
你是否曾在编写 C/C++ 时,收到编译器“变量可能未初始化”的警告?或者在 TypeScript 开发中,看到 IDE 提示“对象可能为 null”?你是否好奇,这些工具并未真正运行你的代码,它们是如何仅凭“阅读”源代码就洞察到潜在问题的?这背后正是静态分析的魔力所在。
如果你是一名具备普通应用程序开发经验的程序员,并希望深入理解编译器与静态分析工具的工作原理,那么这篇文章正是为你准备的。阅读之后,你不仅能掌握这些工具的核心工作机制,还能理解它们为何普遍采用相似的设计架构。最后,我们将一起探索一个成熟的静态分析框架——MCIL (MoonBit C Intermediate Language),了解如何使用 MoonBit 对 C 语言进行静态分析。
我们要做什么?
让我们先预览一下最终要实现的效果。假设有这样一段用自制简单语言编写的代码:
var x
var y = input()
if y > 0 {
x = y + 1
}
return x
这门语言支持变量声明、赋值、if条件语句、while循环和return语句,所有变量都在函数作用域内,没有块级作用域。
这段代码存在一个 Bug:变量 x 仅在 if 语句的 then 分支中被赋值,else 分支为空。如果 y <= 0,程序将执行 else 分支,此时 x 从未被赋值,但 return x 却试图使用它的值。这就是典型的“使用未初始化变量”错误。然而,在编译器看来,这段代码在语法和类型上却是完全正确的。
我们的目标就是构建一个能够自动检测此类问题的静态分析器。更重要的是,我们将深入理解静态分析器为何要如此设计,以及这种设计如何让复杂分析变得简单而强大。
从源码到AST:词法分析与语法分析
在进行静态分析之前,我们必须首先将源代码转化为结构化的数据。这个过程分为两个步骤:词法分析和语法分析。
- 词法分析器 (Lexer):将字符流转换为 Token 流。例如,
var x = 0 会被识别为四个Token:关键字 Var、标识符 Ident("x")、赋值符号 Eq、整数 IntLit(0)。词法分析器顺序扫描字符,跳过空白和注释,根据当前字符决定生成何种类型的 Token。
