在追求极致性能的低延时交易系统架构中,许多人对于“快”的定义存在误区。通常认为,只要将 std::mutex 替换为 std::atomic 实现无锁设计,系统性能就能得到质的飞跃。
然而,在毫秒必争的真实应用场景下,平均延迟往往是一个具有欺骗性的指标。真正决定系统稳定性的,是 P99甚至P999延迟。即使系统成功处理了百万个请求,前九十九万个的响应时间都在几十纳秒,只要最后几个请求因资源竞争卡顿了50微秒,对于下游的实时业务而言,这就是不可接受的抖动。
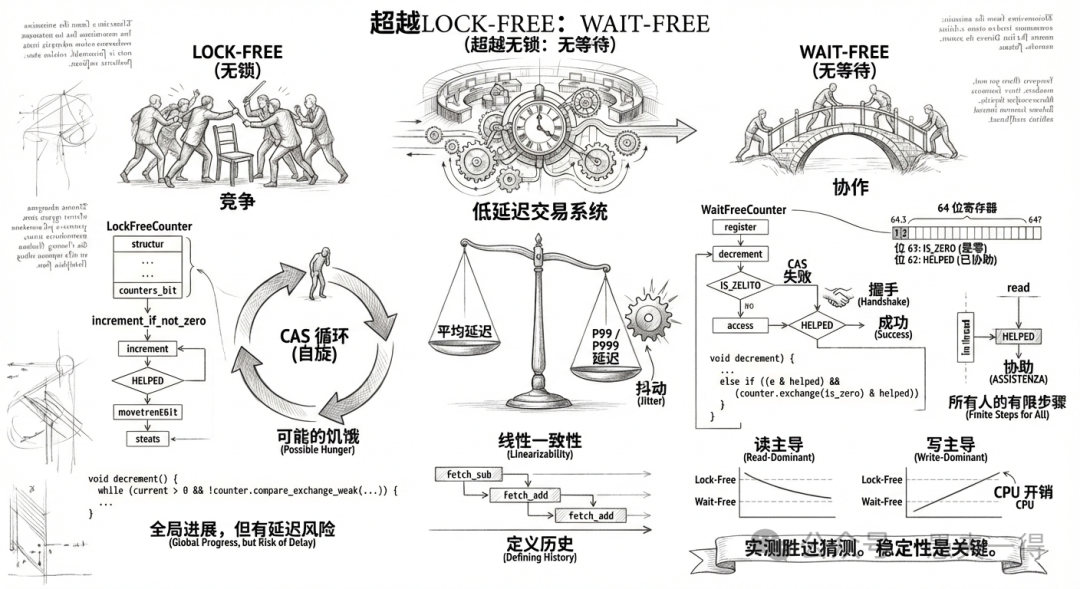
今天,我们将视角从CAS循环移开,探讨并发编程中更为高级且更具挑战性的概念:Wait-Free。为了深入理解,我们将剖析两个版本的“计数器”实现,逐步揭示其中的技术细节。
Lock-Free:全局推进与潜在饥饿
首先,我们需要一个参照物。Lock-Free 是目前主流的高并发编程范式,其核心哲学是保证系统在全局层面的推进。
下面是一个经典的 Lock-Free 计数器,这种模式在 C++ 的 shared_ptr 引用计数中非常常见:我们需要一个“Sticky Counter”,即计数器一旦归零,就永久保持在零状态,不允许再被增加(意味着对象已销毁):
struct LockFreeCounter {
std::atomic<uint64_t> counter{1};
bool increment_if_not_zero() {
auto current = counter.load();
// 核心逻辑:CAS 循环
while (current > 0 && !counter.compare_exchange_weak(current, current + 1)) {
// 如果 current 变了(说明被别人抢先修改了),循环继续,拿着新值重试
}
return current > 0;
}
bool decrement() {
return counter.fetch_sub(1) == 1; // 只看是否减到0
}
};
这段代码非常精简,利用CPU原语消除了锁的开销。就像一群人争抢唯一的会议室,无论竞争多么激烈,总有一人能成功进入。系统整体上始终在向前推进,不会因为某个线程被挂起而导致整体停滞。
但是,竞争失败的线程会怎样?
