2. 内存系统调用全景图
2.1 用户空间与内核空间的鸿沟
让我们先理解一个基本概念:在现代操作系统中,用户进程运行在受保护的“用户空间”,而操作系统内核运行在特权级的“内核空间”。这两者之间有一道严格的边界,跨越这道边界的唯一合法方式就是系统调用。
┌─────────────────────────────────────────────────────────────┐
│ 用户空间 (User Space) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 进程 A │ │ 进程 B │ │ 进程 C │ │
│ │ malloc() │ │ malloc() │ │ malloc() │ │
│ │ free() │ │ free() │ │ free() │ │
│ └──────┬──────┘ └──────┬──────┘ └──────┬──────┘ │
│ │ │ │ │
│ └────────────────┼────────────────┘ │
│ │ │
├──────────────────────────┼────────────────────────────────┤
│ 系统调用接口 │ 内核空间 (Kernel Space) │
│ (syscall) │ ┌──────────────────────────┐ │
│ │ │ 内存管理子系统 │ │
│ brk() ──────────┼─▶│ ┌─────────────────┐ │ │
│ mmap() ─────────┼─▶│ │ 虚拟内存管理 │ │ │
│ munmap() ───────┼─▶│ │ 页面分配器 │ │ │
│ mremap() ───────┼─▶│ │ 页面回收器 │ │ │
│ mprotect() ─────┼─▶│ │ 页表管理 │ │ │
│ mlock() ────────┼─▶│ └─────────────────┘ │ │
│ │ │ │ │
│ │ └──────────────────────────┘ │
└──────────────────────────┴────────────────────────────────┘
图1: 用户空间与内核空间的内存管理交互
2.2 核心内存系统调用概览
Linux提供了多种内存相关的系统调用,每种都有其特定的用途和设计考量:
| 系统调用 |
主要功能 |
适用场景 |
性能特点 |
| brk/sbrk |
调整程序数据段结束位置 |
传统的堆内存分配 |
简单快速,但灵活性差 |
| mmap/munmap |
内存映射文件或匿名内存 |
大内存分配、文件映射 |
灵活强大,支持多种映射类型 |
| mremap |
重新映射虚拟内存区域 |
调整已映射内存大小 |
避免数据复制,效率高 |
| mprotect |
修改内存区域保护属性 |
内存权限控制、调试 |
轻量级权限变更 |
| mlock/munlock |
锁定/解锁内存页面 |
实时应用、密码处理 |
确保页面驻留物理内存 |
| mincore |
查询页面驻留状态 |
内存使用分析 |
了解页面缓存情况 |
3. 核心系统调用深度解析
3.1 brk():最基础的堆内存管理
3.1.1 工作原理
brk() 系统调用是Linux中最原始的内存分配机制。它通过调整程序的“break point”(程序数据段的结束位置)来分配或释放内存。在C语言中,malloc() 函数在底层通常使用 brk() 来管理小内存块的分配。
// brk系统调用的用户空间接口
#include <unistd.h>
int brk(void *addr);
void *sbrk(intptr_t increment);
