当 AI 大模型对算力的需求从 “够用” 转向 “极致”,当芯片制程逼近物理极限,单纯堆晶体管的 “蛮力升级” 早已难以为继。就在此时,英特尔抛出了一款由 20 颗异构小芯片组成的 2.5D 集成系统,以 300MB 超大 SRAM 缓存、20Tb/s 恐怖带宽和 workload 自适应配置,重新定义了分布式 AI 推理的技术天花板。
一、小芯片革命:为什么 “拼接” 成为算力新出路?
随着芯片制程进入3nm、4nm 时代,单芯片的设计复杂度、制造成本呈指数级增长,“重路由”“良率低” 等问题成为难以逾越的鸿沟。而小芯片(Chiplet)技术通过 “化整为零” 的思路,将不同功能、不同制程、甚至不同厂商的芯片裸片,通过高速互连集成在同一封装内,既能突破单芯片的物理限制,又能实现 “按需组合” 的灵活配置,成为高性能计算的必然选择。
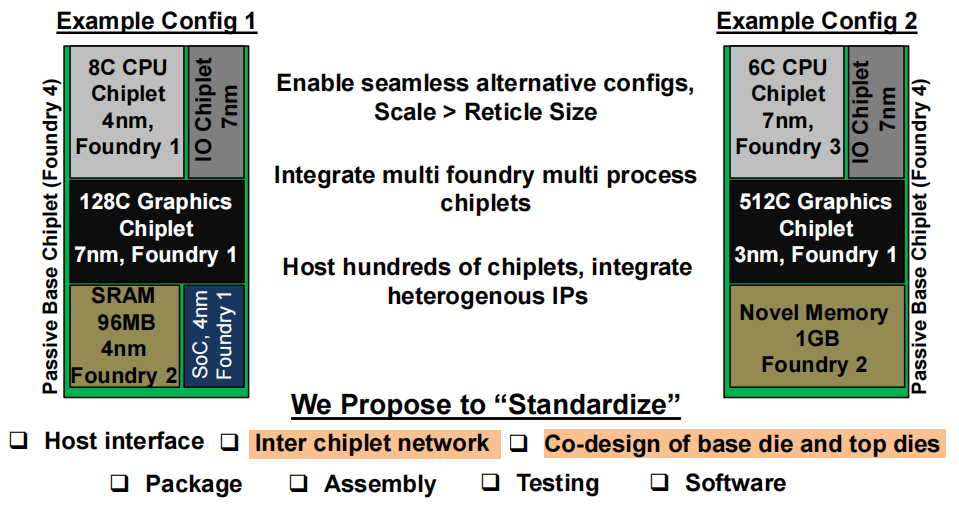
但小芯片技术的普及并非易事:不同厂商的芯片接口不统一、互连延迟高、系统兼容性差,这些 “碎片化” 问题严重制约了性能发挥。英特尔此次推出的 2.5D 异构系统,核心突破就在于建立了一套标准化的小芯片设计框架—— 从底座芯片与顶层芯片的协同设计,到封装、组装、测试的全流程规范,再到软件层面的统一调度,彻底解决了小芯片 “各自为战” 的行业痛点。
