大模型“跑分”已经成为衡量AI模型能力的关键手段。它主要指通过各类标准化的测试集(Benchmark)来评估模型的各项性能。当前业界主流的大模型评测基准包括AIME 2025, SWE Bench Verified, MMLU、GSM8K、HumanEval等。
- AIME2025:包含高难度数学竞赛题,专门用于测试模型的高阶数学推理和竞赛级解题能力,常用来测试模型的上限。
- SWE Bench Verified:基于真实的代码修改和Bug修复任务,旨在评估模型解决实际软件工程问题的能力,比HumanEval等基准难度更高。
- MMLU:包含57个学科的综合知识选择题,考察模型的基础知识和综合理解能力,是最常用的“通识能力”基准。
- GSM8K:由多步求解的小学数学题构成,用于测试基础的数学推理和算术能力。
- HumanEval:要求模型根据描述编写代码并通过单元测试,是评估代码编写能力的入门基准。
其中,基准(Benchmark) 可以理解为统一、公开且可重复的“考题”或“标尺”,它的核心作用是对不同模型的能力进行公平对比。一个有效的基准通常具备三个要素:
- 有固定的题目或任务,确保评估结果具有可比性。
- 有明确的评价标准,对完成度有统一的打分规则。
- 最终目标是为了横向对比,找出模型的优势与短板。
业界对评测基准的分类非常细致,涵盖了从通用能力到专项技能的多个维度,常见的类别包括:数学推理、综合评估、编程与软件工程、Agent能力评测、AI Agent工具使用、常识推理、多模态理解、文本向量检索等。

主流大模型评测的细分能力维度

SuperCLUE评测体系下的各类专项与行业基准
如何获取与解读大模型跑分?
根据2026年初的行业动态,大模型领域的竞争焦点集中在“推理模型”与“多模态”两个方向上。要了解模型的最新性能,可以参考以下几个核心榜单:
基于Artificial Analysis及DataLearnerAI等机构的最新实时数据,我们可以看到当前的主流格局:Gemini系列在推理上表现强劲,Claude模型通用性佳,GPT-4o则保持了综合素质的稳健。国产模型中,Qwen系列展现出较高的性价比,而DeepSeek在代码能力上优势明显。
