在大模型时代,什么最关键?答案是 数据。数据质量决定了模型的上限,数据数量则定义了其能力的边界。然而,我们日常接触的大量文档——如论文、报告、合同——往往是非结构化的。如何高效地将这些复杂文档转化为结构化数据,从而构建可查询、可分析的数据资产呢?
今天介绍一个名为 TextIn xParse 的AI工具,它能高效处理复杂文档的解析,特别是对图表、公式等元素的识别能力突出,下面我们来详细了解一下。
一、什么是TextIn?
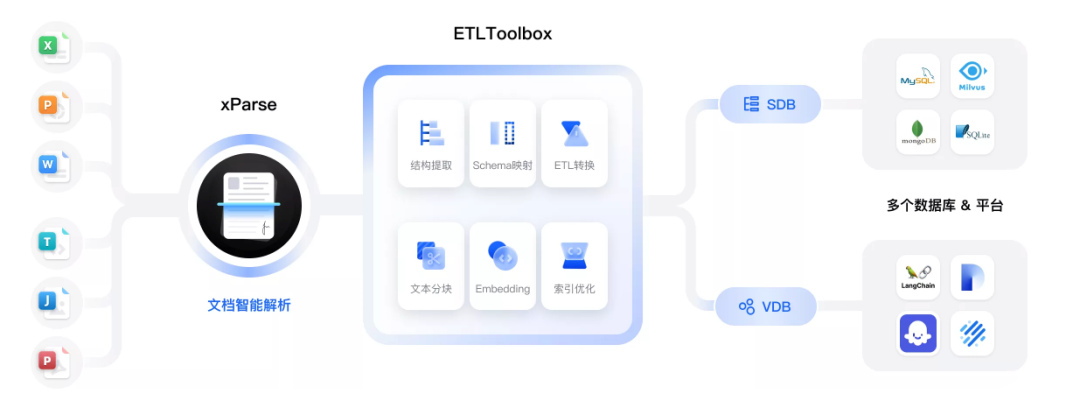
TextIn 是一款对大模型友好的文档解析工具,其核心目标是 让任意文档的信息都能高效准确流入您的数据库,将非结构化内容转化为可查询、可分析的宝贵数据资产,并同时兼容关系型数据库与向量数据库。

其工作流程通常为:文档经过 xParse 智能解析后,使用 ETLToolBox 进行结构抽取、Schema映射、ETL转换、文本分块、Embedding及索引优化等操作,最终输出到各类数据库中。
该工具支持识别文本、图像、表格、公式、手写体、表单字段、页眉页脚等多种元素,并能处理印章、二维码等子类型。它为LLM推理和训练提供了高质量的数据输入,有助于完成数据清洗和文档问答任务,非常适用于构建知识库、RAG(检索增强生成)、Agent或其他自定义工作流。
TextIn 的用户群体广泛,包括AI应用开发者、企业数字化转型团队以及需要进行知识管理的科研人员等。
