作为现代分布式系统架构的基石,Kafka 的高可用性设计是保障数据流处理稳定可靠的关键。本文将深入解析实现 Kafka 高可用的几个核心机制。
多副本机制
为了避免单点故障与数据丢失,Kafka 通过副本机制将每个分区的数据复制到多个不同的 Broker 上。这是构建高可用集群的第一道防线。
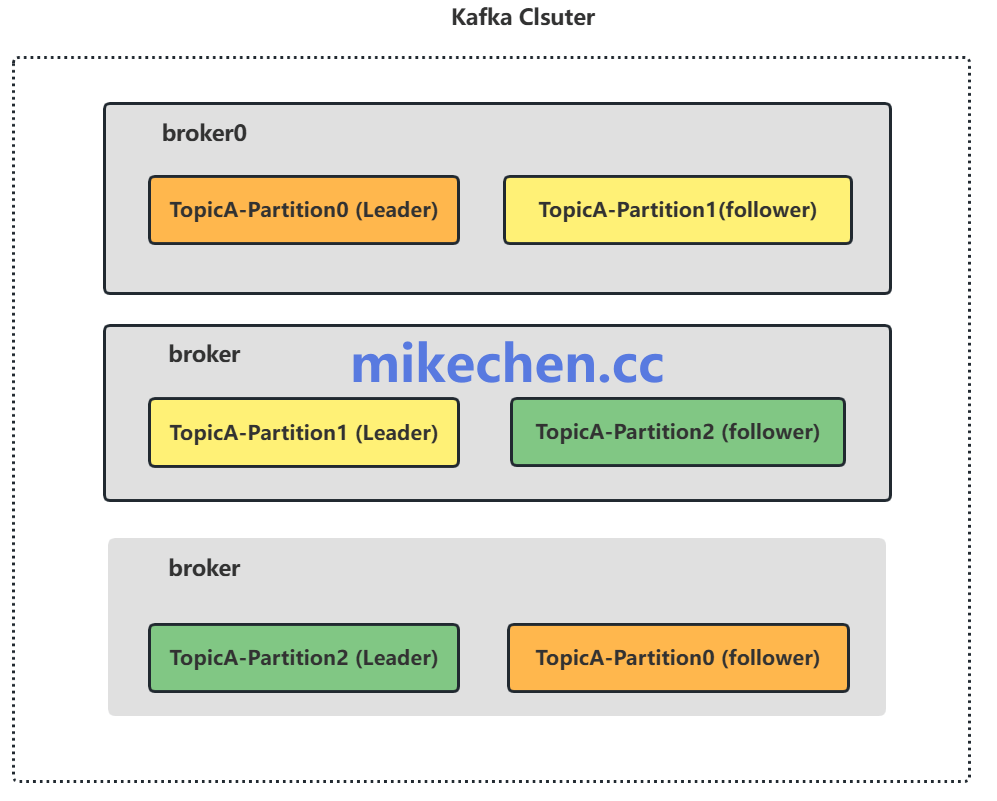
一个关键配置是副本因子(replication.factor),通常建议设置为不低于 3。但这只是开始,核心在于 ISR(In-Sync Replicas)集合 的维护。Kafka 只会将那些与 Leader 副本保持同步状态的副本视为可靠的可用副本。
在写入数据时,生产者的 acks 配置与 min.insync.replicas 参数需要配合使用。例如,设置 acks=all 并要求 min.insync.replicas=2,可以确保在写入时至少有两个副本(包括 Leader)确认成功。这样,即使 Leader 副本发生故障,仍然有处于同步状态的副本可以接管并继续接受写入,从而在强一致性与服务可用性之间取得了良好的平衡。想要深入了解大型系统的高可用设计模式,可以到我们的 后端与架构板块 查阅更多资料。
分区策略
分区是 Kafka 实现并行处理与水平扩展的基础逻辑单位。合理的分区数量能够有效地分散读写负载、提升消费者的并发处理能力。
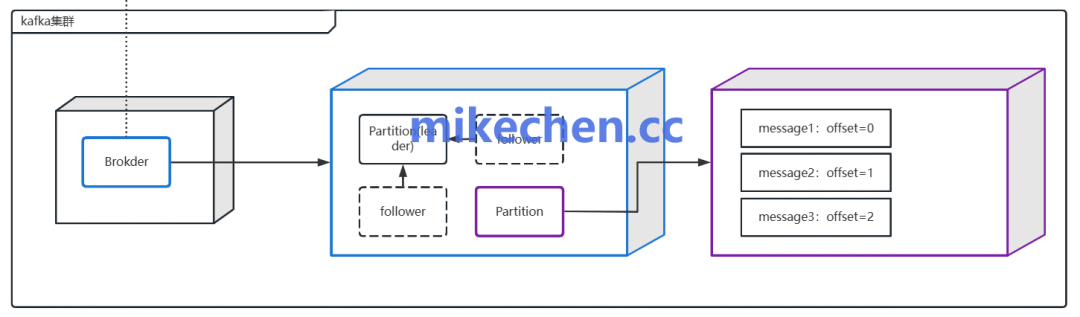
然而,分区数量并非越多越好。过多的分区会增加集群的元数据管理开销和协调成本。在生产者端,需要根据业务键(Key)来合理分配消息到不同分区,这既能实现负载均衡,又能保证相同 Key 的消息有序性(在分区内)。
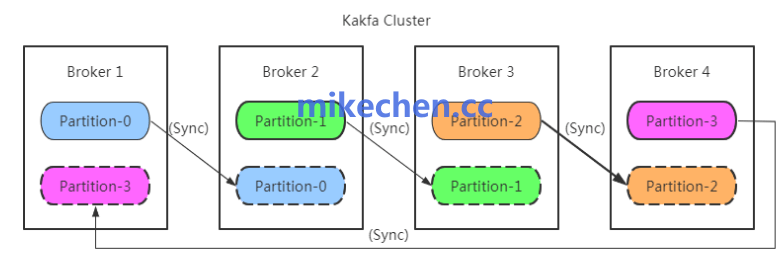
在集群运维层面,当 Broker 宕机或集群扩容时,分区和其副本的分布可能变得不均衡。此时,需要借助动态分区重平衡工具(如 Cruise Control),将分区领导权(Leadership)和副本从负载过高的 Broker 迁移到负载较低的 Broker 上,从而避免热点、保障集群长期稳定运行。
故障恢复机制
Kafka 集群依赖一个单一的 Controller 节点来负责分区 Leader 选举、副本分配等元数据管理任务。因此,Controller 本身的高可用也至关重要。
