最近AI圈除了热议大模型的快速迭代,“算力瓶颈”也成了焦点话题。大家都知道GPU短缺、HBM供不应求,但可能没注意到,存储层正悄然酝酿着一场革新——高带宽闪存(HBF)。今天,我们就结合HBM之父Joungho Kim教授的最新观点,深入解析这项技术:它并非HBM的直接替代品,却可能重塑AI推理的游戏规则,甚至有望在2038年超越HBM的市场规模。
首先要明确一个核心认知:HBF并非凭空出现,而是站在HBM技术肩膀上的“优化版本”。理解其本质是关键——它用NAND闪存替换DRAM,同时借鉴了HBM成熟的3D堆叠架构,主打“高带宽”与“大容量”的平衡,专门为解决AI推理场景的存储痛点而生。

一、HBF vs HBM vs 传统SSD:关键参数对比
谈论技术离不开参数对比,我们将其与HBM4及主流NVMe SSD放在一起看,能更直观地建立认知。毕竟,仅说“1638GB/s带宽”有些抽象。
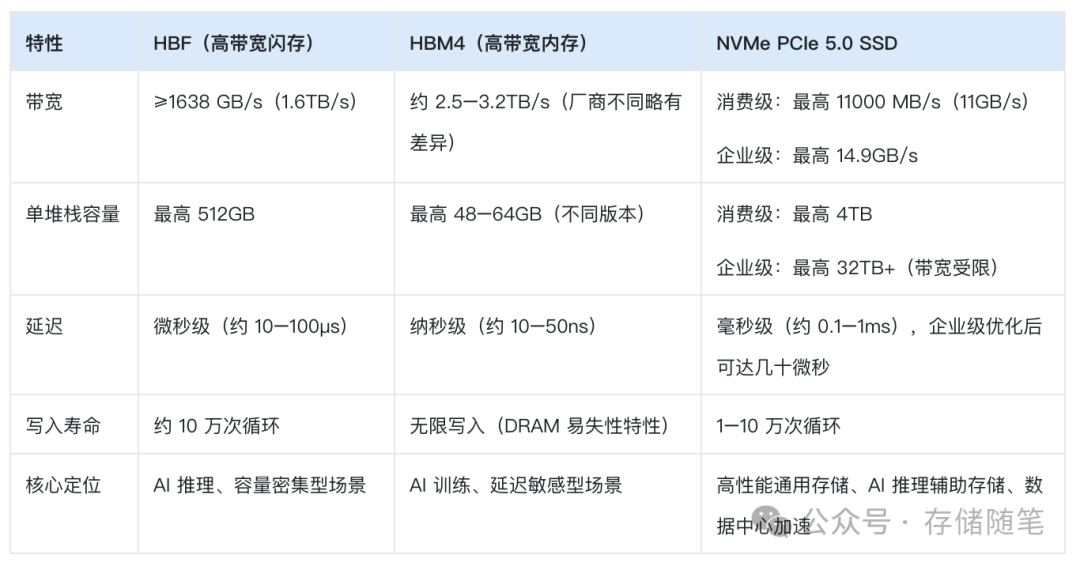
从对比中可以看出:HBM4延迟最低但成本高昂、单堆栈容量有限(约64GB);PCIe 5.0 SSD成本亲民,但带宽最高仅约11GB/s、延迟为毫秒级。而HBF则精准地兼顾了高速与大容量,非常适配AI推理需求——其带宽是PCIe 5.0 SSD的149倍以上,单堆栈容量是HBM4的8倍,成本据称仅为HBM的1/5到1/10。它就像为AI推理引擎装上了“大容量高速缓存”,使其无需在“速度”与“容量”之间艰难取舍。
二、HBF为何能快速商业化?坐享HBM技术红利
Kim教授有一个关键观点:HBM花费了十几年才走向成熟,而HBF的商业化速度会快得多,预计2027年底到2028年初就会集成到NVIDIA、AMD、Google等公司的产品中。核心原因只有一个——复用HBM积累的技术。
HBM的核心难点在于3D堆叠、硅穿孔(TSV)、混合键合(Hybrid Bonding)等封装与架构技术,而三星、SK海力士等巨头对此已驾轻就熟。HBF只是将存储介质从DRAM换成了NAND,核心架构得以复用,这将其研发周期从10年以上大幅压缩到3-5年。
这里需要纠正一个常见误区:HBF并非要取代HBM。Kim教授明确指出,两者是互补关系:HBM继续负责AI训练时对延迟极端敏感的高速数据交换(纳秒级延迟不可替代),而HBF则主攻推理场景——例如ChatGPT生成回答、图像识别等读取密集型任务。这类任务需要大容量存储模型参数和中间数据,对延迟的要求相对宽松。
还有一个值得关注的时间节点:HBF将在HBM6推出时迎来大规模普及。而HBM6本身也将发生重大变化——不再是单一内存堆栈,而是多个堆栈像“住宅小区”一样互联,以解决HBM自身的容量瓶颈。但即便如此,基于DRAM的HBM仍会遇到物理上的容量天花板,此时基于NAND堆叠的HBF便能有效补位。
三、对AI推理的颠覆性影响:从“漫长搬运”到“近存计算”
要理解HBF的价值,需要先看清当前AI推理流程中的“低效”之处。Kim教授曾拆解过:GPU进行推理时,数据需要从存储网络调用,经过数据处理器,再进入GPU计算流水线,传输路径长且曲折。
HBF的出现旨在重构这一流程。首先,它能接管HBM在推理中的数据检索任务。其高达512GB的单堆栈容量(通过8堆栈组合可达4TB),足以直接加载GPT-4级别的大模型(约1.8万亿参数),从而避免频繁在不同存储层级间搬运数据,极大提升效率。