生活中的比喻:把brk想象成一个可伸缩的书架。书架的一端是固定的(程序起始位置),另一端(break point)可以前后移动。当需要更多空间时,就把隔板向后推;当空间过剩时,就把隔板向前拉。简单直接,但不够灵活——你只能调整书架的大小,不能在里面重新布置书籍。
3.1.2 内核实现机制
在内核中,brk() 的实现围绕着进程的 mm_struct 数据结构展开,这是内存管理的核心。
// 内核中mm_struct的部分定义(简化版)
struct mm_struct {
struct vm_area_struct *mmap; /* 虚拟内存区域链表 */
struct rb_root mm_rb; /* 虚拟内存区域红黑树 */
unsigned long start_brk, brk; /* 堆的起始和结束地址 */
unsigned long start_stack; /* 栈的起始地址 */
unsigned long total_vm; /* 总虚拟内存页数 */
unsigned long locked_vm; /* 锁定的内存页数 */
// ... 其他字段
};
// brk系统调用的内核实现(简化逻辑)
SYSCALL_DEFINE1(brk, unsigned long, brk)
{
struct mm_struct *mm = current->mm;
unsigned long newbrk, oldbrk;
// 1. 对齐边界检查
newbrk = PAGE_ALIGN(brk);
oldbrk = PAGE_ALIGN(mm->brk);
// 2. 如果新brk小于旧brk,释放内存
if (brk <= mm->brk) {
do_munmap(mm, newbrk, oldbrk-newbrk, NULL);
goto set_brk;
}
// 3. 如果新brk大于旧brk,分配内存
if (find_vma_intersection(mm, oldbrk, newbrk+PAGE_SIZE))
return -ENOMEM;
if (do_brk(oldbrk, newbrk-oldbrk) != oldbrk)
return -ENOMEM;
set_brk:
mm->brk = brk;
return 0;
}
3.1.3 brk的局限性
虽然 brk() 简单高效,但它有明显的局限性:
- 只能调整堆的末尾,不能释放中间的“空洞”
- 内存碎片问题严重,长期运行的程序容易产生内存碎片
- 不适合大内存分配,可能与其他内存区域冲突
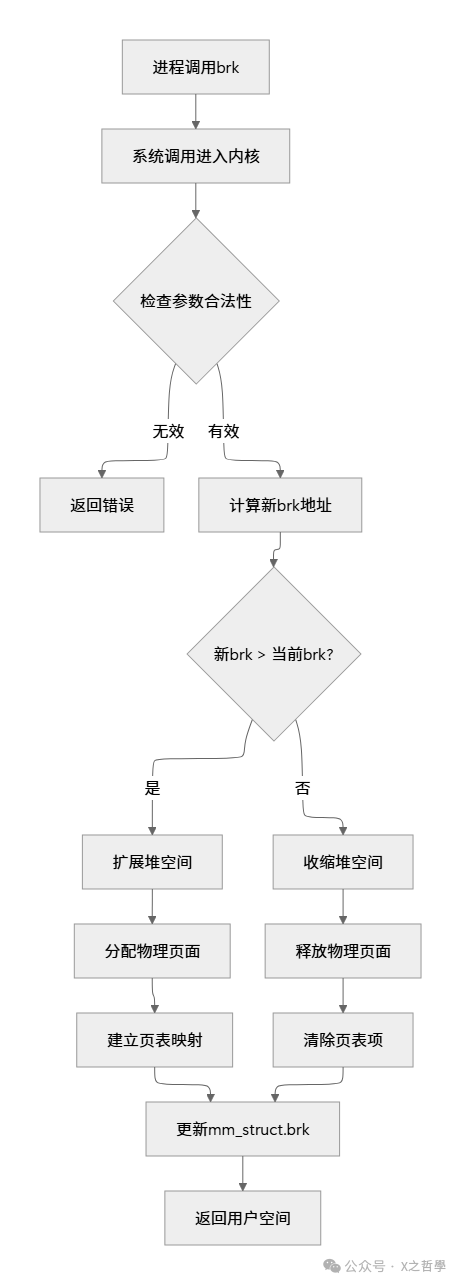
图2: brk()系统调用执行流程图
3.2 mmap():灵活的内存映射机制
3.2.1 设计哲学与能力
如果说 brk() 是简单的伸缩书架,那么 mmap() 就是万能的空间规划师。它不仅能创建新的内存区域,还能将文件、设备内存映射到进程地址空间,实现了内存与外部资源的无缝对接。
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
int munmap(void *addr, size_t length);
mmap的核心能力矩阵:
| 映射类型 |
flags参数 |
典型应用 |
优势 |
| 私有匿名映射 |
MAP_PRIVATE | MAP_ANONYMOUS |
大内存分配、进程堆扩展 |
写时复制、高效零页初始化 |
| 共享匿名映射 |
MAP_SHARED | MAP_ANONYMOUS |
进程间通信、共享内存 |
进程间数据共享 |
| 私有文件映射 |
MAP_PRIVATE |
程序加载、动态链接库 |
节省物理内存、按需加载 |
| 共享文件映射 |
MAP_SHARED |
内存数据库、文件编辑 |
文件与内存同步 |
3.2.2 内核实现架构
mmap() 在内核中的实现是一个复杂但优雅的过程,涉及多个子系统的协作。
// vm_area_struct: 虚拟内存区域的核心数据结构
