近日,笔者收到了飞凌嵌入式寄来的基于 Rockchip RV1126B 处理器的新品开发板。作为一款定位中高端的AI视觉处理器,RV1126B集成了4核Cortex-A53 CPU与独立的3TOPS NPU,旨在满足边缘侧AI计算需求。本文将带您进行快速上手体验,并对其CPU与NPU性能进行实测。
开箱与硬件细节
首先映入眼帘的是飞凌嵌入式标志性的产品包装。

包装内除了开发板,还附有一本涵盖飞凌全系产品的产品手册。本次评测的主角——OK1126B-S开发板本体设计紧凑,接口布局清晰。

开发板的接口细节颇具匠心,提供了USB 2.0、USB 3.0以及用于调试和供电的Type-C接口,方便开发者连接各类外设。

板上保留了瑞芯微处理器平台专用的升级(UPDATE)和复位(RESET)按键,便于系统烧录与调试。

一个非常实用的设计是,开发板引出了一组40Pin的GPIO排针,其引脚定义兼容树莓派标准,这使得大量现有的树莓派扩展模块可以无缝复用,极大降低了开发门槛。

核心处理器Rockchip RV1126B清晰可见,它承载了这款开发板的核心算力。

网络连接方面,开发板提供了一个RJ45以太网口,支持百兆或千兆连接(由于CPU MAC数量限制,二者需择一使用)。

上电与系统查看
通过Type-C转串口线连接MacBook与开发板,可以轻松登录系统。首先使用 df -h 命令查看存储空间,可以看到板载的eMMC存储容量充足,为系统和数据留下了充裕的空间。
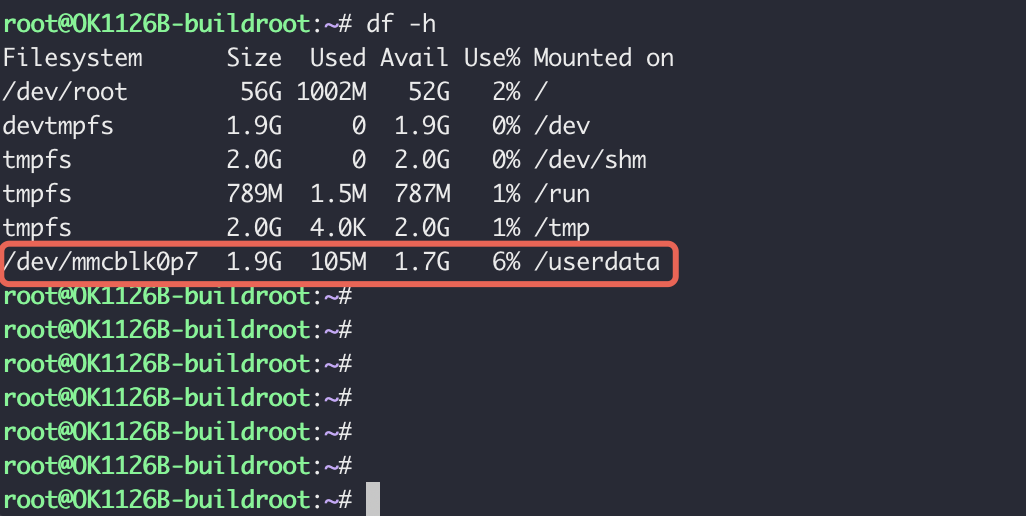
root@OK1126B-buildroot:~# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 56G 1002M 52G 2% /
devtmpfs 1.9G 0 1.9G 0% /dev
