在实时音频通信中,有效的噪声抑制至关重要。本文将对 WebRTC 音频处理模块中的核心降噪器 NoiseSuppressor 进行源码级剖析,重点关注其数据流架构与关键方法 Analyze 的实现细节。
WebRTC NS模块处理流程
首先,我们来了解音频数据流进入降噪处理的核心路径。下图清晰地展示了 WebRTC 音频处理模块的层级架构与数据流向:
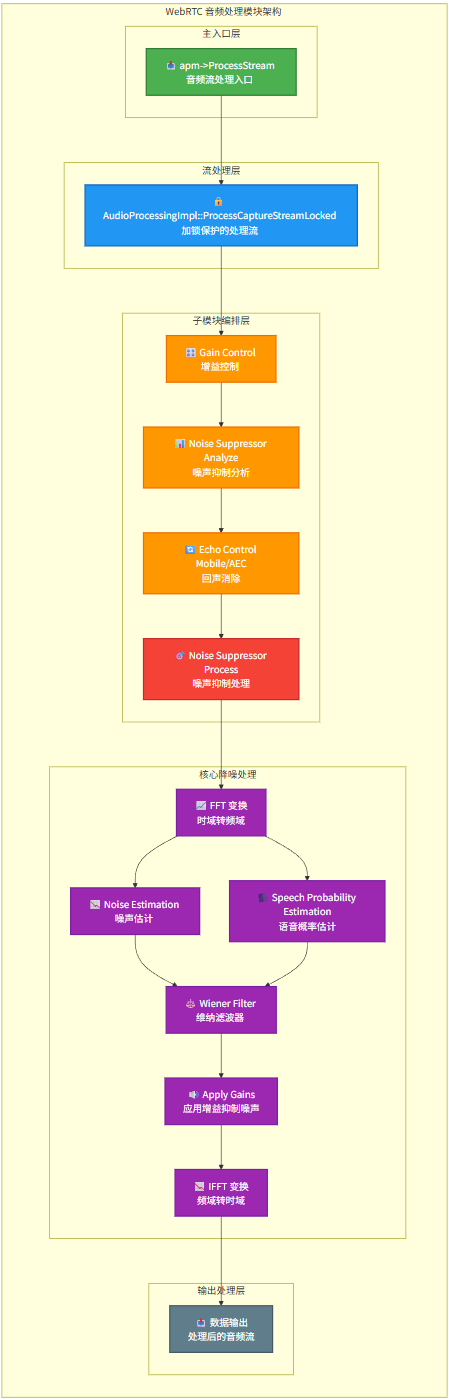
该架构主要分为四个层次:主入口层、流处理层、子模块处理层和核心降噪处理层。数据从 apm->ProcessStream 进入,经过加锁保护的处理流后,依次通过增益控制、噪声抑制分析、回声消除等子模块。对于噪声抑制(NS)而言,其核心处理在频域完成,包括 FFT 变换、噪声估计、语音概率估计、维纳滤波、应用增益抑制噪声,最后通过 IFFT 变换将处理后的频域信号转回时域输出。
聚焦于降噪模块本身,其核心类是 NoiseSuppressor。
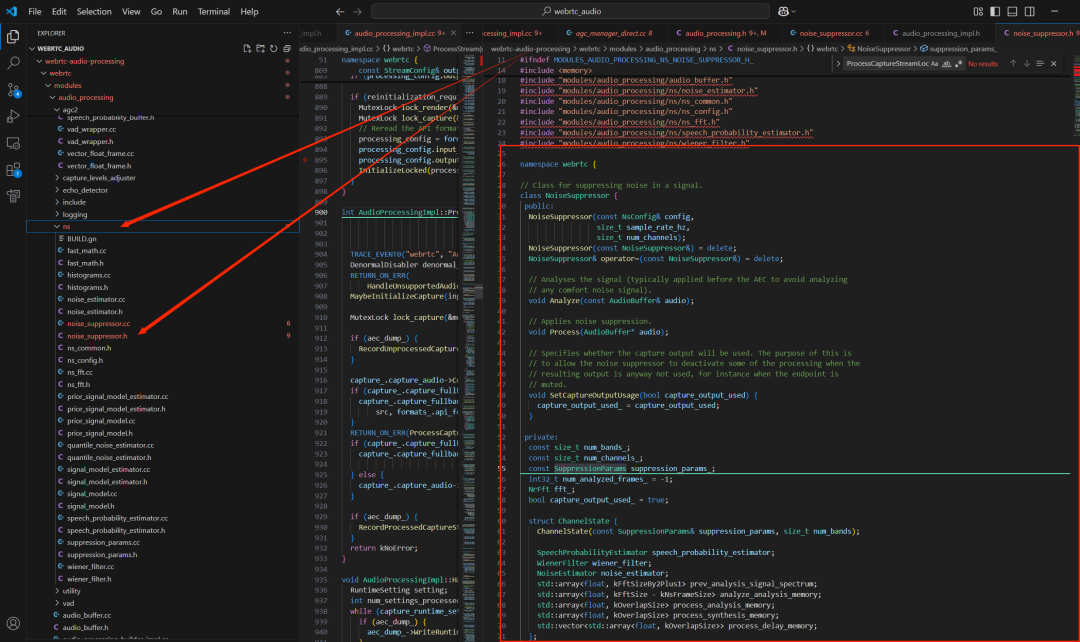
// 用于对输入信号做降噪(Noise Suppression, NS)的核心类。
// 典型位置:WebRTC 音频处理链路(APM)里,通常在 AEC(回声消除) 前后之一执行:
// - Analyze() 常用于“只分析统计量”,可在 AEC 前做,避免分析到 AEC 的 comfort noise。
// - Process() 才会真正修改音频数据,执行降噪。
class NoiseSuppressor {
public:
// 构造函数:
// config : NS 的配置(强度、模式、是否启用某些策略等)
// sample_rate_hz : 采样率(8k/16k/32k/48k... 会影响频带数、上频带处理等)
// num_channels : 通道数(1=mono, 2=stereo...)
