作为后端开发者,每天都要与MySQL的增删改查打交道。之前在文章《MySQL的一条SQL查询语句执行过程全解析》中,我们详细探讨了查询语句的执行流程。本文将重点拆解更新语句的执行过程,并与查询语句进行核心对比。下面先回顾一下SELECT语句的经典执行流程图:
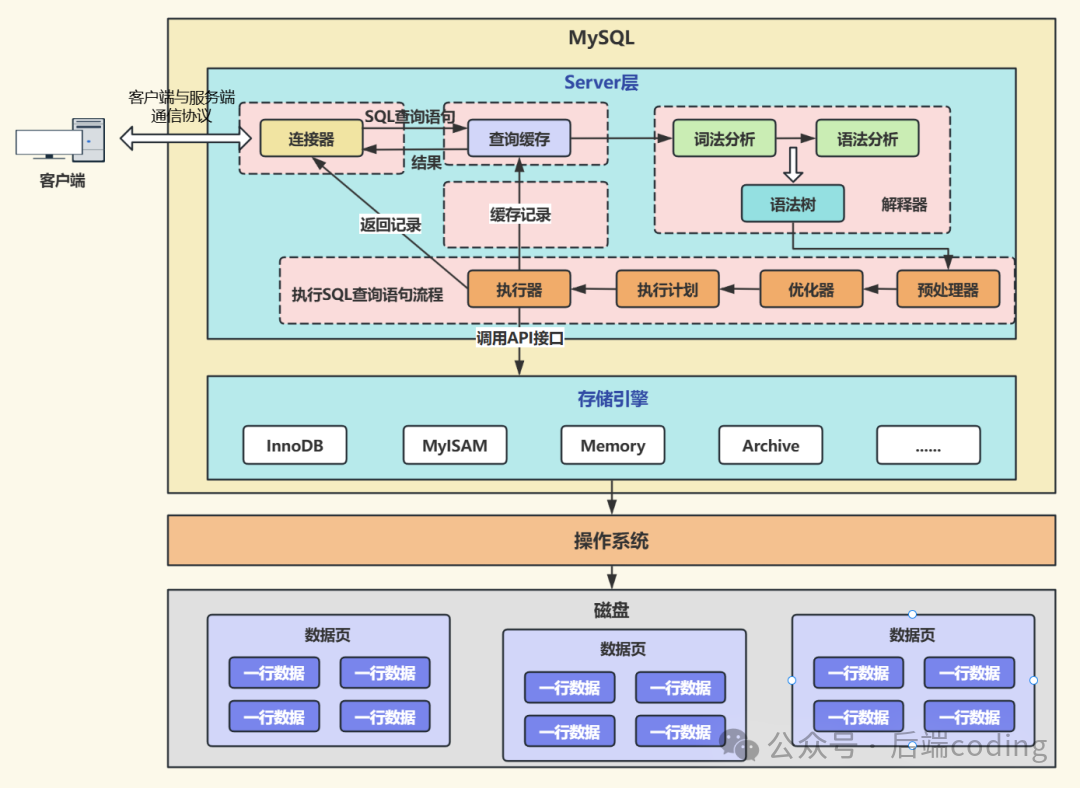
实际上,MySQL的update语句与查询语句的流程“大同小异”,但关键的几个差异点,恰恰是面试常考、工作中容易踩坑的地方,尤其是redo log、binlog和两阶段提交机制。在深入细节之前,我们先给出一个核心结论:MySQL的update语句,会完整经历一遍查询语句的核心流程,但在“查询缓存”和“执行器后续操作”这两个环节,存在显著差异。
下面,我们将结合具体案例 update user set name = ‘xiaoming’ where id = 1,一步步拆解更新语句的全流程,确保每个技术细节都准确清晰。
更新语句 vs 查询语句:通用核心流程剖析
无论是SELECT还是UPDATE,客户端请求到达后,都会先经过MySQL Server层的处理,这部分流程是共通的。接下来,我们在之前讨论过的SELECT流程基础上快速回顾,并重点标注与UPDATE的细微差异。
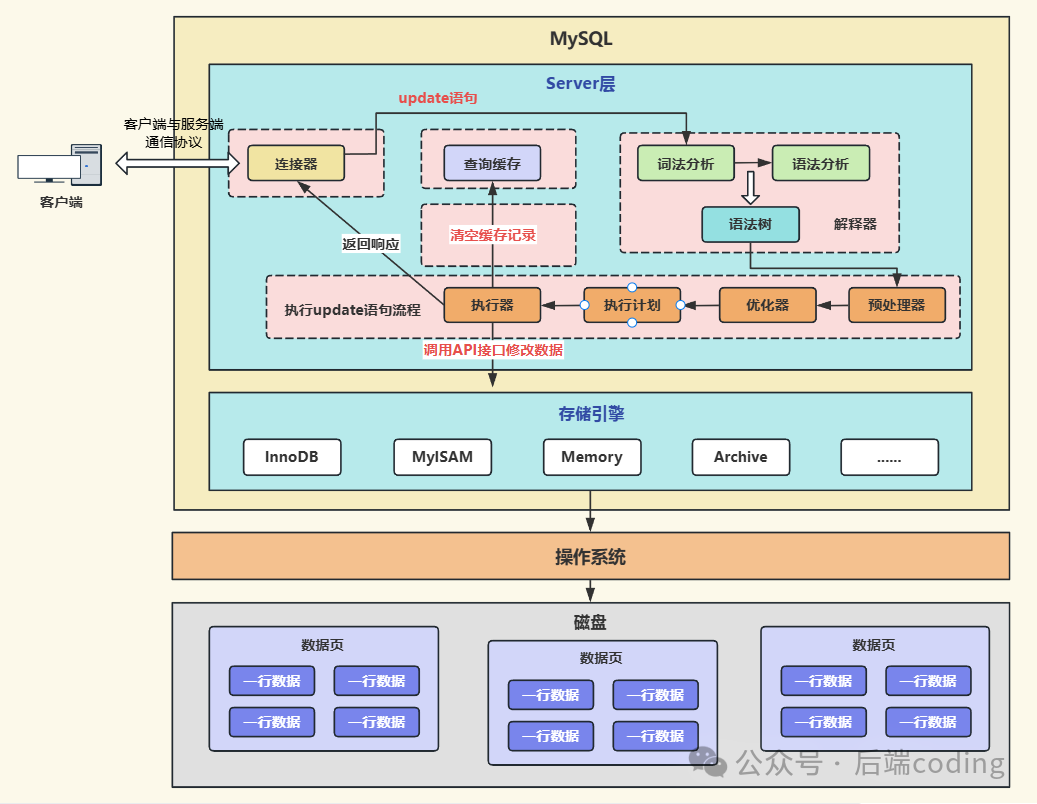
1. 连接器:建立连接,校验身份(与查询一致)
客户端执行任何SQL的第一步,都是通过连接器与MySQL服务器建立连接。连接器负责两件事:
- 校验客户端提供的用户名和密码的合法性。
- 身份验证通过后,分配一个线程来处理该客户端的后续请求,直到连接断开。
此环节对于查询和更新操作完全一致。
2. 查询缓存:更新语句不使用,但会“清空缓存”(关键差异点1)
这是更新语句与查询语句的第一个核心区别,也是查询缓存在MySQL 8.0中被移除的主要原因:
- 查询语句:会先检查查询缓存,若存在完全匹配的SQL结果,则直接返回,跳过后续所有解析、优化流程。
- 更新语句:不会使用查询缓存。但是,只要执行了UPDATE语句(即使更新的是另一行数据),MySQL就会清空该表涉及的所有查询缓存。