二、核心特点
传统OCR工具在应对复杂版面时常常力不从心,而 TextIn 利用LLM技术重新构建文档理解能力,旨在以卓越性能处理最复杂的用例。
2.1 超越OCR,对大模型更友好的文档解析
- 语义化分段:将任意版式的文档拆解为语义完整的段落,并按阅读顺序还原,更适配大模型理解。
- 强大表格识别:行业领先的表格识别能力,可轻松解决合并单元格、跨页表格、无线表格等识别难题。
- 全元素覆盖:能正确识别标题、公式、手写体、印章、页眉页脚及跨页段落。
- 图像预处理集成:无缝集成平台内的图像处理能力,可处理带水印、弯曲的图片。
- 语义关系捕捉:能捕捉更多版面元素间的语义关系,让大模型更深入地“读懂”文档。
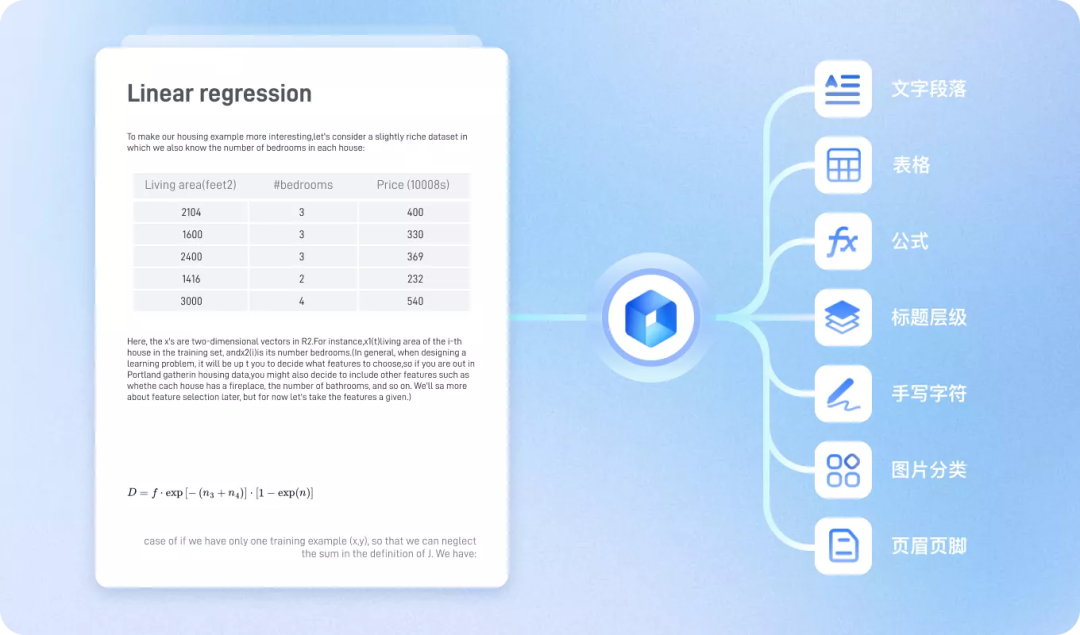
2.2 新时代的ETL:更准、更智能
- 零样本信息抽取:无需训练即可实现任意场景下的关键信息抽取,一套配置应对多样文档。
- 跨文档抽取:即使不确定目标字段位于哪个文件,xParse也支持跨文档进行信息抽取。
- 专项调优模型:使用专项调优的大模型,解决普通模型输出不稳定、长度截断等问题。
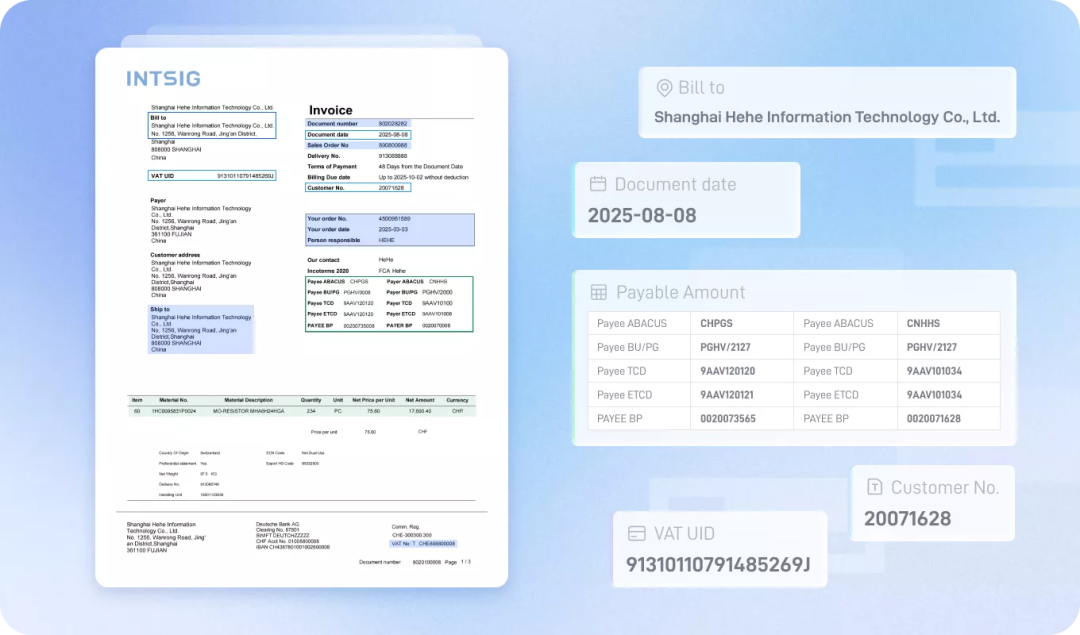
2.3 高质量的Chunk,支撑高质量的RAG问答
- 精准元素还原:更高精度的版面元素还原,为LLM提供准确上下文,提升回答准确性。