NoiseSuppressor(const NsConfig& config,
size_t sample_rate_hz,
size_t num_channels);
// 禁止拷贝:因为内部持有大量状态/堆内存,拷贝成本大且容易引入状态错误。
NoiseSuppressor(const NoiseSuppressor&) = delete;
NoiseSuppressor& operator=(const NoiseSuppressor&) = delete;
// 只分析输入信号(不修改音频内容)。
// 注释里提到:通常在 AEC 前调用,避免把 AEC 产生的 comfort noise 当成噪声/语音去统计。
//
// Analyze() 的典型职责:
// 1) 计算频谱/能量特征
// 2) 更新噪声估计(NoiseEstimator)
// 3) 更新语音存在概率(SpeechProbabilityEstimator)
// 4) 更新上一帧频谱等历史状态
void Analyze(const AudioBuffer& audio);
// 对音频做真正的降噪处理(会就地修改 audio)。
//
// Process() 的典型职责:
// 1) FFT(含 overlap 拼帧)
// 2) 根据噪声估计 + 语音概率计算 Wiener 增益(或其他增益曲线)
// 3) 频域乘增益抑制噪声
// 4) IFFT + overlap-add 合成输出
void Process(AudioBuffer* audio);
// 指定“采集端输出是否会被使用”。
// 目的:当输出不会被用到(例如静音、端点 mute),NS 可以关闭/简化部分耗时步骤降低 CPU。
// 注意:一般仍要维护部分状态,避免恢复输出时瞬态不稳定(爆音、增益突变等)。
void SetCaptureOutputUsage(bool capture_output_used) {
capture_output_used_ = capture_output_used;
}
private:
// ======= 维度与配置参数 =======
// 频带数(band 的概念通常与采样率相关):
// - 在 WebRTC 中,高采样率(32k/48k)往往会拆“低频带 + 高频带(upper band)”进行处理/对齐。
// - num_bands_ 用于控制滤波器组状态、上频带增益数组等的大小。
const size_t num_bands_;
// 通道数:每个通道都有独立的噪声估计、语音概率估计、Wiener滤波状态等。
const size_t num_channels_;
// 抑制参数(由 NsConfig 转换/预计算得到):
// 通常包含:
// - 不同频段的目标抑制量(dB)
// - 最小增益限制(避免“全静音/水下音”)
// - 语音存在时的保真策略(减少语音失真)
// - 过渡平滑、攻击/释放时间常数等
const SuppressionParams suppression_params_;
// 已分析的帧计数:
// - 初始 -1 表示“尚未开始/尚未初始化到稳定状态”
// - 某些算法会在前 N 帧做 warm-up(例如先估噪,再逐步启用强抑制)
int32_t num_analyzed_frames_ = -1;
// FFT 工具对象(NS 的核心是频域处理):
// - 内部会用固定 FFT 大小 kFftSize
// - 以及 kFftSizeBy2Plus1(实信号 FFT 的半谱大小 N/2+1)
NrFft fft_;
// 输出是否被使用(用于降耗/跳过部分处理)
bool capture_output_used_ = true;
// ======= 每通道状态(独立状态机) =======
struct ChannelState {
// 每通道的状态依赖 suppression_params 和 num_bands(例如不同 band 的延迟线长度等)
ChannelState(const SuppressionParams& suppression_params, size_t num_bands);
// 语音概率估计器:
// - 输出每个频点/每个 band 的“像语音的概率”
// - 常用特征:SNR、谱平坦度、谱变化率、历史平滑等
// - 用于避免把语音也当噪声压得太狠
SpeechProbabilityEstimator speech_probability_estimator;
// Wiener 滤波器状态:
// - Wiener 增益常见形式:G(k) = SNR / (SNR + 1)
// - 实际会结合语音概率做保真(比如语音概率高 -> 增益更接近1)
// - wiener_filter 通常保存平滑状态、上一帧增益等
WienerFilter wiener_filter;
// 噪声估计器:
// - 跟踪每个频点的噪声功率谱密度(noise PSD)
// - 在无语音段快速更新,在语音段慢更新或冻结,避免把语音统计进噪声
NoiseEstimator noise_estimator;
// 上一帧“分析用”的频谱(半谱大小 N/2+1):
// - 用于平滑、计算谱变化、语音概率特征、突变检测等
std::array<float, kFftSizeBy2Plus1> prev_analysis_signal_spectrum;
// Analyze() 的分析端 overlap 记忆:
// - 因为 NS 通常是 10ms 一帧输入(kNsFrameSize),
// 但 FFT 窗口 kFftSize 往往更大,需要把上一帧尾巴与当前帧拼成 extended_frame。
// - 这个数组保存“上一帧剩余那部分”。
