本文详细总结了YOLOv8模型前向推理过程中,最终在其检测头部分所输出的数据结构,并阐述了从原始输出到获取最终检测框的完整后处理流程。
YOLOv8模型的推理输出
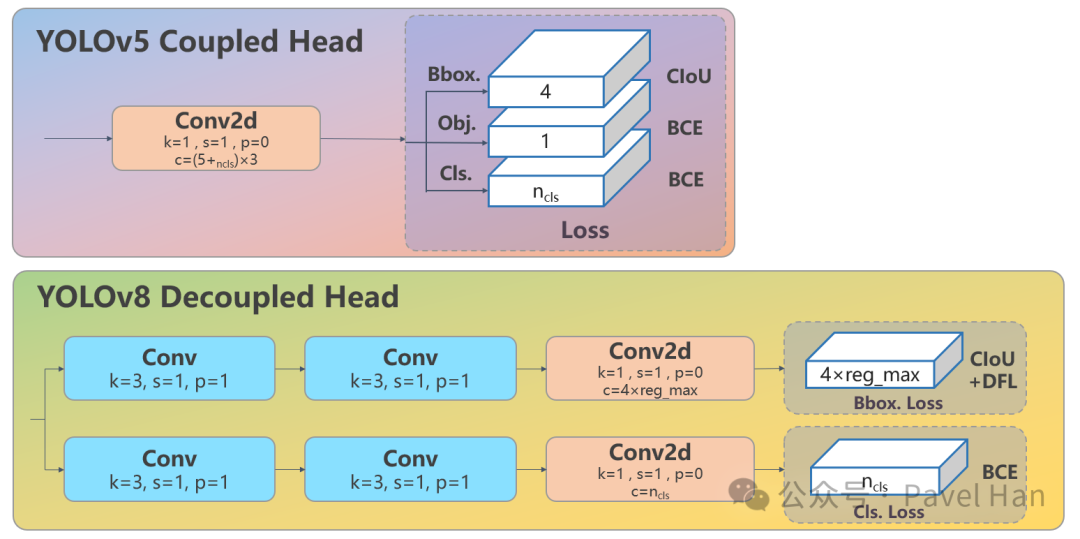
正如之前对网络架构的解读,YOLOv8在主干网络和颈部网络的设计上延续了YOLOv5的思路,但其检测头部分进行了革命性改进。它不仅摒弃了自YOLOv2以来使用的Anchor-based(基于锚框)方案,还引入了Decoupled Head(解耦头)和DFL(Distribution Focal Loss)。
下图清晰地展示了YOLOv5与YOLOv8检测头结构的核心区别:
经过以上改进,对一张输入图片进行推理时,YOLOv8的原始输出通常是一个形状为 (1, 8400, 4+NC) 的张量。其中:
1:代表batch size,即一张图片的推理输出。8400:预测框的总数量。这是三个特征尺度下输出特征图上所有像素点的总和:
80*80 = 6400 (针对小目标的P3特征图)40*40 = 1600 (针对中目标的P4特征图)20*20 = 400 (针对大目标的P5特征图)- 总计:
6400+1600+400=8400。
4+NC:每个预测框的输出维度。
4:预测框的坐标信息(经过解耦头处理的边界框信息)。NC:对应数据集所有类别的分类置信度分数。
与YOLOv5相比,YOLOv8在输出数据上主要有两点核心区别:
- 取消了Objectness分数:YOLOv8不再单独输出目标存在置信度。其分类分支输出的概率值已隐含了“是否存在物体”的信息。因此,YOLOv5的输出格式是
5+NC,而YOLOv8是4+NC。
- 预测框数量锐减:YOLOv5采用Anchor-based设计,每个特征图像素点会输出3个不同尺度的预测框,总数为
25200个。YOLOv8采用Anchor-free设计,每个像素点仅输出1个预测框,总数仅为8400个。
注意:尽管YOLOv8输出的预测框数量减少了(只有原来的三分之一),但其检测精度反而更高。这是因为Anchor-free设计避免了锚框与目标形状不匹配的问题,配合DFL机制,模型对边界的预测是连续、分布式的,而非简单地偏移一个固定框。
最终,检测头输出的形状为 (1, 8400, 4+NC) 的张量将被送入后处理环节,通过NMS(非极大值抑制)等步骤得到最终结果。
坐标回归分支的DFL计算
如上图所示,YOLOv8的坐标回归分支(Bbox Head)会为每个预测框的四个方向(左、上、右、下)分别输出一个长度为reg_max(通常为16)的向量,表示偏移量的概率分布。因此,对于特征图上的每个像素点,坐标回归分支的输出长度为 4 * reg_max。
下面我们通过一个具体例子,说明如何从坐标分支的输出计算得到最终的预测框坐标。
假设向模型输入一张 640x640 分辨率的图片,我们关注Stride=8的特征图(即80x80分辨率的P3层)。选取该特征图上坐标为 (5, 5) 的像素点。
模型在该点坐标回归分支的输出是一个长度为64的向量。其中,预测框中心点到其左、上、右、下边界的偏移量各由16个值表示。假设左边界 L 对应的16个值中,索引3和4的值最大。首先对这16个值进行Softmax计算,得到概率分布。设 Softmax([L0...L15]) 后,p3=0.4, p4=0.6,其余位置概率为0。接着,对索引与其概率进行加权求和,得到左边界在特征图尺度上的粗略偏移量:
L_approx = 3 * 0.4 + 4 * 0.6 = 3.6
此时,由于我们选取的是特征图上坐标为 (5, 5) 的像素格,因此该像素格的中心在特征图中的位置为 (5.5, 5.5)(注意中心点坐标为像素索引加0.5)。
接下来,计算左边界在当前特征图维度(80x80)上的位置:
L_feat = 5.5 - L_approx = 5.5 - 3.6 = 1.9
最后,将此坐标换算到原始输入分辨率上。因为当前特征图的stride=8,所以需要将上述坐标乘以8:
L_orig = L_feat * 8 = 1.9 * 8 = 15.2
按照相同的逻辑,可以计算出 T_orig、R_orig、B_orig。(L_orig, T_orig, R_orig, B_orig) 就是该像素点在原始输入图片上预测的边界框坐标(中心点偏移表示法)。
在上述计算中,由于加权求和得到的偏移量 L_approx 等值在0-15之间,最终计算出的坐标值在靠近图像边缘时可能出现负数或超出640的情况。这表示预测框部分超出了图像边界。在后处理中,通常会执行clip操作,将坐标限制在 [0, 640) 的合理范围内。
YOLOv8模型输出的后处理
YOLOv8模型为每张图片输出8400个预测框,后处理的目标就是从这些预测框中筛选出最终有效的检测框。整个后处理流程主要包括三个步骤:解码(Decoding)、阈值过滤(Thresholding)和非极大值抑制(NMS)。这个过程是许多计算机视觉应用中的关键环节。
Logits解码
YOLOv8检测头的直接输出是原始预测值(logits),并非最终的坐标和概率。
- 分类分支:输出的是各个类别的Logits,需要通过Sigmoid激活函数将其转换为
[0, 1] 之间的概率值。
- 坐标回归分支:输出的是距离中心点左、上、右、下四个方向的概率分布。按照上一节描述的DFL计算过程,可以得到预测框的坐标
(L, T, R, B)。
阈值过滤
这一步非常简单,但能过滤掉绝大部分无效预测框:
- 获取最大类别概率:对于每个预测框,在其
NC个类别分数中,找到数值最大的那个,作为该框的置信度分数。
- 设定置信度阈值:设置一个
conf_thres(例如0.25),该值通常在推理参数中指定。
- 初步过滤:保留所有置信度分数高于
conf_thres的预测框,丢弃所有低于该阈值的框。绝大多数背景框或低质量预测框会在此步骤被剔除,通常过滤率超过90%。
非极大值抑制(NMS)
经过阈值过滤后,剩余的框可能仍存在大量重叠,即多个框指向同一个物体。NMS算法用于消除这些冗余框。
在进行NMS之前,数据通常被整理为一个 (N, 6) 的矩阵,其中N是经过阈值过滤后剩余的框数量。每行包含:
- 预测框坐标(4列):
[x1, y1, x2, y2](左上右下格式)或 [L, T, R, B]。
- 置信度分数(1列):该框属于其对应类别的概率。
- 类别索引(1列):该框预测的类别ID。
NMS的标准执行流程如下:
- 排序:将候选框列表按照置信度分数从高到低进行降序排列。
- 选取最高分框:选取当前列表中分数最高的框
M,将其放入最终检测结果列表。
- 计算IoU:将框
M 与列表中剩余的所有框 B_i 逐一计算交并比(IoU)。
- 抑制冗余框:如果某个框
B_i 与 M 的IoU超过了预设的iou_thres(通常为0.45到0.7),则认为 B_i 是重复预测,将其从候选列表中删除。
- 循环:重复步骤2-4,直到候选框列表为空。
iou_thres 这个参数至关重要:
- 设置过高(如0.9),可能导致重复框未被抑制。
- 设置过低(如0.1),当两个真实物体距离很近时,可能会错误地抑制掉其中一个。
通过解码、过滤和NMS这一套完整的后处理流程,YOLOv8最终输出的是精简、准确的检测框列表,为后续应用提供可靠的目标信息。这种从大量候选框中高效筛选出有效结果的能力,正是现代高效模型训练与部署所追求的目标之一。
 发表于 2026-1-20 16:08:37
|
查看: 564|
回复: 0
发表于 2026-1-20 16:08:37
|
查看: 564|
回复: 0