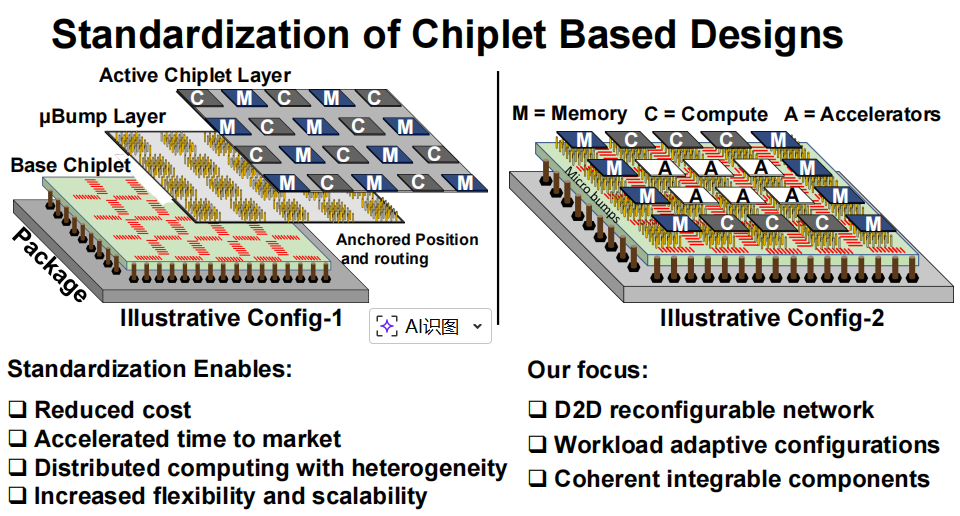
这套系统的野心不止于单一产品,更是要为整个行业提供 “模板化设计” 方案:通过统一的芯片插槽(CS)、微凸点(µBump)布局和 Die-to-Die(D2D)互连协议,让不同代工厂、不同制程的小芯片都能 “即插即用”,大幅降低设计成本、缩短上市时间,真正实现分布式计算的异构融合与灵活扩展。
二、架构深析:20 颗小芯片如何实现 “1+1>20”?
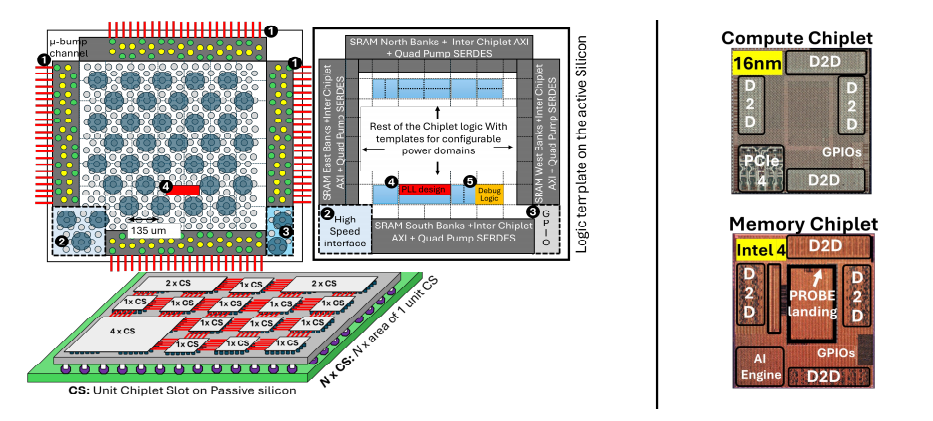
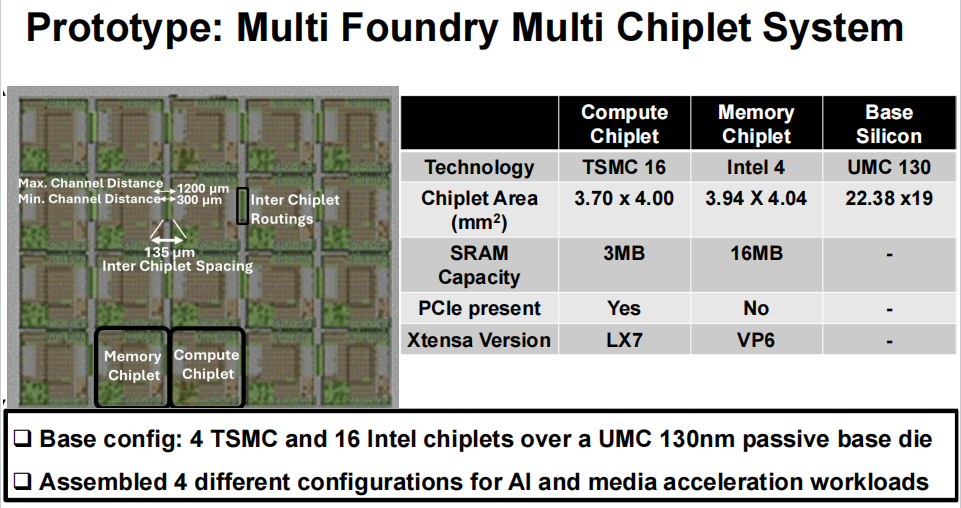
这款 2.5D 系统的强悍性能,源于其 “底层标准化 + 上层异构化” 的精妙设计。整个系统以一块 UMC 130nm 被动底座芯片为核心,搭载 4 颗 TSMC 16nm 计算小芯片和 16 颗 Intel 4(4nm)内存小芯片,通过 392 条物理金属布线实现全互连,形成一个兼具算力、缓存和带宽的 “超级计算集群”。
1. 异构小芯片:各司其职,精准发力
系统中的两颗核心小芯片分工明确,实现 “算力与存储的最优匹配”:
- 计算小芯片(TSMC 16nm):搭载 Tensilica Xtensa LX7 32 位 RISC 处理器,内置 1.5MB 片上 SRAM(分为 4 个 Bank),支持 PCIe 4.0 接口和近内存 AI 加速器(NMC),每颗可提供 4TOPS 算力,专门负责 CNN、GEMM 等密集型计算任务,同时具备芯片间和芯片内调试能力,保障系统稳定性。
- 内存小芯片(Intel 4 4nm):采用 Tensilica Vision P6 架构,聚焦 AI workload 优化,内置 16MB 大容量 SRAM(4 个数据 Bank),虽然不支持 PCIe,但与计算小芯片的 I/O 接口、凸点布局完全匹配,可作为 “近内存缓存” 或 “分布式存储节点”,为计算任务提供低延迟数据供给。
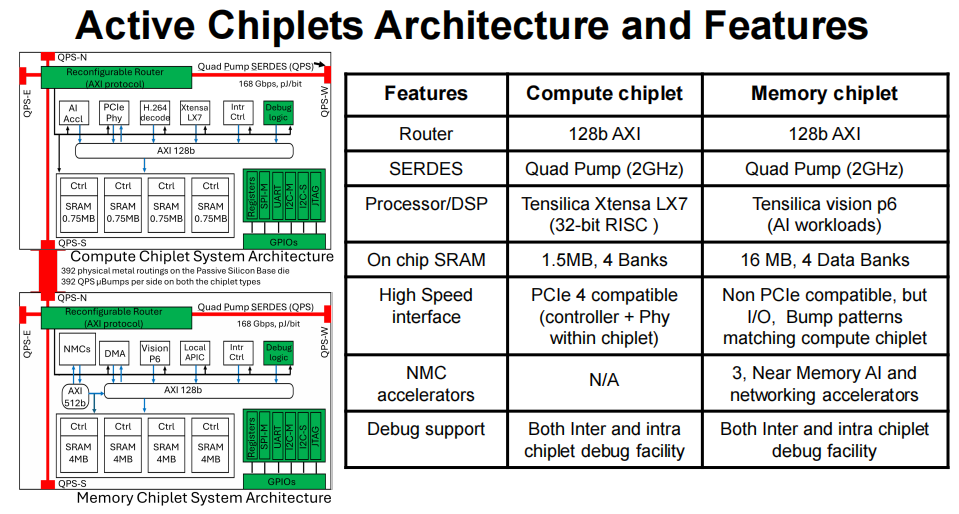
2. 互连与缓存:20Tb/s 带宽,数据 “零延迟” 流转
小芯片系统的性能瓶颈往往在 “互连”,而英特尔这款产品直接将带宽拉满:
- 采用 AXI 协议的可重构 D2D 路由器网络,每颗小芯片的四边都配备 Quad Pump SERDES(QPS),单链路速率达 168Gbps,整个系统的聚合带宽高达 20Tb/s,相当于每秒可传输 2.5GB 数据,彻底解决了小芯片间数据移动的 “堵车” 问题。