- 保留语义关系:可输出元素间的语义关系(如跨页段落合并、图片与注释关联),让向量召回更高效。
- 丰富元数据:可在Chunk中添加坐标、所属页面、章节等信息,进一步提升检索性能。
- 生态集成:解析结果可一键导入下游RAG框架,如RagFlow、Dify、Coze等。
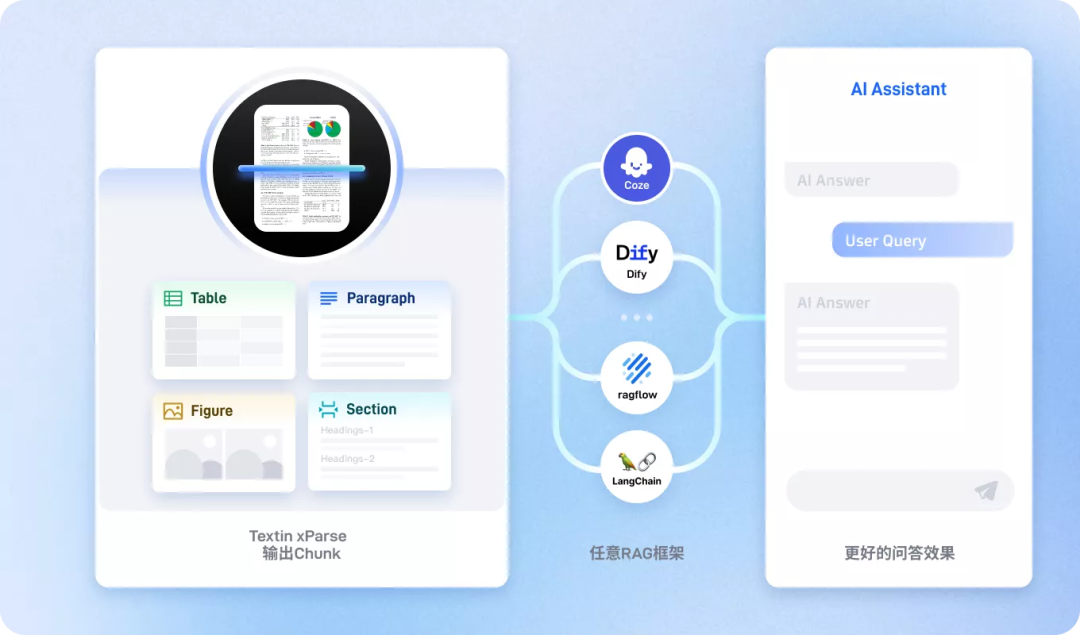
三、实战体验
接下来,我们将使用 TextIn 快速搭建一个可供大模型使用的知识库,实现一个简单的论文阅读助手。
构建知识库的第一步是将复杂文档解析为结构化数据,例如Markdown格式。TextIn 支持两种主要解析方式:Web端在线解析 和 API调用解析。
3.1 Web端解析
首先访问TextIn官网,登录后在产品中心选择“通用文档解析”服务。
为了测试其真实能力,我们上传一篇结构复杂的学术论文。上传后大约10秒,文档即解析完成。
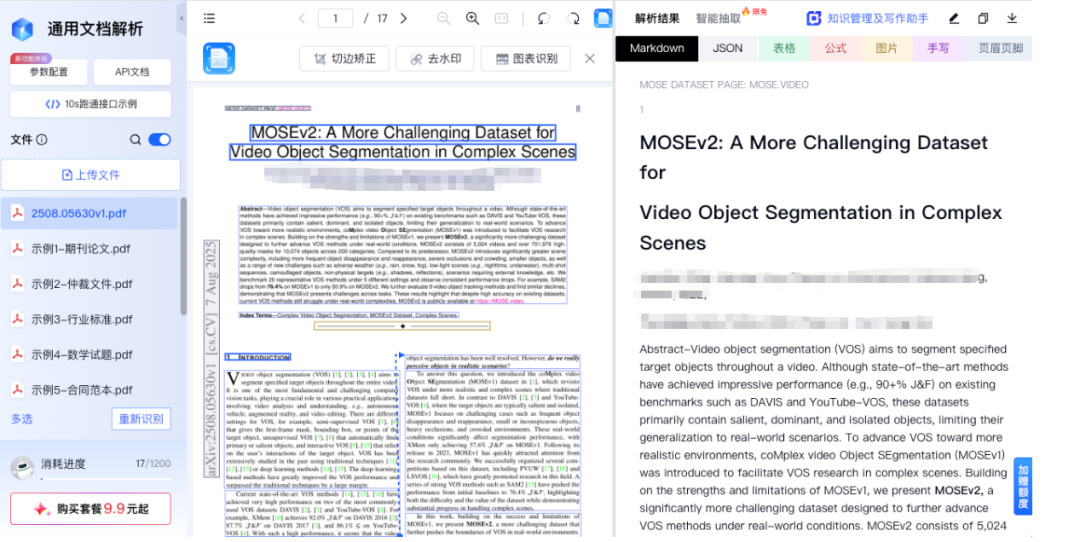
可以看到,文本、图像等内容都被正确解析。在Markdown预览界面点击任意文本块,原始文档视图会同步高亮对应位置,清晰地展示了文档块之间的依赖关系。
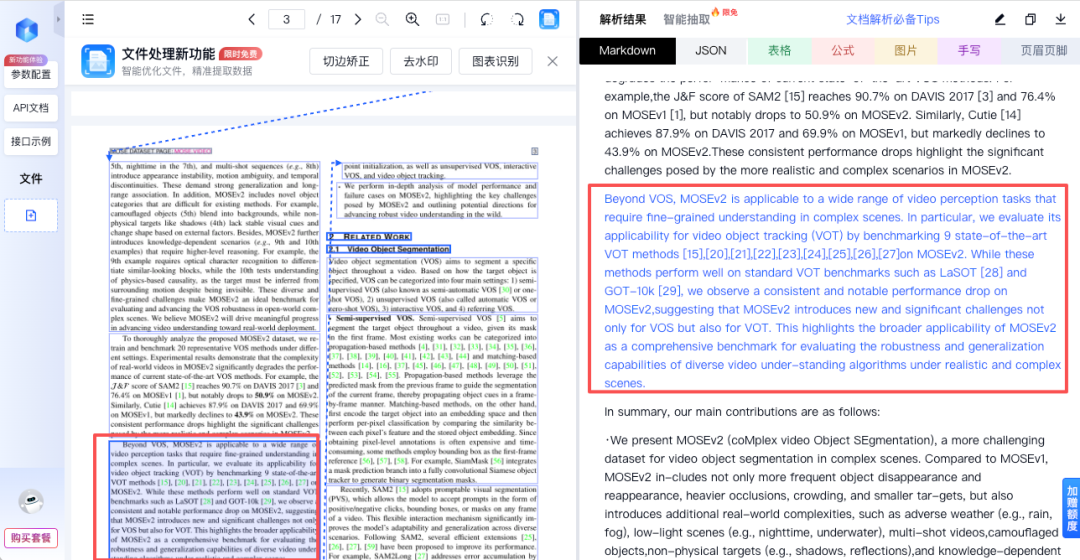
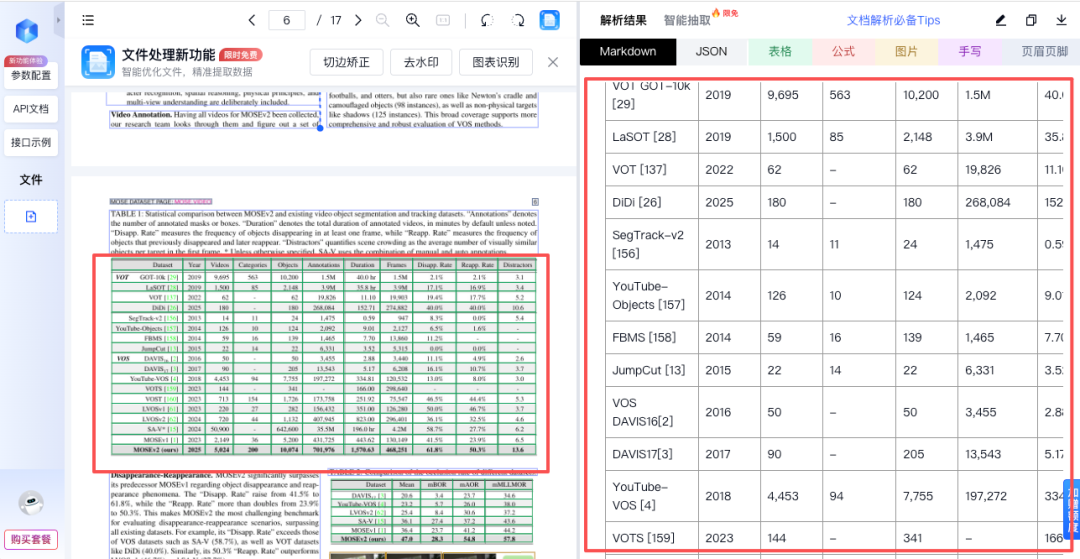
