
DeepSeek的新模型到底何时发布?这无疑是2026年开年最让开发者们翘首以盼的事件之一。
就在DeepSeek-R1模型发布一周年之际,有细心的开发者在DeepSeek官方的GitHub源码仓库中发现了新的线索。官方更新了其核心软件工具FlashMLA的代码,经过AI辅助的全面代码对比分析,一个此前未曾公开的模型架构标识——“MODEL1”浮出水面。该标识在114个相关文件中被提及了31次,迅速引发了开源社区的广泛关注。
FlashMLA是DeepSeek为英伟达GPU深度优化的专用软件工具,其主要任务是优化模型的注意力计算内核,这类更新通常意味着深层次的底层性能调优,而非简单的表面改动。
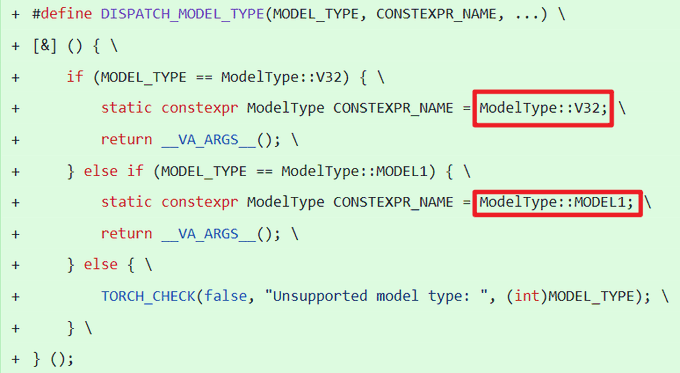
在代码中,“MODEL1”作为与现有“V32”并列的模型类型出现,例如在以下宏定义中:
#define DISPATCH_MODEL_TYPE(MODEL_TYPE, CONSTEXPR_NAME, ...) {
if (MODEL_TYPE == ModelType::V32) {
static constexpr ModelType CONSTEXPR_NAME = ModelType::V32;
return __VA_ARGS__();
} else if (MODEL_TYPE == ModelType::MODEL1) {
static constexpr ModelType CONSTEXPR_NAME = ModelType::MODEL1;
return __VA_ARGS__();
} else {