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 789M 1.5M 787M 1% /run
tmpfs 2.0G 4.0K 2.0G 1% /tmp
/dev/mmcblk0p7 1.9G 105M 1.7G 6% /userdata
CPU性能实测
为了评估其CPU基础算力,我们采用两种方法进行测试。
1. 计算圆周率π(单核浮点性能参考)
这是一种常见的粗略评估CPU计算能力的方法。通过 bc 命令计算π到小数点后2000位,并计时。
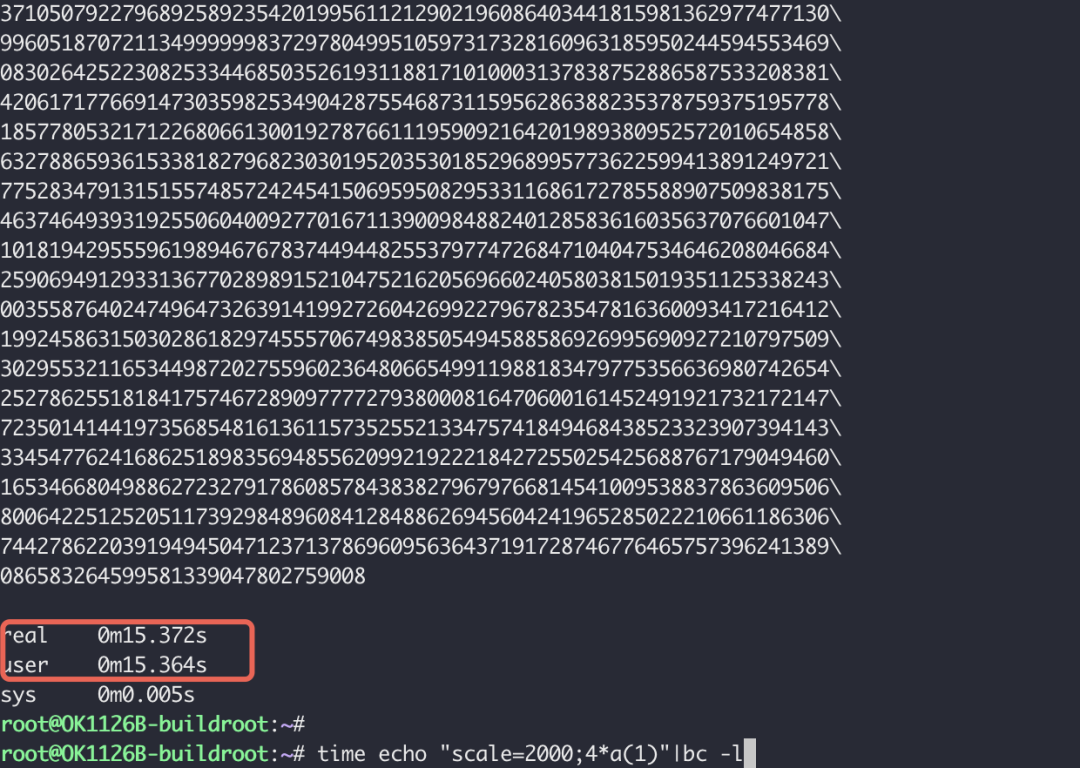
从结果 real 0m15.372s 来看,其单核浮点计算性能与同系列其他四核A53处理器处于同一水平。
2. 使用stress-ng进行压力测试
我们使用专业的压力测试工具 stress-ng 来更精确地测试CPU利用率和调度效率。首先进行单核满载测试。
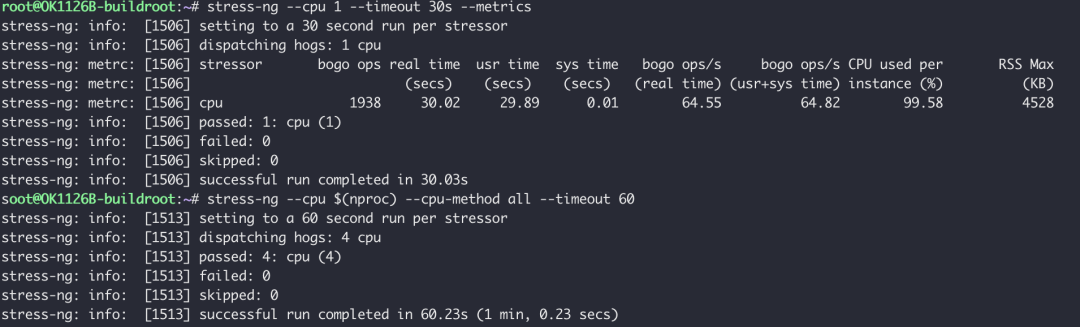
关键指标解读:
- Bogo ops/s: 每秒完成的“假操作”数,数值越高代表单位时间计算量越大。
- CPU利用率: 计算公式为
(usr time + sys time) / real time。
- 在单核测试中:
(29.89s + 0.01s) / 30.02s ≈ 99.58%。
- 这个数值越接近100%,说明操作系统的进程调度开销越小,CPU时间被有效利用于计算任务,系统效率越高。
随后进行的多核全负载测试也顺利通过,表明处理器在多线程负载下运行稳定。
NPU AI算力实测
RV1126B的核心优势在于其集成的独立NPU(神经处理单元),提供高达3TOPS@INT8的AI推理算力。这使其能够在设备端本地实时处理语音、图像等AI任务,无需依赖云端,这正是边缘计算的关键价值所在。