std::array<float, kFftSize - kNsFrameSize> analyze_analysis_memory;
// Process() 的分析端 overlap 记忆(与 Analyze 分开存):
// - Analyze 和 Process 可能在 pipeline 的不同位置被调用,
// 两条路径的状态不能互相踩。
std::array<float, kOverlapSize> process_analysis_memory;
// Process() 的合成端 overlap 记忆:
// - IFFT 回来的时域信号,需要 overlap-add 合成连续输出,
// 这里保存合成时的重叠部分。
std::array<float, kOverlapSize> process_synthesis_memory;
// 处理延迟线(可能是:每个 band 一条或若干条):
// - 在多 band、上频带对齐、或某些平滑/决策需要 lookback 时使用
// - vector<array<kOverlapSize>> 表明:延迟线长度可变(由 num_bands 或配置决定)
std::vector<std::array<float, kOverlapSize>> process_delay_memory;
};
// ======= 滤波器组/FFT 临时工作区 =======
struct FilterBankState {
// FFT 复数频谱的实部缓存
std::array<float, kFftSize> real;
// FFT 复数频谱的虚部缓存
std::array<float, kFftSize> imag;
// 拼好的扩展时域帧(窗函数/overlap 后的输入),用于 FFT
std::array<float, kFftSize> extended_frame;
};
// ======= 堆上缓存(避免实时处理中频繁分配) =======
// 滤波器组状态(可能按:通道×band 或 band 数分配,具体看实现)
std::vector<FilterBankState> filter_bank_states_heap_;
// 上频带增益缓存:
// - 当采样率较高时(如 32k/48k),NS 可能对高频段采用独立增益或从低频外推。
// - 这里存每个频点/每个 band 的 upper band 增益。
std::vector<float> upper_band_gains_heap_;
// 滤波前能量/功率缓存:
// - 用于计算 SNR、语音概率、做能量门限、或用于调节增益/抑制策略
std::vector<float> energies_before_filtering_heap_;
// 增益调整项缓存:
// - Wiener gain 计算出来后,可能还会做额外修正:
// * 最小增益限制
// * 语音存在时减轻抑制(保真)
// * 不同频段不同曲线(低频保留更多、噪声集中频段压得更狠)
std::vector<float> gain_adjustments_heap_;
// 每个通道一个 ChannelState(unique_ptr:避免拷贝大对象,明确所有权)
std::vector<std::unique_ptr<ChannelState>> channels_;
// ======= 关键私有方法:多通道 Wiener filter 聚合 =======
// 将多个通道的 Wiener filter 合并为“一个最终滤波器”:
// - 多通道(立体声)时常用来保持左右一致性(避免左右声道音色/噪声底不同)
// - 也可能用于某些共享处理路径(降低计算或稳定决策)
//
// filter 是输出参数:长度 kFftSizeBy2Plus1 的半谱增益曲线
void AggregateWienerFilters(
rtc::ArrayView<float, kFftSizeBy2Plus1> filter) const;
};
从上面的代码可以总结出,NoiseSuppressor 是 WebRTC 中一个功能完整的实时频域降噪器。它对每个音频通道独立维护噪声估计、语音概率和维纳滤波器增益等状态,提供了 Analyze(仅更新统计量)与 Process(实际应用降噪)两阶段接口,并支持多通道滤波器聚合和静音状态下的算力优化。
从构造函数开始深入
为了深入理解其实现,我们首先分析 NoiseSuppressor 的构造函数。它的核心作用是根据采样率和通道数,提前分配并初始化所有降噪所需的状态、缓存和子模块,避免在实时处理过程中进行动态内存分配,这对于保证 C/C++ 音频处理的实时性至关重要。
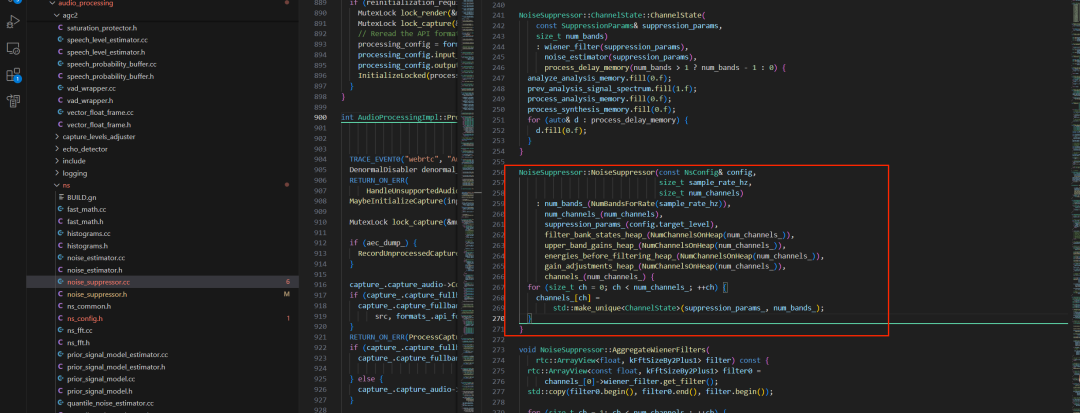
NoiseSuppressor::NoiseSuppressor(const NsConfig& config,
size_t sample_rate_hz,
size_t num_channels)
// ======= 1. 根据采样率计算频带数 =======
// WebRTC 在高采样率(32k/48k)时,会把信号拆成多个 band
//(低频带 + 上频带)分别处理
: num_bands_(NumBandsForRate(sample_rate_hz)),
// ======= 2. 保存通道数 =======
num_channels_(num_channels),
// ======= 3. 从配置生成抑制参数 =======
// suppression_params_ 是 NS 实际算法用的参数集合
// 通常包含:
// - target_level(目标抑制量)
// - 最小增益
// - 平滑系数
// - 语音存在时的保真策略
suppression_params_(config.target_level),
