬编码的URL、API接口等。推荐工具:
Apkatshu、Drozer(需配合手动分析)。
- JS文件分析:前端JavaScript文件中常包含未在页面中直接引用的API接口、子域名等敏感信息。推荐工具:
JSFinder (https://github.com/Threezh1/JSFinder),它能自动化爬取并解析JS文件中的敏感路径。
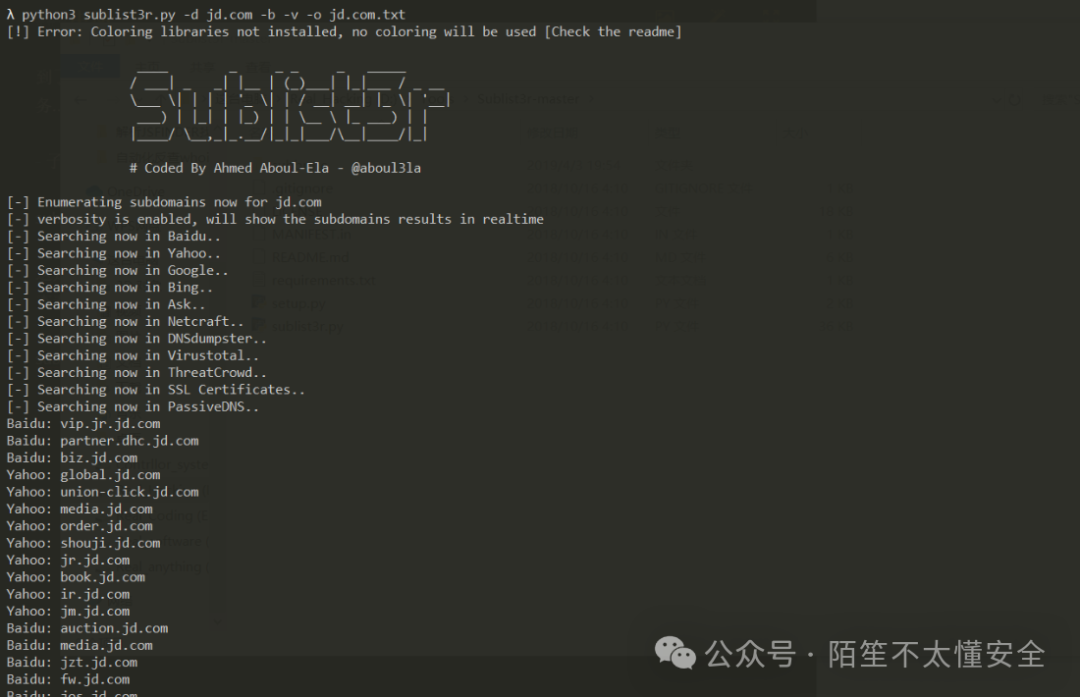
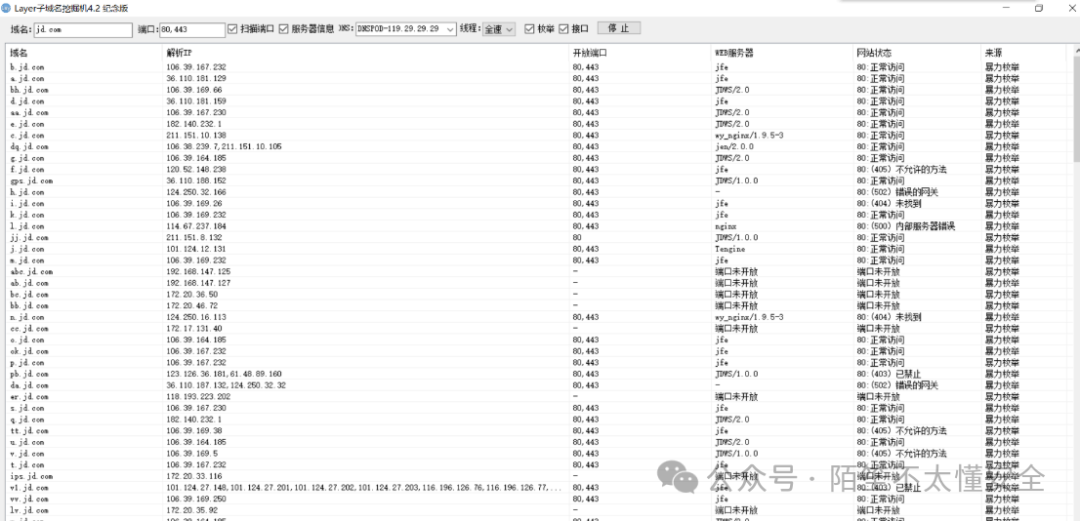
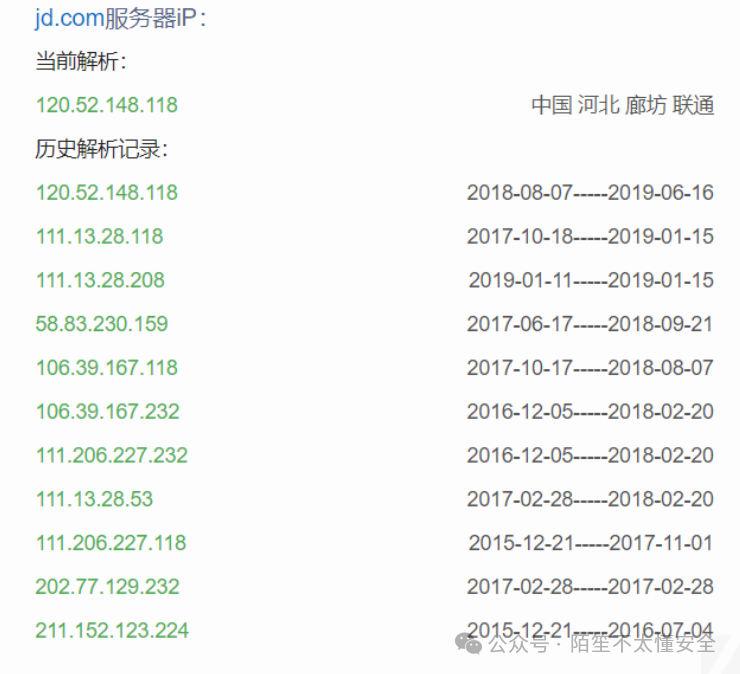
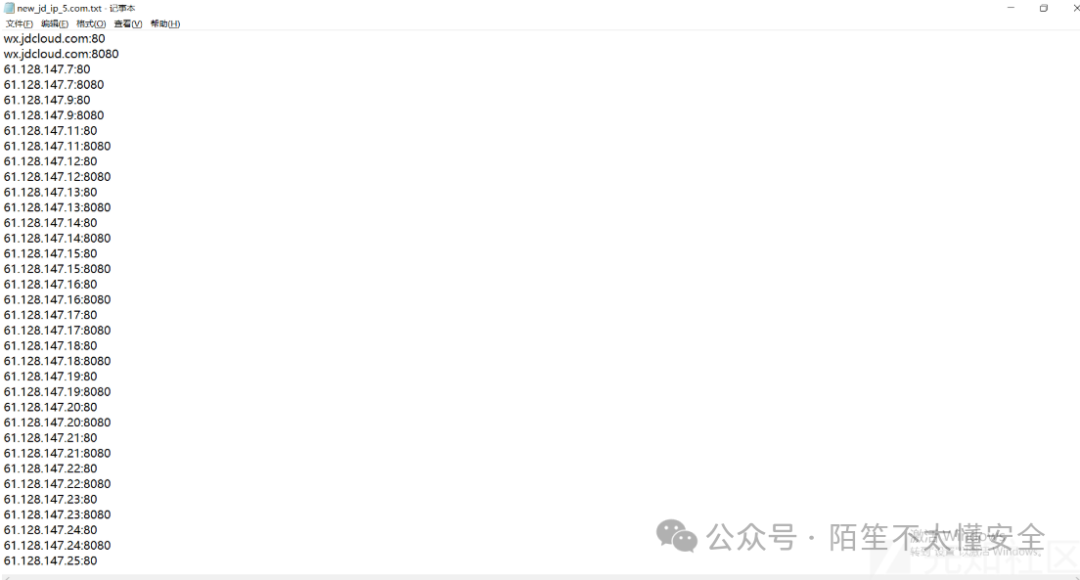
中期:深挖与拓展,聚焦子域名与IP
完成初步的广泛搜集后,接下来的目标是深度挖掘,主要集中在于域名和IP地址的发现上。
至此,一个相对完整的资产列表应该已经形成。建议将结果进行整理和去重,并考虑存入数据库,便于后续的持续监控和比对。
后期:自动化扫描与手动验证
资产搜集完毕后,就进入了实质性的漏洞发现阶段。为了提升效率,可以遵循以下步骤:
-
自动化漏洞扫描:
- Web漏洞扫描:使用
AWVS、AppScan 或开源的 Nuclei、Xray 等工具对Web资产进行初步筛查,发现常见的SQL注入、XSS、命令执行等问题。
- 系统与中间件漏洞扫描:使用
Nessus、OpenVAS 或 Goby 扫描服务器系统漏洞和中间件漏洞(如Shiro反序列化、Weblogic漏洞等)。