TORCH_CHECK(false, “Unsupported model type: “, (int)MODEL_TYPE);
}
}
开发者分析推测,“MODEL1”可能是一个早期的实验性模型分支,最终可能会收敛到V3或V3.2的标准路径上,而基于此架构的新模型,或许将被命名为V4。
更值得关注的是技术细节的演进。代码中明确提及了对fp8稀疏解码内核的内存布局要求,特别是针对MODEL1的缓存对齐要求:
...some kernels also have their own requirements on the layout of k cache, including:
- For sparse fp8 decoding kernel on F3, k_cache.stride(0) must be a multiple of 656B (for V32) or 576B (for MODEL1). Padding is needed sometimes.
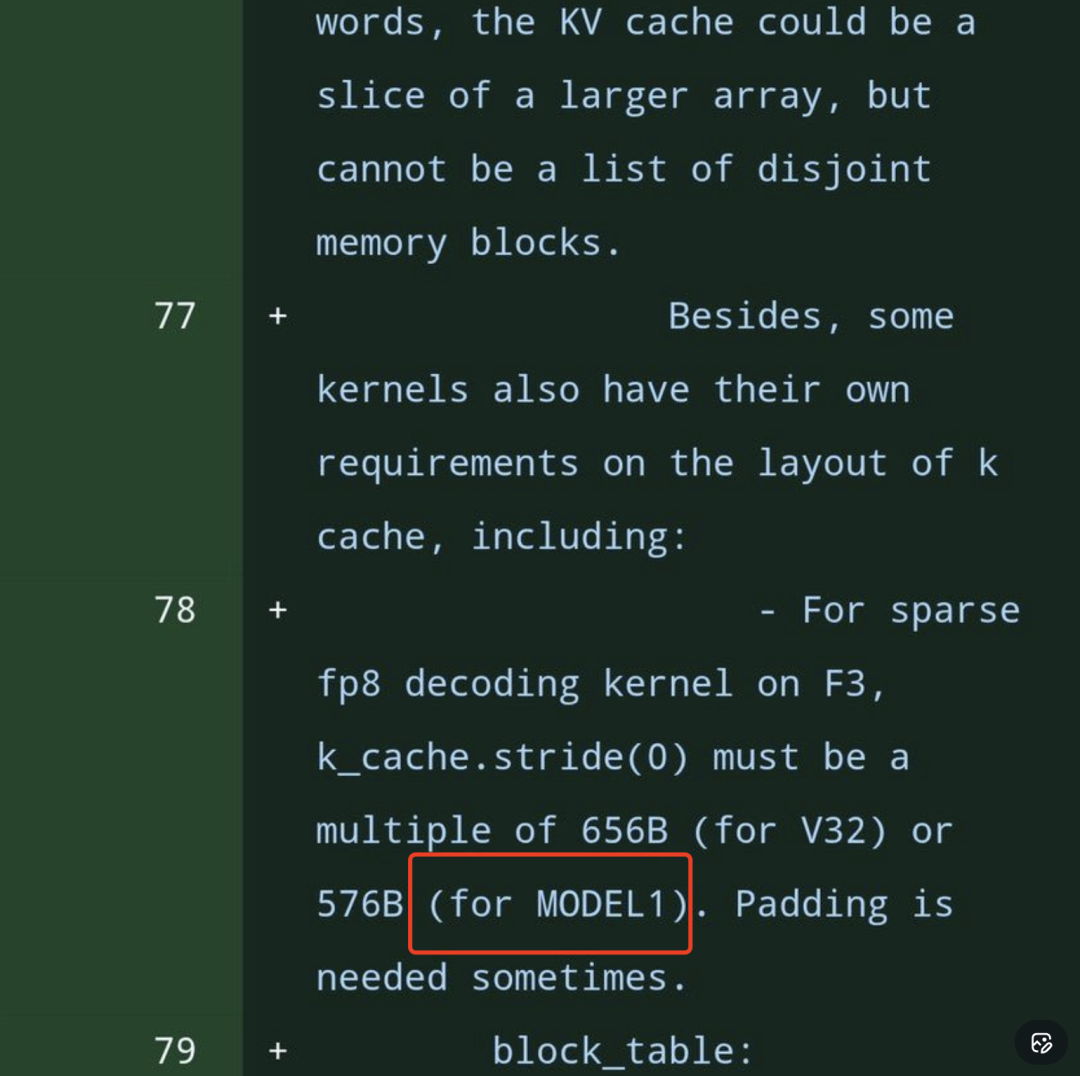
这表明,为了实现极致的显存访问效率,过去算子往往要求严格的内存对齐(如656B或576B的倍数)。而代码中移除了这些强制性的Padding倍数要求,意味着DeepSeek的高性能算子库已经完成了更深层次的解耦与优化。同时,代码库继续强调对fp8和稀疏性(sparsity)的支持,预示着FP8训练/推理以及稀疏注意力(Sparse Attention)技术仍将是新模型的核心技术底座。
进入2026年1月以来,DeepSeek团队已接连发布了两篇技术论文,分别涉及“优化残差连接(mHC)”和“AI记忆模块(Engram)”等创新。结合此次代码泄露的信息,社区普遍推测,“MODEL1”的最终版本很可能是一个在推理效率和性能上更为极致的旗舰模型。