其次,它将推动AI架构的整体升级。Kim教授预测,到HBM7时代,可能会出现“内存工厂”架构——数据在HBM之后即可被直接处理,跳过存储网络、数据处理器等中间环节,彻底打破“计算与存储分离”的传统模式。而HBF作为大容量缓存层,将成为这一架构中的核心组件。
当然,HBF也有其短板:写入寿命约为10万次循环,虽支持无限次读取,但仍需OpenAI、Google等公司优化软件,以更好地适配读取密集型操作。不过,这对于AI推理场景而言并非硬伤,因为推理本就以读取数据为主,写入需求远低于训练。
四、巨头竞速:三星、SK海力士的HBF布局
技术再好,最终要看产业落地。目前HBF赛道已形成“三巨头联盟”:三星、SK海力士与闪迪(SanDisk),其推进速度超出预期。
动作最快的是SK海力士——预计将在2026年展示HBF测试版,相当于向行业放出“技术演示”,证明其可行性。而三星和SK海力士都已与闪迪签署备忘录,成立联合联盟以推进HBF标准化,避免出现“各自为战”的技术壁垒。
三家的目标高度一致:在2027年实现量产。闪迪计划在2026年下半年推出首批样品,2027年初完成在AI推理设备中的原型验证;三星则计划同步将HBF集成到NVIDIA、AMD的产品中,直接对接下游AI厂商的需求。
从技术路线图看,闪迪已规划了迭代节奏:2027年的第二代HBF带宽将超过2TB/s,2028年的第三代超过3.2TB/s,容量也将分别提升至1TB和1.5TB,逐步拉近与HBM的带宽差距,同时保持其容量优势。
五、未来时间线与市场展望:2038年超越HBM?
最后,我们来梳理一下HBF的关键时间节点,结合Kim教授的预测,看看这项技术将如何一步步渗透市场:
- 2026年:SK海力士展示HBF测试版,行业进入“技术验证期”;闪迪推出首批HBF样品,开始与GPU厂商进行适配。
- 2027年:三星、SK海力士实现HBF量产,NVIDIA、AMD、Google的产品正式集成,商业化元年开启。
- 2029-2030年:HBM6推出,HBF迎来大规模普及,成为AI推理服务器的标配。
- 2038年左右:HBF市场规模有望超越HBM,成为AI存储领域的主导力量之一。
从市场规模看,行业预估2027-2028年HBF市场规模约为10-20亿美元,到2030年可能增长至100-150亿美元,占据AI推理存储市场的70%以上。这一增长逻辑很清晰:AI推理的需求将比训练更为广泛(从云端扩展到边缘设备),而HBF是目前最能平衡“性能、容量、成本”三者的方案。
对普通开发者而言,HBF的意义不止是一项新技术——它有望降低AI推理的硬件门槛,推动大模型从“云端专属”走向边缘设备,让智能汽车、家用机器人等都能承载更强大的AI能力。对行业而言,HBF使NAND闪存从“普通存储”升级为“计算-存储融合”的核心组件,整个半导体产业链都可能因此重构。
总结而言:HBF不是HBM的对手,而是AI存储生态中关键的“补位者”。它踩着HBM奠定的技术红利,精准命中了推理场景的痛点。这场从实验室走向量产倒计时的存储革命,值得我们在未来几年重点关注三星、SK海力士的量产进展,以及NVIDIA新一代GPU对HBF的适配——这将直接决定下一代AI技术落地的速度与广度。
对存储和AI底层技术感兴趣的开发者,欢迎来 云栈社区 交流探讨。

 发表于 2026-1-21 12:13:11
|
查看: 195|
回复: 0
发表于 2026-1-21 12:13:11
|
查看: 195|
回复: 0
