背景与研究动机
金融预测的动态性与复杂性
股票价格的形成机制并非静态或线性,而是受到政策法规、舆论导向与宏观经济变动等多重因素的持续影响,呈现出高度非平稳性与不确定性。金融市场本质上是一个信息密集型的动态系统,其中外部冲击(如央行利率调整、地缘政治事件或社交媒体舆情发酵)可能在短时间内引发价格剧烈波动,使得传统基于历史均值或平稳假设的预测模型难以适应真实市场环境。
此外,现有评估体系普遍采用静态数据集与固定训练-测试划分,无法有效模拟市场中信息持续更新、噪声频繁干扰的现实场景。这种训练与实际应用之间的“数据脱节”问题,导致模型在实验室环境中表现良好,却在真实交易中失效。例如,某些模型在回测中展现出优异的收益表现,但一旦投入实时市场,其预测能力迅速衰减,暴露出对动态环境适应能力的严重不足。
因此,构建一个能够反映市场真实动态特征的评估框架,已成为推动金融预测模型从理论走向实践的关键前提。该框架需具备对持续变化的输入信号、非平稳的市场状态以及高频信息干扰的建模能力,从而实现对模型真实性能的可靠衡量。
大语言模型在金融领域的挑战
尽管 LLMs 在预测准确率上取得进展,其决策过程仍存在显著的“黑箱”问题。模型在判断买入、持有或卖出时的内在逻辑模糊不清,缺乏对交易模式与预测结果之间的定向映射分析。例如,当模型推荐某只股票时,无法清晰说明是基于盈利增长预期、行业政策利好,还是短期市场情绪驱动,这严重制约了其在高风险金融决策中的可信度与可审计性。
此外,现有研究在评估体系设计上存在系统性缺陷,主要体现在以下两方面:
- 缺乏对外部变量的独立评估:多数基准未将政策变化、宏观经济指标或舆情波动等外部因素作为独立变量进行控制分析,导致模型性能提升可能被误归因于其自身推理能力,而非对外部环境的敏感响应。
- 未对模型内部数据需求进行系统性分析:不同 LLMs 对训练数据的依赖程度、信息输入的时效性要求及多模态数据整合能力差异显著,但现有评估框架往往忽略这些关键维度,难以判断模型在资源受限或信息延迟场景下的鲁棒性。
综上,当前金融领域中 LLMs 的评估体系亟需从“结果导向”转向“过程-环境-需求”三位一体的综合评估范式,以实现对模型真实能力的全面、可靠刻画。
PriceSeer 框架设计与核心特性
动态实时评估架构
PriceSeer 框架致力于构建一个贴近真实金融市场动态演化的评估环境,突破传统静态基准在时间连续性与信息更新能力上的局限。其核心目标是支持跨时间维度的信息整合与长期推理,以满足金融任务中对长周期预测的现实需求。在这一架构下,模型不仅需分析历史价格走势,还需结合持续注入的外部信息,完成对股票未来价格的动态建模。
首先,框架通过模拟真实市场中动态演化的股票走势,实现了持续更新的预测任务。每只股票提供 249 个按时间顺序排列的历史交易日数据点,涵盖开盘价、收盘价、最高价、最低价及交易量等关键指标,形成完整的时间序列。这种设计使得模型能够在不断演进的时间轴上进行滚动预测,而非仅依赖一次性输入。
此外,框架引入了投资策略生成任务,将预测结果转化为可执行的决策方案,从而直观评估模型的综合决策能力。该任务要求模型基于预测的股价趋势,生成具体的投资建议,如“买入”、“持有”或“卖出”,并附带理由说明。实验表明,不同大语言模型在策略生成上表现出显著差异:部分模型倾向于采取激进型策略,追求高收益;而另一些则更注重风险控制,偏好保守配置,反映出模型在风险偏好上的内在差异。
关键能力总结:
- 支持跨时间维度的信息整合与长期推理
- 模拟真实市场中动态演化的股票走势
- 引入投资策略生成任务,将预测结果转化为可执行决策
多源异构数据融合机制
为真实还原复杂多变的金融市场环境,PriceSeer 构建了高度集成的多源异构数据融合机制,涵盖内部结构化数据与外部非结构化文本信息,全面模拟投资者在实际决策中所接触的信息生态。
框架覆盖美国股市 11 个主要行业板块,包括:基本材料、通信服务、可选消费、必需消费、能源、金融服务业、医疗保健、工业、房地产、科技与公用事业,确保评估结果具备行业代表性与泛化能力。所有数据均来源于真实市场,包含 110 只上市公司股票,总计 27,390 个时间序列数据点,构成一个标准化、可复现的测试集。