公式、表格等复杂格式的提取一直是难点,而 TextIn 对此的处理相当出色。
数学公式也能被完好无误地识别并转换为LaTeX格式。
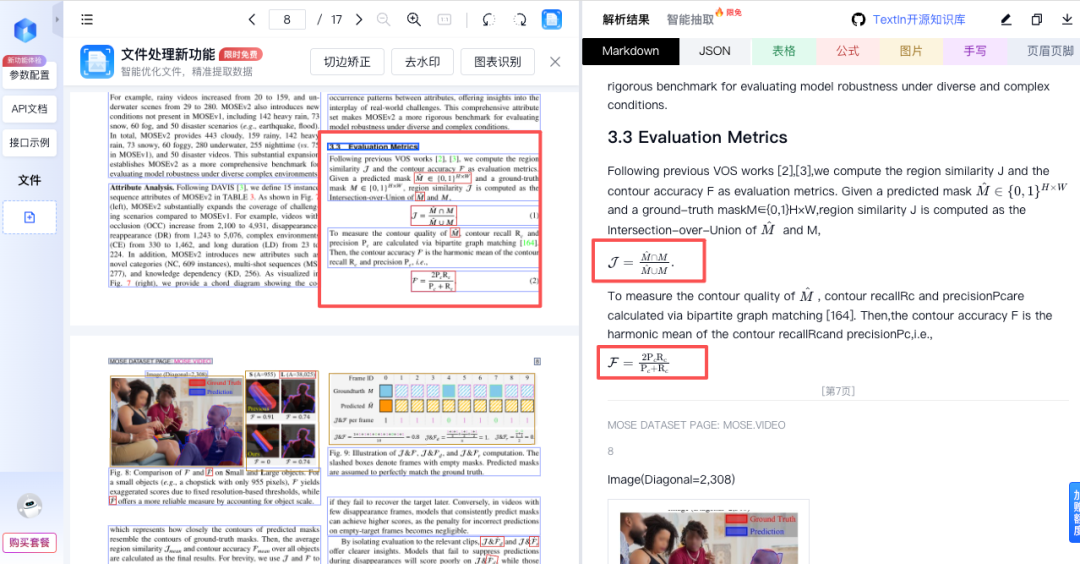
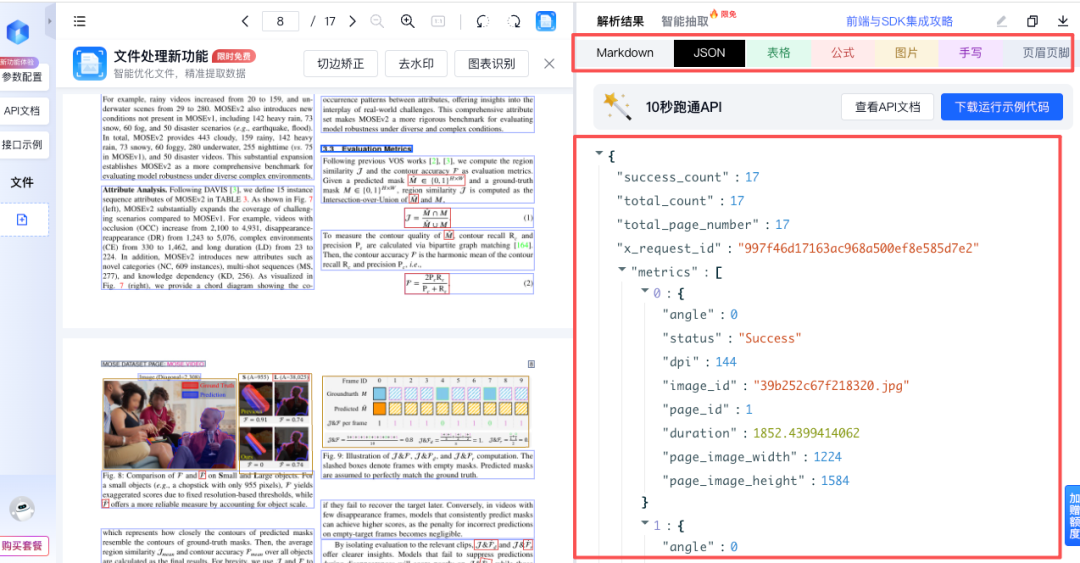
除了Markdown格式,你还可以查看解析后的JSON原始数据、单独导出的表格、公式、图片及页眉页脚信息,方便进行后续的技术文档处理或数据分析。
解析完成后,点击下载按钮即可将Markdown等格式的结果保存到本地。
3.2 API提取
Web端适合单文件或小批量处理,而API方式则便于集成和批量自动化。以下介绍如何在代码中调用 TextIn 的API。
首先,需要在账号设置中获取 x-ti-app-id 和 x-ti-secret-code。以下是使用Python进行API调用的基础示例:
import json
import requests
class OCRClient:
def __init__(self, app_id: str, secret_code: str):
self.app_id = app_id
self.secret_code = secret_code
def recognize(self, file_content: bytes, options: dict) -> str:
# 构建请求参数
params = {}