// ======= 4. 预分配滤波器组/FFT 工作区 =======
// NumChannelsOnHeap() 通常返回:
// num_channels * num_bands
// 或
// num_channels
// 具体取决于实现
// 目的:每个通道/频带都有独立 FFT 缓存
filter_bank_states_heap_(NumChannelsOnHeap(num_channels_)),
// ======= 5. 预分配上频带增益缓存 =======
// 高频段可能采用独立增益或从低频外推
// 这里提前分配,避免 Process() 里 new
upper_band_gains_heap_(NumChannelsOnHeap(num_channels_)),
// ======= 6. 预分配滤波前能量缓存 =======
// 用于:
// - 计算 SNR
// - 语音概率估计
// - 决策是否冻结噪声估计
energies_before_filtering_heap_(NumChannelsOnHeap(num_channels_)),
// ======= 7. 预分配增益调整缓存 =======
// Wiener 增益计算完后,还会做额外修正
// 这里提前准备好数组
gain_adjustments_heap_(NumChannelsOnHeap(num_channels_)),
// ======= 8. 为每个通道预留 ChannelState 指针槽位 =======
// 注意:这里只是 resize vector,还没 new ChannelState
channels_(num_channels_) {
// ======= 9. 为每个通道创建独立的 ChannelState =======
for (size_t ch = 0; ch < num_channels_; ++ch) {
channels_[ch] =
std::make_unique<ChannelState>(suppression_params_, num_bands_);
}
}
构造函数中调用的 NumBandsForRate 函数是一个将采样率映射到逻辑处理频带数量的关键函数。这里的“频带”是 WebRTC NS 内部的处理单元,主要用于对不同频率范围的信号采用差异化的策略。
| sample_rate_hz |
num_bands |
含义 |
| 16000 |
1 |
只有低频带 |
| 32000 |
2 |
低频 + 高频 |
| 48000 |
3 |
低频 + 中频 + 高频 |
其核心逻辑是每 16kHz 采样率对应一个处理频带:
- 16kHz 采样率:只处理 0~8kHz 范围(语音能量主要集中在此)。
- 32kHz 采样率:band0处理 0~8kHz,band1处理 8~16kHz。
- 48kHz 采样率:band0处理 0~8kHz,band1处理 8~16kHz,band2处理 16~24kHz。
需要注意的是,对于 44.1kHz 这类非 16kHz 整数倍的采样率,WebRTC NS 可能无法直接处理,通常需要先进行重采样。
另一个关键配置是降噪等级,它通过 NsConfig 结构体中的 target_level 枚举来设定:
// Config struct for the noise suppressor
struct NsConfig {
enum class SuppressionLevel { k6dB, k12dB, k18dB, k21dB };
SuppressionLevel target_level = SuppressionLevel::k12dB;
};
| 枚举值 |
含义 |
实际效果 |
| k6dB |
轻度降噪 |
几乎不损音质,噪声残留多 |
| k12dB |
中等降噪(默认) |
平衡点 |
| k18dB |
强降噪 |
噪声明显减少,但可能轻微失真 |
| k21dB |
极强降噪 |
最狠,容易产生“水下音” |
构造函数中还涉及到一个内存管理函数 NumChannelsOnHeap:
// Maximum number of channels for which the channel data is stored on
// the stack. If the number of channels are larger than this, they are stored
// using scratch memory that is pre-allocated on the heap. The reason for this
// partitioning is not to waste heap space for handling the more common numbers
// of channels, while at the same time not limiting the support for higher
// numbers of channels by enforcing the channel data to be stored on the
// stack using a fixed maximum value.
constexpr size_t kMaxNumChannelsOnStack = 2;
// Chooses the number of channels to store on the heap when that is required due
// to the number of channels being larger than the pre-defined number
// of channels to store on the stack.
