
研究背景与问题定位
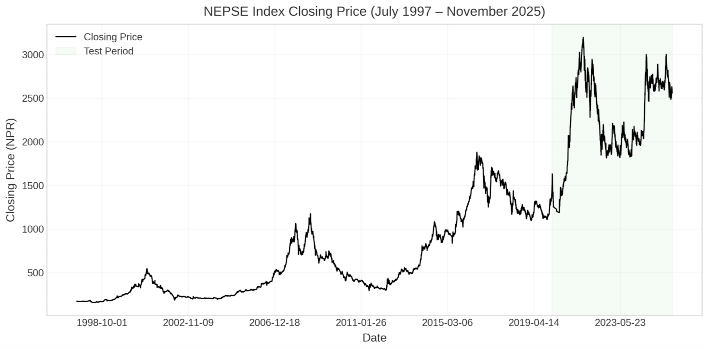
尼泊尔股票市场特征与预测挑战
尼泊尔股票交易所(NEPSE)指数是该国股市的首要基准,全面反映了这一新兴经济体的资本市场表现。具体而言,NEPSE市场呈现出明显的波动率聚集性与条件方差持续性,这意味着市场在经历剧烈波动后,往往会持续处于高波动状态,而非迅速回归平稳。
- 低市值与低流动性:市场整体规模有限,上市公司数量少且行业集中,导致交易频率低、买卖价差大,进一步放大了价格波动。
- 高波动性与非线性特征:日对数收益率的标准差高达 0.01274,其分布呈现尖峰厚尾特征,表明发生极端事件的概率远高于正态分布的预期。
- 对内外部冲击高度敏感:历史数据显示,重大事件(如2015年大地震)会引发市场剧烈震荡,且波动在事件后持续数月,形成显著的非对称响应。
这些特征共同导致传统线性模型的预测能力受限。例如,自回归积分滑动平均(ARIMA)模型虽能捕捉部分线性趋势,但其对非线性动态、条件异方差及突发事件的建模能力不足,难以适应NEPSE指数的复杂演化路径。
研究空白与核心目标
本研究旨在构建一个可复现、严格验证的XGBoost预测框架,以填补方法论与实证的双重空白。具体目标包括:
- 构建基于XGBoost的一步提前(one-step-ahead)连续对数收益率预测模型,充分利用其在处理非线性、高噪声数据方面的鲁棒性。
- 采用时间序列交叉验证策略,确保模型评估过程符合时间顺序,避免前瞻偏差,提升结果的可信度。
- 系统分析特征重要性,通过特征重要性图谱揭示影响NEPSE指数变动的关键驱动因素,增强模型可解释性。
- 提供可复现的代码与数据流程,推动研究透明化与方法标准化,为后续在类似新兴市场中的应用提供范本。
方法论框架设计
数据集与处理流程
本研究构建了一个面向新兴市场指数的可复现预测框架,聚焦于NEPSE指数的日对数收益率一步提前预测。数据来源为第三方平台 NepseAlpha,涵盖 1997年7月20日至2025年11月11日 的完整时间序列,共包含 6,393个观测值,覆盖了尼泊尔资本市场多年的波动周期,具有较高的代表性与历史跨度。
为确保建模的严谨性与可复现性,原始数据中仅保留 交易日期 与 收盘价 字段,剔除非交易日记录,并将日期字段统一转换为标准的 日期时间格式,以支持后续时间序列分析与模型训练的时序对齐。
目标变量定义为 日对数收益率,其计算公式如下:
r_t = log(P_t) - log(P_{t-1})
其中 P_t 表示第 t 日的收盘价。采用对数收益率的主要原因在于其具备优良的统计特性,包括近似正态分布性与时间可加性,这些特性显著提升了金融时间序列建模的稳定性与可解释性。
特征工程体系
为捕捉股价变动中的自相关性、动量效应及波动率动态,本研究实施了系统性的特征工程,构建了多类预测变量,确保所有特征均基于历史信息计算,严格避免未来信息泄露。
- 滞后对数收益率:构建 t-1 至 t-L 天的滞后项,用于捕捉短期至中期的自相关性与动量特征。该设计与日度股票收益的典型动态特征相符。
- 滚动波动率:
- 短期波动率(
