
本文探讨了AI时代工程师的核心价值与技术机会,指出随着大语言模型(LLM)从GPT-1演进至Agent智能体阶段,工程师的关键角色已从“调用模型”转向“深度挖掘模型潜力”的系统性工程实践。作者通过四阶段范式演进梳理技术脉络指出模型决定智能下限,而工程师对业务场景的拆解能力、系统架构设计能力(流程编排/工具抽象/记忆机制/评测体系)才是决定产品体验上限的关键——AI工程师正从“炼丹师”进化为“系统架构师”与“场景定义者”。

前言
随着大语言模型(LLM)从GPT-1进化到如今的Agent智能体时代,我们往往容易陷入一个误区:认为AI应用效果的上限完全取决于基座模型的能力,工程师能做的只是“调用”和“等待”。然而,回顾LLM的发展史,真正的突破往往来自于工程层面的创新。
第一阶段:基础能力——海量数据与巨量参数(Pre-training Engineering)
论文:《Language Models are Few-Shot Learners》(2020)
基本原理:
- 架构:依然是Transformer Decoder,但规模扩大了100倍(1750亿参数)。
- 数据:几乎吞噬了整个互联网(Common Crawl)。
- 机制:
- 不更新权重:在使用时,不进行任何梯度下降。
- Prompt引导:用户在输入中提供几个“问题-答案”的例子。
- 目的:让模型学会“照葫芦画瓢”,实现少样本(Few-Shot)学习。
这一阶段证明了模型规模与数据量带来的“涌现能力”,但其本质仍是静态的知识库。
第二阶段:推理能力——用计算换智能(Inference Engineering)
▐ 1. COT开山之作
论文:《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》(2022)
提出了一种简单而高效的提示(Prompting)方法,其核心观点是:大模型本身就通过预训练具备了内隐的推理能力,不需要外部示例(Zero-Shot),只需要用特定的提示词去“唤醒”它。
核心机制
模型并非不会推理,而是平时习惯了“直觉式”回答(System 1思维)。通过加上“Let's think step by step”,我们强制模型进入“分析式”模式(System 2思维),将一个复杂问题拆解为多个中间步骤。
▐ 2. 自洽性(Self-Consistency)
论文:《Self-Consistency Improves Chain of Thought Reasoning in Language Models》(2022)
这是对COT的增强。其核心思想是:不要只采样一条推理路径,而是采样多条,然后通过“多数投票”(majority vote)的方式选出最一致的答案。
这种方法显著提升了数学推理等复杂任务的准确率,因为它减少了单一路径可能产生的随机错误。
▐ 3. 思维树(Tree of Thoughts, ToT)
论文:《Tree of Thoughts: Deliberate Problem Solving with Large Language Models》(2023)
这是对COT的又一次革命性升级。它不再局限于线性的“思维链”,而是构建一个“思维树”。
- 广度优先搜索(BFS):对于一个问题,生成多个可能的下一步思路(分支)。
- 评估与剪枝:对每个分支进行评估(比如让模型自己打分),保留最有希望的几个,剪掉差的。