size_t NumChannelsOnHeap(size_t num_channels) {
return num_channels > kMaxNumChannelsOnStack ? num_channels : 0;
}
其设计非常巧妙:对于最常见的单声道或立体声(通道数 ≤ 2),相关数据存储在栈上以追求极致的访问速度;只有当通道数超过2时,才在堆上预分配内存。这种策略在保证对多通道音频支持的同时,优化了普遍情况下的性能,是实时音频处理中经典的内存管理设计。
NoiseSuppressor::Analyze 方法详解
接下来,我们深入分析 NoiseSuppressor::Analyze 方法的内部实现,这是理解 WebRTC 如何“感知”噪声与语音的关键。
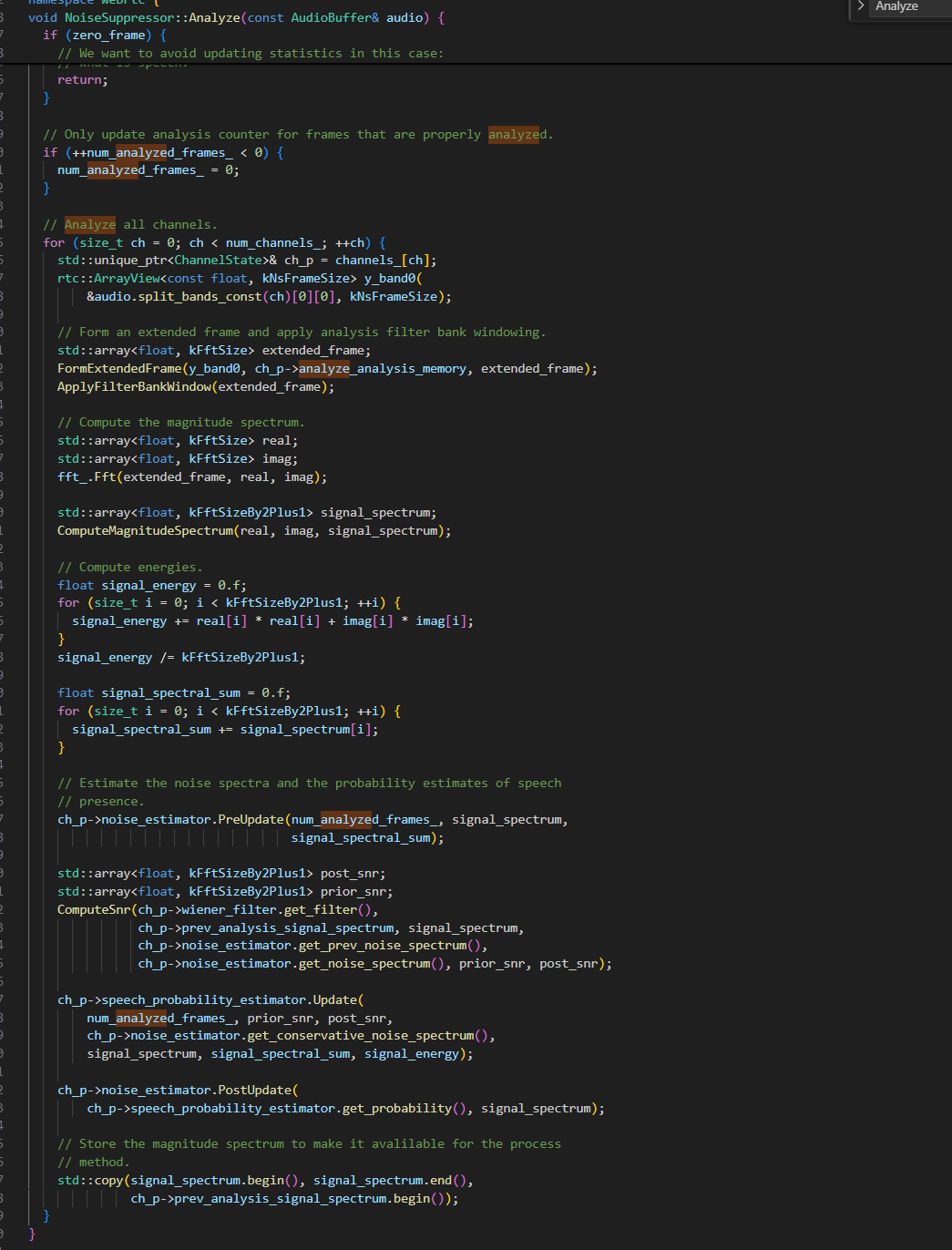
void NoiseSuppressor::Analyze(const AudioBuffer& audio) {
// ============================
// [阶段 0] 每帧分析开始:让噪声估计器进入“分析阶段准备”状态
// ============================
// 作用:为本帧噪声估计更新做准备(例如清空/复位一些临时变量,切换状态机阶段等)
for (size_t ch = 0; ch < num_channels_; ++ch) {
channels_[ch]->noise_estimator.PrepareAnalysis();
}
// ============================
// [阶段 1] 检测“全零帧”(zero frame)
// ============================
// 为什么要检测?