struct vm_area_struct {
unsigned long vm_start; /* 区域起始地址 */
unsigned long vm_end; /* 区域结束地址 */
/* 链接结构 */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
/* 区域属性 */
pgprot_t vm_page_prot; /* 访问权限 */
unsigned long vm_flags; /* 标志位 */
/* 操作函数集 */
const struct vm_operations_struct *vm_ops;
/* 文件映射相关 */
struct file *vm_file; /* 映射的文件 */
unsigned long vm_pgoff; /* 文件中的偏移 */
/* 匿名映射相关 */
struct anon_vma *anon_vma; /* 匿名页反向映射 */
// ... 其他字段
};
// vm_operations_struct: VMA操作函数表
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);
void (*close)(struct vm_area_struct * area);
int (*fault)(struct vm_area_struct *vma, struct vm_fault *vmf);
int (*page_mkwrite)(struct vm_area_struct *vma, struct vm_fault *vmf);
// ... 其他操作
};
3.2.3 mmap执行流程详解
让我们通过一个具体例子理解mmap的完整流程:
// 用户空间示例:使用mmap分配1GB大内存
#define GB (1024*1024*1024UL)
int main() {
// 分配1GB私有匿名内存(不立即分配物理页)
void *addr = mmap(NULL, 1*GB, PROT_READ|PROT_WRITE,
MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
if (addr == MAP_FAILED) {
perror("mmap failed");
return 1;
}
// 首次访问触发缺页异常,分配物理页
((char*)addr)[0] = 'A';
// 使用后解除映射
munmap(addr, 1*GB);
return 0;
}
内核中的mmap执行流程:
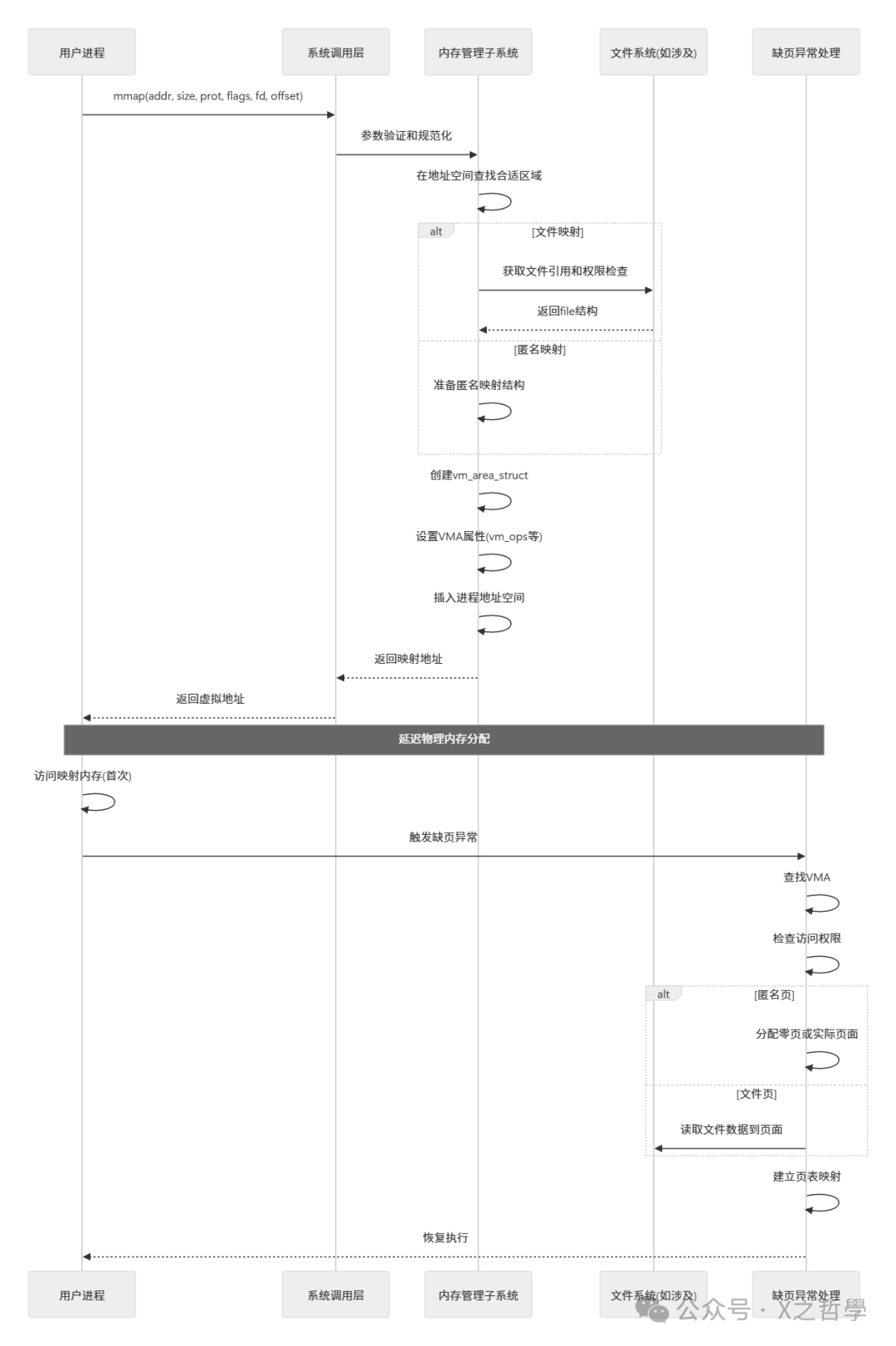
图3: mmap()系统调用与缺页处理的时序图
3.3 写时复制(Copy-on-Write)机制
Linux内存管理中最精妙的特性之一就是写时复制。这不仅是性能优化的关键,也是fork()系统调用能够高效创建进程的基础。
生活中的比喻:想象一对双胞胎共用一本教科书。只要他们都只是阅读,就共享同一本书。但当其中一个需要在书上做笔记(写入)时,老师会立即给他一本新的空白书,他只复制需要修改的那几页,而不是整本书。这就是写时复制的精髓——延迟复制直到真正需要时。
// 写时复制的内核实现关键逻辑
static int do_wp_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct page *old_page, *new_page;
// 获取原页面
old_page = vm_normal_page(vma, vmf->address, vmf->pte);
// 检查是否真正需要复制
if (!old_page || PageAnon(old_page)) {
// 创建新页面
new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, vmf->address);