- 深度优先搜索(DFS):沿着最有希望的路径深入探索,直到找到答案。
ToT让模型拥有了“规划”和“回溯”的能力,极大地提升了解决复杂、开放式问题的能力。
第三阶段:行动能力——从“说”到“做”(Action Engineering)
▐ 1. ReAct:推理+行动
论文:《ReAct: Synergizing Reasoning and Acting in Language Models》(2022)
ReAct框架将“推理”(Reason)和“行动”(Act)交织在一起,形成了一个闭环。
- 推理:决定下一步要做什么(比如,“我需要查一下今天的天气”)。
- 行动:调用外部工具执行(比如,调用一个天气API)。
- 观察:接收工具返回的结果(比如,“今天晴天,气温25度”)。
- 再推理:根据新信息继续推理(比如,“既然天气好,建议用户去公园”)。
这个循环往复的过程,让模型从一个“空谈家”变成了一个能与环境交互的“实干家”。
论文:《Toolformer: Language Models Can Teach Themselves to Use Tools》(2023)
Toolformer更进一步,它试图让模型“自学”如何使用工具。通过在大量包含API调用的日志数据上进行微调,模型学会了在合适的时机调用合适的工具(如计算器、搜索引擎、日历等),并将结果整合到自己的推理中。
第四阶段:自主能力——从“助手”到“代理”(Agent Engineering)
▐ 1. AutoGPT
AutoGPT是第一个引起广泛关注的自主智能体项目。它基于GPT-4,能够接受一个高层次的目标(如“研究XX股票并写一份投资报告”),然后自动拆解任务、规划步骤、调用工具(上网搜索、写代码、保存文件)、自我反思,直至完成目标。
尽管它存在效率低、容易“胡思乱想”等缺点,但它清晰地描绘了未来:用户只需下达目标,Agent负责执行全过程。
如果说AutoGPT是“一个人单干”,那么MetaGPT就是“一个团队协作”。
- 角色分工:它模拟了一个软件公司,拥有产品经理、架构师、项目经理、工程师、测试员等多个角色。
- 标准化流程(SOP):每个角色遵循一套类似真实公司的标准操作流程进行协作。
- 案例:只需输入一句“写一个经典的Flappy Bird游戏”,MetaGPT就能自动生成需求文档、架构图、代码,并完成测试。这启发了后来无数的AI编程工具(如Devin)和开源项目(如OpenDevin, ChatDev)。
MetaGPT开源后迅速成为GitHub上的爆款项目(Star数万),极大地降低了开发者构建多智能体应用的门槛,使得普通开发者也能利用Agent框架去尝试自动化爬虫、自动化数据分析等任务。
结语
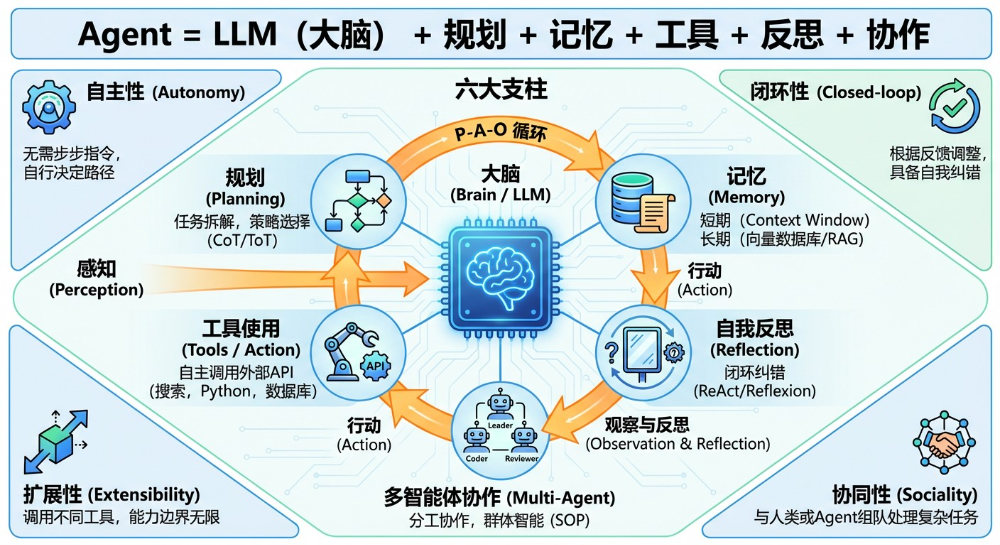
从GPT-3的“预训练”到AutoGPT的“自主代理”,我们看到了一条清晰的技术演进路径。未来的竞争,不再是单纯比拼谁的模型更大,而是比拼谁能更好地设计Agent的“大脑”(规划、记忆、反思)和“手脚”(工具调用、行动执行)。
工程师的价值空间,正在从模型的“使用者”,跃升为智能系统的“建筑师”和“导演”。这正是云栈社区所关注的核心议题:如何在AI+时代,构建真正可靠、高效、可落地的智能系统。
 发表于 2026-1-24 05:08:19
|
查看: 218|
回复: 0
发表于 2026-1-24 05:08:19
|
查看: 218|
回复: 0