例如,刚执行过 select * from user where id = 1,结果被缓存;接着执行 update user set name = ‘test’ where id = 2,即便只更新了id=2的记录,整个user表的所有查询缓存都会被清空。这导致了查询缓存在写频繁的场景下命中率极低,反而消耗资源,因此MySQL 8.0直接移除了该功能。
3. 解析器:词法+语法分析,构建语法树(与查询一致)
跳过查询缓存后,SQL语句进入解析器。解析器的作用是“理解”SQL语句:
- 词法分析:识别SQL中的关键字、表名、字段名、值等。例如,从
update user set name = ‘xiaoming’ where id = 1 中识别出“update”是关键字,“user”是表名。
- 语法分析:校验SQL语句是否符合MySQL语法规则。例如,若将“update”错写为“updata”,解析器会直接报语法错误。
解析完成后,生成一棵“语法树”传递给下一个环节。
4. 预处理器:校验表和字段的合法性(与查询一致)
预处理器负责对语法树进行“合法性校验”:
- 校验SQL中涉及的表(如
user表)是否存在。
- 校验字段(如
name、id)是否存在。
- 校验字段与值的类型是否匹配。
校验失败则返回错误;校验通过后,语法树被优化并传递给优化器。
5. 优化器:选择最优执行计划(与查询一致)
优化器是MySQL的“智能大脑”,它会在多种可能的执行路径中,选择它认为效率最高的方式,生成执行计划。
对于案例 update user set name = ‘xiaoming’ where id = 1,优化器发现where条件中的id是主键索引,就会确定执行计划:使用主键索引快速定位id=1的记录。此逻辑与查询语句一致。
6. 执行器:调用存储引擎,执行具体操作(差异点的开始)
执行计划确定后,执行器登场。执行器的核心作用是调用存储引擎的接口,完成具体的读写操作。
查询语句的执行器调用接口是为了“读取数据”,而更新语句的执行器则是为了“修改数据”,这是后续所有差异的起点。
执行器调用存储引擎(如InnoDB存储引擎)后,更新操作才真正进入核心环节,涉及undo log、redo log、binlog和两阶段提交等查询语句没有的流程。