// 复制页面内容
copy_user_highpage(new_page, old_page, vmf->address, vma);
// 建立新的页表映射
entry = mk_pte(new_page, vma->vm_page_prot);
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
// 更新反向映射
page_add_new_anon_rmap(new_page, vma, vmf->address, false);
// 释放旧页面的引用(如果不再需要)
put_page(old_page);
}
return VM_FAULT_WRITE;
}
4. 内存系统调用的实现框架
4.1 Linux内存管理三层架构
Linux内存管理采用清晰的三层架构,每层都有明确的职责:
┌─────────────────────────────────────────────────────────────┐
│ 用户空间接口层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ malloc() │ │ free() │ │ mmap() │ │ brk() │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────────┘
│
┌─────────────────────────────────────────────────────────────┐
│ 内核系统调用层 │
│ ┌────────────────────────────────────────┐ │
│ │ sys_brk(), sys_mmap(), etc. │ │
│ └────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
┌─────────────────────────────────────────────────────────────┐
│ 内存管理子系统核心层 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 虚拟内存管理 │ │ 页面分配器 │ │ 页面回收器 │ │
│ │ │ │ (伙伴系统) │ │ (kswapd) │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 反向映射机制 │ │ 页表管理 │ │ slab分配器 │ │
│ │ │ │ │ │ │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
┌─────────────────────────────────────────────────────────────┐
│ 硬件抽象层 │
│ ┌────────────────────────────────────────┐ │
│ │ 体系结构相关代码(x86, ARM, etc.) │ │
│ └────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
图4: Linux内存管理的三层架构
4.2 核心数据结构关系网
理解Linux内存管理的关键在于把握几个核心数据结构之间的关系:
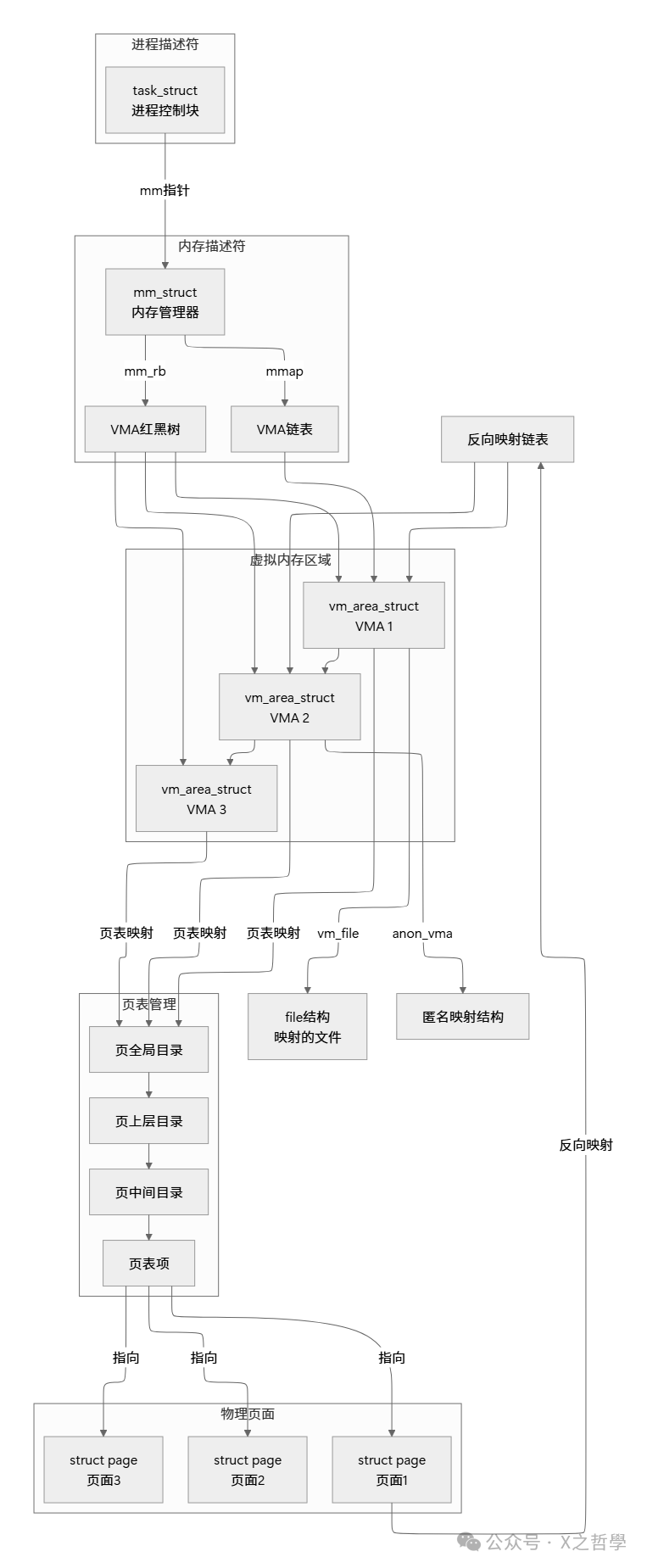
图5: Linux内存管理核心数据结构关系图
4.3 缺页异常处理机制
缺页异常是虚拟内存系统的核心机制,它实现了按需分配和延迟加载。
// 缺页异常处理的主要流程(x86架构)
static __always_inline void
handle_pte_fault(struct vm_fault *vmf)
{
if (!vmf->pte) {