一个模型如何改变整个生态
在DeepSeek R1推出一周年之际,开源平台Hugging Face官方发布博客,深入探讨了过去一年中国开源社区的历史性发展及其对全球开源生态系统的深远影响。可以说,过去一年AI领域的许多进展,都可以追溯到2025年1月那个被称为“DeepSeek时刻”的节点。当时,DeepSeek-R1的横空出世,给整个AI模型圈带来了一场改变游戏规则的冲击波。

在R1之前,中国的AI产业生态主要以闭源模型为中心。开源模型虽然存在,但多集中于学术研究或特定小众场景,对于大多数寻求商业应用的公司而言,并非主流选择。加之AI算力资源紧张,“开源还是闭源”始终是一个争论不休的话题。
R1模型的发布彻底改变了这一局面。它极大地降低了开发者获取先进AI推理能力的门槛,并提供了一个清晰、可复用的工程范式,推动行业进入了全新的发展阶段。更重要的是,它的发布为中国AI发展赢得了极其宝贵的时间窗口,证明即使在算力受限的条件下,通过开源协作和快速迭代,同样能够实现显著的技术创新和产业落地。
一年后的今天,我们看到逐渐成形的不仅仅是一系列新模型,更是一个不断壮大、自然演进的开源人工智能生态系统。来自中国的开源模型首次大规模进入全球主流排行榜单,并反复被用作性能参考的基准。Hugging Face平台上获赞最多的模型榜单也悄然易主。

分析认为,R1的真正历史意义,并不在于它是否是当时的“最强”模型,而在于它系统地降低了三道关键门槛:
第一道是技术门槛。 通过公开其推理路径和后训练方法,R1将此前被封闭API锁住的高级推理能力,变成了可以下载、微调和知识蒸馏的工程资产。许多团队无需再从零开始训练大模型,推理开始像一个可插拔的模块被广泛应用。