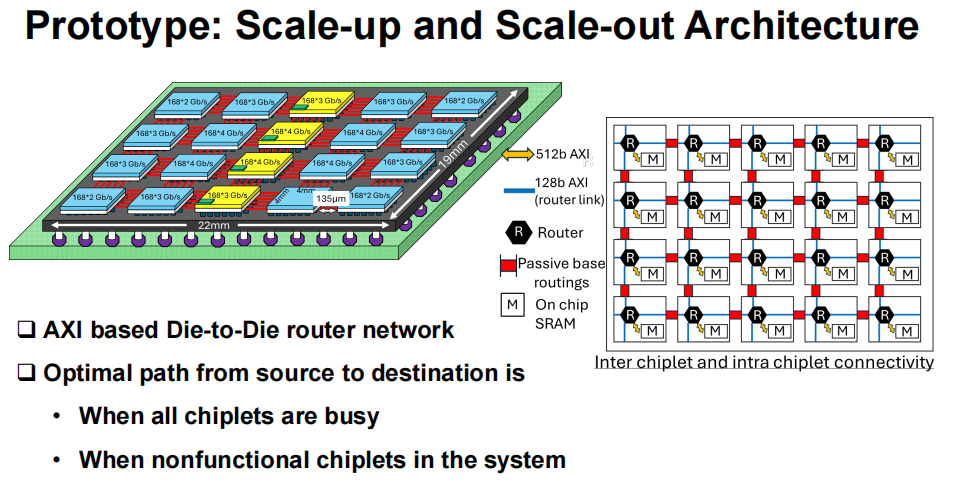
- 底座芯片采用 130nm 工艺,提供 392 条物理布线,小芯片间距仅 135μm,最短通道距离 300μm、最长 1200μm,配合优化的路由算法,能自动选择最优数据路径,即使部分芯片故障或满载,也能保障系统正常运行,容错性与灵活性兼备。
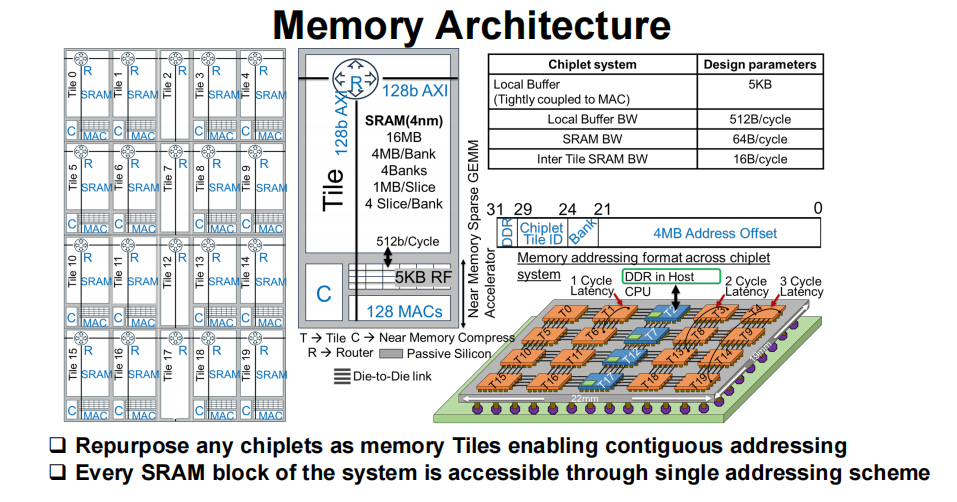
缓存系统同样是 “堆料级” 配置:16 颗内存小芯片 + 4 颗计算小芯片的 SRAM 总容量达 300MB,再加上每颗计算小芯片内置的 5KB 本地缓冲区(带宽 512B/cycle),形成 “本地缓存、近内存缓存、分布式缓存” 的三级存储架构,数据访问延迟低至 1-3 个时钟周期,较传统 DDR 内存大幅降低,为 AI 推理等对延迟敏感的任务提供了坚实保障。
3. 软件生态:智能调度,让算力 “物尽其用”
硬件的强悍需要软件的协同,这套系统配备了完整的软件栈:从 Graph 编译器到定制化中间件,再到资源管理器和驱动程序,能自动将任务最优映射到多小芯片系统中。例如在 ResNet50 推理任务中,软件会自动分配 3 颗内存小芯片 + 1 颗计算小芯片的组合,让计算与数据访问高度并行,最大限度减少 idle 时间。