数据融合机制分为两大类:
- 内部数据:包括历史价格、技术分析指标(如移动平均线、RSI)、财务指标(如市盈率、营收增长率)等结构化信息;
- 外部信息:整合来自新闻事件、政策变动、宏观经济报告等非结构化文本数据,增强模型对市场情绪与外部冲击的感知能力。
通过引入量化金融指标的信息增强方法,PriceSeer 能够在不引入数据污染的前提下,为模型提供更丰富的上下文支持。例如,将新闻事件与股价波动进行时间对齐,帮助模型建立因果关联;同时,结合市场情绪分析与技术面信号,提升预测的综合判断力。
数据构成一览:
- 行业覆盖:11 个主要板块(基本材料、通信服务、可选消费、必需消费、能源、金融服务业、医疗保健、工业、房地产、科技与公用事业)
- 股票数量:110 只上市公司
- 时间序列点数:27,390 个(249 个交易日 × 110 只股票)
- 数据类型:历史价格、财务指标、新闻事件、政策变动、市场情绪分析
抗干扰与鲁棒性评估设计
在信息高度流动且易被操纵的金融市场中,模型的抗干扰能力与信息甄别能力至关重要。为此,PriceSeer 设计了可控的新闻篡改机制,专门用于模拟信息失真与操纵现象,系统检验模型在信息污染环境下的稳定性与可靠性。
具体而言,框架采用三种虚假新闻生成方式,分别从不同维度增强误导性:
- 修改财务数据:将真实营收、利润等关键财务指标替换为虚构数值,制造“业绩暴增”或“亏损加剧”的假象;
- 插入不实事件描述:如“公司即将被跨国巨头收购”、“核心产品被监管机构禁用”等不存在的重大事件;
- 使用夸张性语言:通过“历史性突破”、“全球唯一”、“颠覆性创新”等情绪化表达,放大信息的传播力与欺骗性。
上述虚假新闻由 DeepSeek-V3.2 模型 生成,确保其语义自然、逻辑通顺,能有效模拟真实世界中由媒体、社交平台或利益相关方制造的信息污染场景。这一设计不仅提升了评估的挑战性,也使模型在面对“伪信息”时的表现更具可比性与参考价值。
虚假新闻生成策略:
- 修改财务数据(如营收、利润)为虚构数值;
- 插入不实事件描述(如“公司即将被收购”);
- 使用夸张性语言增强误导性(如“历史性突破”、“全球唯一”);
所有虚假新闻由 DeepSeek-V3.2 模型 生成,用于检验模型在信息污染环境下的稳定性。
该机制使 PriceSeer 成为首个兼具动态性、信息多样性与对抗性扰动能力的金融领域评估基准,为推动大语言模型在真实金融场景中的可信落地提供了关键支撑。
数据构建与特征工程
双源数据架构
PriceSeer 采用双源数据架构,整合时间序列价格数据与新闻文本数据,并构建相应的多模态数据变体,以支持全面的金融决策归因分析。
- 历史价格数据:通过
yfinance 库获取截至 2025 年 11 月 7 日前一年的每日数据,覆盖 110 只美国上市公司股票,横跨 11 个主要行业板块:基本材料(Basic Materials, BM)、通信服务(Communication Services, CS)、可选消费(Consumer Cyclical, CC)、必需消费(Consumer Defensive, CD)、能源(Energy, EG)、金融服务业(Financial Services, FS)、医疗保健(Healthcare, HC)、工业(Industrials, ID)、房地产(Real Estate, RE)、科技(Technology, TN)和公用事业(Utilities, UT)。每只股票包含 249 个每日数据点,具体字段包括 Date(交易日期)、Open(开盘价)、High(当日最高价)、Low(当日最低价)、Close(收盘价)和 Volume(交易量),构成股票价格预测任务的核心输入。
- 新闻数据:从 Google 搜索结果中通过 SerpAPI 获取每只股票最近 10 篇高相关性新闻文章。这些新闻内容经过语义分析与关键词匹配,用于提取事件驱动的市场情绪信号,补充传统技术指标在突发事件响应上的不足。该数据源为模型提供外部信息输入,增强对黑天鹅事件、财报发布、政策变动等非价格因素的建模能力。
关键技术分析指标
收益率指标
