
在 AI 大模型训练与推理的实践中,许多工程师都会遇到一个令人困惑的现象:即便指定相同的 FP16 或 BF16 计算精度,不同硬件(如 GPU 和 NPU)跑出来的结果也存在偏差;甚至在同一厂商的不同代际产品(比如 NPU A1 与 A2)上,计算结果也不完全一致。
这些精度差异是正常的吗?其背后究竟隐藏着哪些技术原理?本文将深入拆解,从浮点数本质、硬件实现、软件栈到并行架构等多个层面,为你揭开 AI 芯片计算精度差异的神秘面纱。
一、浮点数的 “数学陷阱”:交换律和结合律失效了?
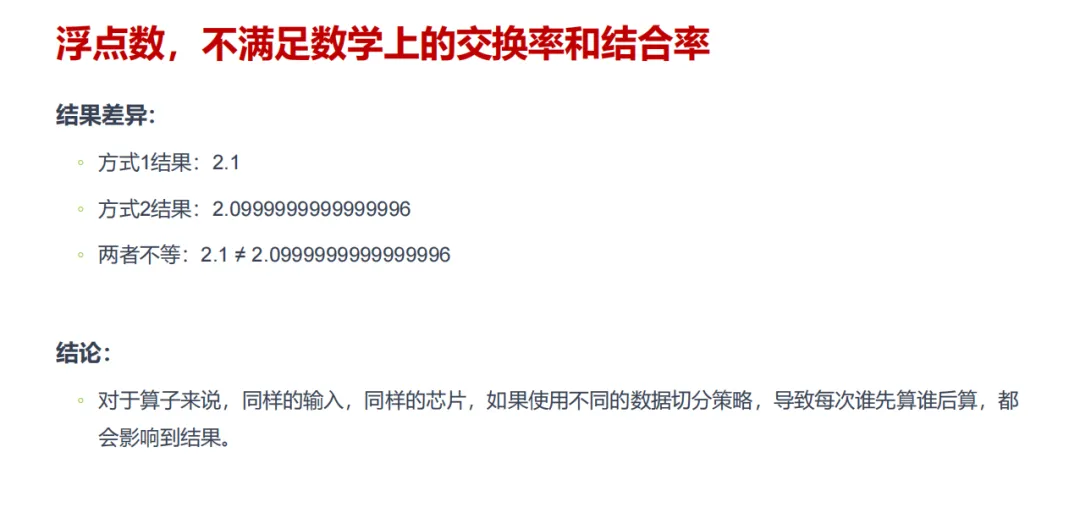
在我们的常识中,加法满足交换律和结合律,1+2+3 的结果必然等于 3+2+1。但在 AI 芯片的浮点运算世界里,这个数学上的铁律却被打破了。
核心原因在于,浮点数在计算机中无法被完全精确表示。例如,我们熟悉的十进制数 0.1,在二进制中是一个无限循环小数,计算机只能以有限精度进行近似存储。

AI 大模型的计算过程,本质上是海量浮点数的累加与乘法运算。不同芯片或不同算法在数据流切分策略上的差异,会导致实际运算顺序不同。每一次运算都可能引入微小的舍入误差,而计算顺序的变化会改变这些误差累积的路径与方向,最终导致可感知的精度偏差。关键在于,这种偏差并非芯片质量或设计缺陷,而是浮点数表示本身的数学特性所致,这也是所有遵循 IEEE 754 标准的处理器共有的现象。
二、硬件底层的 “设计分歧”:浮点运算单元各有千秋
如果说浮点数特性是精度差异的“先天因素”,那么硬件实现层面的差异就是“后天关键变量”。不同厂商设计的 AI 芯片,在其最核心的浮点运算单元(FPU)上,从晶体管级开始就选择了不同的优化路径。
在计算机基础中,浮点运算单元的设计是性能与精度权衡的艺术。NVIDIA GPU 采用了更复杂的累加器结构,其 Tensor Core 专门针对矩阵乘法优化了数据流处理方式;而华为昇腾 NPU 的 Cube Core 则聚焦于 AI 场景的矩阵运算,设计了专属的计算路径。两者虽都能高效完成矩阵乘法,但在累加器位宽、内部数据处理逻辑等细节上的差异,会直接导致计算结果的细微偏差。