// 页表项不存在,需要分配新页面
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf); // 匿名页面
else
return do_fault(vmf); // 文件映射页面
}
if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma))
return do_numa_page(vmf); // NUMA页面迁移
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf); // 交换页面
if (pte_write(vmf->orig_pte) && vma_wants_writenotify(vmf->vma)) {
// 写时复制处理
return do_wp_page(vmf);
}
// 其他情况:权限错误等
return do_page_fault(vmf);
}
5. 实战:内存系统调用使用示例
5.1 实现一个简单的内存分配器
让我们通过实现一个简单的内存分配器来理解这些系统调用如何协同工作。这个例子展示了如何用C/C++将底层系统调用封装成更易用的接口。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/mman.h>
#include <string.h>
// 简单内存分配器结构
struct simple_allocator {
void *heap_start; // 堆起始地址
void *heap_end; // 堆结束地址
void *brk; // 当前break位置
size_t chunk_size; // 分配块大小
};
// 初始化分配器
void allocator_init(struct simple_allocator *alloc,
size_t initial_size, size_t chunk_size) {
// 使用mmap分配初始内存(更灵活可控)
alloc->heap_start = mmap(NULL, initial_size,
PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS,
-1, 0);
if (alloc->heap_start == MAP_FAILED) {
perror("mmap failed");
exit(EXIT_FAILURE);
}
alloc->heap_end = alloc->heap_start + initial_size;
alloc->brk = alloc->heap_start;
alloc->chunk_size = chunk_size;
printf("Allocator initialized: %p - %p\n",
alloc->heap_start, alloc->heap_end);
}
// 简单的分配函数
void* allocator_malloc(struct simple_allocator *alloc, size_t size) {
// 对齐到chunk_size
size_t aligned_size = (size + alloc->chunk_size - 1) &
~(alloc->chunk_size - 1);
// 检查是否有足够空间
if (alloc->brk + aligned_size > alloc->heap_end) {
// 空间不足,尝试扩展
size_t current_size = alloc->heap_end - alloc->heap_start;
size_t new_size = current_size * 2;
void *new_heap = mremap(alloc->heap_start, current_size,
new_size, MREMAP_MAYMOVE);
