在超高清视频应用日益普及的背景下,高效的视频编码技术至关重要。率失真优化量化(RDOQ)作为AVS3视频编码标准中的关键技术,能显著提升编码增益。然而,其高计算复杂度和强数据依赖性(尤其是上下文更新与扫描顺序冲突)一直是硬件并行化实现的瓶颈。本文深入解读了一种针对此问题的创新解决方案——一种基于Zig-Zag扫描线级并行的RDOQ算法及其全流水线硬件架构设计,该成果发表于IEEE TCSVT 2024年7月刊。该设计在保持高编码效率的同时,实现了极高的硬件吞吐量,为8K实时编码提供了可行的硬件实现路径。
1、背景介绍与挑战
率失真优化量化(RDOQ)通过在率失真优化的意义上搜索最佳量化系数水平(OCL)和最后显著系数(LSC)位置,相比传统的均匀标量量化提供了显著的编码增益。然而,RDOQ的硬件实现面临着巨大的挑战,主要体现在以下两个方面:
- OCL决策中的强数据依赖:在确定每个系数的最佳量化水平时,码率的估计依赖于上下文模型的更新。
- 扫描顺序的冲突:LSC位置决策依赖于Zig-Zag扫描顺序的累积RD代价计算,而DCT输出通常是列优先顺序,导致数据访问不匹配。
2、并行化算法设计
2.1 扫描顺序冲突分析
传统的RDOQ依赖于Zig-Zag扫描顺序来计算累积代价,而DCT变换输出通常是列优先的。如果直接在硬件中并行处理Zig-Zag数据,需要大量的buffer来进行数据重排,这会显著增加延迟和面积。
如图1所示,(a)是传统的Zig-Zag扫描,(b)是本文提出的基于列优先的处理方式。通过算法优化,将数据依赖限制在扫描线内部,使得同一列中的不同系数可以并行处理,从而完美契合了硬件的输入顺序,消除了重排buffer的需求。
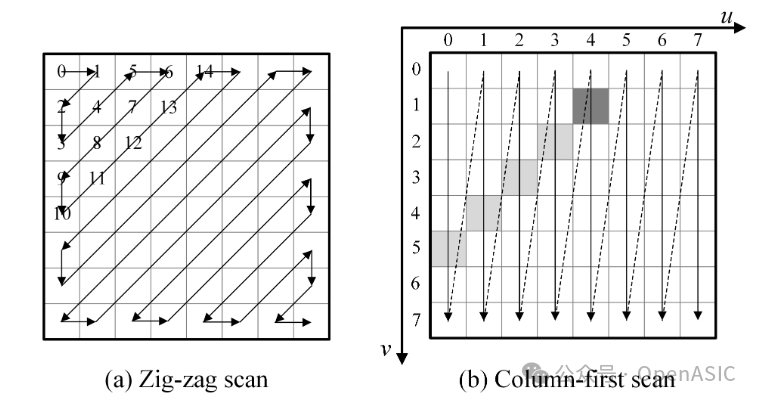
图1:Zig-Zag扫描顺序 (a) 与硬件友好的列优先扫描顺序 (b) 对比
2.2 算法核心逻辑
为了实现上述的并行处理,文章提出了两项核心算法优化:
- OCL决策并行化:通过解耦
prev_level 和 run 的计算依赖,将其限制在Zig-Zag扫描线内部。对于右上(Up-Right)和左下(Down-Left)扫描线分别设计了简化的上下文推导公式。
- 基于贪婪策略的LSC决策:将全局最优搜索分解为“局部扫描线次优搜索” + “全局最优决策”。算法首先在每条扫描线内部并行寻找次优LSC位置,然后通过Shift Buffer传递并比较这些次优解。