- 简单收益率(Simple Return):衡量两个时期间价格的百分比变化,便于直观理解。其计算公式为:
Return_t = (Close_t - Close_{t-1}) / Close_{t-1},其中 Close_t 表示第 t 日的收盘价。该指标具有计算简单、含义清晰的优点,适用于初步市场趋势判断与可视化展示。
- 对数收益率(Log Return):基于自然对数计算,具备时间可加性与近似正态分布的统计特性,适用于连续时间建模与高级统计分析。其定义为:
LogReturn_t = ln(Close_t / Close_{t-1})。在小幅度变动下,对数收益率近似于简单收益率,但其数学性质更优——例如,多期对数收益率可直接相加,且在大样本下更接近正态分布,因此在时间序列建模、波动率估计与风险分析中具有显著优势。
趋势识别指标
- 简单移动平均(SMA):通过计算指定周期
N 内的价格平均值,平滑短期噪声以识别长期趋势。本系统选取周期 N ∈ {3,5,10,15,30} 天,对应不同时间尺度的趋势信号:SMA_t(N) = (1/N) * Σ_{i=0}^{N-1} Close_{t-i},其中 Close_{t-i} 表示在时间 t 前 i 个周期的收盘价。短期 SMA(如 3 日、5 日)对价格变化响应迅速,适合捕捉短期趋势;而长期 SMA(如 15 日、30 日)则更具稳定性,用于判断中期市场方向。
- 相对强弱指数(RSI):一种动量震荡指标,用于衡量价格变动的速度与幅度,取值范围为 0 到 100。通常,RSI 值高于 70 表示市场处于超买状态,低于 30 则表示超卖状态,提示潜在反转风险。其计算步骤如下:
- 计算每日收益(Gain)与损失(Loss):
Gain_t = max(0, Close_t - Close_{t-1}), Loss_t = max(0, Close_{t-1} - Close_t)
- 采用指数平滑法计算平均收益与平均损失(14 日周期):
AvgGain_t = (13*AvgGain_{t-1} + Gain_t) / 14, AvgLoss_t = (13*AvgLoss_{t-1} + Loss_t) / 14
- 计算相对强度(RS)与 RSI 值:
RS = AvgGain / AvgLoss, RSI = 100 - 100/(1+RS)。RSI 的动态特性使其在识别趋势反转与市场极端情绪方面具有重要价值。
动量与信号指标
动量与信号指标用于捕捉价格趋势的加速或减速过程,是生成交易信号的关键工具。
- 移动平均收敛/发散(MACD):由 12 期与 26 期指数移动平均线(EMA)之差构成,反映短期与长期趋势之间的相对强度。其定义为:
MACD = EMA(Close, 12) - EMA(Close, 26)。其中,指数移动平均(EMA)对近期数据赋予更高权重,计算公式为:EMA_t(α) = α * Close_t + (1-α) * EMA_{t-1}。MACD 线能有效识别趋势的背离与转折,常用于判断趋势的强度与持续性。
- MACD信号线:MACD 的 9 期指数移动平均,用于平滑 MACD 值并生成交易信号。其计算方式为:
Signal_Line = EMA(MACD, 9)。信号线作为参考基准,当 MACD 线上穿信号线时,通常视为看涨信号;反之,当 MACD 线下穿信号线时,则为看跌信号。该机制在趋势跟踪策略中被广泛采用。
波动性与区间指标
波动性与区间指标用于衡量市场波动程度及价格所处的相对位置,有助于识别支撑与阻力位。
- 布林带(Bollinger Bands):基于 20 日简单移动平均(SMA)与两倍标准差构建,形成一组动态通道。其上下轨定义如下:
Upper_Band = SMA(20) + 2 * σ(20)
Lower_Band = SMA(20) - 2 * σ(20)
其中,SMA(20) 为过去 20 个交易日的简单移动平均,σ(20) 为对应周期内的标准差。上轨通常代表阻力位,下轨代表支撑位,带宽随市场波动性动态调整。当布林带收窄(窄带)时,预示波动性下降,可能即将出现突破;而当带宽扩张(宽带)时,则反映市场活跃度上升,趋势可能延续。
