
在 AI 辅助编程领域,一个核心问题长期存在:我们更应该追求更强大的基座模型,还是构建更精密的工程架构?近日,Meta 与哈佛大学的研究人员联合开源了 Confucius Code Agent (CCA),为我们提供了一个值得深思的答案。这是一个基于 Confucius SDK 构建的开源 AI软件工程师,专门为处理工业级规模的代码仓库和长周期会话而设计。
本文将基于 arXiv 上的最新论文 “Confucius Code Agent: Scalable Agent Scaffolding for Real-World Codebases”,深入解析 CCA 如何通过层级工作记忆、持久化笔记以及元代理设计,在 SWE-Bench Pro 等硬核基准测试中,让中等体量的模型表现超越了顶级配置的模型。
论文地址:https://arxiv.org/pdf/2512.10398
1. 核心理念:脚手架(Scaffold)即本体
Confucius SDK 的设计哲学并非将脚手架视为对大语言模型(LLM)的一层简单包装,而是将其作为首要的设计问题。研究团队认为,当真正的创新从模型本身转移到代理脚手架和工具栈时,中等规模模型的潜力将被极大地释放。
该 SDK 围绕三个核心维度构建架构:
- 代理体验 (Agent Experience):控制模型“看到”的内容,包括上下文布局、工作记忆和工具执行结果。
- 用户体验 (User Experience):关注人类工程师的可读性,例如执行轨迹、代码差异对比和安全防护。
- 开发者体验 (Developer Experience):侧重于代理本身的可观测性、配置与调试。
CCA 正是这一架构理念的具体实现。它通过一种被称为“元代理”的机制,以构建、测试、改进的循环,自动化地合成和优化代理配置。
2. 攻克长窗口难题:层级工作记忆
在 SWE-Bench Pro 的真实测试场景中,解决一个复杂问题往往需要推理数十个文件并进行多轮交互。传统的“滑动窗口”机制在面对这种长视距任务时显得力不从心——要么丢失关键上下文,要么迅速耗尽模型的 Token 限制。
Confucius SDK 引入了 层级工作记忆 机制来应对这一挑战:
- 轨迹分区:将交互轨迹划分为不同的作用域。
- 压缩与摘要:不仅记录步骤,还会对过去的操作进行摘要,并为后续轮次保留压缩后的上下文。
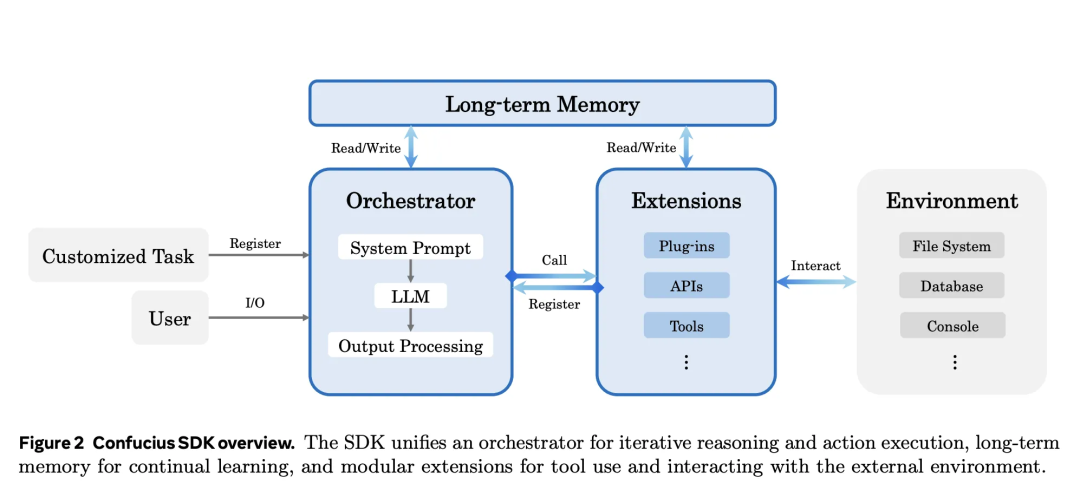
这种设计确保了代理在将 Token 使用量控制在模型限制范围内的同时,依然能够“记住”关键的代码补丁、错误日志和设计决策。这证明了高效的编码代理需要显式的记忆架构,而不仅仅依赖于模型自身的上下文窗口。
3. 像人类一样成长:跨会话的持久化笔记
CCA 的另一项重要突破在于其 持久化笔记系统。
经验的积累对人类工程师的成长至关重要。CCA 使用一个专门的笔记代理,将执行轨迹转化为结构化的 Markdown 笔记。这些笔记捕捉了特定任务的解决策略、代码仓库的惯例以及常见的失败模式。