更新一条记录的8步核心细节(InnoDB引擎视角)
结合案例 update user set name = ‘xiaoming’ where id = 1,我们详细拆解执行器与InnoDB存储引擎协同工作的全过程。
步骤1:定位目标记录,加载到内存(缓冲池)
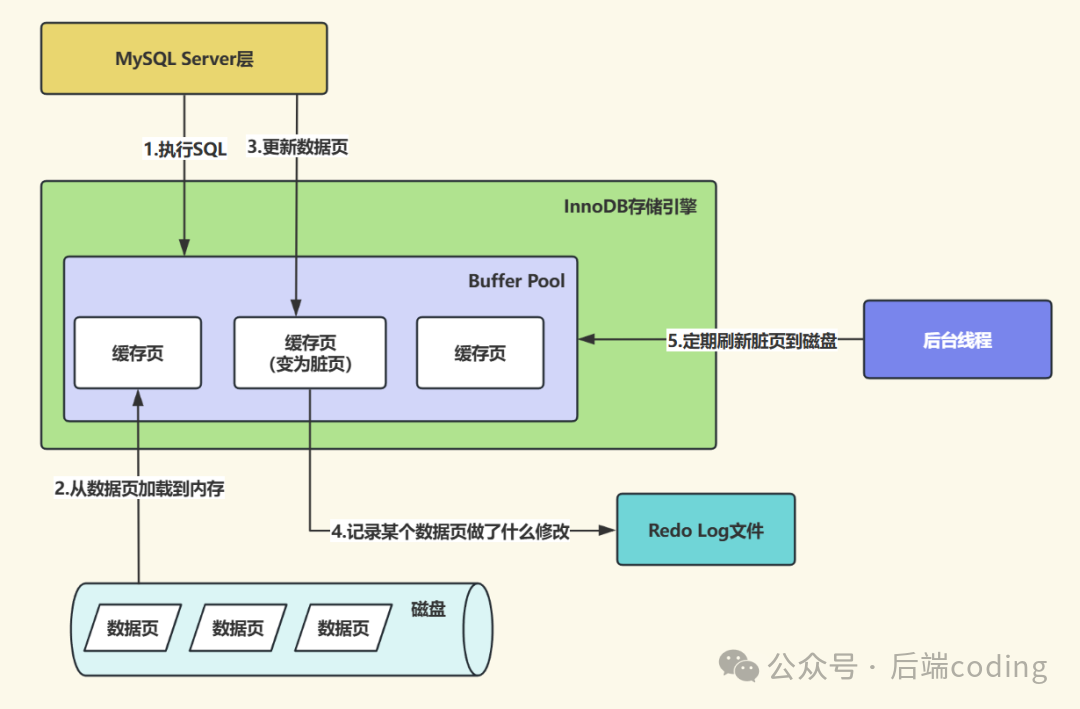
执行器首先调用InnoDB接口,根据优化器确定的“主键索引查找”计划定位id=1的记录。这里有两种情况:
- 若id=1所在的数据页已在InnoDB的Buffer Pool(缓冲池) 中(即之前被读取过),则直接从内存取出记录返回给执行器。
- 若数据页不在Buffer Pool(缓冲池) 中,InnoDB会从磁盘读取该数据页,加载到Buffer Pool,再将记录返回。
关键点:Buffer Pool是InnoDB的内存缓存,旨在减少磁盘I/O,所有读写都先操作内存数据,再异步同步到磁盘。
步骤2:校验更新前后是否一致,避免无效更新
执行器拿到记录后,会先做“无效更新校验”:对比更新前的值(如原name=’zhangsan’)和待更新的值(name=’xiaoming’)。若两者完全一致,则直接终止流程,避免无效的磁盘和日志写入。仅当值确实发生变化时,执行器才将“旧记录”和“新记录”作为参数传给InnoDB。
步骤3:开启事务,记录undo log(用于回滚)
InnoDB收到更新请求后,首先会开启一个事务(若无显式事务则开启隐式事务),并立即记录undo log(回滚日志)。这是保证事务原子性(ACID中的A)的核心。
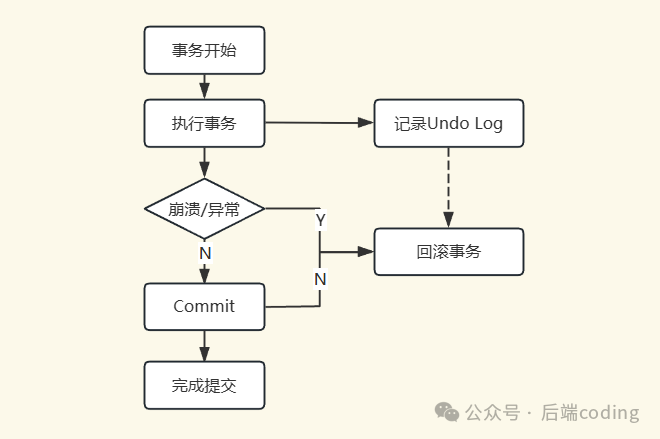
对于UPDATE操作,InnoDB会将被修改列的“旧值”记录到undo log中(例如,“user表id=1的name旧值为’zhangsan’”)。undo log先写入Buffer Pool的Undo页面(内存),同时会生成对应的redo log(见下一步)。
关键点:undo log用于事务回滚和MVCC(多版本并发控制),保证数据一致性和隔离性。
步骤4:更新内存数据,记录redo log(WAL技术核心)