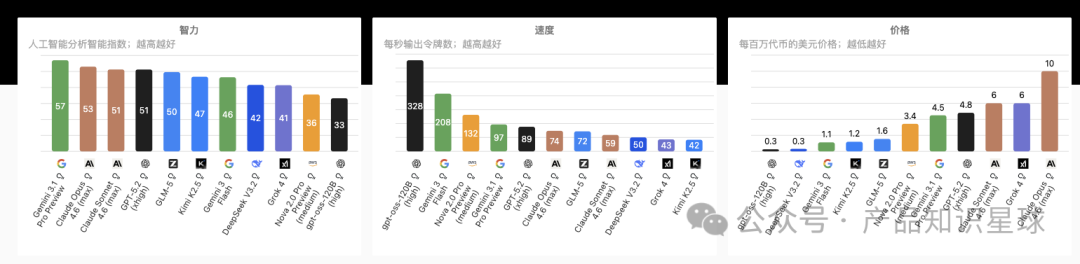
智力、速度、价格三维度下的主流大模型对比
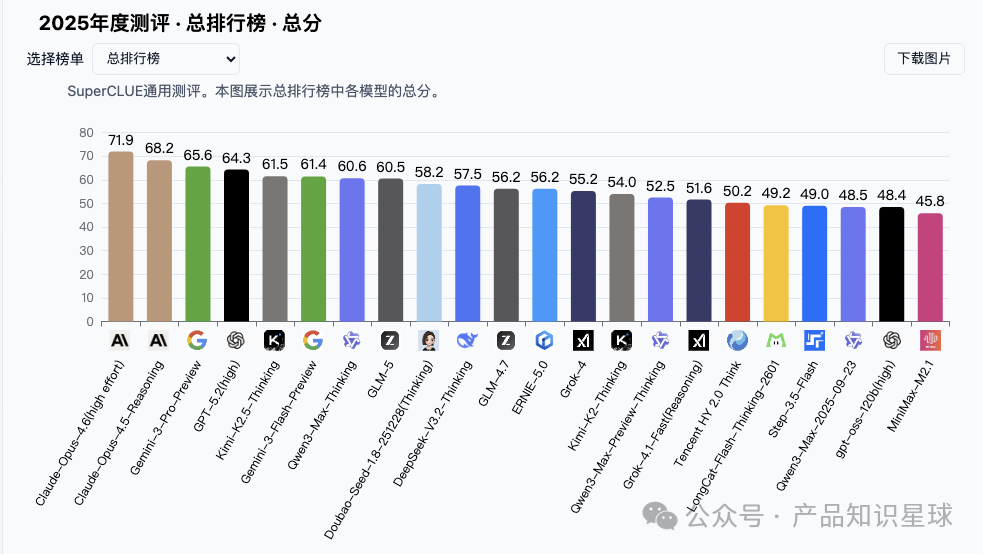
2025年度SuperCLUE通用测评模型总分排名
为了更全面地理解“分数”的来源,可以参考以下几类公认的评测平台:
- 竞技场模式(盲测):
- LMSYS Chatbot Arena:采用用户匿名投票的方式,对模型的回复进行两两比较。由于其结果来自真实用户的主观感受,被认为是最难“刷分”、最接近真实体验的榜单。
- 开源与学术基准:
- Hugging Face Open LLM Leaderboard:全球最权威的开源大模型评测平台,主要评估基础语言模型在多个核心任务上的能力。
- MMLU / GSM8K:分别测试大规模多任务语言理解和小学数学能力,是模型发布时最常引用的指标之一。
- 中文语境专项:
- SuperCLUE:专为中文语境、Agent能力及行业应用设计的综合性评测基准。
- OpenCompass (司南):由上海人工智能实验室推出的开源、全面的大模型评测体系与工具平台。

2025年值得关注的中文大模型及多模态、行业应用分布

2025年各垂直领域的国内AI智能体产品概览
理性看待“跑分”:分数不等于一切
在参考各类榜单的同时,我们也需要保持理性:
- 跑分不等于实际体验:行业正逐渐从“盲目刷分”转向关注“商业落地”。有些模型在标准测试集上得分很高,但在处理复杂业务逻辑或超长文档时可能表现不佳。
- 领域日趋专项化:评测正变得更加垂直。例如,字节跳动的 Trae 和阿里的 通义灵码 在编程领域评测中表现出色;而 Gemini 系列则在视频理解与生成方面优势显著。
- 推理能力成为新焦点:2026年的一个重要趋势是评估模型的“思维链”能力,即模型在输出最终答案前展示推理过程的能力,这也是Qwen 3.5-Thinking等模型的核心竞争力。
如何构建贴合业务的评测体系 (Benchmark)?