// - 实际系统里,麦克风 mute / 通道未连接 / 上游直接置零,会出现连续很多“全 0”帧。
// - 如果在全 0 帧时继续更新“噪声统计/语音阈值”,统计量会被拉向“零信号”,
// 导致后续一旦有真实信号进来,算法会误判“一切都是语音”,从而降噪失效,
// 并且需要很长时间重新学习噪声底。
bool zero_frame = true;
for (size_t ch = 0; ch < num_channels_; ++ch) {
// 取出本通道的 band0(第 0 个频带)的 10ms 时域数据。
// split_bands_const(ch)[0] 是 band0 的 float 数组(长度 kNsFrameSize)
rtc::ArrayView<const float, kNsFrameSize> y_band0(
&audio.split_bands_const(ch)[0][0], kNsFrameSize);
// 计算“扩展帧”的能量:当前 10ms + 上一帧遗留的 overlap memory(analyze_analysis_memory)
// 注意:这里不是只算当前 y_band0 能量,而是算“拼接后的 extended frame 能量”
// 这样可以更可靠地判断是否真的是“全静音/全0”
float energy = ComputeEnergyOfExtendedFrame(
y_band0, channels_[ch]->analyze_analysis_memory);
// 只要任何一个通道的能量 > 0,就不是全零帧
if (energy > 0.f) {
zero_frame = false;
break;
}
}
if (zero_frame) {
// ============================
// 全零帧:直接返回,不更新任何统计量
// ============================
// 注释解释的核心点:
// - 若用全0信号更新统计,会把各种阈值/均值拉向 0
// - 一旦信号恢复,算法会把一切当作语音(speech)
// - 降噪效果消失,并且需要较长时间重新“学会噪声是什么”
return;
}
// ============================
// [阶段 2] 更新分析帧计数 num_analyzed_frames_
// ============================
// 只有“真正分析过的帧”才计数:zero_frame 会被跳过。
// 初始值可能是 -1,这里确保递增后不会一直为负。
if (++num_analyzed_frames_ < 0) {
num_analyzed_frames_ = 0;
}
// ============================
// [阶段 3] 对每个通道做频域分析与统计更新(不修改音频)
// ============================
for (size_t ch = 0; ch < num_channels_; ++ch) {
// ch_p:当前通道的状态(噪声估计/语音概率/维纳滤波/历史频谱/overlap memory 等)
std::unique_ptr<ChannelState>& ch_p = channels_[ch];
// 取本通道 band0 的 10ms 输入帧
rtc::ArrayView<const float, kNsFrameSize> y_band0(
&audio.split_bands_const(ch)[0][0], kNsFrameSize);
// ----------------------------
// 3.1 构造 extended frame(扩展帧)并加窗
// ----------------------------
// 为什么要 extended frame?
// - NS 以 10ms 为“处理步长”,但 FFT 往往需要更长窗口 kFftSize(例如 256/512/1024)
// - 因此必须把上一帧尾巴(overlap)与当前帧拼接成 kFftSize 长度的 FFT 输入
// - analyze_analysis_memory 保存的是上一帧保留下来的那一段,用于 overlap 拼接
std::array<float, kFftSize> extended_frame;
FormExtendedFrame(y_band0, ch_p->analyze_analysis_memory, extended_frame);
// ApplyFilterBankWindow:对时域帧乘窗函数(如 Hann/Hamming 等)
// 作用:
// - 降低频谱泄漏(spectral leakage)
// - 让频域幅度更稳定,便于做噪声估计/语音概率估计
ApplyFilterBankWindow(extended_frame);
// ----------------------------
// 3.2 FFT -> 频谱(real/imag),再计算幅度谱 |X(k)|
// ----------------------------
// real/imag:FFT 输出复数频谱的实部和虚部
std::array<float, kFftSize> real;
std::array<float, kFftSize> imag;
fft_.Fft(extended_frame, real, imag);
// signal_spectrum:幅度谱(通常只取半谱 N/2+1,因为输入是实信号)
// kFftSizeBy2Plus1 = kFftSize/2 + 1
std::array<float, kFftSizeBy2Plus1> signal_spectrum;
ComputeMagnitudeSpectrum(real, imag, signal_spectrum);
// ----------------------------
// 3.3 计算一些统计特征(能量、谱总和)
// ----------------------------
// signal_energy:这里通过频域功率(real^2 + imag^2)求平均,作为整体能量特征
float signal_energy = 0.f;
for (size_t i = 0; i < kFftSizeBy2Plus1; ++i) {
signal_energy += real[i] * real[i] + imag[i] * imag[i];
}