此外,为了极致提升运算性能,不同芯片对低精度计算(如 FP16)中的非规格化数会采取不同的截断或近似处理策略。有些硬件会选择直接截断以加快速度,有些则会保留更多精度,这种性能优化策略上的分歧,也让最终的精度输出存在必然差异。
值得注意的是,即便是同一类型的芯片,不同代际产品之间的精度也可能不同。例如从 GPU 的 A100 到 H100,或 NPU 的 A1 到 A2,随着架构迭代和电路优化,浮点运算的实现细节会不断调整,精度表现自然也会随之变化。
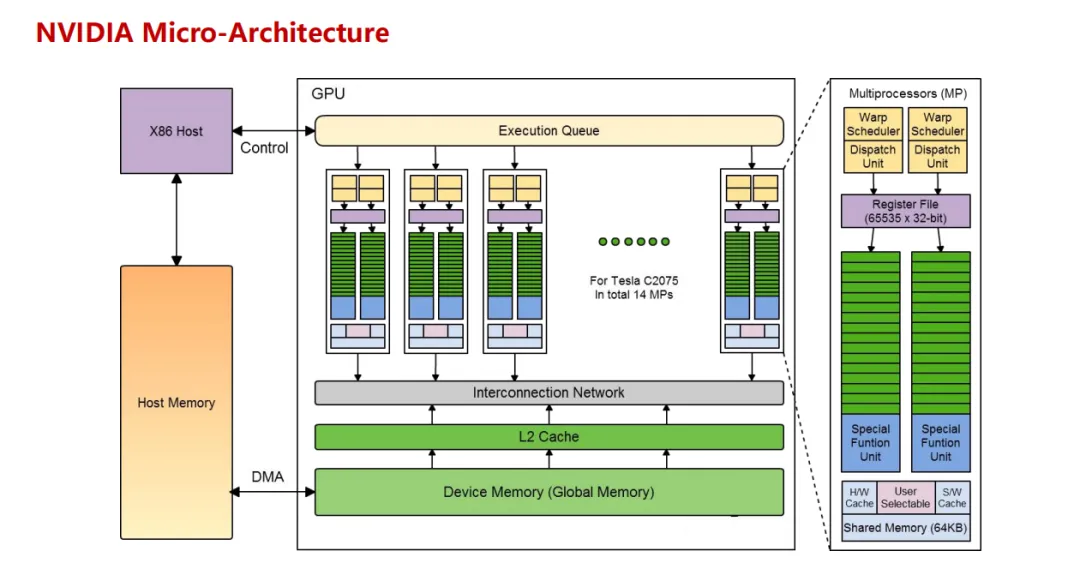
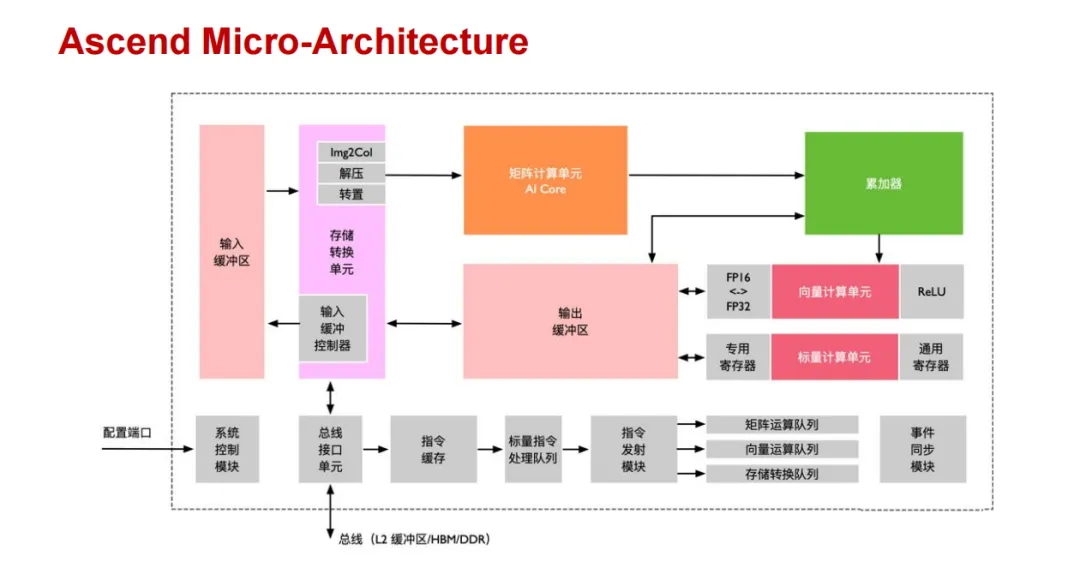
三、软件栈的 “底层博弈”:算法与编译器的隐形影响
硬件之上的软件栈,其实现差异同样在悄无声息地影响着最终计算结果。AI 芯片的强大算力需要通过底层的数学库和编译器来充分释放,而不同厂商在这方面的实现逻辑可谓大相径庭。
在数学库层面,以 NVIDIA 的 cuBLAS 和昇腾的 CANN 算子库为例,它们在实现矩阵乘法时,所采用的分块策略、循环展开方式、内存访问优化等手段都存在差异。以常见的 GEMM(通用矩阵乘)运算为例,不同的分块大小会直接影响浮点数累加的顺序,从而导致舍入误差积累的方向发生偏移,最终反映在计算结果上。

