随着大模型技术的不断发展,强化学习(RL)逐渐成为了优化和调整模型性能的重要手段。在深入了解大模型工程机制后,我开始专注于如何运用强化学习的算法,特别是在后训练阶段对模型进行调参和优化。为此,我开设了这一专题,旨在探讨一些主流的强化学习算法及其在大模型中的应用,包括PPO(Proximal Policy Optimization)、DPO(Direct Policy Optimization)、GRPO(Generalized Robust Policy Optimization),以及它们在实际场景中的调参技巧和实践经验。
强化学习算法介绍
笔者始终认为,目前RL还没有得到充分的规模化应用,未来将会出现大量的RL工程实例涌现。
强化学习的核心优势之一,在于它不依赖于大量完美标注的数据,这为它提供了独特的灵活性和适应性。在许多任务中,尤其是在一些长尾任务或复杂环境中,传统的有监督学习方法(如SFT)往往需要成千上万的标注数据对进行训练。而强化学习通过定义合理的评估标准,能够在相对较少的数据基础上,依靠试错机制不断优化,最终实现有效的性能提升。
强化学习主要分为三大类方法:
基于价值
计算每个动作在当前环境下的价值,目标就是选择的行为能获得未来最大的动作价值。
以 DQN(Deep Q-Network)为代表的基于价值的方法,通过计算“当前状态有多有利”的价值,并选择能达到最高价值的行为。以象棋为例,就如同观察棋盘后判断当前局面“吃象”能获得最大的价值评估值,然后走出能最大化这个评估值的棋步。
基于策略
计算当前环境下选择每个动作的概率,目标是获取未来最大价值。
模型直接学习一个策略函数,通常通过神经网络来输出在每个状态下采取每个动作的概率分布,而不是通过Q值来选择动作。
集成价值策略
融合了上述两种方法的AC算法,价值函数和策略函数一起进行优化。价值函数负责在环境学习并提升自己的价值判断能力,而策略函数则接受价值函数的评价,尽量采取在价值函数那可以得到高分的策略。

我们可以直观的感受到AC算法集成了两种算法的优点,Critic提供对当前策略的评估奖励信号,帮助Actor改进策略,从而实现了更稳定、有效的学习过程,但仍存在一个根本性问题:一旦存在错误的更新,会导致强化学习过程断崖式坠落。
这也为近年来大火的强化学习算法提供了创新动力。
PPO
PPO 是目前广泛使用的强化学习方法。据称,OpenAI 的 GPT-3.5/4 在强化学习阶段(RLHF)也主要使用了 PPO。
PPO 的强大之处在于其学习更新公式(目标函数)中集成的 “裁剪功能”。

类似TRPO的KL散度,只不过在工程实现上,PPO简化了许多。
DPO
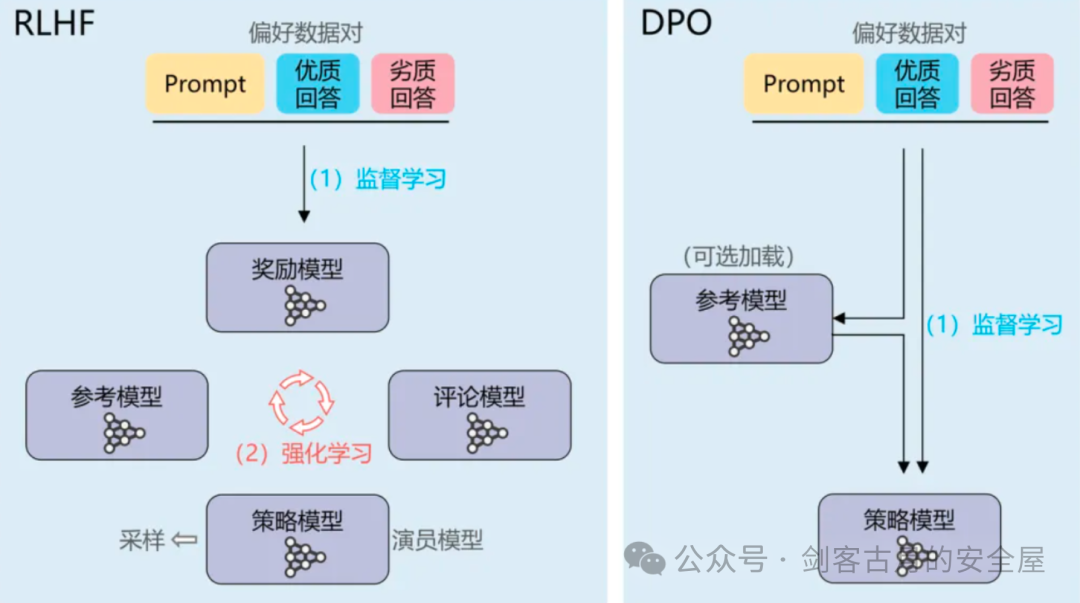
在强化学习中,PPO(Proximal Policy Optimization)被广泛应用于多个复杂的任务中,但它也面临着一些实际问题,特别是在计算资源和训练稳定性方面。PPO通常需要同时加载多个模型,具体包括:
- 奖励模型:用于评估当前策略下的行为是否优越。
- Actor模型:负责根据状态选择动作,形成决策。
- Critic模型:评估动作的好坏,提供反馈给Actor,从而优化策略。
这种设计带来的挑战是,模型之间的相互依赖和计算复杂性使得训练过程变得异常复杂。尤其是,内存消耗较大,调整难度加大,并且错误的更新可能导致训练失败。这种“多模型协同”方案虽然在一些任务中有效,但在资源有限的情况下,确实增加了系统的复杂性。
DPO的创新:简化模型设计
与PPO的多模型架构不同,DPO(Direct Policy Optimization)提供了一种更简洁、直观的方法。DPO的核心创新在于抛弃了奖励模型和Critic,只依赖与SFT(Supervised Fine-Tuning)相似的简单计算方式,就能直接优化符合人类偏好的AI。这种方法大大简化了深度强化学习的架构,使得模型更加高效,计算需求大幅下降,同时也避免了PPO中常见的训练稳定性问题。
DPO的优势不仅仅在于简化了模型结构,还在于其优化过程可以直接使用人类选择的数据来进行更新。通过这种方式,DPO能够在没有显式奖励模型的情况下,从人类偏好数据中学习到合适的策略,直接提升AI的表现。