- 语法分析器 (Parser):将 Token 流转换为抽象语法树 (AST)。AST 是程序的树形表示,体现了代码的层次结构。我们通常采用递归下降法:为每种语法成分编写一个解析函数,函数之间相互调用。处理运算符优先级时,可为每个优先级层编写一个函数,低优先级函数调用高优先级函数。
我们的 AST 定义如下:
// 表达式
enum Expr {
Int(Int) // 整数: 0, 42
Var(String) // 变量: x, y
BinOp(
BinOp,
Expr,
Expr
) // 二元运算: x + 1
Call(String,Array[Expr]) // 函数调用: input()
Not(Expr) // 逻辑非: !x
}
// 语句
enum Stmt {
Var Decl(String,Expr?) // 变量声明: var x 或 var x = 0
Assign(String,Expr) // 赋值: x = 1
If(Expr,Array[Stmt],Array[Stmt]) // if-else
While(Expr,Array[Stmt]) // while 循环
Return(
Expr
) // 返回
}
之前的示例代码会被解析为如下结构的 AST:
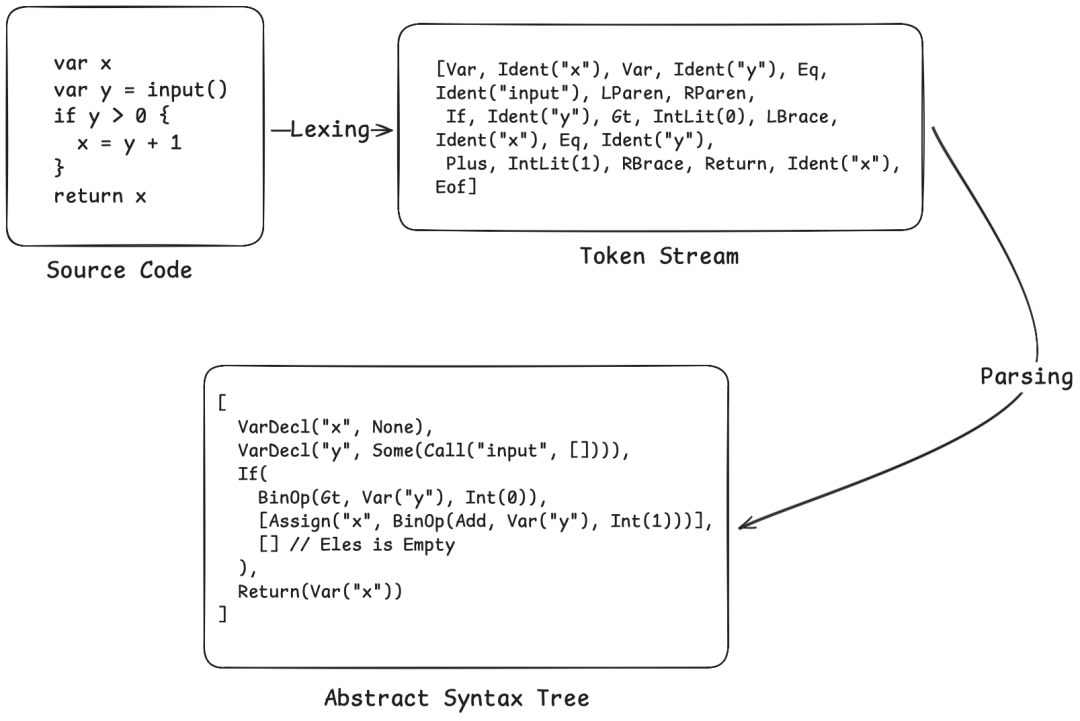
完整的 Lexer/Parser 实现代码将在文末的仓库链接中提供,总计约400行。但本文的重点不在于此——我们更关心的是,获得 AST 之后如何进行有效的分析。对编译原理中的这些基础步骤有清晰的认识,是理解后续更复杂分析的前提。
编译器与静态分析器的关系
在深入之前,让我们先看看整体图景。传统编译器和静态分析器路径不同,但它们拥有共同的起点:
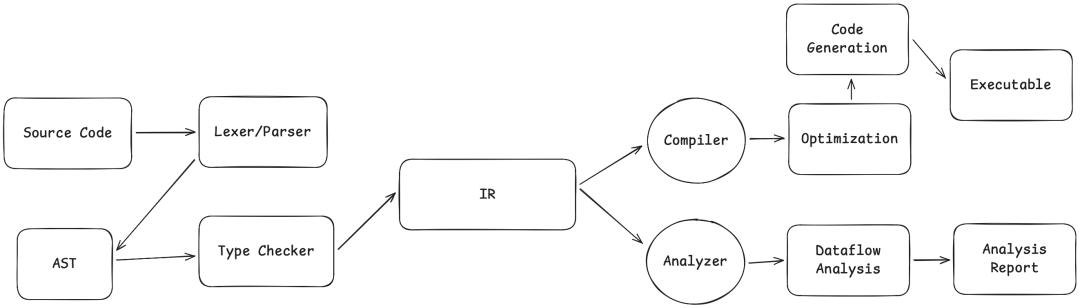
编译器和静态分析器共享从源代码到中间表示 (IR) 的前半段流程。分岔点出现在 IR 之后:编译器继续向下,最终生成可执行文件;静态分析器则“切断”了生成代码的路径,转而分析 IR 本身,输出的是警告和错误报告,而非机器码。
两者都基于一个深刻的洞察:直接在 AST 上进行分析非常困难,而转换成 IR 后会容易得多。这也正是 CIL (C Intermediate Language) 这类框架存在的意义——它们提供一种“分析友好”的中间表示,既保留了源语言的语义,又在结构上更易于进行自动化分析。
为何不能直接在AST上做分析?