布林带指标在识别价格超买/超卖状态、趋势延续与反转方面具有重要应用价值,是技术分析中广泛使用的工具之一。
实验设计与评估流程
核心任务设定
本实验围绕两个核心任务展开,旨在全面评估大语言模型(Large Language Model, LLM)在金融预测与投资决策中的综合能力。首先,收盘价预测任务要求模型在三个不同时间窗口下预测目标股票未来3、5、10个交易日的收盘价,分别对应具体预测日期:2025年11月12日、2025年11月14日与2025年11月21日。该设定覆盖了短期(3天)、中期(5天) 和长期(10天) 三种投资周期,支持对模型在不同时间尺度上趋势捕捉能力的系统性评估。
此外,投资策略生成任务要求模型基于上述预测结果,制定独立且合理的投资策略,涵盖短期、中期与长期持有周期。该任务不仅检验模型的预测精度,更考察其将预测转化为可执行投资行为的能力。具体而言,每个模型需在初始资本为10,000美元的前提下,依据预测结果生成买入与卖出时机建议,并通过固定交易策略(即在最后一个数据日买入,于预测时间点卖出)模拟真实投资流程,最终以实际盈亏情况作为评价其投资管理能力的核心指标。
输入上下文构建
为支持上述任务,实验构建了多模态、结构化的输入上下文 C,融合历史价格、量化技术指标与新闻舆情信息,确保模型具备全面的上下文感知能力。
- 历史价格序列:采用回溯窗口长度
L=249,覆盖约一年的每日收盘价数据,构成时间序列 P = {p_{t-L}, ..., p_{t-1}}。该长度设计确保模型能捕捉长期趋势与周期性波动,同时避免信息过载。例如,对于2025年11月12日的预测,模型将基于2024年11月12日至2025年11月11日的历史价格进行分析。
- 辅助金融特征:引入由RSI、MACD、布林带宽度等构成的量化技术指标向量
F = {f_{t-L}, ..., f_{t-1}}。这些指标提供关于市场动量、超买超卖状态及波动率的客观信号,帮助模型识别潜在反转或延续信号。例如,若MACD出现金叉且RSI处于中性区域,可能预示短期上涨动能增强。
- 新闻与可信度信息:整合与目标股票相关的新闻条目集合
N = {n_1, n_2, ...},其中每条新闻附带可信度标签 c_i ∈ {0, 1},0表示虚假信息(谣言/假新闻),1表示真实新闻。这一设计特别用于评估模型在信息噪声环境下的判别能力——能否有效区分真实利好与人为操纵的虚假信息,从而提升预测的鲁棒性。
整合机制:上述三类信息通过结构化提示(prompt)整合为统一输入 C = {P, F, N},确保模型在推理过程中能同时感知价格趋势、技术信号与舆情动态,实现多源信息融合。
提示工程策略

为引导模型在复杂金融场景中发挥最优性能,实验采用精细化的提示工程策略,确保模型行为与任务目标高度对齐。
- 角色设定:将模型定位为“金融数据分析师”,强调其专业视角与严谨分析风格。该角色设定有助于抑制模型生成模糊或情绪化表达,提升输出的客观性与可解释性。例如,模型在分析新闻时,会优先评估信息来源的可信度,而非仅依赖文本情感倾向。
- 任务说明:明确指定预测目标,包括具体股票名称(如
stock_name)与精确预测日期(2025年11月12日、14日、21日)。这一设计避免了歧义,确保模型输出与任务要求严格匹配。此外,要求预测结果以精确数值形式返回,禁止使用区间估计或模糊表述,强化了对模型输出确定性的要求。
- 数据整合:将历史价格序列、筛选后的技术指标向量、真实与虚假新闻信息整合为结构化提示,形成完整的输入上下文。该过程遵循以下逻辑顺序:
- 时间顺序呈现:历史价格按时间倒序排列,便于模型识别近期趋势;
- 指标分类标注:技术指标以清晰标签(如“MACD: 0.12”)呈现,增强可读性;
- 新闻分类处理:真实新闻与虚假新闻分别标注并置于独立模块,便于模型进行对比分析。
提示结构示例(简化版):
你是一名金融数据分析师,请分析股票 `stock_name` 的未来走势。
【历史价格】
2025-11-11: 105.32
2025-11-10: 104.87
...