早期版本中,Controller 的选举和状态同步依赖于 ZooKeeper。在新版本中,Kafka 引入了 KRaft 共识协议来替代 ZooKeeper,以实现更简单、更高效的元数据管理。无论底层机制如何,目标都是相同的:设计稳定的选举流程和快速的故障切换策略,以最大限度地缩短 Controller 故障导致的不可用时间窗口。
当分区 Leader 发生故障时,Controller 会从 ISR 集合中快速选举出一个新的 Leader。相关的配置参数如 unclean.leader.election.enable 需要谨慎对待:若设置为 false(默认),则只允许从 ISR 中选举,保证了数据一致性但可能牺牲可用性;若设置为 true,则允许从非 ISR 副本中选举,提高了可用性但可能造成数据丢失。这需要根据业务对数据一致性的要求来权衡。
运维、监控与容灾策略
高可用性不仅仅停留在架构设计层面,更依赖于一套完善的运维、监控与容灾体系。
全面的监控需要覆盖以下关键指标:
- Broker 可用性:节点是否在线。
- 分区领导分布:Leader 是否均匀分布在各个 Broker 上。
- ISR 大小:同步副本数量是否健康。
- 副本滞后(Replica Lag):Follower 副本落后于 Leader 的消息量。
- 请求延迟与吞吐量:集群性能表现。
- 磁盘利用率:避免因磁盘写满导致服务不可用。
基于监控指标设置合理的告警策略,可以实现问题的早期发现和主动干预。此外,定期进行故障恢复演练和滚动升级验证,是检验高可用架构是否真正有效的“试金石”。
对于更高要求的容灾场景,可以考虑跨数据中心部署。使用工具如 MirrorMaker 或 Kafka 内置的跨集群复制功能,可以将数据实时同步到另一个数据中心的 Kafka 集群中,从而实现灾难恢复和地域级的冗余备份。当然,这也会引入跨数据中心的网络延迟、带宽成本和最终一致性问题,需要根据业务需求仔细评估。想系统学习 Kafka 及其他核心中间件的原理与实践,可以访问 数据库/中间件/技术栈板块 获取更多教程和讨论。 |  发表于 2026-1-18 06:03:59
|
查看: 199|
回复: 0
发表于 2026-1-18 06:03:59
|
查看: 199|
回复: 0