for key, value in options.items():
params[key] = str(value)
# 设置请求头
headers = {
"x-ti-app-id": self.app_id,
"x-ti-secret-code": self.secret_code,
# 方式一:读取本地文件
"Content-Type": "application/octet-stream"
# 方式二:使用URL方式
# "Content-Type": "text/plain"
}
# 发送请求
response = requests.post(
f"https://api.textin.com/ai/service/v1/pdf_to_markdown",
params=params,
headers=headers,
data=file_content
)
# 检查响应状态
response.raise_for_status()
return response.text
def main():
# 创建客户端实例,需替换你的API Key
client = OCRClient("你的x-ti-app-id", "你的x-ti-secret-code")
# 插入下面的示例代码
if __name__ == "__main__":
main()
将以下代码插入到上述 main() 函数中,即可完成一次完整的文档解析并保存结果:
# 在main函数中插入
# 读取本地文件
with open("你的文件.pdf", "rb") as f:
file_content = f.read()
# 设置URL参数,可按需设置,这里已为你默认设置了一些参数
options = dict(
dpi=144,
get_image="objects",
markdown_details=1,
page_count=10,
parse_mode="auto",
table_flavor="html"
)
try:
response = client.recognize(file_content, options)
# 保存完整的JSON响应到result.json文件
with open("result.json", "w", encoding="utf-8") as f:
f.write(response)
# 解析JSON响应以提取markdown内容
json_response = json.loads(response)
if "result" in json_response and "markdown" in json_response["result"]:
markdown_content = json_response["result"]["markdown"]
with open("result.md", "w", encoding="utf-8") as f:
f.write(markdown_content)
print(response)
except Exception as e:
print(f"Error: {e}")
请注意:请求体需为文件的二进制流。支持 PNG, JPG, PDF, DOC, DOCX, XLS, PPT, TXT 等多种格式,具体限制请参考官方文档。
3.3 创建知识库
获得结构化的Markdown文档后,我们可以在Coze平台上创建知识库。在Coze中新建一个知识库,并选择“文本格式”。
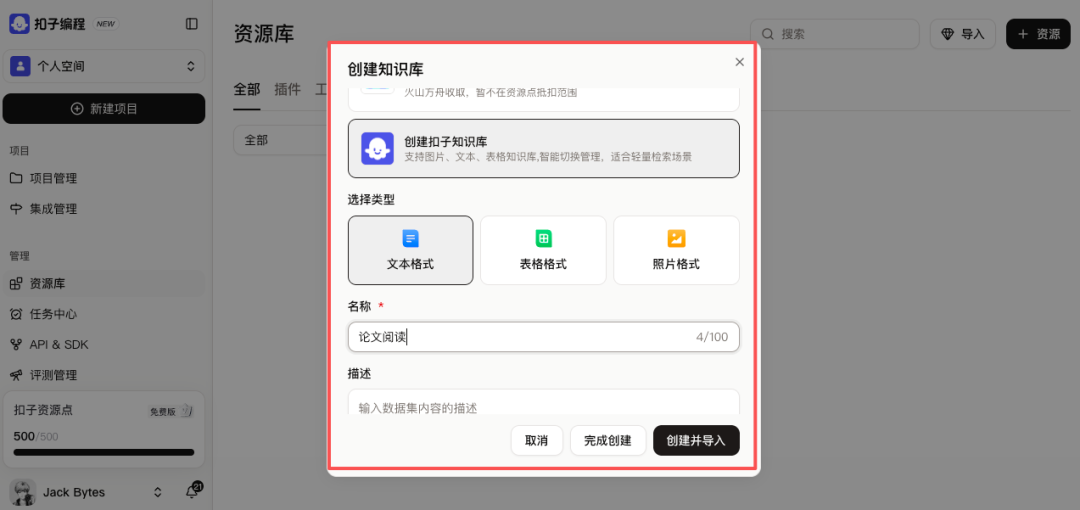
将之前解析好的Markdown文件上传到该知识库。
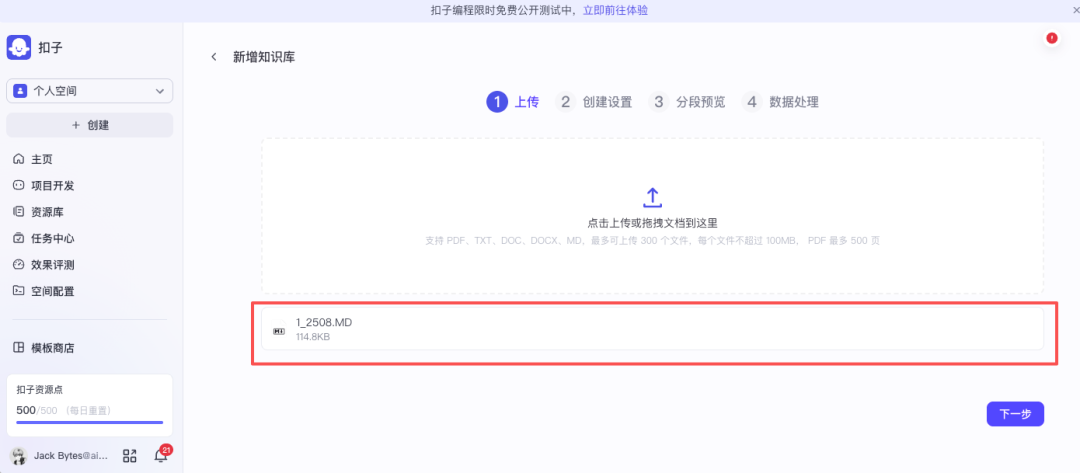
上传后,系统会自动进行分段与清洗处理,你可以预览分段结果以确保质量。
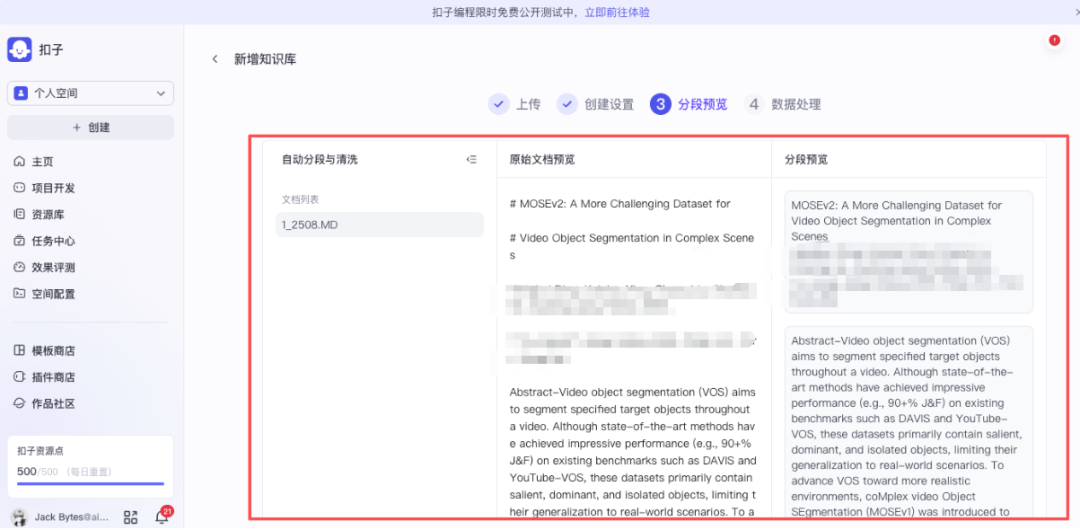
处理完成后,文档内容便成功导入知识库,为后续的智能问答做好准备。
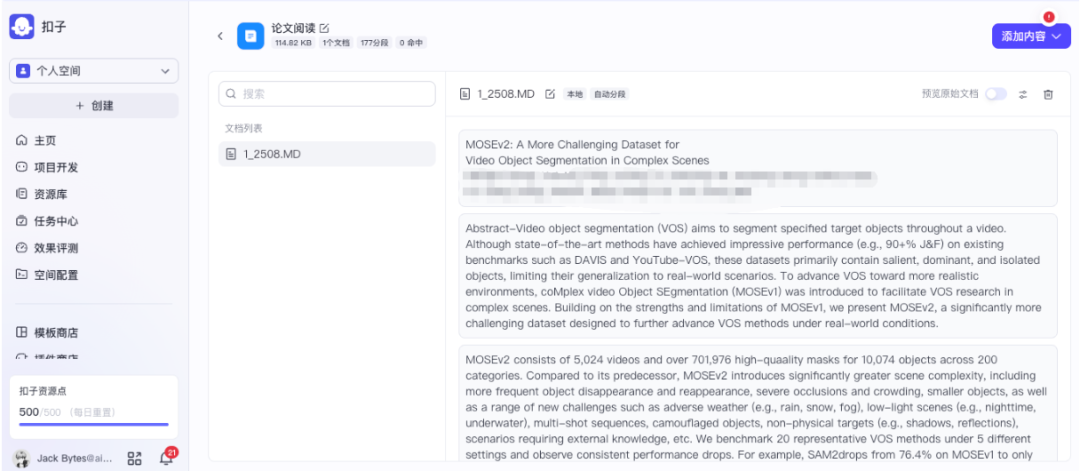
3.4 创建智能体
最后,我们在Coze上创建一个智能体(Bot),将其人设定义为“学术论文阅读助手”,并关联上一步创建的知识库。
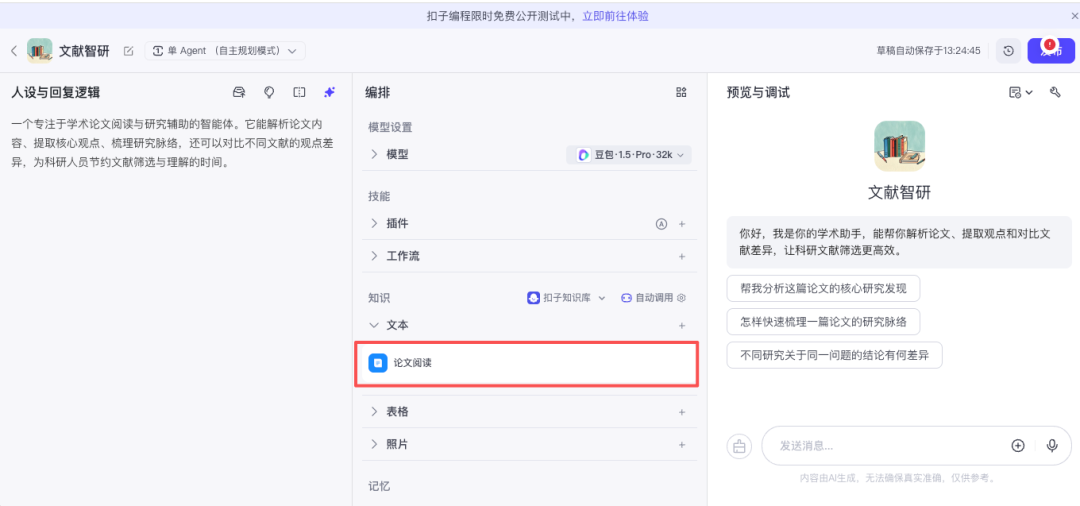