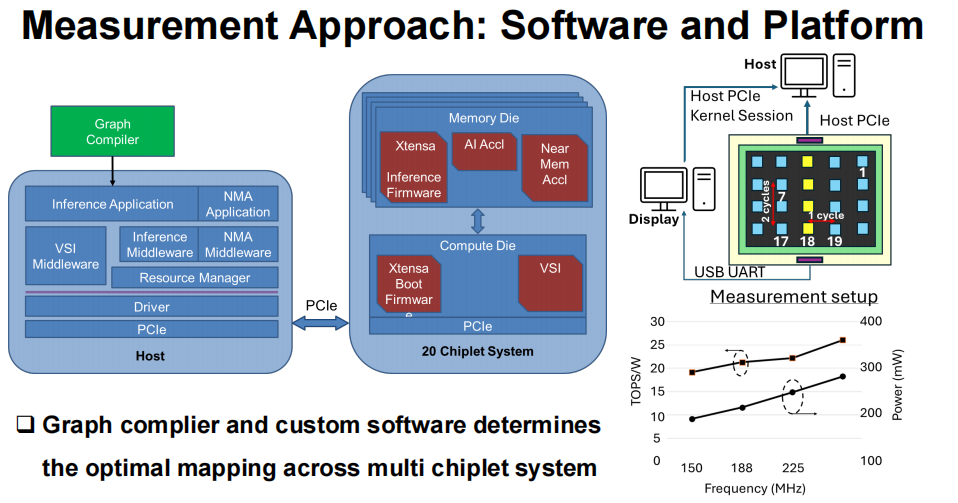
实测显示,在 300MHz 频率下,该系统运行 ResNet50 的推理速率达 6FPS,支持 6 条并行线程;若将硬件算力提升至 20TOPS / 小芯片,预计推理速率可突破 30FPS,而单颗小芯片的功耗仅 2.5W,能效比远超传统单芯片方案。
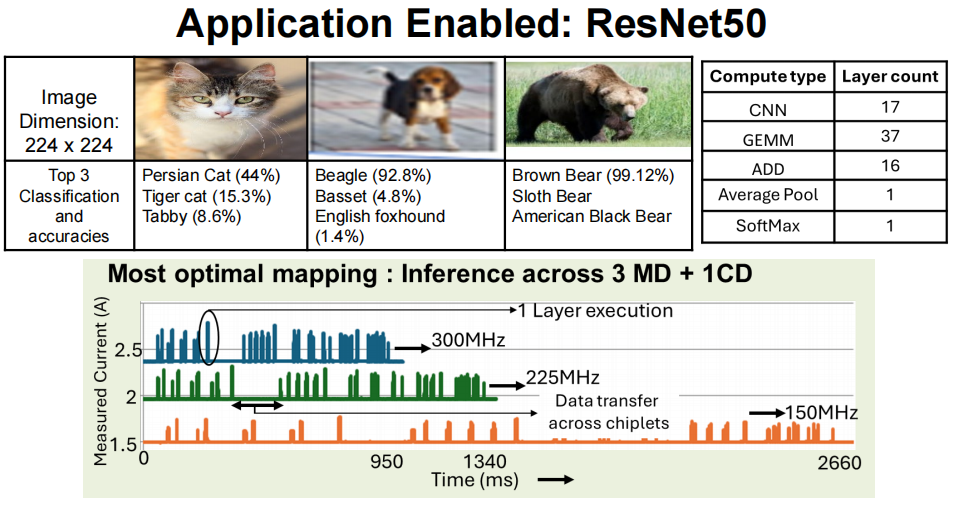
三、实测封神:ResNet50 推理性能碾压,重新定义 AI 算力标准
架构的优势最终要靠实测验证,这款 2.5D 系统在 ResNet50(224x224 图像分类)任务中的表现堪称 “教科书级”:
- 性能表现:在 150-300MHz 频率范围内,推理延迟低至 950ms,分类准确率与传统单芯片方案持平(如棕熊识别准确率达 99.12%);若按 20 颗小芯片满配算力计算,每秒可处理 30 帧图像,完全满足实时 AI 推理需求。
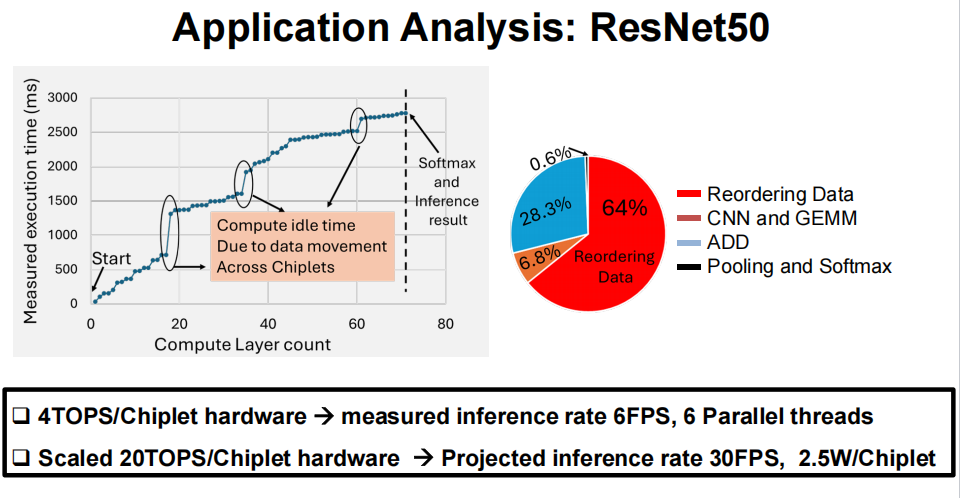
- 对比优势:与同类小芯片系统相比,英特尔这款产品在小芯片数量(20 颗,远超行业平均的 2-4 颗)、异构支持(唯一实现多代工厂、多制程融合)、带宽(20Tb/s)和缓存容量(300MB)上均处于领先地位,尤其是被动硅底座的设计,在信号完整性和成本控制上更具优势。