vol_5):过去5个交易日对数收益率的滚动标准差,反映市场短期内的波动水平。
- 中期波动率(
vol_20):过去20个交易日对数收益率的滚动标准差,用于衡量中期市场波动趋势。
- 相对强弱指数(RSI 14周期):基于过去14日的涨跌幅度计算,采用指数加权移动平均 估计平均上涨收益与平均下跌损失。RSI值在0–100之间波动,通常用于识别市场情绪反转点。
- 10日对数收益率滚动均值(
mean_10):过去10个交易日对数收益率的移动平均,反映短期趋势方向与均值回归倾向。
所有特征在训练集上进行标准化处理,以消除量纲差异。特征生成过程严格保持时间顺序,仅使用当前及历史数据。对于因计算产生的缺失值,均已从数据集中移除。
模型构建与超参数优化
本研究采用 XGBoost 回归器 作为核心建模工具,其基于梯度提升决策树框架,通过迭代优化损失函数逐步构建强学习器。该模型引入 L1与L2正则化项,有效抑制过拟合,提升模型泛化能力,特别适用于高噪声、非线性特征的金融时间序列预测任务。
超参数优化采用 Optuna 框架,基于 树状帕尔策估计器 进行贝叶斯优化,以高效探索高维参数空间。优化过程仅在初始训练集(占总数据的80%)上执行。交叉验证采用 5折时间序列交叉验证,确保验证集始终位于训练集之后。
优化目标为最小化验证集上的 均方误差。搜索空间涵盖估计器数量、最大深度、学习率、子样本比例、正则化系数等多个关键参数。
为确保实验可复现性,所有实验均使用固定随机种子。在最优XGBoost模型中,关键参数包括较低的学习率、适中的树深度,以及较高的子采样比例,同时采用适度的L1与L2正则化。
样本外评估机制与验证策略
滚动验证设计
为真实反映模型在实际金融部署中的表现,本研究采用滚动验证机制。该方法通过模拟模型在时间序列上的迭代训练与预测过程,有效避免前瞻偏差。该策略被广泛推荐用于非平稳时间序列分析,尤其适用于金融数据的动态建模场景。
在具体实施中,本研究并行测试两种训练窗口策略:
- 扩展窗口:训练集从起始时间点开始,随预测步进逐步扩大,包含所有历史观测数据。该策略旨在利用不断积累的历史信息。
- 滚动窗口:训练集固定为800个观测值,随预测时间点向前滑动更新。该策略在保持训练样本量稳定的同时,增强模型对近期市场动态的适应性。
在每个时间步,模型均使用初始调优阶段获得的最优超参数重新拟合。该过程在多个滞后配置下重复执行,以检验模型在不同预测时间尺度下的泛化能力。
评估指标体系
为全面衡量模型性能,本研究构建了多层次的评估指标体系。
回归性能指标
核心回归性能指标包括:
- 均方根误差:反映预测值与真实值之间的平均平方误差,对异常值敏感。
- 平均绝对误差:表示预测误差的平均绝对大小,对异常值不敏感,提供更稳健的误差度量。
- 决定系数(R²):表示模型解释目标变量方差的比例。
方向准确性
方向准确性是金融预测中尤为关键的指标,定义为预测与实际对数收益率符号一致的比例。该指标在投资决策中具有直接意义,尤其适用于趋势跟踪策略的评估。
值得注意的是,方向准确性直接基于对数收益率计算,其结果与价格变动方向一致。在本研究中,XGBoost模型在扩展窗口与20阶滞后配置下,方向准确性达到65.15%,显著优于岭回归与ARIMA等传统模型。