第二道是落地门槛。 采用宽松的MIT许可证发布,使得R1的使用、修改和分发变得极为简单。企业可以轻松将其集成到生产环境。模型蒸馏和领域适配,从“特种项目”变成了“常规操作”。社区讨论的焦点也从“哪个模型分数高”转向了“如何高效部署与降本”。
第三道是心理门槛。 当核心问题从“我们能不能做到”转变为“我们如何才能做得更好”时,整个行业的心态和决策模式都发生了根本性改变。对于中国AI技术社区而言,这也是一次持续获得全球关注和认可的难得机遇。
这三道门槛的共同降低,意味着整个AI应用生态系统开始具备自我复制与快速迭代的内生能力。
市场共识与战略对齐
一旦开源成为主流,一个自然而然的问题随之浮现:企业的战略将如何调整?过去一年的发展给出了清晰答案:竞争的焦点正从模型之间的“单打独斗”,转向系统级工程能力、生态构建和商业化落地的综合比拼。
与2024年相比,R1发布后的中国AI格局逐渐稳定为一种新模式:巨头引领方向,初创公司快速跟进,垂直行业企业纷纷入局。尽管应用场景各异,但一种共识尤其在头部企业间形成:开源不再是一种短期的市场战术,而已成为长期核心竞争战略的一部分。
此后,中国发布顶尖模型和开源代码仓库的机构数量呈爆发式增长。互联网科技公司的开源动作愈发密集。
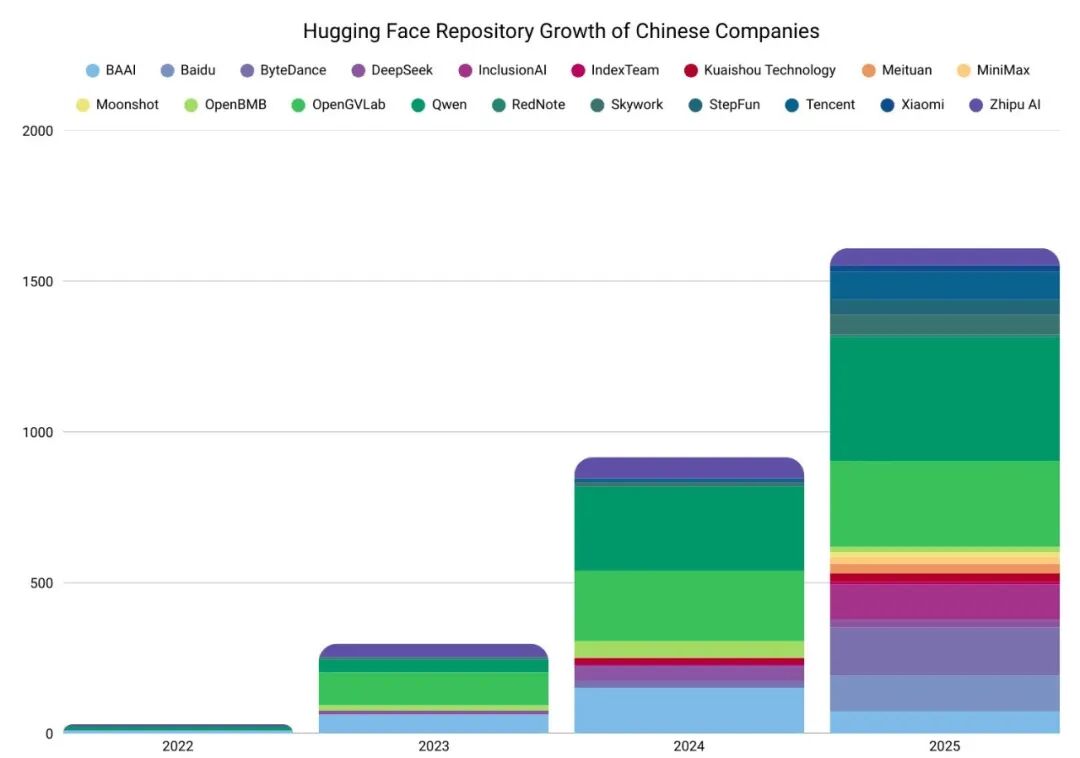
与此同时,一大批新晋力量也发布了性能优异的开源模型,如月之暗面的Kimi K2、MiniMax的M2以及智谱GLM系列等。在开源模式的助推下,模型迭代速度惊人,高性能模型几乎以周为单位更新。中国新模型每周都稳居Hugging Face“最受欢迎”和“下载量最高”榜单前列。