-
指纹识别与信息强化:
- 使用
Wappalyzer、EHole 或在线平台如云悉,识别网站使用的技术栈(CMS、框架、中间件、前端库等),这能极大地帮助后续的漏洞利用。
-
敏感文件与目录扫描:
- 使用
BBScan、dirsearch、dirmap 等工具扫描网站备份文件(.zip, .tar, .bak)、源码泄露(.git/, .svn/)、配置文件等。
- 推荐工具:
-
人工深度测试:
自动化工具无法覆盖所有逻辑漏洞和复杂场景。在自动化扫描的基础上,必须进行人工审计。这包括但不限于:
- 业务逻辑漏洞测试(越权、流程绕过)。
- 接口参数测试(未授权访问、信息泄露)。
- 根据识别出的特定框架/组件,进行针对性漏洞利用尝试。
总结
信息收集是渗透测试的基石,它决定了后续攻击面的宽度与深度。本文梳理了从企业信息、域名、IP、端口到应用层资产的全链路收集方法,并介绍了相应的工具。需要注意的是,工具和技术在不断发展,但其背后的思想——多维度、持续性地发现和关联资产——是永恒不变的。
真正的安全能力体现在将自动化工具的高效与安全研究员深度思考相结合。在逆向工程与漏洞挖掘的路上,持续学习、归纳方法论并建立自己的知识体系,远比单纯收集工具列表更为重要。欢迎在云栈社区的安全板块与更多同行交流探讨,共同精进。 |  发表于 2026-3-1 08:22:14
|
查看: 227|
回复: 0
发表于 2026-3-1 08:22:14
|
查看: 227|
回复: 0