理论上,直接在 AST 上进行静态分析是可行的,但实践起来极其痛苦。难点并非分析目标本身复杂,而在于 AST 将控制流隐含在语法结构之中:if、while、break、continue、提前 return 等结构都会迫使分析代码显式模拟所有可能的执行路径,并引入不动点迭代、路径合并等复杂逻辑。结果就是,分析器的复杂度迅速被语法细节所主导,而非由分析问题本身决定。
更糟糕的是,这种实现方式几乎无法复用。即使“未初始化变量分析”和“空指针分析”在抽象层面上属于同一类数据流分析,它们在 AST 上的实现却不得不重复编写大量相似的控制流处理代码。因此,直接在 AST 上进行递归分析,往往导致代码臃肿、易错、不可扩展,并且缺乏统一的抽象层次。
CIL 的核心思想:把控制流“拍平”
CIL (C Intermediate Language) 是加州大学伯克利分校开发的一个 C 程序分析框架。其核心思想简单而强大:不要在 AST 上进行分析,而是先将 AST 转换为一种更适合分析的中间表示 (IR)。
这种 IR 具有两个关键特征:
1、用“基本块”取代嵌套的控制结构
基本块是一段顺序执行的代码,其内部没有分支,也没有跳转目标。换言之,一旦开始执行一个基本块的第一条指令,就必然顺序执行到最后一条指令,既不会中途跳出,也不会有其他代码跳入。
基本块之间通过显式的跳转指令连接。例如:
if cond { ──▶ Block0: if cond goto Block1 else Block2
A Block1: A; goto Block3
} else { Block2: B; goto Block3
B Block3: ...
}
while cond { ──▶ Block0: goto Block1
A Block1: if cond goto Block2 else Block3
} Block2: A; goto Block1 ← 向后跳转
Block3: ...
if 语句被转化为条件跳转,while 循环则被转化为一个回环结构——Block2 执行完毕后跳回 Block1 重新检查条件。
2、用“三地址码”取代复杂的表达式
三地址码是一种简化的指令格式,每条指令最多涉及三个“地址”(变量或临时值)。例如,x = y + z * w 这样的复合表达式,会被拆解为:
t1 = z * w
t2 = y + t1
x = t2
其中 t1、t2 是编译器生成的临时变量。
在代码中,我们可以这样定义 IR:
// 指令:三地址码格式
enum Instr {
BinOp(Operand, BinOp, Operand, Operand) // dest = left op right
Copy(Operand, Operand) // dest = src
Call(Operand, String, Array[Operand]) // dest = func(args...)
}
// 终结指令:基本块的出口
enum Terminator {
CondBr(Operand, Int, Int) // if cond goto block1 else block2
Goto(Int) // goto block
Return(Operand) // return value
}
// 基本块
struct Block {
id : Int
instrs : Array[Instr] // 块内的指令序列
term : Terminator // 终结指令
preds : Array[Int] // 前驱块
succs : Array[Int] // 后继块
}
让我们看看之前的例子转换成 IR 后的样子:

现在,控制流的结构变得一目了然。Block 0 是入口,执行后根据条件跳转到 Block 1 或 Block 2。Block 1 和 Block 2 最终都跳向 Block 3,Block 3 执行返回操作。
这种结构有一个专门的名称:控制流图 (Control Flow Graph, CFG)。图的节点是基本块,边是跳转关系。其可视化表示如下:
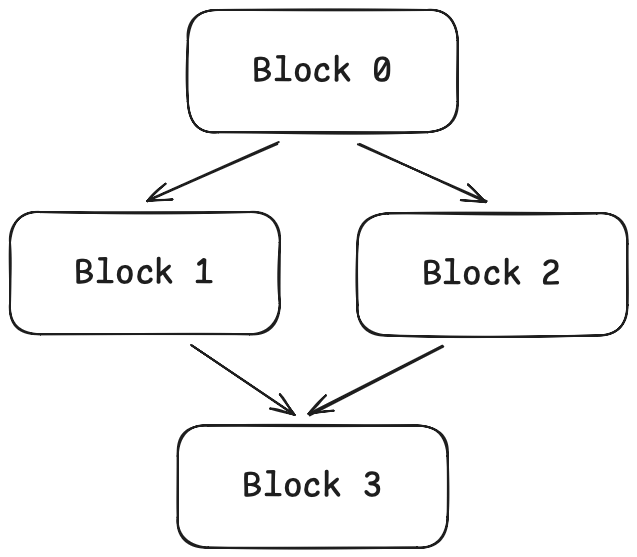
数据流分析:在 CFG 上“流动”信息
有了 CFG,我们就可以用一种非常优雅的方式进行分析:让信息在图上“流动”。
以“未初始化变量检测”为例。我们想知道:在程序的每个执行点,哪些变量已经被定义(初始化)过了?