在DPO中,我们去掉了奖励模型和Critic,而是直接基于人类选择的数据来更新策略。其核心思想是直接从人类偏好数据中学习,并优化策略,使得AI行为更符合人类偏好。其优化目标公式可以表示为:

qwen2与2.5采用DPO方法进行后训练。
然而,DPO也有一定的局限性:
- 无法进行探索:DPO基于已知数据进行学习,对于未见过的情况或数据之外的创新解法的挖掘能力有限。
其本质上也是在有限的数据中寻找泛化性,不具有探索性。
GRPO
GRPO 为PPO 的变种,旨在提升数学推理能力,并优化 PPO 的内存使用。我们在讲DPO的时候谈到:PPO比DPO更具有创造探索性,但却面临着成本换能力的困境。
GRPO正是为解决成本问题而生。
GRPO通过去除Critic(Critic网络通常是一个专门的“教练”角色,用来评估行为),替代性地采用了自评估机制,即通过“比较自己生成的多个回答”来判断优劣,从而减轻了计算成本。


按照我的理解:一个是请了家教帮忙批改作业,一个是自己批改自己的作业。
Deepseek-R1便是用GRPO配合基于规则的奖励设计完成实现。
后续不少算法则在该基础上进行优化,比如DAPO(字节),引入了非对称裁剪机制+token粒度动态权重与损失+长度软惩罚。
环境搭建
conda create --name rl_lunarlander python=3.12
pip install numpy tensorflow gym Box2D -i https://mirrors.aliyun.com/pypi/simple/
pip install 'stable-baselines3[extra]' huggingface_sb3 matplotlib IPython -i https://mirrors.aliyun.com/pypi/simple/
官方地址:https://gymnasium.farama.org/environments/box2d/lunar_lander/ Lunar Lander是GYM库中的一个经典环境,它模拟了一个航天器在月球表面着陆的场景。在这个环境中,智能体的目标是控制航天器安全且准确地着陆在指定的着陆点上。
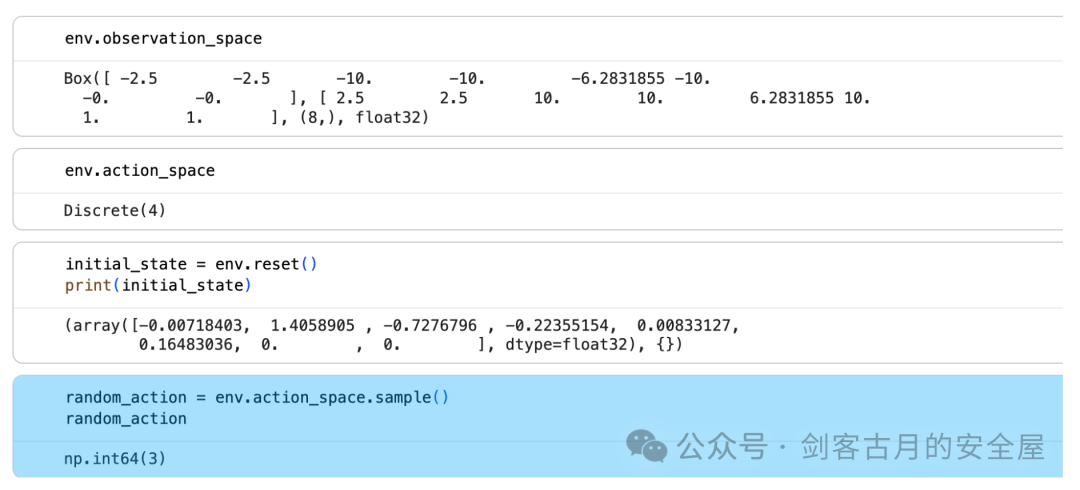
这里记录了观测值、初始状态、动作。
训练实战
这里以PPO为例,你可以手动搭建一个PPOAgent,也可以使用现成的库。
手动搭建Agent
Memory类:存储历史数据
class Memory:
def __init__(self):
self.actions = []
self.states = []
self.logprobs = []
self.rewards = []
self.is_terminals = []
def clear_memory(self):
del self.actions[:]
del self.states[:]
del self.logprobs[:]
del self.rewards[:]
del self.is_terminals[:]
该类用于存储强化学习过程中智能体的历史数据。包括:
actions:记录智能体在每个时间步选择的动作。states:记录智能体在每个时间步的状态。logprobs:记录每个动作的对数概率(log probability),用于后续的策略更新。rewards:记录每个时间步的奖励。is_terminals:记录每个时间步是否为终止状态。
clear_memory():清空存储的数据,用于每次更新后重置内存。
Actor-Critic 网络结构
class ActorCriticDiscrete(nn.Module):
def __init__(self, state_dim, action_dim, n_latent_var):
super(ActorCriticDiscrete, self).__init__()
# actor
self.action_layer = nn.Sequential(
nn.Linear(state_dim, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, action_dim),
nn.Softmax(dim=-1)
)
# critic
self.value_layer = nn.Sequential(