编译器的优化则是另一个关键因素。现代编译器会根据目标硬件的特性对指令进行重排,并决策是否使用融合乘加(FMA)等指令。NVIDIA 的 NVCC 编译器和昇腾 CANN 底层的编译器,所生成的最终指令序列可能存在显著不同。这些在微观指令层面的微小差异,经过AI大模型训练中海量运算的不断放大,最终会形成可观测的精度差异。
四、并行计算的 “不确定性”:线程与内存的协同难题
大模型训练极度依赖大规模并行计算,而并行架构本身固有的非确定性,也成为加剧精度差异的重要因素。
在线程调度层面,GPU 所采用的 CUDA 多线程 warp 调度策略,与昇腾 NPU 的多进程核函数调度方式存在本质不同。在并行计算中,线程块的执行顺序和线程间的数据同步往往无法完全固定。这种非确定性会导致浮点运算的累加顺序产生随机变化,误差积累的路径也随之改变,最终结果自然难以保证完全一致。

同时,对共享内存或各级缓存(如 L1、L2)的访问竞争,也会带来精度的微妙影响。不同硬件架构的内存一致性模型存在差异,这导致数据在多线程环境下更新的时序可能不同。尤其是在多线程并发访问同一内存地址时,这种时序上的微小差别会间接传导至计算过程,导致结果的偏差。

五、误差累积的 “蝴蝶效应”:海量运算下的精度放大
大模型的训练过程涉及数十亿乃至上万亿次的浮点运算,每一次运算所引入的微小舍入误差,都会在后续的计算中被不断传递和累积,最终形成“蝴蝶效应”。
根据 IEEE 754 浮点运算标准,所有兼容的芯片都采用“就近舍入”(Round-to-Nearest)模式来处理运算结果。然而,不同芯片在具体实现这一舍入规则时,其内部细节可能存在难以察觉的细微差异。在单次运算中,这种差异可能仅体现在小数点后十几位,但经过万亿次运算的层层累积后,偏差会被指数级放大,最终达到可观测甚至影响模型输出的程度。

值得庆幸的是,现代大模型通常具备强大的容错与泛化能力。实践证明,只要将不同硬件间的精度差异控制在较小的范围内(例如双千分之一量级),模型的最终推理效果和训练收敛速度通常不会受到本质性影响。对于智能 & 数据 & 云场景下的应用而言,追求绝对一致的精度往往不切实际,确保精度差异可控、可预期才是工程实践中的关键。
总结:精度差异不可怕,可控才是关键
通过以上分析,我们可以得出明确的结论:在 AI 大模型计算中,GPU 与 NPU 之间、乃至同类型芯片的不同代际之间出现精度差异,是必然发生的现象。这是浮点数的数学特性、硬件设计差异、软件栈实现、并行架构非确定性等多重因素共同作用的结果。

但这绝不意味着我们可以容忍无限制的、不可控的精度偏差。在实际的模型开发与部署中,工程师更应关注的是误差是否被约束在合理且可接受的范围内。目前行业共识是,只要能将精度差异稳定地控制在小数千分位之后,就不会对大模型的实用效果产生显著影响。
对于广大 AI 从业者而言,深入理解精度差异产生的底层逻辑,不仅能帮助我们以正确的心态看待计算结果的微小波动,更能指导我们在芯片选型、模型优化和算法调试中做出更科学、更高效的决策。毕竟,在推动大模型落地应用的征程上,精度的“可控性”远比绝对的“一致性”更具现实意义。
希望本文的技术剖析能为你带来启发。欢迎到云栈社区与更多开发者交流关于硬件算力与模型优化的心得。
 发表于 2026-1-21 13:02:03
|
查看: 190|
回复: 0
发表于 2026-1-21 13:02:03
|
查看: 190|
回复: 0