整体算法流程如图2所示,清晰地展示了从预量化到OCL并行决策,再到贪婪策略LSC搜索的全过程。
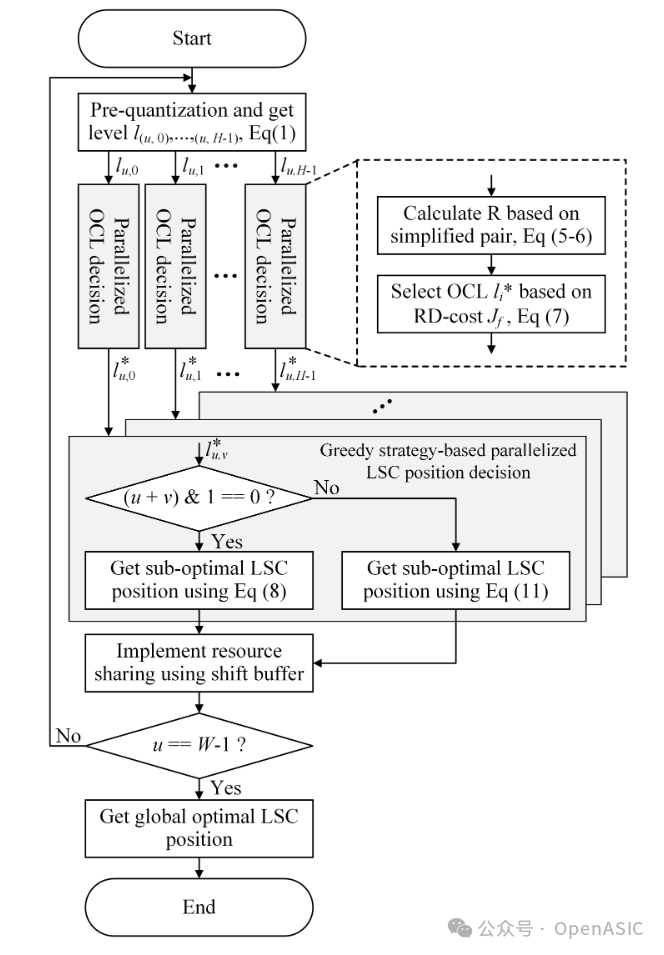
图2:提出的并行化RDOQ算法整体流程图
3、全流水线硬件架构设计
为了支持8K超高清视频的实时编码,本文设计了一种九级全流水线硬件架构。该架构不仅实现了高并行度,还通过特殊的流水线调度解决了数据依赖问题。
3.1 整体架构与流水线级数
整体硬件架构如图3所示,设计采用32像素/周期的并行度,意味着它可以同时处理一列(高度<=32)的所有系数。架构分为三个核心阶段:
- S1-S2 (预量化阶段):
- 处理模块:包含
Round 和 Shift 单元。
- 功能:独立处理每个系数的预量化,无数据依赖,适合大规模并行。
- S2-S4 (OCL决策阶段):
- S2-S3 (失真计算):计算所有候选Level (0, 1, ..., L)的失真。由于失真计算不依赖上下文,因此被安排在流水线前段并行执行。
- S4 (率计算与代价比较):这是关键路径。在此阶段完成Rate计算(依赖上下文)和RD-Cost合成。通过Data-forwarding技术,在单周期内完成上下文更新和最佳Level选择。
- S5-S9 (LSC决策阶段):
- S5 (扫描位置计算):计算每个系数的扫描位置代价。
- S6 (Shift Buffer):利用移位寄存器实现“即时(On-the-fly)”的次优位置决策,解决列优先输入与Zig-Zag扫描的冲突。
- S7-S9 (比较器树):为了快速找到全局最优LSC位置,设计了树状比较结构。S7使用8个比较器,S8使用4个,S9使用1个。这种并行比较将原本需要32个周期的串行过程压缩至3个周期。
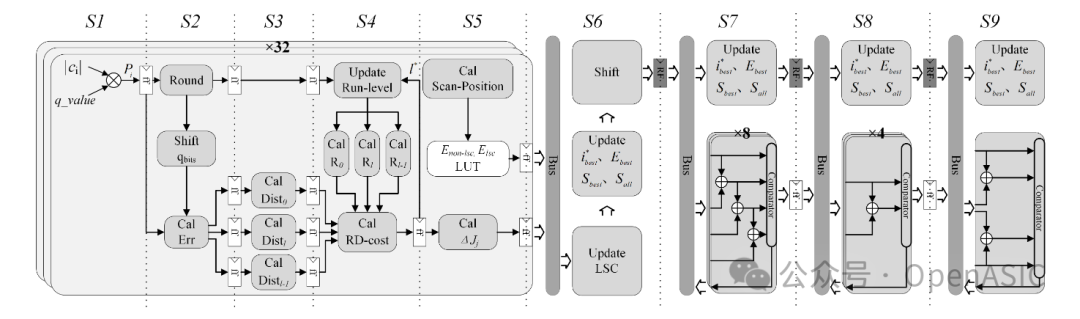
图3:RDOQ并行算法的九级硬件架构设计图,展示了从预量化、OCL决策到LSC决策的完整数据通路
3.2 复杂的率计算数据通路
在OCL决策中,Rate的计算是最复杂的,因为不同的Level值对应不同的编码方式(截断一元码、哥伦布编码等)。为了优化面积和时序,本文针对候选Level (Rl 和 R{l-1}) 设计了三条并行数据通路,如图4所示:
- Path 1 (Path_1):处理
|L| == 1 的情况。此时Rate仅依赖于 est_level 表查找,逻辑最简单。