我们可以在 CFG 上进行如下思考:
- 在程序入口(Block 0 的开头),只有函数参数是“已定义”的,局部变量都是“未定义”的。
- 每条赋值语句会“产生”一个定义。例如
x = 0 之后,x 就变为“已定义”状态。
- 每条赋值语句也会“杀死”之前的定义。例如
x = 1 会使之前 x = 0 的定义失效。
- 在控制流的汇合点(例如 Block 3 的开头),信息需要“合并”。Block 3 可能从 Block 1 到达,也可能从 Block 2 到达。如果一个变量在 Block 1 结尾是“已定义”的,但在 Block 2 结尾是“未定义”的,那么在 Block 3 开头它就是“可能未定义”的。
这就是数据流分析的基本思路。我们为每个基本块的入口和出口关联一个“状态”(在此例中,状态是“已定义变量”的集合),然后定义:
- 传递函数:给定一个基本块的入口状态,如何计算其出口状态?即模拟块内每条指令的效果。
- 合并函数:当多条控制流边汇合到一个点时,如何合并来自不同前驱的状态?例如取交集(要求所有前驱都已定义才算定义)或取并集(任一前驱定义了就算可能定义)。
接下来,我们从入口开始,不断迭代更新各个基本块的状态,直到所有块的状态不再变化(达到“不动点”)。
这个过程可以用一个通用的算法框架来实现:
- 将所有基本块加入待处理工作表。
- 从工作表中取出一个块。
- 根据其所有前驱块的状态和合并函数,计算该块的入口状态。
- 根据传递函数,计算该块的出口状态。
- 如果出口状态发生变化,则将该块的所有后继块加入工作表。
- 重复步骤 2-5,直到工作表为空。
最后,我们可以将这个框架抽象成一个通用函数,用户只需提供传递函数和合并函数即可:
struct ForwardConfig[T] {
init : T // 入口的初始状态
transfer : (Block, T) -> T // 传递函数:入口状态 -> 出口状态
merge : (T, T) -> T // 合并函数:多个状态 -> 一个状态
equal : (T, T) -> Bool // 判断状态是否相等(用于检测不动点)
copy : (T) -> T // 复制状态(避免共享引用)
}
fn forward_dataflow[T](fun_ir : FunIR, config : ForwardConfig[T]) -> Result[T] {
// 初始化每个块的状态
// 迭代直到不动点
// ...
}
这个框架的美妙之处在于其通用性。无论你分析的是什么问题(未初始化变量、空指针、整数溢出……),只要能为该问题定义出合适的传递函数和合并函数,就能套用同一个分析框架,而无需为每个新问题重写复杂的控制流迭代逻辑。
前向分析 vs 后向分析
刚才描述的是前向分析 (Forward Analysis):信息从程序入口向出口流动。但有些分析天然是后向的 (Backward Analysis)。
例如活跃变量分析 (Liveness Analysis):我们想知道在程序的每个点,哪些变量的值在之后还会被用到。这个问题需要从程序出口往回看。如果一个变量在某点之后不再被使用,那它就是“死”的,之前对它的赋值可能就是无用代码。
后向分析与前向分析是对称的:信息从出口向入口流动;传递函数的作用变为从“出口状态→入口状态”;合并函数作用于后继块的状态,而非前驱块。
struct BackwardConfig[T] {
init : T // 出口的初始状态
transfer : (Block, T) -> T // 传递函数:出口状态 -> 入口状态
merge : (T, T) -> T // 合并后继的状态
equal : (T, T) -> Bool
copy : (T) -> T
