随着2025年被广泛视为“Agent元年”,应用侧产品快速迭代的同时,业界也在重新审视大模型核心能力的来源。单靠预训练堆叠数据和算力已难以拉开代差,后训练(Post-training)阶段的强化学习(RL)正成为新的竞争焦点。如何让模型不仅能生成文本,更能在复杂任务中学会思考、决策与自我纠错?RL提供了一条可规模化的路径。然而,大模型的RL训练早已超越简单的脚本运行,演变为一项融合了推理系统与训练系统的复杂系统工程。
从 RLHF 到 RLVR
我们可以将大模型的训练过程类比为:预训练是“把百科全书背进脑子”,监督微调(SFT)是“统一答题格式”,而强化学习则像“刷题加复盘”。模型通过反复试错和优化奖励信号,从而学会将推理步骤固化为可迁移的技能。因此,理解奖励信号的来源与性质,是构建RL系统的第一步。
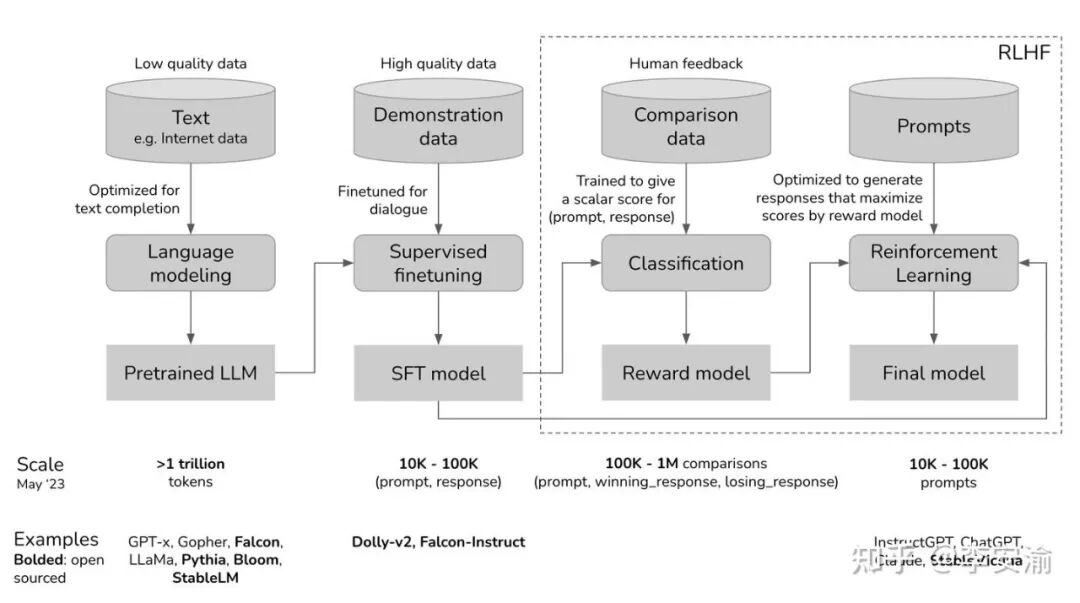
上图清晰地展示了大语言模型训练的经典三阶段流程。第一阶段是海量数据的预训练,第二阶段是基于高质量示范的监督微调(SFT),而第三阶段则是基于人类反馈的强化学习(RLHF)。目前,业界主流的后训练流程可以概括为三件套:SFT、RLHF和RLVR。
监督微调(Supervised Fine-Tuning, SFT)
顾名思义,SFT需要带“标签”的数据,通常是指令跟随数据或示范数据,格式为[指令(Prompt), 示范答案(Response)]。

SFT的目的是将预训练阶段“仅会文本接龙”的模型,通过高质量示范调整为一个“会按指令办事”的模型。其优化目标是最大化示范答案在模型下的出现概率。完成SFT后得到的模型,不仅为后续强化学习提供了一个良好的策略起点(Actor初始化),也常作为冻结的参考策略,用于RL阶段的KL约束,防止策略更新偏离太远。
基于人类反馈的强化学习(RLHF)
既然有了SFT,为什么还需要RLHF?这是因为SFT提供的是单一的“示范答案”,但对于许多开放式任务(如写作、创意生成),可能存在多个同样合理的回答。SFT可能只拟合了数据中的某一种模式,灵活性不足。
RLHF的核心思想是:先用人类偏好数据训练一个“打分器”(奖励模型,Reward Model),再通过强化学习让模型去最大化这个分数,同时用KL散度约束将策略“拽住”,防止其过度优化奖励而丧失通用性(即reward hacking)。这让模型能够探索多种回答,并通过更细粒度的偏好信号进行学习。