if (new_heap == MAP_FAILED) {
return NULL;
}
alloc->heap_start = new_heap;
alloc->heap_end = new_heap + new_size;
}
void *ptr = alloc->brk;
alloc->brk += aligned_size;
return ptr;
}
// 示例使用
int main() {
struct simple_allocator alloc;
// 初始化分配器:1MB初始空间,4KB对齐
allocator_init(&alloc, 1024*1024, 4096);
// 分配内存
int *array = allocator_malloc(&alloc, 100 * sizeof(int));
if (!array) {
fprintf(stderr, "Allocation failed\n");
return 1;
}
// 使用内存
for (int i = 0; i < 100; i++) {
array[i] = i * i;
}
// 输出验证
printf("Array[10] = %d\n", array[10]);
// 注意:简单分配器不支持free,实际程序结束由系统回收
return 0;
}
5.2 共享内存通信示例
// 进程A:创建共享内存并写入数据
#include <stdio.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#define SHM_SIZE 4096
#define SHM_NAME "/my_shm"
int main() {
// 创建共享内存对象
int fd = shm_open(SHM_NAME, O_CREAT | O_RDWR, 0666);
ftruncate(fd, SHM_SIZE);
// 映射共享内存
void *ptr = mmap(NULL, SHM_SIZE,
PROT_READ | PROT_WRITE,
MAP_SHARED, fd, 0);
// 写入数据
sprintf(ptr, "Hello from Process A!");
printf("Data written to shared memory\n");
printf("Press Enter to exit...");
getchar();
// 清理
munmap(ptr, SHM_SIZE);
close(fd);
shm_unlink(SHM_NAME);
return 0;
}
// 进程B:读取共享内存数据
int main() {
// 打开共享内存对象
int fd = shm_open(SHM_NAME, O_RDONLY, 0666);
// 映射共享内存
void *ptr = mmap(NULL, SHM_SIZE,
PROT_READ,
MAP_SHARED, fd, 0);
// 读取数据
printf("Read from shared memory: %s\n", (char*)ptr);
// 清理
munmap(ptr, SHM_SIZE);
close(fd);
return 0;
}
6. 调试与性能分析工具
6.1 常用工具命令汇总
| 工具类别 |
工具名称 |
主要用途 |
示例命令 |
| 系统调用跟踪 |
strace |
跟踪系统调用 |
strace -e brk,mmap ./program |
| 内存映射查看 |
pmap |
查看进程内存映射 |
pmap -x <pid> |
| 虚拟内存统计 |
vmstat |
系统内存统计 |
vmstat 1 |
| 进程内存信息 |
proc文件系统 |
详细内存信息 |
cat /proc/<pid>/maps |
| 内存泄漏检测 |
valgrind |
内存错误检测 |