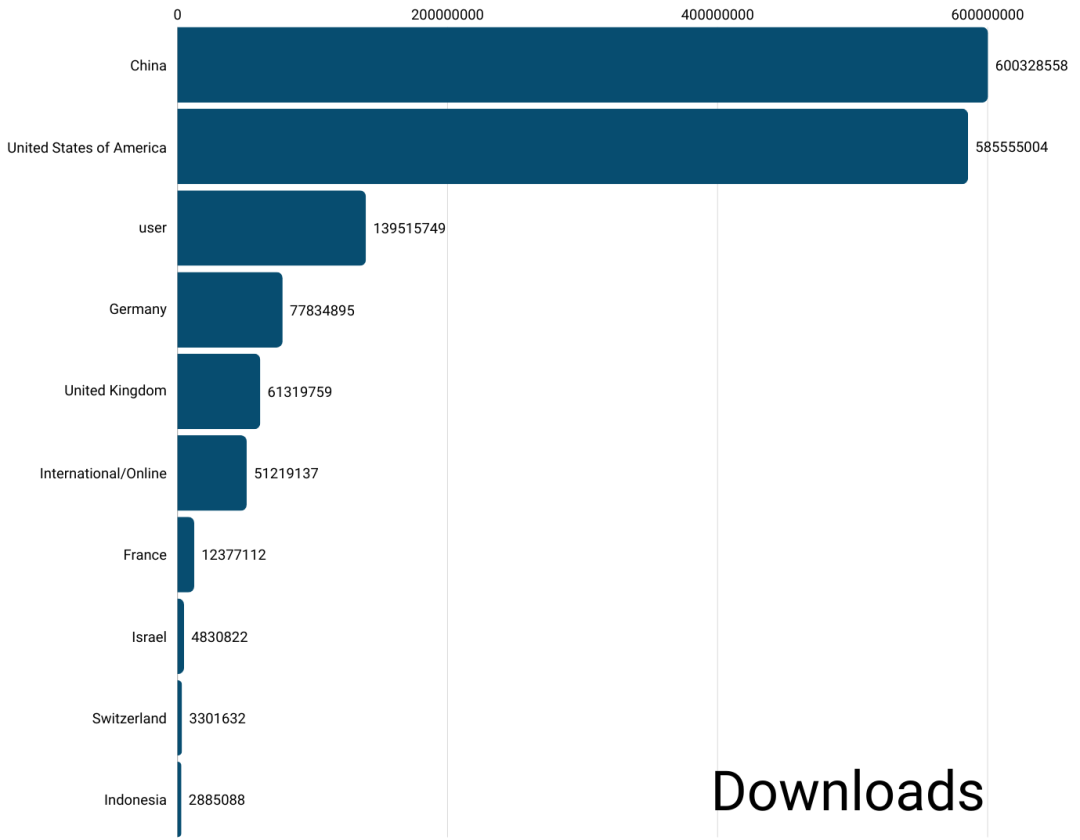
这一战略成效显著。据统计,在发布不到一年的新建AI模型下载量方面,中国模型的下载总量已超过包括美国在内的任何其他国家。
中国AI企业之间并非通过正式协议进行协同,而是在共同的算力约束、技术路径、经济成本和监管环境下,快速形成了市场的“战略对齐”。这并非意味着它们结成了技术联盟,相反,在相似的约束条件下,各厂商沿着新的技术基础展开竞逐,反而碰撞出了更多的市场活力与创新火花。
走向更有利的竞争地位
展望2026年,全球对开源AI技术采纳与发展的积极情绪依然高涨,开源领导力被视为全球AI竞争中的关键一环。
根据相关报告,得益于其开放性和易用性,DeepSeek等开源模型在许多发展中国家以及受技术获取限制的地区(如俄罗斯、伊朗、古巴及非洲部分国家)建立了坚实的市场地位。在北美和欧洲,其采用率相对较低。
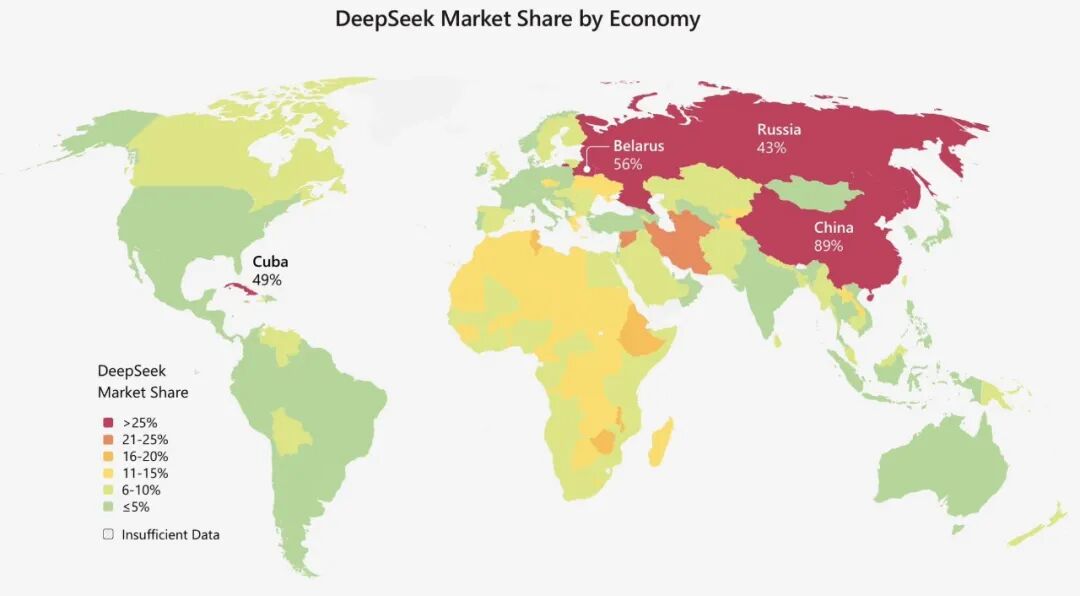
与一年前最大的不同在于,如今的中国市场,拥有全球竞争力的开源模型已不止一个。分析人士指出,美国凭借其巨额投资、高端芯片和封闭生态系统,可能在追逐“最佳模型”的竞赛中保持优势;而中国则更展现出将“足够好用”的模型快速、大规模整合到实际产业应用中,并在全球范围内推广扩散的能力。
人工智能竞赛更像一场马拉松,而非短跑。当前,中国在“创新”和“技术扩散”这两个关键变量上正日益掌握主动权,逐渐走向更有利的长期竞争地位。
 发表于 2026-1-24 05:12:23
|
查看: 228|
回复: 0
发表于 2026-1-24 05:12:23
|
查看: 228|
回复: 0