【技术指标】
RSI: 58.4(中性)
MACD: 0.12(金叉)
布林带宽度: 0.08(收敛)
【新闻摘要】
- 真实新闻:公司Q3营收同比增长23%(可信度:1)
- 虚假新闻:市场传言公司将被收购(可信度:0)
请预测该股票在以下日期的收盘价:
- 2025年11月12日:______
- 2025年11月14日:______
- 2025年11月21日:______
评估指标与性能分析
主要评估指标
本文采用三项核心指标:相对误差(Relative Error)、命中率(Hit Rate) 与 性能评分(Performance Score),分别从数值偏差、趋势判断与综合表现三个维度进行量化分析。
- 相对误差(Relative Error):衡量预测值与实际值之间的偏差程度,通过将绝对误差除以实际价格,有效消除不同股票价格水平带来的尺度差异。其数学表达式为:
RE = |ŷ - y| / y。其中,ŷ 表示模型预测的价格,y 表示实际价格。该指标越低,表明模型在价格预测上的精确性越高。
- 命中率(Hit Rate):用于评估模型在方向性判断上的能力,即正确预测价格上升或下降趋势的比例。其定义如下:
Hit Rate = N_correct / N_total。其中,N_correct 为趋势预测正确的次数,N_total 为总预测次数。高命中率意味着模型具备较强的市场趋势感知能力。
- 性能评分(Performance Score):为提升相对误差的可解释性与可比性,本文将其转换为标准化的性能评分,采用自然对数缩放方式,使取值范围限定在 1–100 之间,数值越大表示性能越优。转换公式如下:
Score = 100 / (1 + β * RE)。其中,β 为惩罚系数,用于调节误差容忍度与评分敏感性之间的权衡。在本实验中,β 的取值依据经验设定为 23,确保评分对小误差变化具有足够敏感度。
模型性能对比
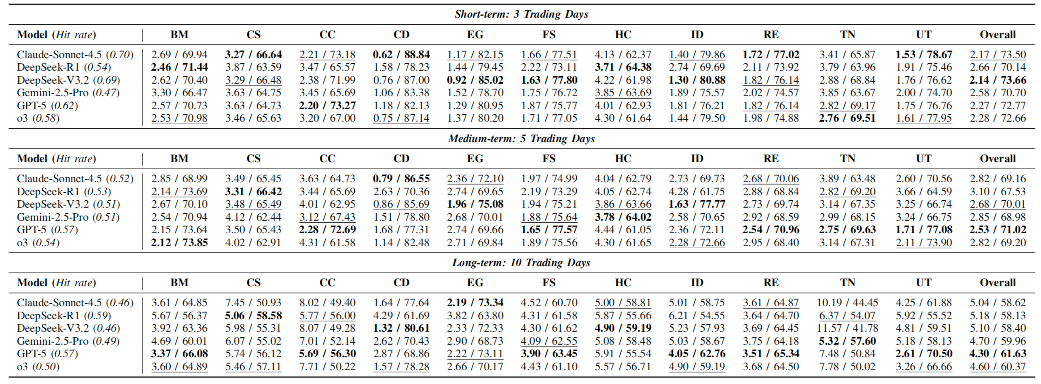
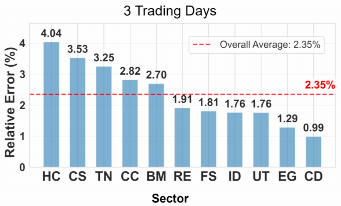
短期预测(3天)
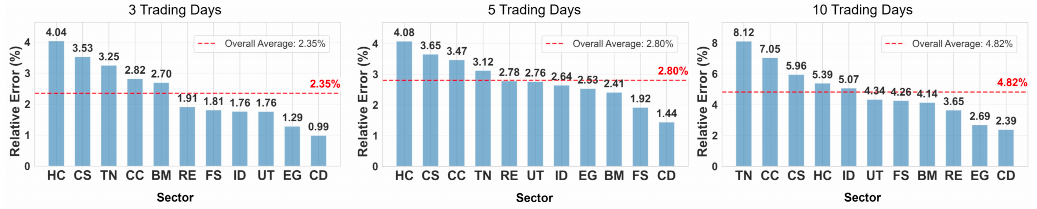
在短期预测任务中,模型需快速响应市场波动,对即时信息的捕捉能力要求极高。实验结果显示,DeepSeek-V3.2 表现最为突出,其整体相对误差最低,达到 RE = 2.35%,显著优于其他模型。该模型在能源、金融服务业与工业板块中表现尤为优异,反映出其在高频市场动态建模方面的强大能力。
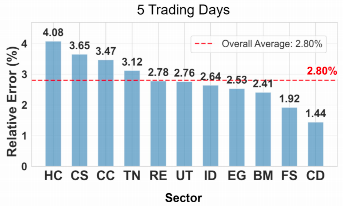
中期预测(5天)
进入中期预测阶段,模型需在时间跨度扩大背景下维持稳定输出。此时,GPT-5 凭借其更深层次的上下文理解与趋势推演能力,取得最佳整体性能,相对误差为 RE = 2.80%。其优势在多个关键行业中体现:在消费周期、金融服务业、房地产、科技与公用事业等行业中均处于领先地位,表明其具备跨行业趋势识别与建模的综合能力。