valgrind --leak-check=full ./program |
| 性能分析 |
perf |
内存访问分析 |
perf mem record ./program |
6.2 /proc文件系统内存信息详解
/proc文件系统提供了丰富的内存信息,是调试内存问题的重要工具:
# 查看进程内存映射
cat /proc/self/maps
# 输出示例:
00400000-00401000 r-xp 00000000 08:01 123456 /bin/cat # 代码段
00600000-00601000 r--p 00000000 08:01 123456 /bin/cat # 数据段
00601000-00602000 rw-p 00001000 08:01 123456 /bin/cat # BSS段
7ffff7a0e000-7ffff7bd0000 r-xp 00000000 08:01 789012 /lib/x86_64-linux-gnu/libc-2.27.so
7ffff7bd0000-7ffff7dd0000 ---p 001c2000 08:01 789012 /lib/x86_64-linux-gnu/libc-2.27.so
7ffff7dd0000-7ffff7dd4000 r--p 001c2000 08:01 789012 /lib/x86_64-linux-gnu/libc-2.27.so
7ffff7dd4000-7ffff7dd6000 rw-p 001c6000 08:01 789012 /lib/x86_64-linux-gnu/libc-2.27.so
7ffff7dd6000-7ffff7dda000 rw-p 00000000 00:00 0 # 匿名映射
7ffff7dda000-7ffff7dfd000 r-xp 00000000 08:01 345678 /lib/x86_64-linux-gnu/ld-2.27.so
7ffff7fde000-7ffff7fe1000 rw-p 00000000 00:00 0 # 栈
7ffff7ff7000-7ffff7ffa000 r--p 00000000 00:00 0 # vdso
7ffff7ffa000-7ffff7ffc000 r-xp 00000000 00:00 0 # vsyscall
7ffff7ffc000-7ffff7ffd000 r--p 00022000 08:01 345678 /lib/x86_64-linux-gnu/ld-2.27.so
7ffff7ffd000-7ffff7ffe000 rw-p 00023000 08:01 345678 /lib/x86_64-linux-gnu/ld-2.27.so
7ffff7ffe000-7ffff7fff000 rw-p 00000000 00:00 0
7ffffffdd000-7ffffffff000 rw-p 00000000 00:00 0 # 栈(主线程)
6.3 使用gdb调试内存问题
# 1. 启动gdb调试程序
gdb ./my_program
# 2. 设置断点在内存相关函数
(gdb) break mmap
(gdb) break brk
# 3. 运行程序
(gdb) run
# 4. 当断点触发时,查看调用栈
(gdb) backtrace
# 5. 查看内存映射信息
(gdb) info proc mappings
# 6. 查看特定内存区域内容
(gdb) x/32x 0x7ffff7a0e000
# 7. 监控内存写入(watchpoint)
(gdb) watch *(int*)0x7ffff7dd6000
7. 高级主题:NUMA、大页和内存压缩
7.1 NUMA(非统一内存访问)支持
在多处理器系统中,NUMA架构对内存性能有重要影响。Linux提供了相应的系统调用和策略:
// 设置NUMA内存策略