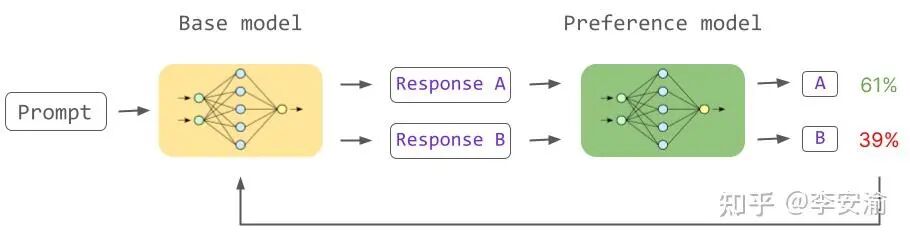
标准的RLHF流程分为两步:
- 训练奖励模型(RM):输入是
(prompt, response),输出是一个标量分数。通常使用(prompt, 更优答案, 次优答案)这样的三元组数据进行训练。
- 更新策略模型(Actor):使用强化学习算法(如PPO)更新策略,目标是让模型生成能获得更高RM分数的回答。

具有可验证奖励的强化学习(RLVR)
RLVR可以理解为在后训练流程中引入了“硬信号”。在数学、代码生成等可验证的环境中,模型生成的回答可以通过规则、标准答案、单元测试等方式自动判定对错,从而获得更客观、稳定的奖励r(x,y)。
相比依赖人类主观偏好训练的RM,RLVR的奖励信号更容易规模化获取,这使得我们可以将大量算力投入更长时间的在线强化学习和更大规模的轨迹采样(rollout)中。模型在持续的试错中,更可能自发形成可靠的推理策略(如拆解步骤、进行中间验证),从而涌现出思维链(CoT)能力。
从优化形式上看,RLVR与RLHF类似,都是最大化奖励并用KL正则约束策略,只是奖励来源不同。
RL 核心算法:PPO 与 GRPO
在RLHF流程中,我们提到了需要更新策略模型π_θ(y|x)。具体如何利用采样样本进行稳定、可重复、多轮迭代的策略更新,就涉及到了强化学习算法。
PPO(近端策略优化)
PPO是一种基于策略梯度的具体优化算法。其核心思想是:使用旧策略π_θ_old采样一批数据,然后用这批数据对新策略π_θ进行多轮小批量更新,但每一步更新都通过技术手段限制新策略与旧策略之间的差异,防止更新过快导致训练不稳定。
PPO采用Actor-Critic架构,需要同时训练策略网络(Actor)和价值网络(Critic)。Critic用于估计状态价值,作为Baseline来计算优势函数(Advantage),从而降低策略梯度估计的方差。
它通过重要性采样比值(Importance Sampling Ratio)来衡量新旧策略的差异:
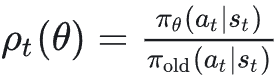
PPO通过裁剪(Clip)这一操作来限制每次参数更新的幅度,其损失函数如下:
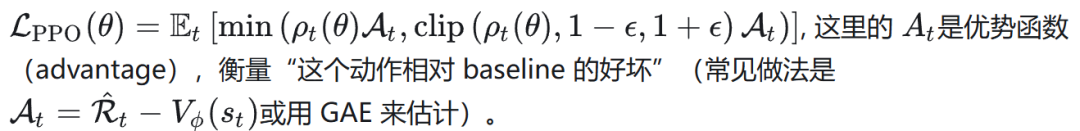
GRPO(组相对策略优化)
在InstructGPT时代,RLHF的标准配置是SFT + RM + PPO。然而,在推理或RLVR这类序列级奖励(整个回答对或错)更常见的设定中,训练一个能在每个token上都稳定工作的价值函数(Critic)既昂贵又困难。
因此,像DeepSeek-Math等工作提出了GRPO作为PPO的变体。它保留了PPO的近端更新思想,但用“组内相对优势”替代了Critic来估计优势函数,从而显著降低了训练侧的负担。
GRPO的做法非常直接:对同一个prompt,使用当前策略采样生成一组(例如4个或8个)答案,并计算每个答案获得的奖励(例如在数学题中是否正确)。

然后,将每个样本的优势(Advantage)设为组内归一化的相对收益:
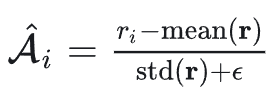
接下来,策略更新仍然使用PPO风格的裁剪目标函数,只是其中的优势函数不再来源于Critic的估计,而是来源于组内答案的相对比较。这正是GRPO能降低负担的根本原因:它省去了训练和同步Critic的巨大成本,将压力更多地转移到了需要更高并发采样的Rollout阶段。
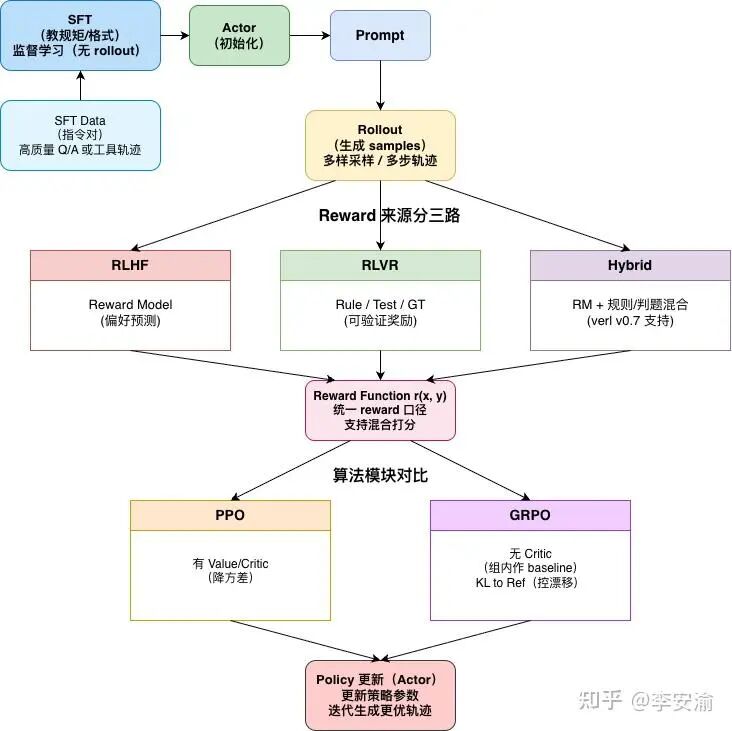
结合以上内容,一个典型的大模型后训练数据流如下图所示,清晰地展示了从SFT初始化,到Rollout采样,再到通过不同奖励源(RLHF/RLVR/混合)进行策略更新的完整闭环。如果你对强化学习的底层原理和应用想进行更系统的学习,可以关注云栈社区的人工智能板块,那里有更多深入的讨论和资源。
Infra 的核心挑战:精神分裂的“混合负载”
如果说预训练是一台稳定运转的“重型压路机”,那么RL训练则更像一条需要随时变速的复杂生产线。同一个模型在单个训练循环中需要反复切换角色,承担两种截然不同的工作负载:
- Rollout阶段(推理负载):模型扮演“考生”,目标是尽可能高并发地生成文本轨迹。这需要榨干推理吞吐量,涉及KV缓存、动态批处理、张量并行等技术,通常使用vLLM、SGLang等推理优化引擎。此时显存中的关键是KV Cache。