nn.Linear(state_dim, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 1)
)
ActorCriticDiscrete 类定义了一个 Actor-Critic 网络结构,用于处理离散动作空间的情况。
- Actor:根据当前状态预测动作的概率分布。使用
Softmax 函数输出每个动作的概率值。
- Critic:根据当前状态预测该状态的价值。输出的是一个标量值,表示该状态下的预期回报。
def act(self, state, memory):
state = torch.from_numpy(state).float()
action_probs = self.action_layer(state)
dist = Categorical(action_probs)
action = dist.sample()
memory.states.append(state)
memory.actions.append(action)
memory.logprobs.append(dist.log_prob(action))
return action.item()
根据当前状态选择一个动作,并存储到 memory 中。通过 Categorical 分布从动作的概率分布中采样动作。
def evaluate(self, state, action):
action_probs = self.action_layer(state)
dist = Categorical(action_probs)
action_logprobs = dist.log_prob(action)
dist_entropy = dist.entropy()
state_value = self.value_layer(state)
return action_logprobs, torch.squeeze(state_value), dist_entropy
评估给定状态和动作的价值。
action_logprobs:计算给定动作的对数概率,用于后续的策略优化。dist_entropy:计算动作分布的熵,表示策略的随机性(用于鼓励探索)。state_value:通过 Critic 网络输出当前状态的价值。
PPOAgent算法实现
初始化
class PPOAgent:
def __init__(self, state_dim, action_dim, n_latent_var, lr, betas, gamma, K_epochs, eps_clip):
self.lr = lr
self.betas = betas
self.gamma = gamma
self.eps_clip = eps_clip
self.K_epochs = K_epochs
self.timestep = 0
self.memory = Memory()
self.policy = ActorCriticDiscrete(state_dim, action_dim, n_latent_var)
self.optimizer = torch.optim.Adam(self.policy.parameters(), lr=lr, betas=betas)
self.policy_old = ActorCriticDiscrete(state_dim, action_dim, n_latent_var)
self.policy_old.load_state_dict(self.policy.state_dict())
self.MseLoss = nn.MSELoss()
PPOAgent 是 PPO 算法的核心部分,负责训练和更新策略。
self.policy:当前策略(包括 Actor 和 Critic)。self.policy_old:存储上一次策略,用于计算策略的变化。self.optimizer:使用 Adam 优化器来更新策略网络的参数。self.MseLoss:均方误差损失函数,用于计算价值函数的误差。
更新策略
def update(self):
rewards = []
discounted_reward = 0