- Path 2-8 (Path_others):处理
1 < |L| <= 8 的情况。除了查表,还需要加上对应的数值编码代价。
- Path >8 (Path_>8):处理
|L| > 8 的大数值情况。此时逻辑最复杂,需要结合哥伦布编码计算前缀和后缀长度。
硬件优化细节:为了节省昂贵的乘法器资源,设计中所有的乘法操作(如 est_level * |L|)都被替换为移位和加法操作,显著减小了电路面积。
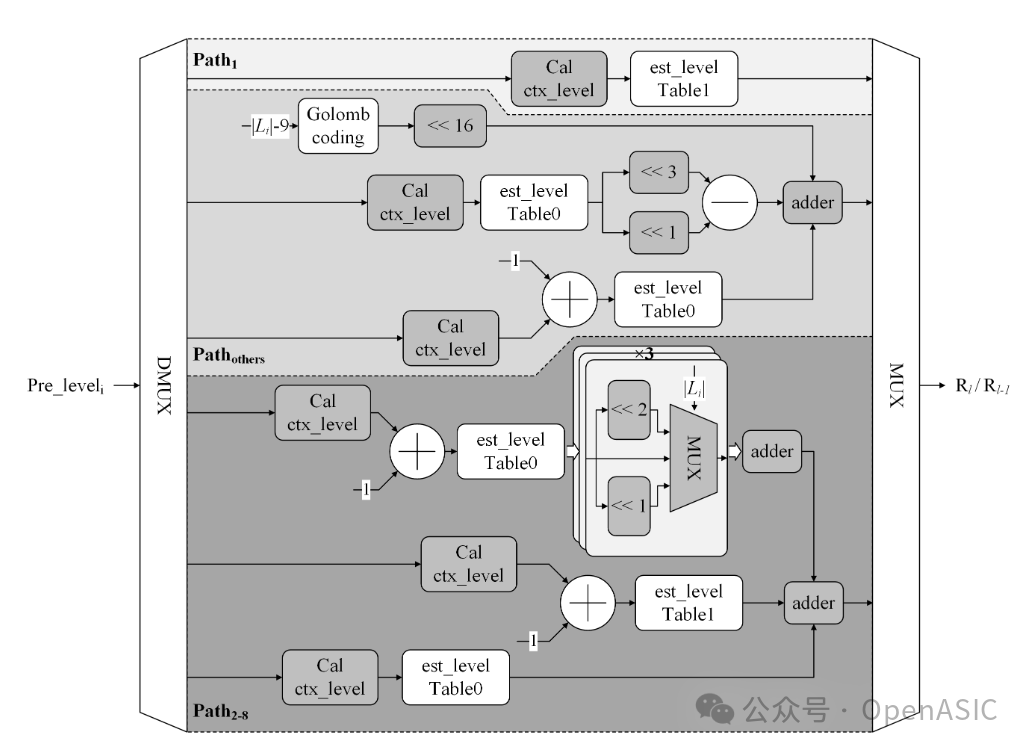
图4:针对Rl和R{l-1}的率计算模块的三条数据通路设计,采用了无乘法器的优化实现
4、实验结果与对比
4.1 编码性能与时间效率
在AVS3参考软件HPM-4.0上的测试表明,本文提出的算法在保持高编码效率的同时,显著降低了计算时间。
- BD-Rate损失极低:在AI、RA和LDB配置下,BD-Rate仅分别增加了0.25%、0.26%和0.27%。
- 时间节省显著:RDOQ模块的计算时间分别减少了31.37%、28.58%和28.53%。
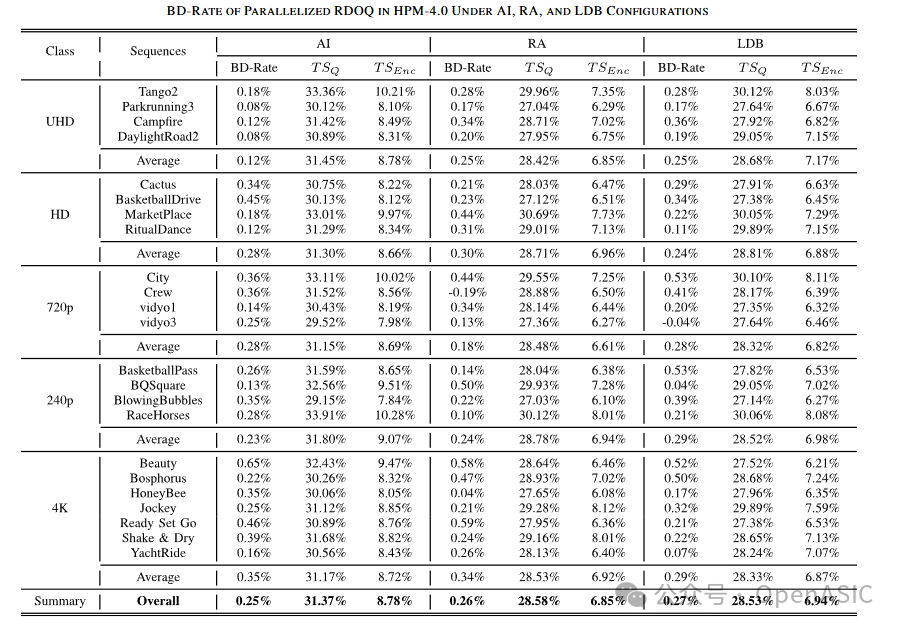
表I:并行化RDOQ算法在HPM-4.0中的BD-Rate和时间节省性能
4.2 硬件综合性能
使用UMC 28nm工艺库和Design Compiler进行综合,并与现有的FPGA实现(如Zhao et al. [41])进行了对比:
- 逻辑门数:1,223.2 K
- 芯片面积:0.67 mm²
- 最大频率:471.2 MHz
- 吞吐量:支持8K@89fps实时编码。
如表II所示,在FPGA平台上,本文设计相比Zhao等人的工作,LUTs资源减少了34.39%,DSPs减少了50%以上。更重要的是,处理32×32 TU仅需40个周期(相比竞品的538个周期),体现了全流水线与高并行度的巨大优势。
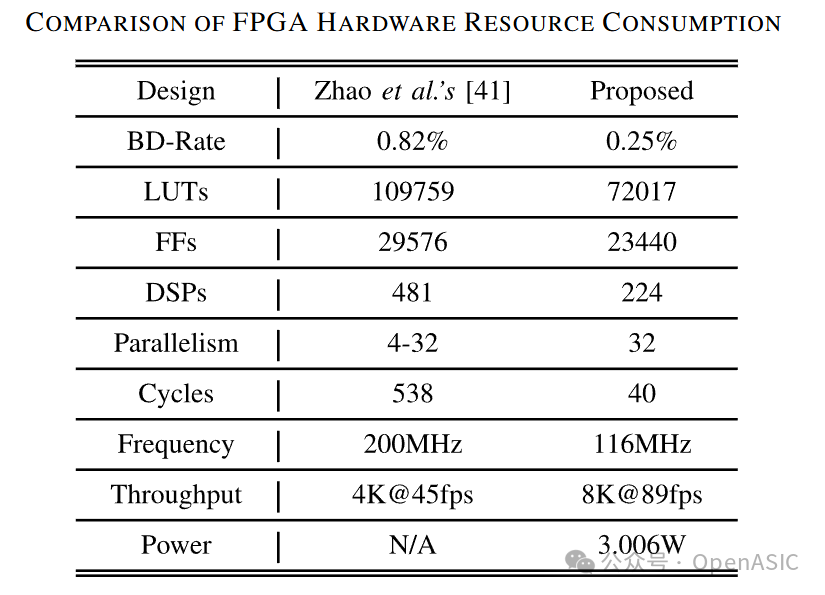
表II:FPGA硬件资源消耗与吞吐量对比
5、结论
本文针对AVS3视频编码标准,提出了一种基于Zig-Zag扫描线级并行的RDOQ算法及全流水线硬件架构。
- 架构创新:设计了九级流水线,通过S7-S9的比较器树将LSC决策延迟从32周期降低至3周期。
- 电路优化:针对率计算设计了三条专用数据通路,并用移位替代乘法,大幅降低了面积。