记录完undo log后,开始真正的更新操作。这是MySQL WAL(Write-Ahead Logging,预写日志) 技术的核心:
- 更新内存记录:修改Buffer Pool中id=1记录的
name字段为’xiaoming’,并将该数据页标记为脏页(内存与磁盘数据不一致)。
- 记录redo log:将“对某个数据页的修改操作”写入redo log buffer(redo log的内存缓冲区)。
此时,从应用层面看,更新操作已经“完成”,可以准备向客户端返回成功。关键在于:更新不会立即将脏页写入磁盘,而是先写redo log。因为redo log是顺序写入,速度远快于随机写磁盘。脏页由后台线程异步刷盘,在性能和持久化之间取得平衡。通过参数innodb_flush_log_at_trx_commit可以控制redo log的刷盘策略,保证事务提交时redo log的持久性。
步骤5:记录binlog(用于主从复制、数据恢复)
InnoDB完成内存更新和redo log记录后,执行器会触发记录binlog(二进制日志)。请注意,binlog是MySQL Server层的日志,所有存储引擎通用。
- binlog记录的是SQL的“逻辑操作”(如“更新
user表id=1的name为xiaoming”),而非物理数据页的变化。
- binlog先写入binlog cache(内存缓冲区),在事务提交时才会统一刷入磁盘的binlog文件。
核心作用:binlog用于主从复制和数据恢复。
步骤6-8:两阶段提交(保证redo log和binlog一致性)
这是整个流程最复杂也最关键的一步。为何需要两阶段提交?因为redo log(InnoDB层)和binlog(Server层)是两个独立的日志系统。若不协调,可能出现“redo log提交成功,binlog提交失败”等不一致状态,导致主从数据不一致或数据恢复失败。
两阶段提交(Prepare + Commit)的目的就是保证这两个日志的“原子性”,确保它们要么都成功,要么都失败。
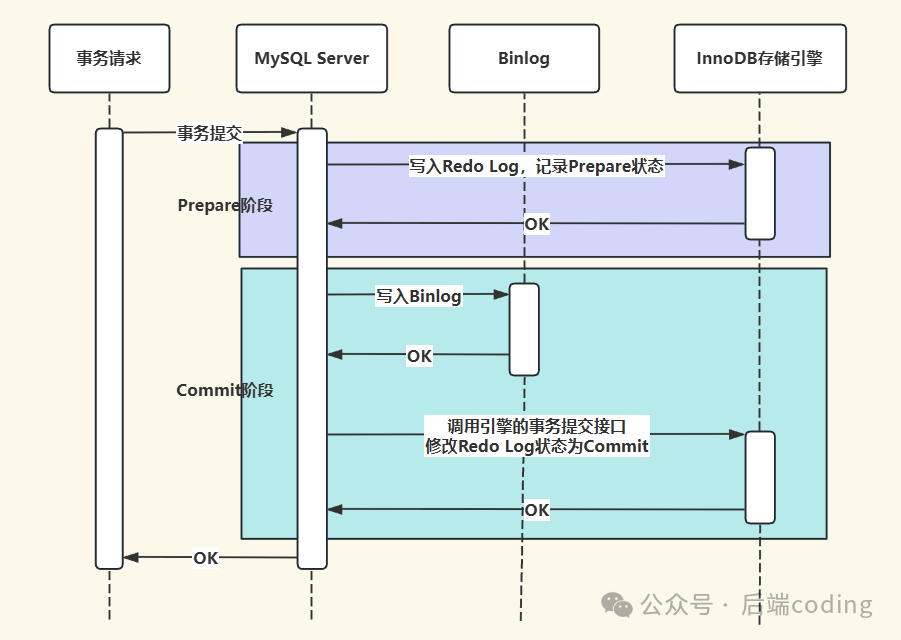
具体步骤:
- Prepare阶段:InnoDB将redo log中对应事务的状态标记为
PREPARE,并将redo log buffer的内容刷盘。