for reward, is_terminal in zip(reversed(self.memory.rewards), reversed(self.memory.is_terminals)):
if is_terminal:
discounted_reward = 0
discounted_reward = reward + (self.gamma * discounted_reward)
rewards.insert(0, discounted_reward)
rewards = torch.tensor(rewards, dtype=torch.float32)
rewards = (rewards - rewards.mean()) / (rewards.std()+1e-5)
old_states = torch.stack(self.memory.states).detach()
old_actions = torch.stack(self.memory.actions).detach()
old_logprobs = torch.stack(self.memory.logprobs).detach()
for _ in range(self.K_epochs):
logprobs, state_values, dist_entropy = self.policy.evaluate(old_states, old_actions)
ratios = torch.exp(logprobs - old_logprobs.detach())
advantages = rewards - state_values.detach()
surr1 = ratios * advantages
surr2 = torch.clamp(ratios, 1-self.eps_clip, 1+self.eps_clip) * advantages
loss = -torch.min(surr1, surr2) + 0.5*self.MseLoss(state_values, rewards) - 0.01*dist_entropy
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
self.policy_old.load_state_dict(self.policy.state_dict())
PPO算法的关键更新步骤:
- 奖励折现:从后往前计算每个时间步的折现奖励。
- 优势计算:计算每个时间步的优势(即当前价值和折现奖励之间的差异)。
- 优化策略:使用重要性采样和剪切的目标函数来计算损失,并通过梯度下降更新策略。
执行和步进
def step(self, reward, done):
self.timestep += 1
self.memory.rewards.append(reward)
self.memory.is_terminals.append(done)
if self.timestep % update_timestep == 0:
self.update()
self.memory.clear_memory()
self.timstamp = 0
def act(self, state):
return self.policy_old.act(state, self.memory)
step:每次与环境交互后,存储奖励和终止标记,并在需要时进行策略更新。act:根据当前状态,使用旧策略(policy_old)选择一个动作。policy_old 是更新前的策略,用于计算策略的变化。
具体训练参数与循环
state_dim = 8 ### 游戏的状态是个8维向量
action_dim = 4 ### 游戏的输出有4个取值
n_latent_var = 256 # 神经元个数
update_timestep = 1200 # 每多少步更新策略
lr = 0.002 # learning rate
betas = (0.9, 0.999)
gamma = 0.99 # discount factor
K_epochs = 4 # update policy for K epochs
eps_clip = 0.2 # clip parameter for PPO 论文中表明0.2效果不错