- Train阶段(训练负载):模型扮演“学生”,根据生成的轨迹和奖励进行反向传播,更新参数。这涉及梯度、优化器状态、激活值等,通常使用FSDP、ZeRO-3等训练并行策略。此时显存中的关键是参数、梯度和优化器状态。
这两种负载对系统资源的诉求是冲突的:训练需要重通信和参数切片,推理需要保留完整的KV缓存和追求高吞吐。这就导致了混合负载(Hybrid Workload)的难题。每次在训练和推理状态间切换,都可能面临显存布局重整、参数广播等高昂开销。此外,Rollout阶段因生成长度不一而产生的长尾效应,会导致同步训练中GPU空转等待,极大拖慢整体效率。
因此,RL基础设施的本质不是单纯优化训练或推理,而是将两个系统高效、无缝地拼接成一条“不漏水的流水线”。
verl:把“推理系统+训练系统”粘成一条流水线
字节跳动开源的verl框架正是为了解决这一核心挑战而设计的。它没有强行将训练和推理揉成同一种形态,而是承认二者的差异,并专注于在两者之间搭建高效的“桥梁”。
verl的价值在于,它设计了一套组件化的系统,在两套异构系统之间打通数据流和参数流,并将长尾Rollout的吞吐问题纳入整体设计。
从架构上看,verl分为两层:底层是verl-core(四大核心组件),上层是verl-trainer(用这些组件拼装出同步、异步等不同的训练流水线)。
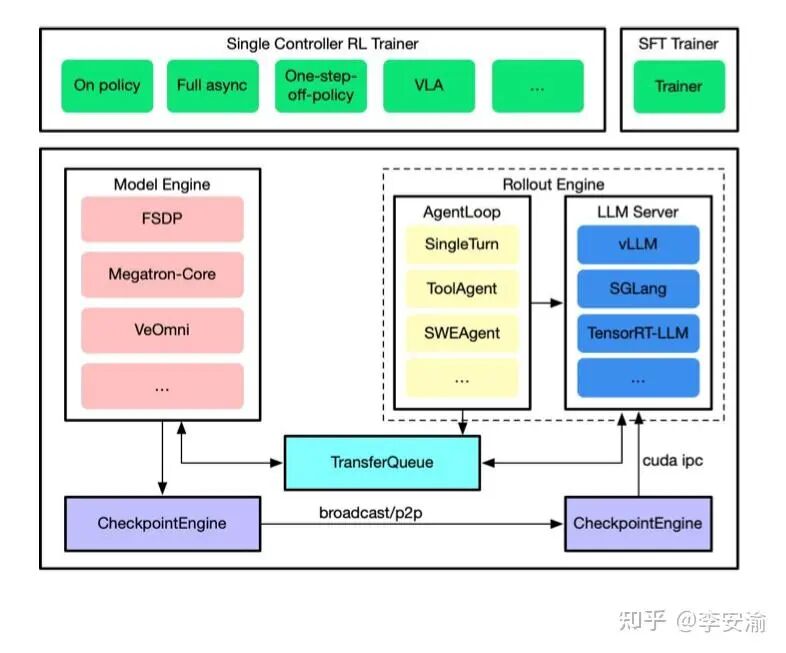
verl-core的四大组件构成了其基石:
- 模型引擎(Model Engine):封装训练后端(如FSDP),向上提供统一接口,让上层只需关注RL逻辑。
- 滚存引擎(Rollout Engine):将推理侧构建为类服务化形态,集成动态批处理、KV管理,并通过
AgentLoop抽象支持多轮对话、工具调用等复杂轨迹生成。
- 传输队列(TransferQueue):作为数据流的“物流枢纽”,负责将Rollout产生的大量轨迹、对数概率、奖励等数据高效、稳定地传输给训练侧,并起到削峰填谷的作用。
- 检查点引擎(Checkpoint Engine):管理参数流。在训练与Rollout资源分离后,它负责将训练侧快速更新的策略参数,以可控的频率同步给Rollout侧,避免策略陈旧,同时减少频繁存盘读盘的开销。
基于这四大组件,verl-trainer可以实现多种运行范式:
- 同步On-policy:简单直观,但易受长尾Rollout拖累。