}
活跃变量分析的传递函数可以这样编写:
fn liveness_transfer(block : Block, out_state : LiveSet) -> LiveSet {
let live = out_state.copy()
// 从后向前处理指令(因为是后向分析)
for i = block.instrs.length() - 1; i >= 0; i = i - 1 {
let instr = block.instrs[i]
// 先移除这条指令定义的变量
match get_def(instr) { Some(v) => live.remove(v), None => () }
// 再加入这条指令使用的变量
for v in get_uses(instr) { live.add(v) }
}
live
}
为什么要“先移除定义,再加入使用”?考虑 x = x + 1 这条指令。在这条指令执行前,x 必须是活跃的(因为我们要读取它的旧值)。但在这条指令执行后,x 的旧值就不再需要了(因为我们已经写入了新值)。所以在后向分析中,我们需要先处理定义(消除旧值的活跃性),再处理使用(添加操作数的活跃性)。
对于合并函数,活跃变量分析通常使用并集:如果一个变量在任意一条出边上(即任意一个后继块入口)是活跃的,那么它在当前点就是活跃的。这是因为程序可能执行任意一条分支,只要变量在后续有可能被用到,它在当前点就必须被视为活跃的。
检测未初始化变量
现在,让我们来实现一个实用的分析:检测可能未初始化的变量。
思路是使用定值可达性分析 (Reaching Definitions Analysis) 来跟踪每个程序点可能到达的变量定义。如果在某个点使用了一个变量,但没有任何定义能到达这个点,那么就发生了未初始化使用。
定值可达性分析是前向分析。每条赋值语句产生一个新定义,同时“杀死”同一变量的旧定义。在控制流汇合点,来自多个分支的定义集合取并集(因为任意一条路径上的定义都可能到达)。
有了定值可达性信息,检测就变得直接了:
for block in fun_ir.blocks {
let mut defs = reaching.defs_in[block.id]
for instr in block.instrs {
// 检查使用的变量
for var in get_uses(instr) {
if not(defs.has_def(var)) && not(is_param(var)) {
warn("Variable may be uninitialized: " + var)
}
}
// 更新定义
match get_def(instr) {
Some(var) => defs = defs.update(var, current_def)
None => ()
}
}
}
在我们的示例代码上测试,分析器将成功输出:
Warning: Variable may be uninitialized: x (at Block 3, Return)
这正是我们期望的结果!
MCIL:真实的 C 语言分析
刚才用于教学的项目称为 MiniCIL,它是一个参考 CIL 设计的简易教学项目,其 DSL 仅包含几种简单的语句。真实的 C 语言要复杂得多。为此,我们基于 MoonBit 实现了一个完整的 CIL:MCIL,它能够处理完整的 C 语言,并执行复杂的静态分析工作。
MCIL 与 MiniCIL 的架构一脉相承:
C 源代码 → Lexer/Parser → AST → cabs2cil → CIL IR → 分析