数据验证效果:研究团队在 151 个 SWE-Bench Pro 实例上进行了对比测试(使用 Claude 4.5 Sonnet 模型):
- 第一轮(无笔记):代理从零开始解决任务并生成笔记。
- 第二轮(有笔记):代理读取第一轮生成的笔记。
结果显示,在引入笔记机制后:
- 平均交互轮次从 64 降至 61。
- Token 使用量从约 104k 降至 93k。
- 一次通过率从 53.0% 提升至 54.4%。
这表明笔记不仅仅是日志,它们真正充当了有效的“跨会话记忆”,赋予了 AI 学习和进化的能力。
4. 性能实测:脚手架优于模型尺寸
在 SWE-Bench Pro(包含 731 个需要修改真实 GitHub 仓库并通过测试的问题)的评估中,Confucius Code Agent 展现了惊人的能力。
下图展示了不同模型在 SWE-Bench-Pro 基准上的解决率对比:
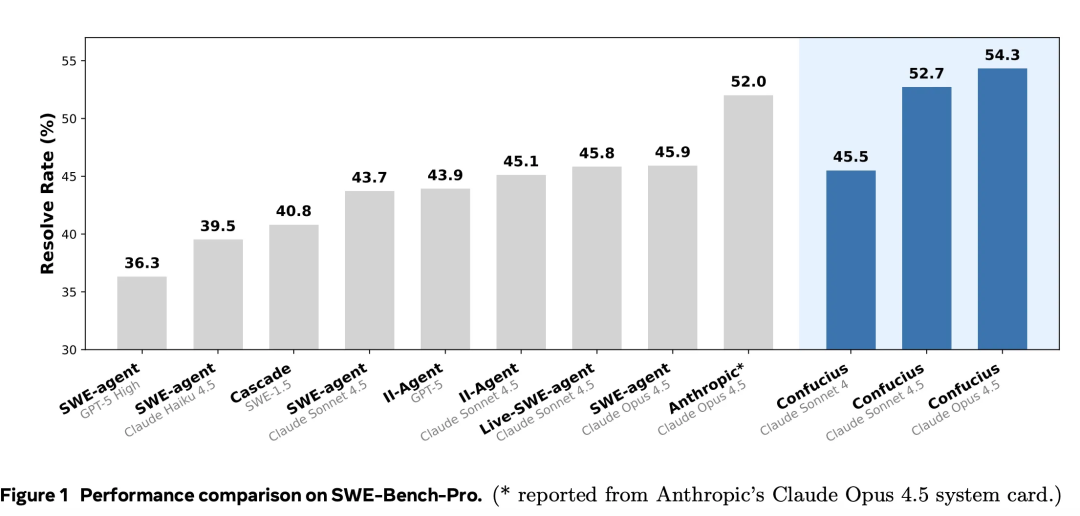
从对比数据中可以获得一个关键洞察:使用 Confucius Code Agent 脚手架的 Claude 4.5 Sonnet(中等规模模型)取得了 52.7 的得分,击败了使用普通脚手架的 Claude 4.5 Opus(顶级规模模型,得分 52.0)。
这一结果有力地支撑了本文的核心论点:一个强大的工程脚手架对最终效果的贡献,可以抵消甚至超越模型参数规模带来的优势。
此外,在面对多文件编辑任务时,CCA 也表现出了出色的稳定性。数据显示,即使需要编辑的文件数量超过 10 个,其一次通过率依然保持在 44.4 的高位,证明了其在大型代码库中具备良好的鲁棒性。
5. 工具复杂度的影响
除了记忆机制,工具的使用策略同样是影响代理性能的关键变量。研究团队在 SWE-Bench Pro 的 100 个子集上进行了消融实验。
在使用 Claude 4.5 Sonnet 模型的情况下:
- 简单的工具配置:一次通过率为 44.0。
- 丰富的高级工具处理策略:一次通过率飙升至 51.6。
这说明,代理如何选择工具、如何对工具调用进行排序,以及如何从工具报错中恢复,其重要性几乎等同于对基座模型的选择。
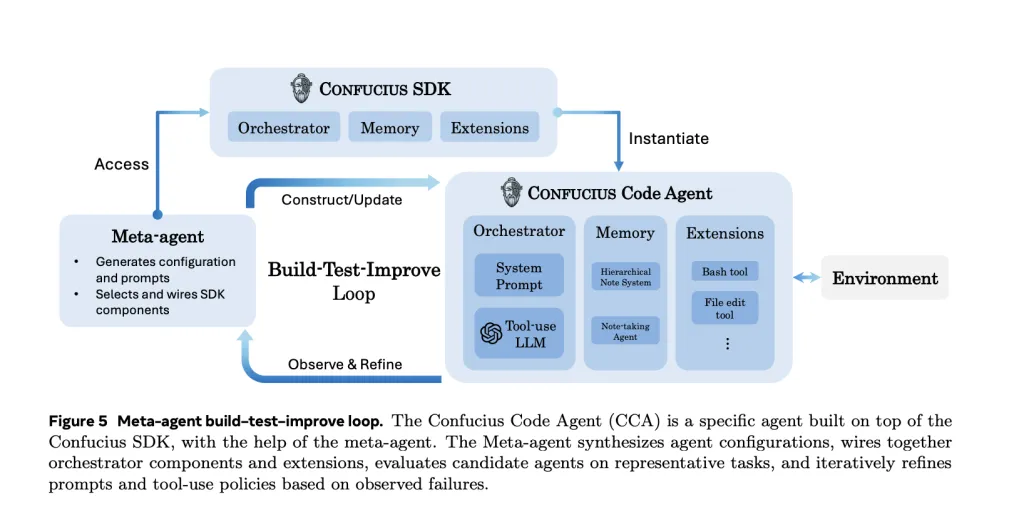
结语
Confucius Code Agent 的开源标志着 AI 软件工程领域的一个转折点。它向我们证明,单纯依赖基座模型能力的提升并非解决复杂工程问题的唯一路径。
通过 层级工作记忆 解决上下文限制,通过 持久化笔记 实现经验复用,再配合 元代理 进行自动化调优,Confucius SDK 展示了一条更为工程化和可落地的路径。对于开发者而言,这意味着未来的 AI 编程助手将不再是一个只会补全代码的“插件”,而是一个真正能够理解项目架构、具备长期记忆并能自我进化的“数字同事”。
你对这类能处理真实复杂任务的AI代理感兴趣吗?欢迎到云栈社区的开发者板块交流讨论。
 发表于 2026-1-15 02:08:05
|
查看: 162|
回复: 0
发表于 2026-1-15 02:08:05
|
查看: 162|
回复: 0