signal_energy /= kFftSizeBy2Plus1;
// signal_spectral_sum:幅度谱的总和(一个粗粒度的谱强度特征)
float signal_spectral_sum = 0.f;
for (size_t i = 0; i < kFftSizeBy2Plus1; ++i) {
signal_spectral_sum += signal_spectrum[i];
}
// ----------------------------
// 3.4 噪声估计器:PreUpdate(更新前)
// ----------------------------
// PreUpdate 常用于:
// - 根据当前观测谱做预测/预处理
// - 更新一些内部平滑统计量
// - 为后续 SNR 计算提供“当前噪声谱候选”
ch_p->noise_estimator.PreUpdate(num_analyzed_frames_, signal_spectrum,
signal_spectral_sum);
// ----------------------------
// 3.5 计算 SNR(先验/后验)
// ----------------------------
// post_snr:后验 SNR,通常基于当前观测谱与噪声谱直接计算(当前帧的即时SNR)
// prior_snr:先验 SNR,通常用“决策导向(decision-directed)”方法平滑:
// prior_snr ≈ α * (上一帧增益^2 * 上一帧SNR) + (1-α) * max(post_snr-1, 0)
// 这样做的好处:
// - prior_snr 更平滑,避免增益抖动导致“音乐噪声(musical noise)”
// - 对语音概率估计也更稳定
std::array<float, kFftSizeBy2Plus1> post_snr;
std::array<float, kFftSizeBy2Plus1> prior_snr;
ComputeSnr(
// 上一帧/当前的 Wiener filter(或增益曲线),用于 decision-directed 的 prior SNR 估计
ch_p->wiener_filter.get_filter(),
// 上一帧分析阶段存下来的幅度谱(历史观测)
ch_p->prev_analysis_signal_spectrum,
// 当前帧幅度谱(当前观测)
signal_spectrum,
// 上一帧噪声谱估计
ch_p->noise_estimator.get_prev_noise_spectrum(),
// 当前帧噪声谱估计
ch_p->noise_estimator.get_noise_spectrum(),
// 输出:先验/后验 SNR
prior_snr, post_snr);
// ----------------------------
// 3.6 语音概率估计器更新(SpeechProbabilityEstimator)
// ----------------------------
// 目的:估计“这一帧/这一频点像语音的概率”
// - 语音概率高:后续会减少噪声估计更新(避免把语音统计进噪声)
// - 语音概率高:后续 Process 里也通常会更保真(增益更接近 1)
//
// conservative_noise_spectrum:更保守的噪声谱(常用于防止低估噪声)
// 低估噪声会导致 SNR 假性偏高,从而抑制不足/判语音不准。
ch_p->speech_probability_estimator.Update(
num_analyzed_frames_, prior_snr, post_snr,
ch_p->noise_estimator.get_conservative_noise_spectrum(),
signal_spectrum, signal_spectral_sum, signal_energy);
// ----------------------------
// 3.7 噪声估计器:PostUpdate(更新后)
// ----------------------------
// 根据语音概率来决定噪声谱如何更新:
// - 语音概率低:快速更新噪声谱(环境噪声变化能跟上)
// - 语音概率高:慢更新或冻结(避免把语音当噪声学进去)
ch_p->noise_estimator.PostUpdate(
ch_p->speech_probability_estimator.get_probability(), signal_spectrum);
// ----------------------------
// 3.8 保存当前幅度谱(供下一帧 Analyze 或 Process 使用)
// ----------------------------
// 注释说:让 Process() 可用。
// 常见用法:
// - Process 阶段可能用这个“最近分析谱”来做平滑、估计 prior SNR、或者辅助决策。
std::copy(signal_spectrum.begin(), signal_spectrum.end(),
ch_p->prev_analysis_signal_spectrum.begin());
}
}
关键组件与概念解析
在 Analyze 方法中,channels_[ch]->noise_estimator.PrepareAnalysis(); 调用了一个重要的噪声估计器方法。这个 NoiseEstimator 是 ChannelState 的成员之一。
PrepareAnalysis() 的具体实现非常简单,但意义重大:
void NoiseEstimator::PrepareAnalysis() {
std::copy(noise_spectrum_.begin(), noise_spectrum_.end(),
prev_noise_spectrum_.begin());
}
它的作用是在每一帧分析开始前,将上一帧最终估计出的噪声谱 (noise_spectrum_) 备份到 prev_noise_spectrum_ 中。这个历史噪声谱是计算信噪比 (SNR) 和语音概率的关键输入,保证了降噪算法状态更新的连续性和平滑性。
理解“全零帧(Zero Frame)”跳过机制
“全零帧”指的是当前输入音频帧的所有采样点值都为零(或能量极低)。这通常发生在麦克风被静音、通道断开或上游模块无输出时。Analyze 方法为什么要检测并跳过这种帧?