价格重建评估
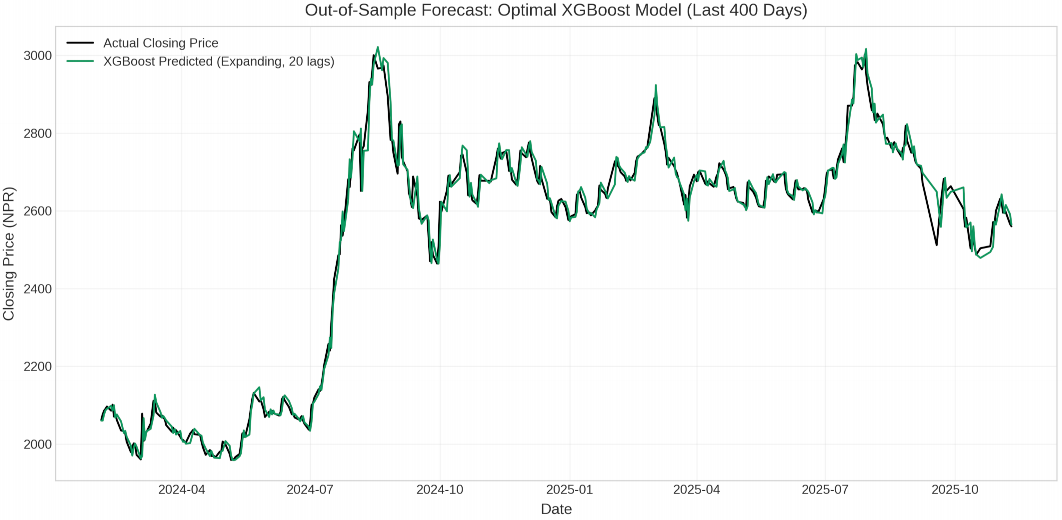
为增强结果的可解释性,本研究通过指数变换将对数收益率预测结果重构为实际收盘价序列,便于直观理解模型在价格路径上的表现。
然而,价格重建过程存在误差累积风险,即单步预测误差会随时间传播并放大。因此,尽管价格重建指标在可视化中具有价值,其重要性次于对数收益率预测,核心评估依据仍集中于对数收益率层面的性能。
| 模型 |
RMSE |
MAE |
R² |
方向准确性 (%) |
| XGBoost (Expanding, 20 lags) |
30.65 |
22.3 |
0.995 |
65.15 |
| CNN |
31.0022 |
21.9451 |
0.9123 |
60.13 |
| N-BEATS |
34.0797 |
24.0028 |
0.9907 |
58.77 |
| LSTM |
79.2095 |
63.8545 |
0.9498 |
52.45 |
| TFT |
156.3624 |
115.1321 |
0.8044 |
57.82 |
注:所有模型均在相同的滚动预测下评估。加粗数值突出了XGBoost模型的最优表现。
对比深度学习模型,XGBoost在RMSE、MAE与方向准确性方面均表现最优,尤其在方向预测准确率上显著领先。
实证结果与模型表现分析
最优模型配置与性能对比
经过系统性调优与严格验证,最优模型配置被确定为:扩展窗口策略结合20个滞后项。该配置在多个关键性能指标上全面超越基准模型。
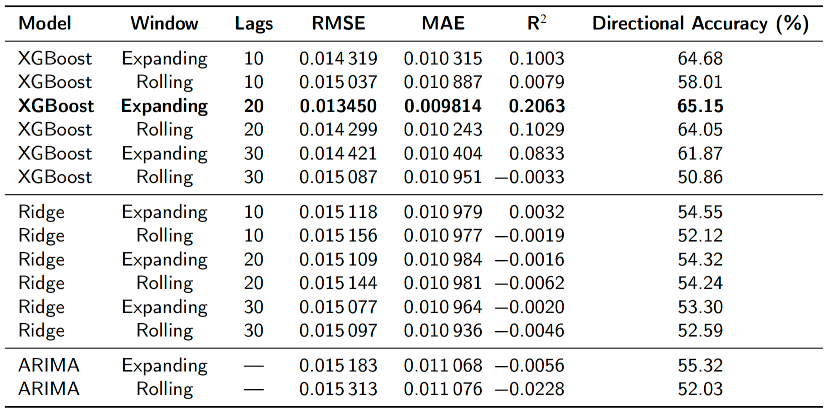
- 均方根误差:达到 0.013450,显著优于ARIMA与岭回归模型,相对改进幅度约为11%–12%。
- 平均绝对误差:为 0.009814,在相对基准模型中实现了约11%–12%的降低。
- 方向准确率:达到 65.15%,显著高于ARIMA与岭回归模型的52%–55%区间,远超随机猜测水平。
- 决定系数(R²):样本外R²的95%置信区间为 (0.152, 0.258),该区间不包含零值,表明模型解释的方差具有统计显著性。
统计显著性检验
为验证模型性能提升的非随机性与统计可靠性,本研究引入了三类经典检验方法:
- Diebold-Mariano检验:结果显示,XGBoost在两次对比中均具有统计显著优势(p < 0.01)。
- Pesaran-Timmermann检验:检验统计量为 4.82,在显著性水平 p < 0.01 下拒绝“无方向预测能力”的原假设。
- 二项检验:在1%显著性水平下,拒绝“方向准确率为50%”的零假设。
模型间横向比较
为全面评估XGBoost在复杂模型架构中的相对地位,本研究将最优XGBoost模型与四种主流深度学习模型进行横向比较。
| 模型 |
RMSE |
MAE |
R² |
方向准确率 (%) |
| XGBoost (Exp., 20) |
30.65 |
22.3 |
0.995 |
65.15 |
| CNN |
31.0022 |
