在信创推进、数据库自主可控的大背景下,一个现象越来越明显:国产数据库的“技术母本”,正在从 MySQL,全面转向 PostgreSQL。
你会发现:
- 腾讯云 TDSQL PG(TBase)
- 阿里云 PolarDB for PostgreSQL
- 华为云 GaussDB / openGauss
- 易景数通 openHalo
它们无一例外,都选择了 PostgreSQL 作为底层内核。
问题来了:
MySQL 明明更流行、更成熟、更“好用”,那为什么真正做数据库的大厂,反而不选它?
答案很简单:不是 MySQL 不够好,而是它有“天花板”。 而 PostgreSQL,恰好踩在了这些天花板的另一侧。
01 国产数据库都在 PostgreSQL 上“深度定制”
先看几个代表性方案,你就能感受到差异:
1. 腾讯云 TDSQL PG(TBase)
- 基于 PostgreSQL 深度改造
- 引入 GTM 全局事务管理器
- 支持 跨 shard 分布式事务
这是 MySQL 原生架构很难优雅解决的问题。
2. 阿里云 PolarDB for PostgreSQL
- 重构存储层
- 实现 一写多读 + 共享存储
- 秒级扩容只读节点
这不是简单的“主从复制”,而是真正的云原生数据库形态。
3. 华为云 GaussDB / openGauss
- 兼容 PostgreSQL 生态
- 引入 列存储
- 支持 HTAP(OLTP + OLAP)
- 内置 AI 优化器
PostgreSQL 在这里成为了一个“可演进的内核”。
4. openHalo(易景数通)
- 面向分布式场景
- 基于 PostgreSQL 强大的扩展能力构建
核心不是“改 SQL 语法”,而是改数据库的能力边界。
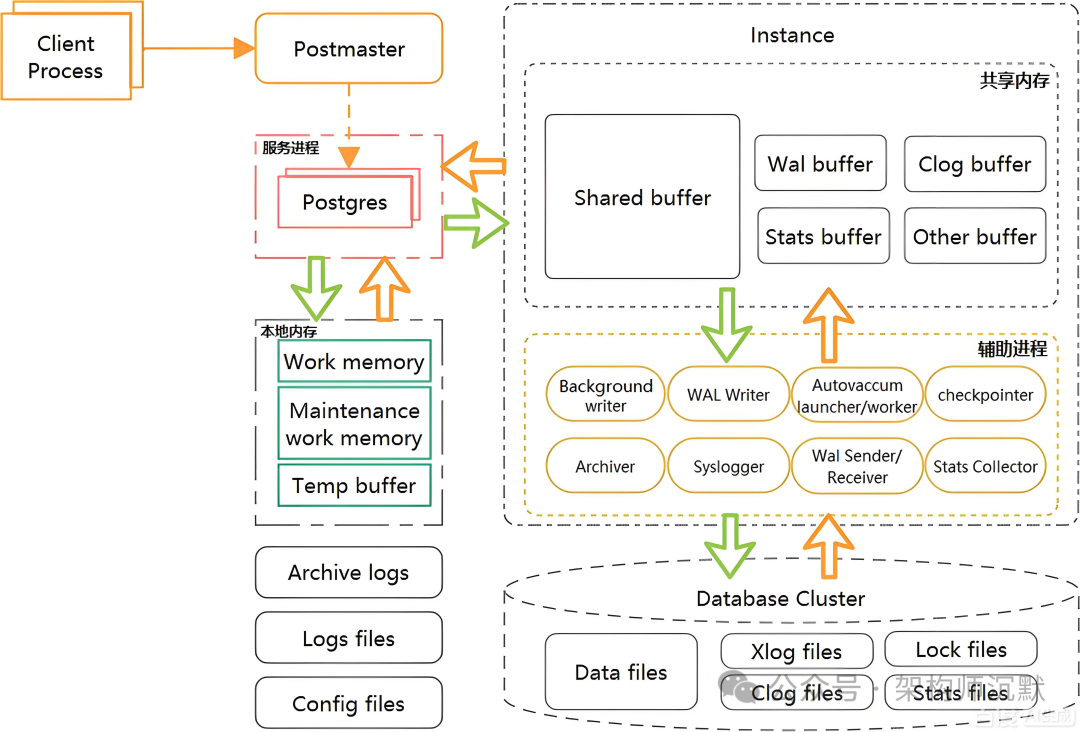
02 为什么不是 MySQL?