MCIL 的词法分析器需要处理 C 语言的所有 Token:sizeof、typedef、struct、-> 等等。语法分析器需要解析 C 语言的完整语法:函数指针、复合字面量、指定初始化器、GCC 扩展等。cabs2cil 转换模块则需要处理类型推导、隐式转换、常量折叠、作用域解析等复杂问题。
然而,它们核心的分析框架和思想是相通的。理解了 MiniCIL,阅读 MCIL 的代码就会容易许多。
下面是一个 MCIL 对 C 语言代码进行静态分析的实例输出:
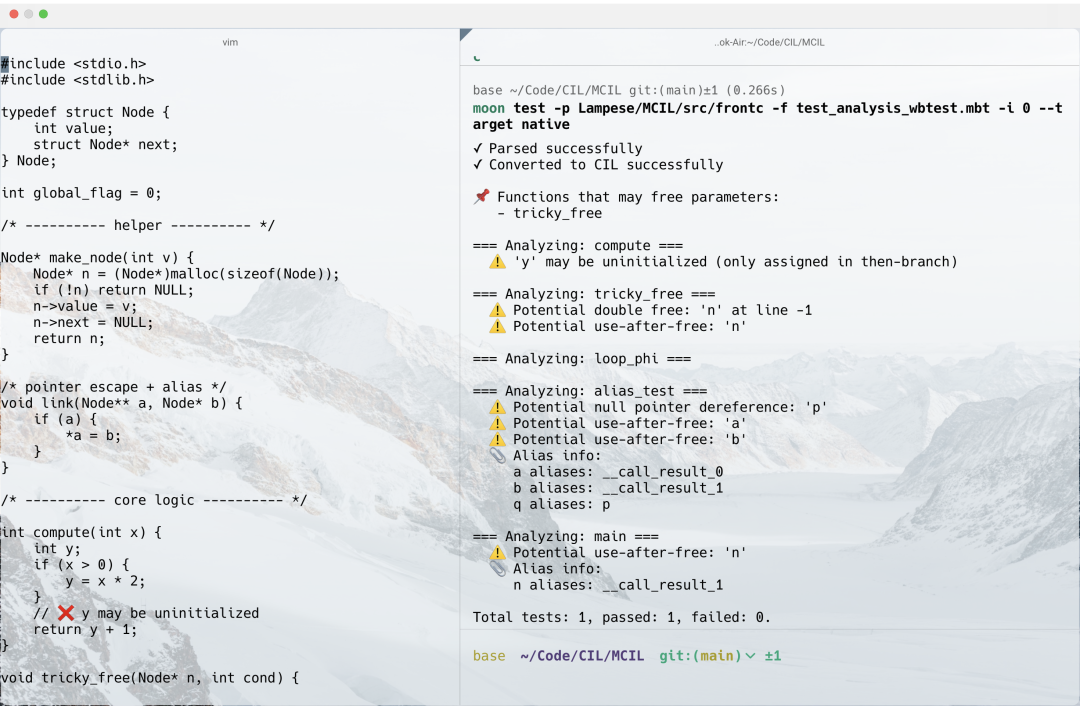
C语言分析会遇到的困难
如果你对 MCIL 的实现细节感兴趣,那么了解 C 语言静态分析面临的主要挑战至关重要:
- 指针和别名 (Aliasing):我们教学用的 DSL 只有简单变量,但 C 语言有指针。当你写
*p = 1 时,你修改的是哪个变量?如果 p 可能指向 x 或 y,这条语句就可能修改两者中的任何一个。更棘手的是,p 和 q 可能指向同一块内存(形成别名),修改 *p 会影响 *q 的值。跟踪指针的指向关系称为别名分析,这是静态分析中最困难的问题之一。
- 过程间分析 (Interprocedural Analysis):我们的教学分析仅针对单个函数。但当你调用
foo(x) 时,foo 函数会修改 x 指向的内存吗?会释放它吗?如果只分析单个函数,这些信息都会丢失。过程间分析需要构建调用图,并跟踪函数之间的数据流。MCIL 实现了简单的过程间分析,可以检测 free(p) 之后对 p 的使用。
- 复杂的类型系统:C 语言的类型系统充满陷阱:数组退化成指针、函数指针的复杂语法、结构体的内存布局、联合体的类型双关等。MCIL 的
cabs2cil 转换会处理这些问题,将它们规范化为统一的形式。例如,所有隐式类型转换都会变成显式的 CastE,数组到指针的转换通过 StartOf 操作表达。
- C语言的未定义行为 (Undefined Behavior):有符号整数溢出、空指针解引用、越界访问、释放后使用 (use-after-free)……C 语言标准将这些都定义为“未定义行为”,编译器可以假设它们不会发生。静态分析工具需要检测这些问题,但又不能过于保守导致误报过多(因为有些代码可能特意利用这些行为实现特定功能)。
总结
在本文中,我们系统地学习了静态分析的基本流程:从源代码出发,经过词法分析、语法分析得到 AST,再将其转换为由基本块和显式跳转构成的 CFG,最后利用数据流分析框架在 CFG 上进行迭代计算,直至达到不动点。我们以活跃变量分析和未初始化变量检测为例,展示了这一分析思想的通用性与强大之处。
值得一提的是,CIL 框架诞生于21世纪初,在2002年的论文《CIL: Intermediate Language and Tools for Analysis and Transformation of C Programs》中首次发表。尽管它相对精简,但至今仍是学习静态分析的优秀范例。随着编译器技术的发展,以 SSA (Static Single Assignment) 形式为核心的 LLVM/Clang 编译基础设施日趋成熟,并在工业界成为事实标准。这类框架在统一中间表示、跨阶段优化以及代码生成方面展现出更强的通用性与扩展性,因而在实际工程中逐渐取代了以 CIL 为代表的、主要面向单一语言静态分析的中间表示工具。感兴趣的读者可以进一步探索这些更现代、更强大的静态分析技术。
参考文献
希望这篇深入浅出的解析能帮助你揭开静态分析工具的神秘面纱。如果你想与更多开发者交流编译原理、程序分析或 MoonBit 相关的技术,欢迎访问云栈社区,在那里分享你的见解或提出问题。
 发表于 2026-1-14 03:21:23
|
查看: 234|
回复: 0
发表于 2026-1-14 03:21:23
|
查看: 234|
回复: 0