如果继续用全零信号更新内部的统计量(如噪声谱估计、能量阈值),会导致这些统计值被错误地拉向零。当真实的带噪音频再次出现时,算法会因为历史统计值过低而严重误判:可能将所有的信号(包括噪声)都识别为“语音”,从而不敢进行有效的噪声抑制,导致降噪功能暂时失效,并且需要很长时间才能重新学习到正确的噪声特性。
理解“扩展帧(Extended Frame)”与Overlap机制
噪声抑制通常以固定的短时帧(如10ms)为单位进行处理,但为了获得更好的频域分辨率,快速傅里叶变换(FFT)需要一个更长的分析窗口(例如256个采样点)。为了解决这个矛盾,采用了重叠拼接(Overlap)的技术。
扩展帧的构建公式可以简化为:
extended_frame = [上一帧尾巴 (analyze_analysis_memory)] + [当前帧 (10ms)]
analyze_analysis_memory 这个数组就是用来保存“上一帧尾巴”的,它在每一帧处理完后更新,实现了帧与帧之间的状态延续,这是 网络/系统 中流式音频处理算法的常见模式。
Analyze 整体流程总结
我们可以通过下面的流程图来直观地把握 NoiseSuppressor::Analyze 方法的完整执行逻辑:
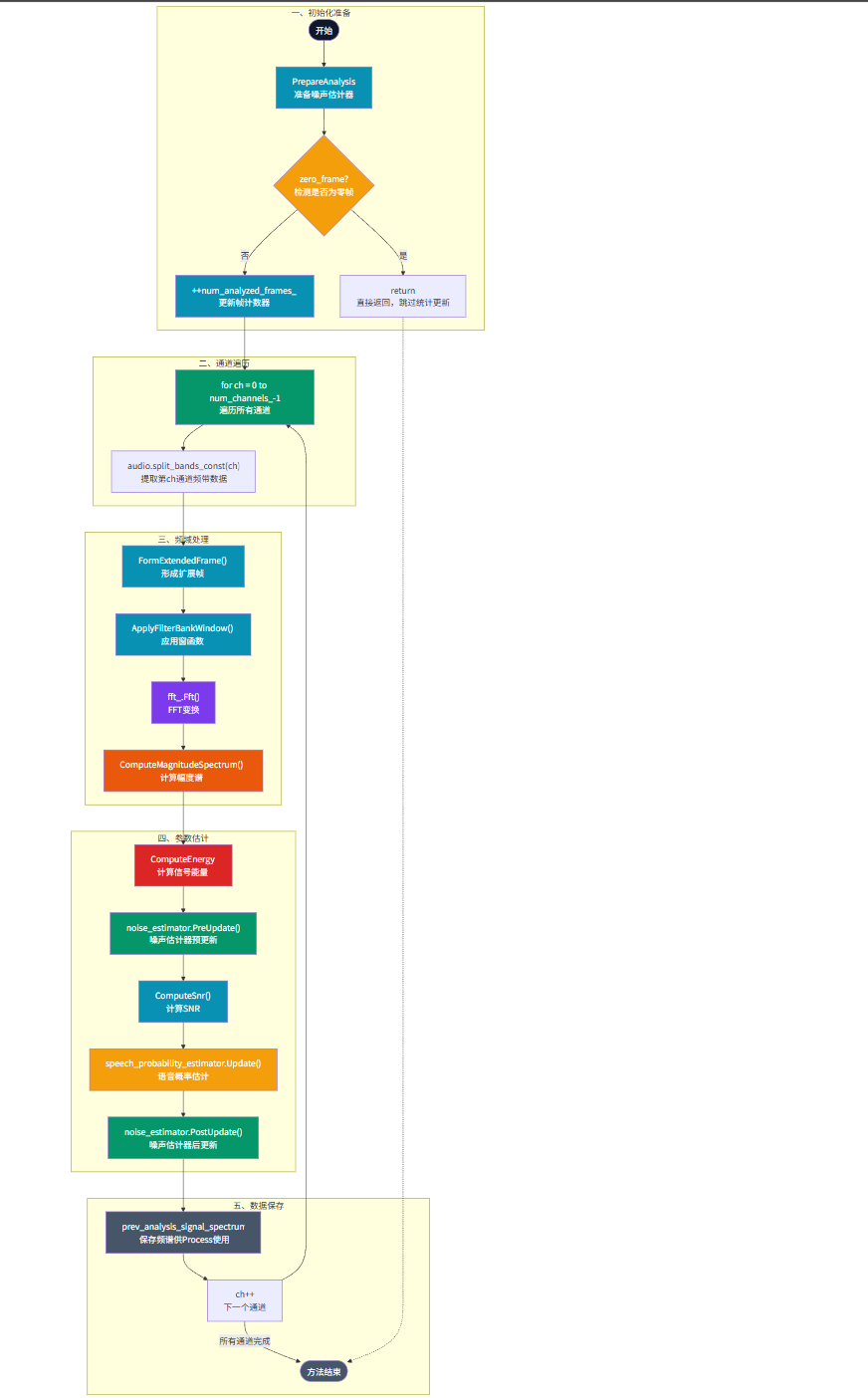
整个流程从准备分析开始,首先检测是否为无效的全零帧,若是则跳过更新。对于有效帧,则遍历每个通道,进行数据扩展、加窗、FFT变换至频域,进而计算能量、更新噪声估计、计算信噪比、估计语音概率,并最终保存当前频谱供下一帧使用。这个流程清晰地展示了WebRTC如何在不修改原始音频的情况下,为后续的降噪处理积累必要的环境感知信息。
总结与预告
本文详细解析了 WebRTC 中 NoiseSuppressor 类的整体结构、构造函数设计以及核心的 Analyze 方法。我们看到了它如何通过精细的状态管理、内存优化和信号处理流程,为实时降噪做好准备。其中对全零帧的处理、重叠帧的构建、以及噪声与语音概率的联合估计,都是保证算法鲁棒性和有效性的关键设计。
Analyze 方法主要完成了“感知”阶段的工作,而实际的“消除”动作则在 Process 方法中完成。此外,文中提及的 NoiseEstimator、SpeechProbabilityEstimator、WienerFilter 等子模块的内部机制还有更多细节值得探讨。这些内容,我们将在下一篇 开源实战 分析文章中继续深入。
 发表于 2026-1-19 07:12:44
|
查看: 179|
回复: 0
发表于 2026-1-19 07:12:44
|
查看: 179|
回复: 0