仔细看那个 while 循环。在 Lock-Free 的定义中,我们默认允许“饥饿”现象的存在。如果你的系统中有一个负责关键信号处理的线程运气极差,每次执行CAS指令前的一瞬间都被其他线程抢先修改,它就会在这个 while 循环中无限自旋。
对于追求确定性的低延时系统,这种“理论上可能永远循环下去”的代码是不可控的风险源。
Wait-Free:有限步数与协作精神
如何消除这种不确定性?答案就是 Wait-Free。
Wait-Free 的定义极为严苛:每一个线程,无论其他线程如何执行、挂起或被调度,都必须在有限的步数内完成自己的操作。也就是说,代码中绝不能出现不可控的重试循环。
这听起来有些反直觉:如果CAS操作失败了,不重试该怎么办?难道直接报错吗?
Wait-Free 的核心思维转换在于:从“竞争”走向“协作”。当 Lock-Free 的逻辑是“你挡住了我的路,我需要重试推开你”时,Wait-Free 的逻辑则是“我看到你似乎遇到了困难,我顺手帮你把工作完成,然后我们一起前进”。这种机制被称为 Helping。
下面展示一个 Wait-Free 的 Sticky Counter 实现,它体现了这种协作模式。为了实现无循环,需要引入 Bit Stealing 技术:既然64位计数器的低位用不完,我们就挪用高位作为状态标记。
static constexpr uint64_t is_zero = 1ull << 63; // 第63位:标记“已置零”
static constexpr uint64_t helped = 1ull << 62; // 第62位:标记“协助中”
- 低 62 位:存储实际的计数值。
- 第 63 位 (
is_zero):表示计数器已经归零,并且状态已被“固化”。一旦此位被置 1,计数器在逻辑上就永远视为 0。
- 第 62 位 (
helped):这是一个中间状态,表示“正在处理归零逻辑”或“已经有人协助处理了”。
请仔细品味 decrement(减操作)的逻辑,这是整个算法的核心:
bool decrement() {
// 步骤 1:先斩后奏。
// 不管三七二十一,先原子减 1。这一步绝对不会阻塞,也绝对不用循环。
if (counter.fetch_sub(1) == 1) {
// 此时,物理内存里的值可能已经变成 0 了。
// 但我们需要确立“归零”这个逻辑状态。
// 只有旧值是 1 的这个线程,有资格去宣告“是我把计数器归零的”。
uint64_t e = 0;
// 步骤 2:尝试宣示主权。
// 试图将计数器从 0 变成 is_zero (标记位)。
if (counter.compare_exchange_strong(e, is_zero))
return true; // 运气真好,没冲突,我也成功置位,任务结束。
// 步骤 3:CAS 失败了?这时候要是 Lock-Free 就该 while 重试了。
// 但 Wait-Free 不允许重试。我们需要分析失败原因。
// 失败意味着 e 被更新成了当前内存里的值。
// 我们检查这个当前值里,是不是包含了 helped 标记?
else if ((e & helped) && (counter.exchange(is_zero) & helped))
// 这一行是逻辑的高潮:
// 条件1 (e & helped):说明有个好心人(通常是 read 线程)发现我想归零但还没做,
// 于是它帮我把值设成了 is_zero | helped。
// 条件2 (exchange):这是一个“握手”。我无条件把值设回纯粹的 is_zero。
// 为什么?因为我要确认刚才那个 helped 标记确实是针对我的“协助”,而不是随机的垃圾数据。
// 如果 exchange 拿回来的旧值里确实有 helped,说明协助关系成立。
return true;
}
return false;
}
这段代码最反直觉的地方在于:当 CAS 失败时,它没有选择重试,而是去检查是否有其他线程已经帮它完成了工作。
那么,谁来提供帮助呢?是 read 线程。在 Wait-Free 的设计中,读操作不再是单纯的只读操作,它也承担起了维护系统状态的责任:
uint64_t read() {
auto val = counter.load();
// 如果读到 0,说明可能刚刚有个线程执行了 fetch_sub,但还没来得及设 is_zero 标记。
// 作为 Wait-Free 的读线程,我不能干等着(那就变成阻塞了),也不能返回错误的中间状态。
// 我选择“多管闲事”:帮那个兄弟把标记位立起来!