random_seed = 1
agent = PPOAgent(state_dim , action_dim, n_latent_var, lr, betas, gamma, K_epochs, eps_clip)
EPISODE_PER_BATCH = 5 # update the agent every 5 episode
NUM_BATCH = 200 # totally update the agent for 400 time
avg_total_rewards, avg_final_rewards = [],[]
# prg_bar = tqdm(range(NUM_BATCH))
for i in range(NUM_BATCH):
log_probs, rewards = [],[]
total_rewards, final_rewards = [],[]
values = []
masks = []
entropy = 0
# collect trajectory
for episode in range(EPISODE_PER_BATCH):
### 重开一把游戏
state = env.reset()[0]
total_reward, total_step = 0, 0
seq_rewards = []
for i in range(1000):## 游戏未结束
action = agent.act(state)### 按照策略网络输出的概率随机采样一个动作
next_state, reward, done, _, _ = env.step(action)### 与环境state进行交互,输出reward 和 环境next_state
state = next_state
total_reward += reward
total_step += 1
rewards.append(reward)### 记录每一个动作的reward
agent.step(reward, done)
if done:## 游戏结束
final_rewards.append(reward)
total_rewards.append(total_reward)
break
print(f"rewards looks like ", np.shape(rewards))
if len(final_rewards)>0 and len(total_rewards)>0:
avg_total_reward = sum(total_rewards)/len(total_rewards)
avg_final_reward = sum(final_rewards)/len(final_rewards)
avg_total_rewards.append(avg_total_reward)
avg_final_rewards.append(avg_final_reward)
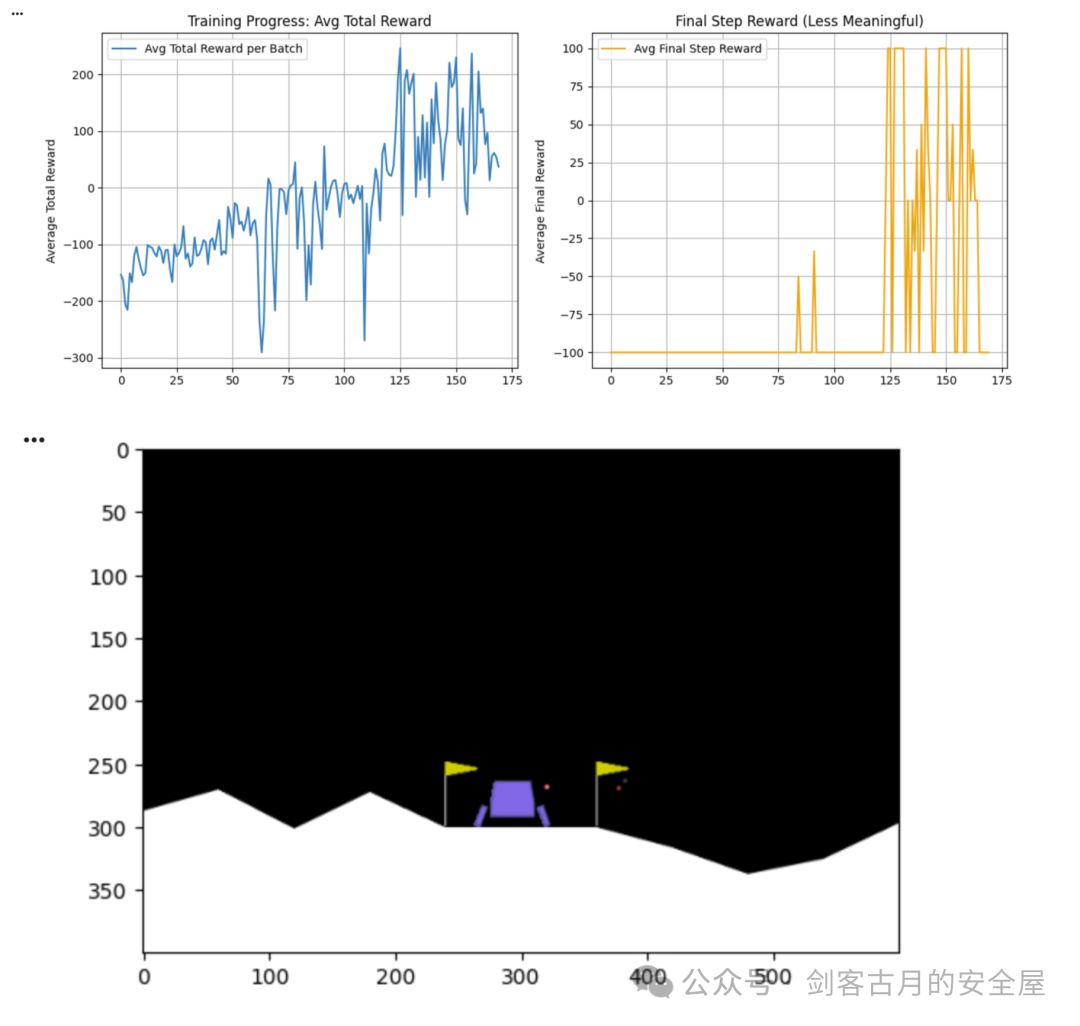
最后的rewards曲线图如下:
自定义奖励机制设计实战
在强化学习中,奖励机制对代理的学习效率和最终性能起着至关重要的作用。
这里用到了stable_baseline封装的PPO,但奖励函数为自己配置的奖励机制,并对比 默认奖励 和 自定义奖励 下代理的表现。
# 可配置奖励包装器
from dataclasses import dataclass
import numpy as np
import gymnasium as gym
@dataclass
class RewardConfig:
# 势能型稠密项(基于状态)
w_distance:float=0.0 # 距离着陆区的负权(越近越好)
w_velocity:float=0.0 # 速度幅值的负权(越慢越好)
w_angle:float=0.0 # 姿态角度的负权(越正越好)
w_legs:float=0.0 # 腿接触正项(每条腿 +1)
# 推进器代价(离散动作:0无操作,1左侧推,2主推,3右侧推)
penalty_main:float=0.0
penalty_side:float=0.0
# 是否替换原始 reward
replace_reward:bool=False
scale:float=1.0
