一、Llama-factory安装
-
从GitHub下载最新版本的llama-factory代码包
-
在GPU服务器上解压:
unzip Llama-factory-main.zip
-
创建虚拟环境:
conda create -n llama-factory --offline --clone base
-
安装llama-factory依赖包:
cd Llama-factory-main
pip install -e ".[torch, metrics]"
-
安装过程中如遇报错,可根据提示解决。例如出现导入错误时:
yum install libsndfile
-
验证安装结果:
llamafactory-cli version
显示版本信息即表示安装成功。
二、数据集及训练模型准备
1. 数据集准备
使用测试团队提供的训练数据集,共计477条"测试用例生成脚本"数据。数据集按3:7比例分割,137条作为评估数据集,340条作为训练数据集。
将数据文件上传至./Llama-factory/data目录,修改dataset_info.json文件添加以下配置:
"testcase_pred": {
"file_name": "data_json_0710_pred.json"
},
"testcase_train": {
"file_name": "data_json_0710_train.json"
}
2. 训练模型准备
基础模型采用qwen3-8b,从魔搭社区下载safetensors格式模型文件,存放于服务器目录如/data/1/models/Qwen/qwen3-8b。
三、基于Llama-factory WebUI进行微调
Llama-factory提供可视化WebUI界面,新手可通过以下命令启动:
cd /data/1/models/Llama-factory
CUDA_VISIBLE_DEVICES=2,3 GRADIO_SERVER_PORT=9582 llamafactory-cli webui
访问http://IP:9582即可进入操作界面。
微调流程包含训练、评估、对话和导出四个核心环节。
1. 模型微调
配置步骤如下:
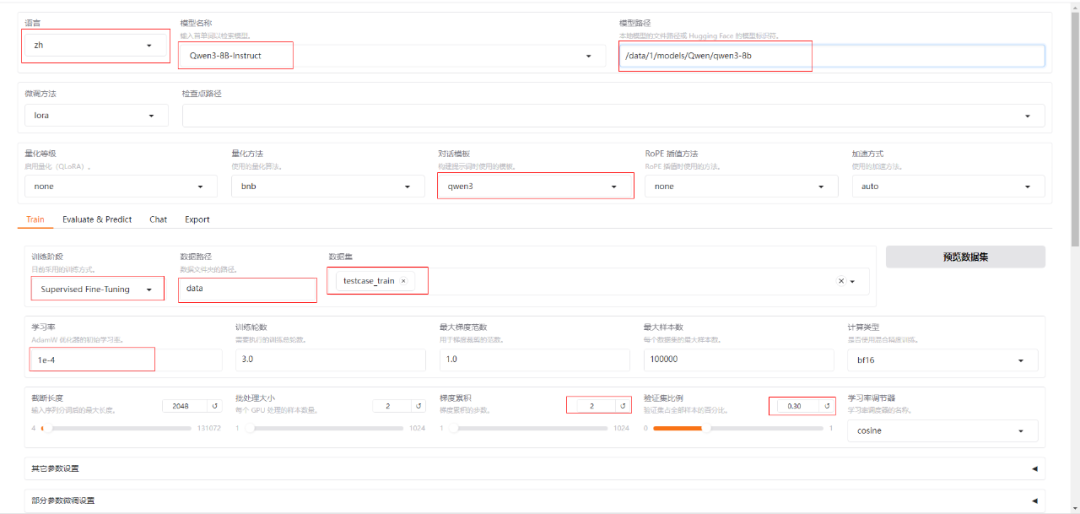
- 选择本地基础模型和训练数据集(testcase_train)
- 优化方案暂采用默认设置
- 点击预览命令查看完整训练指令
- 保存训练参数至本地
- 点击开始按钮启动微调
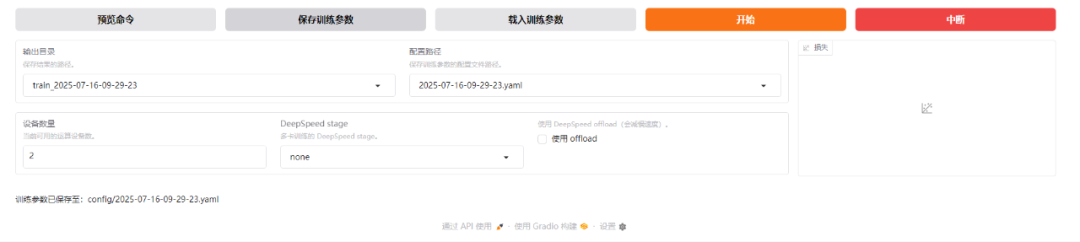
训练过程中可实时监控进度和损失函数变化,完成后页面会显示提示信息。
2. 模型评估
切换至Evaluate&Predict页面:
- 选择预准备的评估数据集
- 启动评估任务并查看进度
- 获取评估结果如下:
{
"predict_bleu-4": 4.891540000000001,
"predict_model_preparation_time": 0.0064,
"predict_rouge-1": 7.424934285714286,
"predict_rouge-2": 2.1897800000000003,
"predict_rouge-l": 4.195487857142858,
"predict_runtime": 725.8749,
"predict_samples_per_second": 0.189,
"predict_steps_per_second": 0.048
}
3. 模型对话
在Chat页面执行以下操作:
- 选择训练完成的检查点模型
- 点击加载模型按钮
- 输入测试内容验证输出效果
- 观察微调后模型对特定指令的响应能力
4. 模型导出
导出步骤:
- 切换到Export页面
- 指定导出目录路径
- 点击开始导出合并基础模型与微调检查点
- 完成后在服务器目录查看完整模型文件
四、总结
通过本次实践,我们完成了基于人工智能框架Llama-factory的完整微调流程。虽然评估指标显示模型效果仍需优化,但已验证了通过Python环境进行本地模型微调的可行性,为后续深度优化奠定了实践基础。 |  发表于 2025-11-29 03:07:17
|
查看: 276|
回复: 0
发表于 2025-11-29 03:07:17
|
查看: 276|
回复: 0