#include <numaif.h>
// 在指定节点分配内存
void* numa_alloc_onnode(size_t size, int node);
// 绑定当前进程到指定节点
long set_mempolicy(int mode, const unsigned long *nodemask,
unsigned long maxnode);
7.2 大页(Huge Page)支持
大页可以减少TLB缺失,提高内存访问性能:
// 使用大页分配内存
void *addr = mmap(NULL, 2*1024*1024, // 2MB大页
PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_HUGETLB,
-1, 0);
7.3 内存压缩(zswap, zram)
Linux内核的内存压缩机制可以在内存紧张时透明地压缩页面:
# 查看内存压缩统计
cat /sys/kernel/debug/zswap/stored_pages
cat /sys/kernel/debug/zswap/pool_total_size
8. 性能优化最佳实践
8.1 内存分配策略选择
| 场景 |
推荐方法 |
理由 |
注意事项 |
| 小内存频繁分配 |
标准malloc + brk |
缓存友好,开销小 |
注意内存碎片 |
| 大内存分配(>128KB) |
mmap匿名映射 |
避免堆碎片,独立管理 |
触发缺页开销 |
| 文件读写 |
mmap文件映射 |
零拷贝,自动同步 |
文件大小限制 |
| 进程间共享 |
mmap共享映射 |
高效IPC |
需要同步机制 |
| 实时性要求高 |
mlock锁定页面 |
避免交换延迟 |
减少可用内存 |
8.2 常见内存问题诊断
# 1. 检查内存泄漏
valgrind --tool=memcheck --leak-check=full ./program
# 2. 检查内存越界
valgrind --tool=memcheck --track-origins=yes ./program
# 3. 分析内存使用趋势
watch -n 1 'ps -eo pid,comm,rss,vsz | grep my_program'
# 4. 监控缺页异常
perf stat -e page-faults ./program
# 5. 分析内存访问模式
perf record -e cache-misses ./program
9. 总结
Linux内存系统调用体现了操作系统设计的核心智慧:在简单与复杂之间寻找平衡,在安全与性能之间取得妥协。通过深入分析brk、mmap等系统调用的工作原理,我们可以看到Linux如何通过精心设计的抽象层和高效的实现机制,为应用程序提供强大而灵活的内存管理能力。
9.1 核心设计思想回顾
- 分层抽象:从物理内存到虚拟地址空间的层层抽象,每层都有明确的职责边界。
- 延迟分配:通过缺页异常实现按需分配,提高内存使用效率。
- 写时复制:最大化共享,最小化复制,平衡性能与资源使用。
- 统一接口:无论文件、设备还是匿名内存,都通过相同的mmap接口访问。
9.2 未来发展趋势
随着硬件技术的发展,Linux内存管理也在不断演进:
- 异构内存系统:对DRAM、NVM、GPU内存的统一管理。
- 智能预取:基于机器学习的内存访问模式预测。
- 安全增强:内存安全特性如MTE(Memory Tagging Extension)。
- 量子计算影响:量子内存管理的新范式探索。
希望这篇对Linux内存系统调用的深度解析能帮助你更好地理解操作系统底层的运作机制。如果你想与更多开发者交流系统底层知识,欢迎访问云栈社区,那里有更多深入的技术讨论和资源分享。
 发表于 2026-1-15 02:12:55
|
查看: 224|
回复: 0
发表于 2026-1-15 02:12:55
|
查看: 224|
回复: 0