- Commit阶段:MySQL Server将binlog cache的内容刷盘至binlog文件。刷盘成功后,调用InnoDB的提交接口,将redo log中该事务的状态从
PREPARE改为COMMIT(此状态可延迟写入)。
- 事务提交完成,释放锁等资源。
异常处理:
- 若在Prepare阶段后、Commit阶段前崩溃:MySQL重启后会检查binlog。如果binlog中存在该事务记录,则重做commit;如果没有,则利用undo log回滚。
- 若在Prepare阶段前崩溃:直接通过undo log回滚事务。
核心总结与要点回顾
为了方便记忆和查漏补缺,以下是UPDATE语句执行流程的核心要点总结:
- 整体流程:连接器 → (跳过但清空)查询缓存 → 解析器 → 预处理器 → 优化器 → 执行器 → InnoDB引擎(核心更新步骤)。
- 关键差异(vs SELECT):UPDATE不使用查询缓存但会清空相关缓存;执行器后续会触发undo log、redo log、binlog记录及两阶段提交流程。
- 核心日志:三者缺一不可,各自承担关键角色:
- undo log:用于事务回滚和MVCC,保证原子性与隔离性。
- redo log:WAL技术的核心,提供崩溃恢复能力,保证持久性,先写日志后刷脏页以提升性能。
- binlog:用于主从复制和数据恢复,记录逻辑操作。
- 性能优化设计:Buffer Pool减少磁盘I/O;redo log与binlog采用先写内存缓冲区再异步刷盘的策略;两阶段提交在保证一致性的前提下,尽可能减少对性能的影响。
- 版本与引擎注意:MySQL 8.0已移除查询缓存;InnoDB是支持事务、redo log、undo log的存储引擎(MyISAM不支持这些特性)。
理解UPDATE语句的完整执行流程,尤其是日志系统如何协同工作,对于深入掌握MySQL、进行性能调优和故障排查至关重要。希望本文的梳理能帮助你在技术成长的道路上更进一步。欢迎在云栈社区与更多开发者交流讨论数据库相关技术。
 发表于 2026-1-25 00:04:30
|
查看: 220|
回复: 0
发表于 2026-1-25 00:04:30
|
查看: 220|
回复: 0