长期预测(10天)
在长期预测中,模型需克服市场噪声干扰,捕捉结构性趋势。GPT-5 再次展现卓越稳定性,其相对误差维持在较低水平,且在多数行业中的趋势预测命中率处于前列,体现出极强的泛化能力。
- 长期平均命中率:0.51,高于短期(0.6)与中期(0.53)的平均值,说明模型在长期尺度上对趋势方向的把握能力更强。
- 在金融服务业、房地产、科技及公用事业等多个行业中,GPT-5 在长期预测中表现出最低的整体相对误差(
RE = 4.82%),并在七个行业实现了最佳性能。
- 该结果表明,GPT-5 不仅具备短期反应力,更能在长周期中持续输出高质量预测,适用于战略资产配置与长期投资决策。
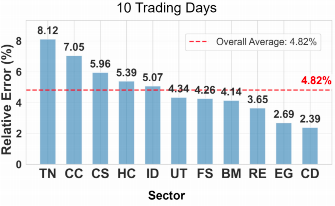
行业差异与预测可预测性
不同行业的市场结构与驱动机制显著影响预测的可实现性。根据预测表现,可将行业划分为两类:创新型行业与稳定型行业。
- 创新型行业(通信服务、科技、医疗健康、可选消费):具有高波动性、技术快速迭代、非线性增长路径以及高度事件驱动特征,导致预测不确定性显著升高。例如,医疗健康行业在所有预测周期中均维持较高的误差水平,反映出其受重大临床试验、监管审批、并购事件等突发因素影响的特殊风险特征。
- 稳定型行业(必需消费、能源、公用事业):具备需求刚性、监管透明、与宏观经济高度相关等特征,市场行为更具规律性,因此预测精度更高。此类行业对模型的长期趋势建模能力要求较低,但对基本面变化的响应需足够灵敏。
此外,上图显示,在仅使用历史价格数据的基准条件下,模型在不同行业间的性能差异明显,为后续引入新闻与舆情信息的增益分析提供了参照。这表明,外部信息的引入对提升高不确定性行业的预测能力具有关键作用。
模型策略风格分化
模型在投资策略上的表现差异,进一步揭示了其内在决策逻辑的分化。根据资金配置模式,可将模型策略划分为两大类:
- 集中型策略:由 DeepSeek-R1、GPT-5 与 o3 构成,其核心特征为将资金高度集中于单一行业,追求高收益与高风险并存的回报模式。该策略在特定行业爆发时可带来极端正收益,但同时也伴随最大亏损风险,实验中表现出显著的峰谷波动。
- 分散型策略:其余三类模型采用多行业配置,通过跨行业资产分散降低整体风险,注重稳健性与长期可持续性。虽然其表现未出现极端峰值,但在各类市场环境下均能维持相对稳定输出,适合风险厌恶型投资者或机构配置需求。
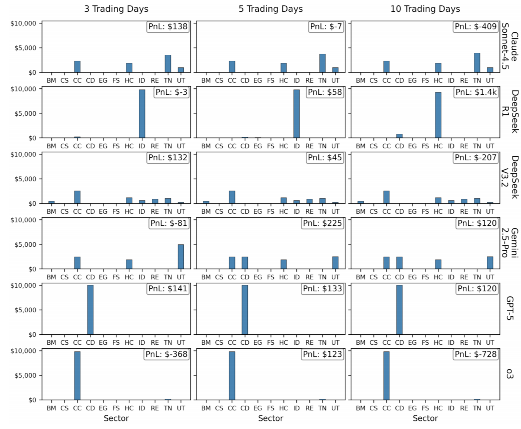
如上图所示,这种策略分化在长期预测中尤为明显:集中型模型在个别行业实现突破,而分散型模型则在整体波动率控制上更具优势。该结果提示,在实际应用中,应根据投资目标与风险偏好选择适配的模型策略。