四、后摩尔时代,算力增长的 “新范式”
英特尔这款 2.5D 异构小芯片系统的推出,不仅是一次产品创新,更是对整个半导体行业的启发:
- 突破制程限制:无需依赖更先进的制程,通过小芯片集成就能实现算力、带宽、缓存的同步暴涨,为摩尔定律放缓后的算力增长提供了 “非制程依赖” 的新路径。
- 推动行业标准化:其提出的标准化设计框架,从硬件接口到软件调度,为破解小芯片生态碎片化难题提供了可行性极高的方案,有望加速整个产业的成熟。
当单芯片的 “内卷” 走到尽头,英特尔用 20 颗小芯片的 “协同作战”,证明了异构集成是后摩尔时代的核心竞争力。这款 2.5D 系统以 300MB 缓存、20Tb/s 带宽和极致的灵活性,不仅在 AI 推理性能上实现碾压,更树立了小芯片标准化设计的行业标杆。未来,随着小芯片接口、封装技术的进一步成熟,我们或许会看到更多 “按需组合” 的算力解决方案。对这类前沿硬件架构与技术趋势感兴趣的开发者,欢迎到 云栈社区 的计算机基础板块深入交流与探讨。 |  发表于 2026-1-25 05:59:18
|
查看: 158|
回复: 0
发表于 2026-1-25 05:59:18
|
查看: 158|
回复: 0