要对服务于自身业务的AI大模型进行准确评估,建立一套适配特定场景的评测体系至关重要。以下结合行业实践,系统介绍评测体系的建设方法与一个具体案例。
一、评测动力与核心需求
构建评测体系的动力主要来自四个方面:
- 技术创新推动:通过测试发现模型优势与局限,驱动技术优化与突破。
- 实际应用验证:在真实行业场景中验证模型效果,挖掘其应用潜力。
- 安全与合规评估:评估模型在内容安全、偏见处理、隐私保护等方面的表现,确保其符合伦理与法规要求。
- 用户体验提升:通过测试理解用户交互模式,优化模型的易用性和沟通自然度。
二、评测维度与框架设计
一个全面的大模型评测体系通常采用多维度框架,例如“能力-任务-指标”三维模型。国内外的代表性体系各有侧重:
-
国内主流体系:
- 智源评测:覆盖简单理解、知识运用、推理、数学、代码、任务解决及安全七大能力维度,包含超8万道考题。
- 电子标准院LMBench:基于国家标准,分为单/多模态的理解与生成四大类,并提供标准化测评工具。
- 信通院“方升”评测:采用“三横一纵”(行业、应用、通用、安全)架构,拥有超300万条评测数据的题库。
- OpenCompass:开源的评测平台,涵盖语言、推理、知识、代码、数学、指令跟随和智能体七个维度。
- SuperCLUE:分为通用、专项和行业三类基准,共2194题,全面覆盖中文场景下的模型能力评估。
-
国际主流体系:
- HELM (斯坦福):旨在对语言模型进行全面评估,覆盖准确性、鲁棒性、公平性等多维度,使用MMLU、MATH等多个核心数据集。
- Chatbot Arena (UC Berkeley):通过众包用户对模型回复进行匿名投票,以成对比较的方式评估模型在实际对话中的表现。
- Open LLM Leaderboard (Hugging Face):权威的开源模型评测平台,集成了AI2 Reasoning Challenge、MMLU等多个基准测试,结果公开可复现。
这些体系在评测维度、数据集构建、评测方法(自动化与人工结合)以及量化打分机制上各有特色,但总体趋势是追求更全面、客观和贴近应用的评估。
三、实战案例:AI电话销售Agent评测体系构建
以下以AI电话销售场景为例,展示如何基于业务特性构建一套可落地的评测体系。
核心目标:全方位评估AI电销Agent在真实销售对话中的沟通效率、转化能力、合规性及用户体验。
核心评测维度与权重:
-
基础能力维度 (权重 30%)
- 语言表达能力:考察语音清晰度、语速适配、语气亲和度。
- 信息理解与提取:测试对用户需求、异议点等关键信息的捕捉与记录准确性。
- 基础合规性:检查开场白是否规范、隐私信息保护是否到位、是否使用禁语。
-
销售核心能力维度 (权重 50%)
- 需求挖掘与痛点匹配:评估通过引导式提问识别用户痛点,并精准匹配产品卖点的能力。
- 异议处理能力:测试对“价格太贵”、“不需要”等常见异议的回应逻辑与说服力。
- 销售逻辑与促成技巧:考察产品介绍的结构性、促成时机的把握以及跟进话术的设计。
- 多轮交互韧性:评估在长时间对话、用户频繁打断或偏离主题时的沟通维持与引导能力。
-
用户体验维度 (权重 20%)
- 交互自然度:避免机械应答,保证回复及时性,并模拟人类化的共情表达。
- 尊重用户选择:在用户明确拒绝时及时终止销售动作,合理控制通话时长。
评价标准与计分方式:
采用1-5分制对每个细分任务进行打分(例如,1分表示极差,3分表示合格,5分表示优秀)。总得分由各维度得分加权平均后归一化为百分制,并设置额外加减分项(如成功促成交易加分,出现违规表述减分)。
测评流程与等级评定:
- 场景配置:设定外呼脚本、用户画像库、异议场景库。
- 模拟外呼:通过电话机器人平台发起至少50通测试通话(多轮对话占比≥70%)。
- 数据标注与评分:结合AI语音分析工具与人工审核完成评分校准。
- 报告生成:输出单项能力得分、总得分及改进建议。
- 等级评定:根据总分划定S级(90-100分)到D级(60分以下)五个等级,对应不同适用场景。
通过这样结构化的评测体系,企业可以量化评估不同AI电销Agent的综合能力,为模型选型与优化提供扎实的数据支撑。无论是参考开源项目的成熟实践,还是研读各平台的官方文档,其核心思路都是相通的:紧密结合业务需求,设计科学、全面、可量化的评估方案。
在实际开发和选型过程中,如果遇到复杂的评估场景或需要更深入的交流,欢迎到 云栈社区 的相关板块与更多开发者和技术专家一起探讨。 |  发表于 2026-3-1 04:28:18
|
查看: 284|
回复: 0
发表于 2026-3-1 04:28:18
|
查看: 284|
回复: 0