外部信息影响分析
财务指标与真实新闻的影响
在短期预测中,财务指标与真实新闻均能显著提升模型的预测精度,其中新闻信息的信号强度尤为突出。这一现象表明,近期发布的权威新闻内容对市场价格的即时反应具有更强的解释力,能够有效捕捉市场情绪与突发事件带来的短期波动。
- 短期效应显著:在 1–5 日的预测周期内,真实新闻提供的信息流比财务指标更具时效性与敏感性,其信号强度更高,能够快速反映市场变化。
- 误差降低效果明显:实验数据显示,引入财务指标使相对误差降低 0.074,而真实新闻则带来更显著的 0.198 的误差降幅,说明新闻信息在捕捉短期市场动态方面具有更强的预测增益。
- 中长期负面影响:然而,当预测周期延长至 10–20 日时,这两类信息反而导致预测性能下降。这表明其影响具有明显的时效性与短期性,主要作用于近端市场价格调整,难以支撑长期趋势建模。
这一发现提示我们,尽管外部信息在短期内能增强模型表现,但若未结合时间衰减机制或信息可信度评估,其长期使用可能引入噪声,反而干扰模型对基本面趋势的判断。
虚假信息的影响
- 短期严重损害性能:在预测初期(1–5 日),虚假信息导致模型性能显著下降,暴露出其对信息真实性的高度敏感性。这表明模型在缺乏有效验证机制时,容易将误导性内容误认为有效信号,从而引发错误推理。
- 负面效应随周期减弱:随着预测周期延长,虚假信息带来的负面影响逐渐减弱。这一现象可能源于模型在训练过程中逐步学习到对信息来源、表达方式和语义一致性等特征的判别能力。
- 长期内可能转为轻微正面影响:在 10–20 日的中长期预测中,部分模型甚至表现出轻微的性能提升,暗示其具备逐步识别与过滤虚假内容的能力。这表明模型在持续学习中发展出对“夸大”“虚构成分”的辨别机制,能够将虚假信息中的噪声转化为潜在的反向信号。
综合来看,外部信息的影响具有显著的时间依赖性与性质差异。财务指标与真实新闻在短期具有显著增益,但中长期可能因信息过时或过度反应而产生反效果;而虚假信息虽在短期内造成严重干扰,但模型具备一定的自适应过滤能力,长期中或可转化为辅助判断的信号源。因此,在构建金融预测系统时,应引入动态信息权重调整机制与可信度评估模块,以实现对外部信息的智能筛选与有效利用。对这类大数据处理与价值挖掘的研究,是金融科技领域的重要方向。
项目链接
项目标题
PriceSeer: Evaluating Large Language Models in Real-Time Stock Prediction
github仓库
https://github.com/BobLiang2113/PriceSeer
对这篇研究的深入探讨,我们欢迎更多开发者加入云栈社区的交流,共同研究人工智能在量化金融领域的应用前景。
 发表于 2026-1-16 02:45:22
|
查看: 306|
回复: 0
发表于 2026-1-16 02:45:22
|
查看: 306|
回复: 0