开发者可以使用瑞芯微提供的RKNN工具链来部署和测试AI模型。我们使用板载的示例模型进行了一次简单的推理速度测试。
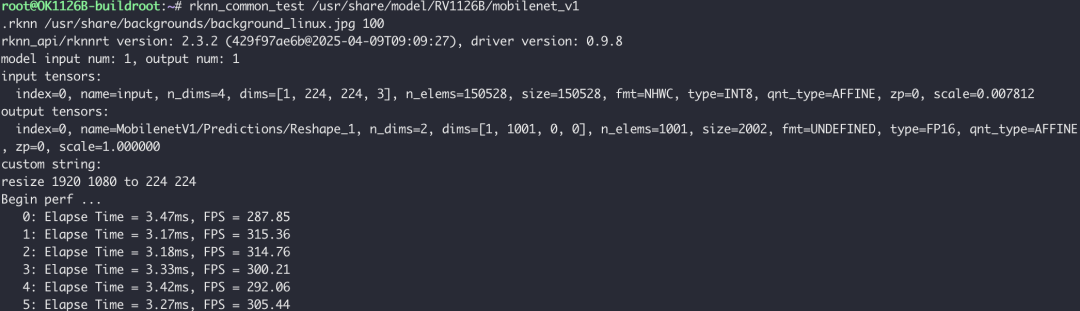
Begin perf ...
0: Elapse Time = 3.47ms, FPS = 287.85
1: Elapse Time = 3.17ms, FPS = 315.36
2: Elapse Time = 3.18ms, FPS = 314.76
...
测试结果显示,对于MobileNetV1这类经典视觉模型,RV1126B的NPU能够达到每秒超过300帧(FPS)的推理速度,完全能够满足大多数边缘侧实时视觉分析应用的需求,例如人脸检测、安全帽识别、区域入侵报警等。这种强大的端侧AI能力,对于构建响应迅速、隐私安全的 智能物联网 系统至关重要。
总结
通过本次快速上手与实测,飞凌嵌入式这款基于RV1126B的开发板给人留下了深刻印象:
- 硬件设计成熟:接口丰富、布局合理,特别是兼容树莓派GPIO的设计极大地提升了易用性和生态兼容性。
- CPU性能均衡:四核Cortex-A53处理器配合高效的 Linux 6.1系统,能够很好地承担通用计算和系统控制任务。
- NPU算力突出:3TOPS的专用AI算力是其主要优势,足以在端侧高效运行多种AI模型,赋能边缘智能应用。
- 开发支持完善:官方提供了全面的资料、BSP支持以及RKNN工具链,有利于开发者快速进行AI项目的落地。
总的来说,飞凌嵌入式OK1126B-S开发板是一款适合用于边缘AI计算、机器视觉、智能安防等领域开发和验证的硬件平台。其软硬件组合为探索端侧智能提供了坚实的基础。
本文首发于 云栈社区,一个专注于技术分享与交流的开发者社区。
 发表于 2026-1-15 13:40:33
|
查看: 413|
回复: 0
发表于 2026-1-15 13:40:33
|
查看: 413|
回复: 0