- 性能卓越:硬件支持32像素/周期的并行度,在471MHz下可实现8K@89fps的实时编码能力。
实验结果比对数据的参考文献如下:
[20] H. Lee, S. Yang, Y. Park, and B. Jeon, "Fast quantization method with simplified rate-distortion optimized quantization for an HEVC encoder," IEEE Trans. Circuits Syst. Video Technol., vol. 26, no. 1, pp. 107–116, Jan. 2016.
[31] M. Xu, T. Nguyen Canh, and B. Jeon, "Simplified level estimation for rate-distortion optimized quantization of HEVC," IEEE Trans. Broadcast., vol. 66, no. 1, pp. 88–99, Mar. 2020.
[38] H. Igarashi et al., "Parallel rate distortion optimized quantization for 4k real-time GPU-based HEVC encoder," in Proc. IEEE VCIP, 2018, pp. 1–4.
[40] J. Xu et al., "Hardware-friendly fast rate-distortion optimized quantization algorithm for AVS3," in Proc. ICDIP, 2022, pp. 593–600.
[41] J. Zhao et al., "Scanline-based fast algorithm and pipelined hardware design of rate-distortion optimized quantization for AVS3," in Proc. IEEE ICCE, 2023, pp. 1–6.
 发表于 2026-1-25 06:34:38
|
查看: 185|
回复: 0
发表于 2026-1-25 06:34:38
|
查看: 185|
回复: 0