- One-step-off-policy:允许使用一步陈旧的策略进行Rollout,以换取更高的吞吐。
- 全异步(Fully Async):将Rollout与训练彻底解耦,两者异步并行,通过TransferQueue和CheckpointEngine持续交换数据和参数,最大化系统利用率。
性能优化:对抗“长尾效应”的黑科技
随着GRPO、RLVR等需要大量采样(Group Sampling)的算法普及,Rollout阶段正成为端到端迭代的瓶颈。长思维链训练更是放大了长尾轨迹问题,导致GPU因等待最慢的样本而产生大量空转。
近期研究指出,相邻训练轮次中模型对同一提示词生成的响应存在高度相似性(可复用token比例高达75%-95%)。利用这一特性,出现了两类系统级优化方案:
投机式Rollout(Speculative Rollouts)
其思想是复用历史轨迹,减少重复生成。SPEC-RL将推理加速中的“推测解码”思想引入RL的Rollout阶段:它以上一轮旧策略生成的轨迹作为“草稿”,由当前新策略并行地进行验证;一旦遇到第一个不一致的token,就保留已验证的前缀,并从该位置开始续写。这样可以避免大量重复计算,显著提升Rollout速度。
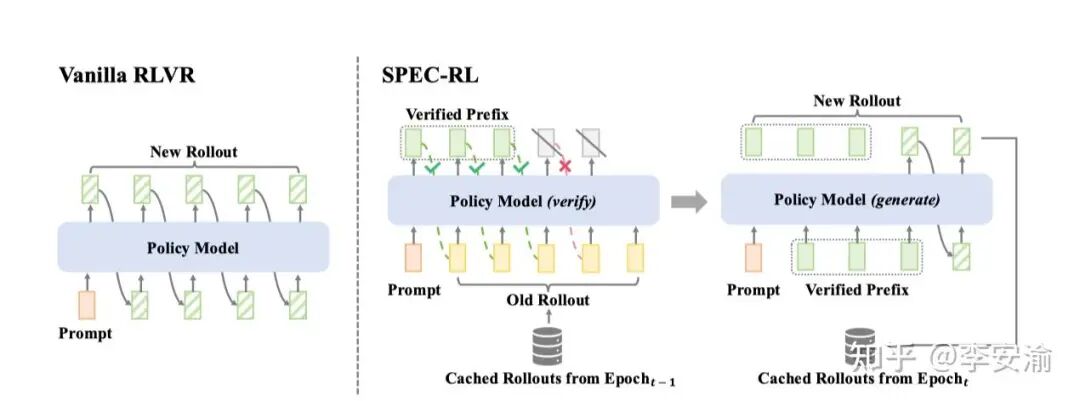
SPEC-RL作为纯Rollout阶段的增强技术,可以无缝集成到PPO、GRPO等算法中。报告显示其能降低2-3倍的Rollout时间,且不牺牲策略质量。值得注意的是,SPEC-RL正是在verl框架基础上进行开发的,这体现了先进算法与强大基础设施协同演进的趋势。
切分与调度(Divided Rollout)
另一类思路是将长尾任务拆分开,通过长度感知的调度策略,将负载抹平,减少等待气泡。这需要底层调度系统具备更精细的任务管理和资源分配能力。
通过对大模型RL Infra从算法(GRPO)到系统(verl)再到优化技术(SPEC-RL)的层层拆解,我们可以看到,构建高效的后训练平台已成为释放大模型复杂推理能力的关键。这场竞赛不仅是算法的竞争,更是系统工程能力的终极对决。
 发表于 2026-1-19 10:38:06
|
查看: 251|
回复: 0
发表于 2026-1-19 10:38:06
|
查看: 251|
回复: 0