21.9451 |
0.9123 |
60.13 |
| N-BEATS |
34.0797 |
24.0028 |
0.9907 |
58.77 |
| LSTM |
79.2095 |
63.8545 |
0.9498 |
52.45 |
| TFT |
156.3624 |
115.1321 |
0.8044 |
57.82 |
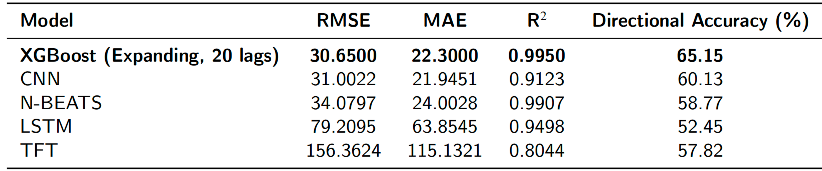
从结果可见,XGBoost在RMSE、MAE与方向准确性三项核心指标上全面领先。进一步的Diebold-Mariano检验显示,XGBoost显著优于表现最强的CNN模型。
窗口策略比较与滞后阶数影响
模型性能对训练窗口策略与滞后阶数高度敏感。
- 窗口策略比较:在扩展窗口与滚动窗口的对比中,扩展窗口策略表现更优。这表明引入更长的历史信息有助于模型识别潜在的长期动态与结构性模式。
- 滞后阶数影响:在多种滞后配置中,滞后阶数为20时性能达到最优。这一发现验证了日度收益率序列中存在短期至中期的时间依赖性。
模型可解释性与市场机制洞察
特征重要性分析
在最优XGBoost模型中,特征重要性按“增益”排序揭示了市场动态的关键驱动因素。
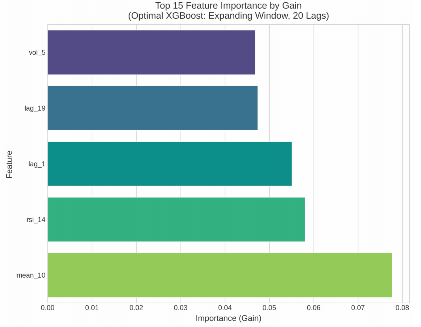
- 10日滚动均值(mean_10):贡献度最高,反映市场短期均值回归特征。
- 滞后阶数1(lag_1)与滞后阶数19(lag_19):体现短期动量与中周期延续性。
- 5日短期波动率(vol_5):显著贡献,印证波动率聚集性。
- 14周期RSI(rsi_14):辅助作用,但整体重要性较低。
10日滚动均值的高重要性表明市场在短期偏离均值后存在显著的修正倾向,即均值回归特征。滞后1项与滞后19项的显著贡献揭示了短期至中期动量效应的存在。5日短期波动率的重要性则有力印证了波动率聚集性这一金融典型事实。
市场机制的经济解释
模型输出的特征重要性结果,在经济层面上提供了清晰的机制洞察,与金融市场的典型事实高度一致。
- 短期动量效应:体现在滞后1项的高重要性上,表明价格在短期内具有延续趋势的能力。
- 均值回归特征:由10日滚动均值的高权重所支撑,反映出市场在过度偏离后存在自我修复倾向。
- 波动率聚集性:是模型对5日短期波动率赋予高重要性的直接体现,说明市场风险在特定时期内会集中爆发。
这一致性不仅验证了模型的有效性,也说明其预测能力建立在对真实市场机制的深刻捕捉之上。对Python和机器学习技术感兴趣的开发者,可以在云栈社区找到更多相关的实战案例与深入讨论。
项目地址
文章标题
XGBoost Forecasting of NEPSE Index Log Returns with Walk Forward Validation
GitHub
https://github.com/sahajrajmalla/nepse-xgboost-forecasting
 发表于 2026-1-20 02:52:44
|
查看: 345|
回复: 0
发表于 2026-1-20 02:52:44
|
查看: 345|
回复: 0