class RewardShapingWrapper(gym.Wrapper):
"""
记录奖励分量到 info['reward_components']
可选地以自定义加权合成为新的 reward
"""
def __init__(self, env: gym.Env, config: RewardConfig):
super().__init__(env)
self.cfg = config
def _decompose(self, obs: np.ndarray, action)->dict:
x, y, vx, vy, angle, v_angle, l_leg, r_leg = obs[:8]
return {
"distance": -float(np.sqrt(x*x + y*y)),
"velocity": -float(np.sqrt(vx*vx + vy*vy)),
"angle": -float(abs(angle)),
"legs": float((l_leg > 0.5)+(r_leg > 0.5)),
"pen_main": float(action == 2),
"pen_side": float(action in [1,3]),
}
def step(self, action):
obs, reward, terminated, truncated, info = self.env.step(action)
comps = self._decompose(obs, action)
shaped = (
self.cfg.w_distance * comps["distance"]
+ self.cfg.w_velocity * comps["velocity"]
+ self.cfg.w_angle * comps["angle"]
+ self.cfg.w_legs * comps["legs"]
- self.cfg.penalty_main * comps["pen_main"]
- self.cfg.penalty_side * comps["pen_side"]
) * self.cfg.scale
info["reward_components"] = {**comps, "env_reward": reward, "shaped": shaped}
if self.cfg.replace_reward:
reward = shaped
return obs, reward, terminated, truncated, info
# 配置1:仅记录,不改变原始奖励
log_only = RewardConfig()
# 配置2:自定义奖励(鼓励稳、慢、省油)
custom_cfg = RewardConfig(
w_distance=200.0,
w_velocity=50.0,
w_angle=50.0,
w_legs=10.0,
penalty_main=0.3,
penalty_side=0.03,
replace_reward=True,
)
# 分别训练,对比 GIF 效果
import imageio.v2 as imageio
from stable_baselines3 import PPO
ENV_ID = "LunarLander-v2"
TOTAL_STEPS = 200_000
SEED = 42
def make_env(cfg, render_mode=None):
env = gym.make(ENV_ID, render_mode=render_mode)
return RewardShapingWrapper(env, cfg)
def train_and_save(cfg, model_path):
env = make_env(cfg)
model = PPO("MlpPolicy", env, verbose=0, seed=SEED)
rewards = [] # 用来记录每个episode的总奖励
obs, _ = env.reset(seed=SEED)
total_reward = 0 # 用来记录当前episode的总奖励
for _ in range(TOTAL_STEPS):