if (val == 0 && counter.compare_exchange_strong(val, is_zero | helped))
return 0; // 我帮忙了!
return (val & is_zero) ? 0 : val;
}
这就是 Wait-Free 的精髓:写线程将值减到 0 后正准备设置标记,读线程进来发现值是 0 但没有标记,它不阻塞,而是直接帮忙写入 is_zero | helped。随后,写线程尝试设置标记失败,但通过检查 helped 位发现已经有人帮忙,于是直接“握手”并返回。所有线程都在有限的步数内向前推进,彻底消除了时间上的不确定性。
当然,对于 increment_if_not_zero 操作,逻辑则相对简单:
bool increment_if_not_zero() {
return (counter.fetch_add(1) & is_zero) == 0;
}
线性一致性:定义操作的“历史”
你可能会产生疑问:fetch_sub 之后,内存中确实短暂地变成了 0,如果此时另一个线程执行 increment_if_not_zero 看到 0 并把它加回了 1,该怎么办?CAS 失败既不是因为自己,也不是因为协助,而是因为有人“捣乱”(加回去了),这种情况下不需要重试吗?
这里涉及到并发设计的另一个重要理论——线性一致性。
在 Wait-Free 算法中,我们不仅是在编写代码,更是在定义操作的历史。当 fetch_sub(减)和 fetch_add(加)操作并发交错时,在物理时间上它们可能重叠了,但在逻辑时间轴上,我们可以强制规定:如果 decrement 的 CAS 失败是因为被 increment 干扰(导致值不再是 0),那么我们就视作 decrement 操作发生在 increment 操作之后。
既然是一加一减,结果相互抵消,那么我们就当作无事发生,直接返回 false(表示不需要执行归零逻辑)。通过这种严密的逻辑推导来规避重试,是 Wait-Free 算法设计中为了换取“有限步数”这一特性而采用的策略。
并非越复杂越快:适用场景的权衡
那么,算法越复杂、概念越高级,性能就必然越好吗?
事实并非如此。Wait-Free 并不总是比 Lock-Free 快。它的优势主要体现在稳定性和读多写少的场景中。
- 在读操作占主导时,Wait-Free 表现极佳。因为读线程的“协助”行为分散了写线程的竞争压力,而且读操作本身不需要像 CAS 循环那样反复争抢缓存行。
- 但在写操作占主导时,Lock-Free 反而可能更快。原因在于,Wait-Free 所涉及的位运算、状态判断、原子交换握手等操作,都是实打实的 CPU 指令开销。而 Lock-Free 在竞争不激烈时,只是一个简单的原子加减操作,极其轻量。
总结
从 Lock-Free 到 Wait-Free,不仅仅是代码技巧的提升,更是对系统确定性追求的进阶。
- Lock-Free 是“适者生存”:它保证了系统整体的高吞吐量,但允许个别请求因竞争而产生长尾延迟。
- Wait-Free 是“兜底承诺”:它通过复杂的协作机制,保证每一个请求都能在可预期的指令周期内完成,彻底消除了因自旋导致的延迟抖动。
对于低延时系统的开发者而言,务必牢记:实测数据远比理论猜测更为可靠。
如果你的系统对 P99 延迟极其敏感,或者像 shared_ptr 引用计数这样需要绝对防止死锁/活锁的底层机制,Wait-Free 是你的重要工具。但对于绝大多数通用场景,一个编写精良的 Lock-Free 结构,甚至是一个设计良好的自旋锁,往往才是性能与复杂度之间的最佳平衡点。更多关于C++高性能编程的讨论,欢迎在云栈社区进行交流。
 发表于 2026-1-18 06:07:42
|
查看: 156|
回复: 0
发表于 2026-1-18 06:07:42
|
查看: 156|
回复: 0