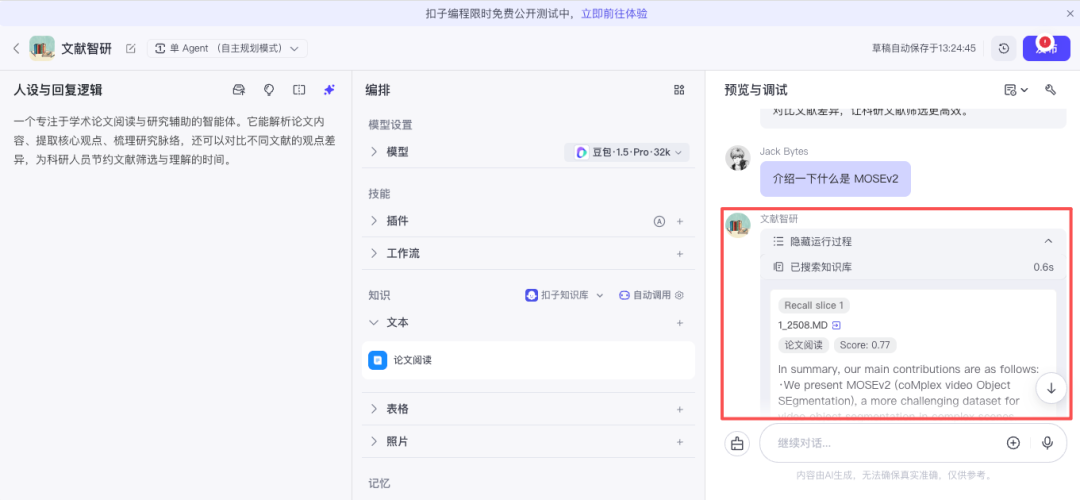
至此,一个简单的论文阅读助手就搭建完成了。在与助手对话时,可以观察到它能够正确调用知识库并进行检索,从而给出基于论文内容的回答。
四、总结
在大模型应用爆发的当下,数据质量决定了AI能力的天花板。TextIn xParse不仅仅是一个OCR工具,更是构建高质量AI数据资产的关键基础设施。
它的核心价值体现在:
- 精准解决痛点:能完美处理传统OCR难以应对的复杂表格、数学公式、双栏排版和图文混排,将静态PDF文档“激活”为机器可读的结构化数据。
- 深度大模型友好:直接输出保留逻辑与语义的Markdown格式,极大提升了后续RAG环节的切片质量和召回准确率。
- 部署灵活易用:既提供开箱即用的Web端可视化解析,也为开发者提供强大的API,可无缝集成至Coze、Dify等主流AI平台工作流中。
无论你是需要处理大量文献的研究者,还是正在构建企业知识库的开发者,TextIn都能帮助你打通从“非结构化文档”到“高质量数据资产”的关键路径。如果你希望自己的AI应用更聪明、更专业,不妨从用TextIn提升数据质量开始尝试。更多关于AI工具和实战经验的分享,欢迎关注 云栈社区 的后续内容。
 发表于 2026-1-15 12:59:59
|
查看: 183|
回复: 0
发表于 2026-1-15 12:59:59
|
查看: 183|
回复: 0