action, _ = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = env.step(action)
total_reward += info["reward_components"]["shaped"] # 累积当前episode的奖励
if terminated or truncated: # 当episode结束时
rewards.append(total_reward) # 将该episode的总奖励记录下来
total_reward = 0 # 重置总奖励以开始下一个episode
obs, _ = env.reset(seed=SEED) # 重置环境,开始新的episode
model.save(model_path)
env.close()
return rewards # 返回每个episode的总奖励
def record_gif(cfg, model_path, gif_path, max_steps=1000, fps=30):
env = make_env(cfg, render_mode="rgb_array")
model = PPO.load(model_path, env=env)
obs, _ = env.reset(seed=SEED)
frames = [env.render()]
for _ in range(max_steps):
action, _ = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = env.step(action)
frames.append(env.render())
if terminated or truncated:
break
env.close()
imageio.mimsave(gif_path, frames, fps=fps)
rewards_log_only = train_and_save(log_only, "ppo_default")
rewards_custom = train_and_save(custom_cfg, "ppo_custom")
# 对比奖励曲线
plt.figure(figsize=(12,6))
# 默认奖励
plt.subplot(1,2,1)
plt.plot(rewards_log_only, label="默认奖励")
plt.title("默认奖励机制")
plt.xlabel("时间步")
plt.ylabel("奖励")
plt.legend()
# 自定义奖励
plt.subplot(1,2,2)
plt.plot(rewards_custom, label="自定义奖励", color='orange')
plt.title("自定义奖励机制")
plt.xlabel("时间步")
plt.ylabel("奖励")
plt.legend()
# 调整图形布局
plt.tight_layout()
plt.show()
# 方案A:默认奖励(仅记录)
record_gif(log_only, "ppo_default", "ppo_default.gif")
# 方案B:自定义奖励
record_gif(custom_cfg, "ppo_custom", "ppo_custom.gif")
这里奖励权重最高的是鼓励距离着陆区越近越好,你可以尝试各种不同的奖励设计来探索模型行为的变化。
总结
通过这篇文章,我们深入探讨了PPO算法及其变种DPO、GRPO的原理,并结合奖励机制设计进行了实战。在强化学习中,合理的奖励设计能够帮助模型更好地学习任务目标,而通过自定义奖励机制,我们能够更精确地控制模型的行为。通过实际的对比实验,可以看到自定义奖励在强化学习训练中的优势。这些知识点在实际应用中非常重要,尤其是当涉及到复杂环境和高效的模型训练时。
后续我们还将通过大语言模型的后训练强化学习进行实战演练,欢迎在云栈社区继续交流探讨。
参考文章
https://mp.weixin.qq.com/s/DiKulIhOnMc_VSJO4UJRSw
 发表于 2026-1-20 02:18:49
|
查看: 229|
回复: 0
发表于 2026-1-20 02:18:49
|
查看: 229|
回复: 0