接下来我们说点“得罪人的实话”。
1. MySQL 的数据类型,真的不够用
在简单业务中,MySQL 很好。但在复杂系统建模上,它可能会让你写出一堆“很丑的表”。
而 PostgreSQL 提供了:
- ARRAY:一个字段可以存储多个值
- RANGE:时间区间、价格区间天生支持
- 复合类型:直接映射现实世界中的对象
- JSONB:可索引、可更新、可高效查询
一句话总结:
PostgreSQL 是“面向业务建模”的数据库,MySQL 更像“面向表结构”的数据库。
2. MySQL 没有“真正的序列(Sequence)”
很多人不知道:MySQL 到现在,都没有独立的序列对象。
PostgreSQL 可以这样做:
CREATE SEQUENCE order_seq START 1;
INSERT INTO orders(id) VALUES (nextval('order_seq'));
而 MySQL:
- 只能依赖
AUTO_INCREMENT
- 必须绑定到表
- 不能跨表共享
- 在分布式场景下,通常需要额外引入 Redis 或 Snowflake 算法
这在金融、订单、分布式事务系统中,是实打实的工程成本和复杂度。
3. MySQL 的扩展生态,太弱了
PostgreSQL 被称为 “可编程数据库” 不是没有道理的。你可以直接安装各种扩展:
- TimescaleDB → 时序数据库
- Citus → 分布式数据库
- pg_trgm → 相似度搜索
- pg_stat_statements → SQL 级性能监控
而 MySQL:
- 插件生态相对匮乏
- 能力较为割裂
- 很多高级功能只能在“数据库外解决”
4. MySQL 的性能诊断,成本极高
MySQL 排查问题,往往需要组合使用:
- slow log
- Performance Schema
- SHOW PROCESSLIST
- 经验 + 运气
PostgreSQL 则提供了开箱即用的强大工具集:
pg_stat_activitypg_stat_statementspg_locksEXPLAIN ANALYZE
所见即所得,定位问题的成本低了一个量级。
5. 复制机制:MySQL 更像“备份”,PG 更像“高可用”
MySQL:
- 默认 异步复制
- 主库宕机,从库可能丢失数据
- 半同步需要额外配置
- GTID 在复杂运维中容易踩坑
PostgreSQL:
- 基于强大的 WAL 日志机制
- 原生支持 同步复制
- 主库可等待备库确认后再提交事务
- 理论上可以实现 零数据丢失
一句话概括:
MySQL 的复制更偏向“数据容灾”,而 PostgreSQL 的复制是“架构高可用能力”的一部分。
6. MySQL 的“开源”,并不彻底
这是很多人忽略的关键点。
| 维度 |
MySQL |
PostgreSQL |
| 许可证 |
GPL + 商业 |
BSD-like(类BSD) |
| 控制方 |
Oracle |
社区 |
| 企业版 |
有功能差异 |
核心功能无阉割 |
| 技术路线 |
商业驱动 |
技术驱动 |
PostgreSQL 是 真正意义上的“社区主导型开源数据库” ,这让基于它进行深度定制和长期技术演进的厂商更为安心。
7. MVCC 实现,决定了并发模型的上限
PostgreSQL:
- 多版本存储在数据行中
- 读写操作彻底隔离
- 支持更高级的事务隔离级别
MySQL(InnoDB):
- 依赖 undo log 构建版本链
- 长事务容易导致 undo 空间膨胀
- 在高并发场景下的内部复杂度更高
这也是为什么:
金融、交易、复杂高并发系统,往往更偏爱 PostgreSQL 作为底层基石。
03 那 MySQL 就不行了吗?
MySQL 依然是 Web 和互联网场景的王者。
它的优势也非常明确:
- 部署极简,开箱即用。
- 读性能强劲,在简单查询场景下表现出色。
- Web 生态成熟,ORM、框架支持完善。
- 云厂商深度优化,提供了丰富的托管服务。
- 社区资源极其丰富,遇到问题更容易找到解决方案。
对于 读多写少、需要快速上线和迭代的业务,MySQL 依然是最优解之一。其强大的生态和丰富的云服务选择,让它成为了一个非常务实的 数据库技术栈 选项。

04 总结
这不是一场“谁更好”的辩论,而是关于 “谁更适合” 的理性选择。
如果要一句话总结:
MySQL 是效率优先的数据库,PostgreSQL 是架构和演进优先的数据库。
国产数据库巨头们集体选择 PostgreSQL 作为底层内核,本质上是在选择:
- 更长的技术生命周期和演进潜力
- 更大的架构灵活性与定制空间
- 更少的、由底层设计带来的隐性天花板
这条路,已经被腾讯、阿里、华为等头部厂商的战略布局所共同验证。对于开发者而言,理解这两种主流数据库的基因差异,将有助于我们在未来的技术选型中做出更明智的决策。欢迎在 云栈社区 交流更多关于数据库与架构设计的实践经验。
 发表于 2026-1-15 05:02:34
|
查看: 160|
回复: 0
发表于 2026-1-15 05:02:34
|
查看: 160|
回复: 0
