在人工智能的演进历程中,我们正经历从“预测型 AI”向 “自主 Agent(Autonomous Agents)” 的历史性跨越。过去的 AI 更像是被动的响应者,局限于回答问题或生成内容;而现在的 Agent 则是一个拥有感知、决策与执行能力的完整系统,能够主动思考、调用工具并闭环完成复杂任务。为了帮助开发者和产品决策者厘清这一新物种的技术路径,Google 团队发布了权威指南《Introduction to Agents》,将 Agent 的能力划分为 L0 至 L4 五个层级。
一、 Agent 的解剖学架构:模型、工具与编排
要理解 Agent 的能力分级,首先需要拆解其核心架构。Google 将一个标准的 Agent 系统定义为四个核心组件的有机结合:
- 大脑 (The Model): 核心推理引擎。它负责信息处理、选项评估及最终决策。模型的推理能力直接决定了 Agent 的智商上限。
- 双手 (The Tools): 连接数字与物理世界的桥梁。通过工具,Agent 可以访问日历、发送邮件、检索数据库或执行代码。没有工具,Agent 仅仅是一个与世隔绝的聊天机器人。
- 神经系统 (The Orchestration): 编排层,即 Agent 的“管家”。它负责管理思维链 (Chain of Thought)、维护状态记忆 (State),并决定何时调用何种工具。它赋予了 AI 连贯的逻辑与“短期记忆”能力。
- 躯体 (Deployment): 部署环境。这不仅指服务器基础设施,还包含让 Agent 能被用户交互、或被其他 Agent 调用的运行时接口。
二、 Agent 的工作机制:认知-行动闭环
Agent 解决问题的过程并非单次推理,而是一个包含“观察-思考-修正”的递归闭环。
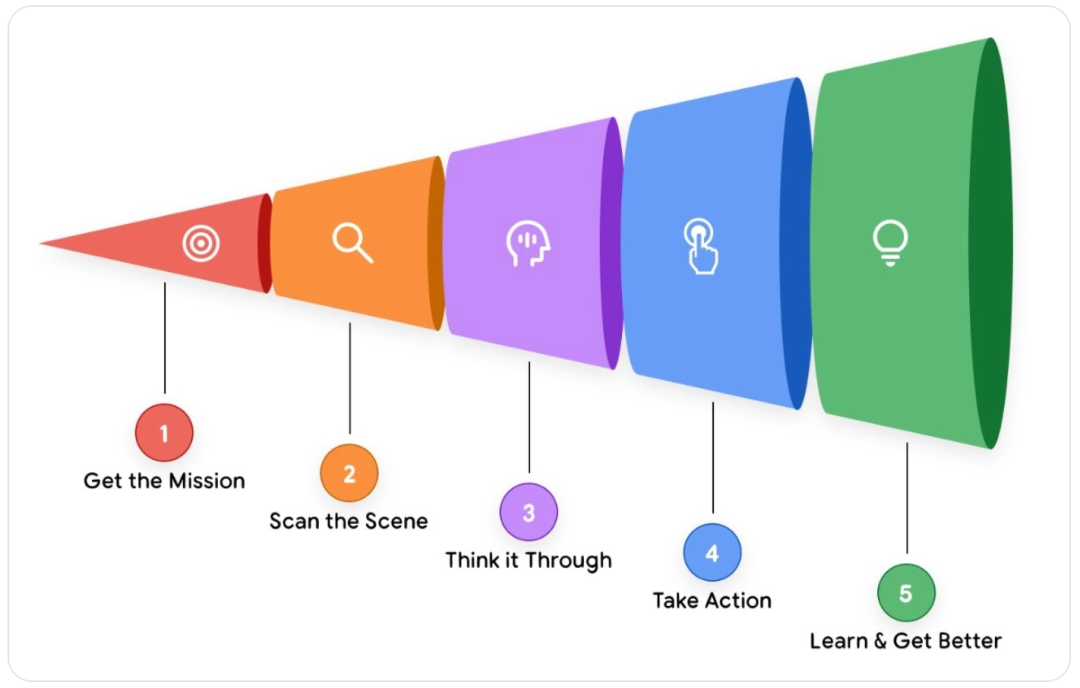
图 1:智能体解决问题的漏斗模型
这一循环通常包含五个关键步骤:
- 接收使命 (Get the Mission): 接收高层级的模糊目标,例如:“帮我安排团队下周的参会行程”。
- 扫描环境 (Scan the Scene): 获取上下文信息。Agent 会检索记忆(“用户之前的偏好是什么?”)并检查可用资源(“我有差旅系统的权限吗?”)。
- 深度规划 (Think It Through): 制定多步骤执行计划。例如:先提取参会名单 -> 再核对日历空档 -> 最后根据预算限制预订机票。
- 采取行动 (Take Action): 执行具体操作。调用 API 查询数据库、读取文档或发送确认邮件。
- 观察与迭代 (Observe and Iterate): 验证执行结果。如果订票失败,Agent 会分析错误日志,修正参数并重新生成计划,直到闭环完成。
三、 Agent 能力分级:从孤岛到自进化
基于自主权(Autonomy)与协作能力(Collaboration)的强弱,Google 将 Agent 的进化路径划分为五层金字塔:
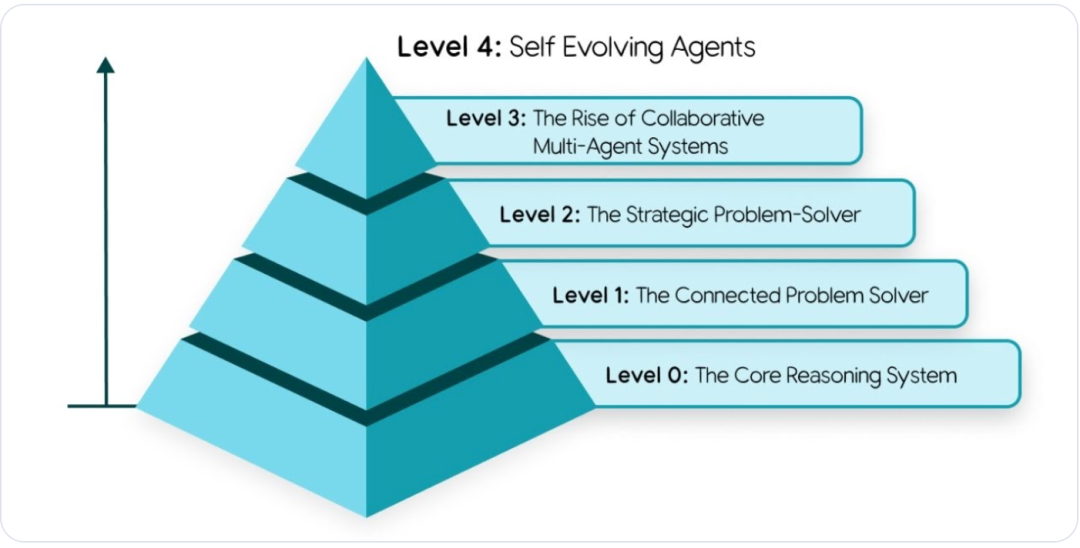
图 2:Google Agent 能力演进金字塔模型
Level 0:核心推理系统 (Core Reasoning System)
这是 Agent 的雏形,本质上是一个无外接能力的“裸模型”。
- 特点: 仅依赖预训练数据(Pre-trained Knowledge)进行问答,无外部工具连接,无长期状态记忆。
- 局限: 处于“盲目”状态。它可以背诵棒球规则,但如果你问“昨晚洋基队的比分是多少?”,它会因无法联网而产生幻觉或表示无能为力。
Level 1:互联型问题解决者 (Connected Problem-Solver)
当“大脑”接驳了“双手”,真正的 Agent 诞生了。
- 特点: 具备 工具调用 (Tool Use) 能力。
- 表现: 面对比分查询,它会判断“需要检索实时信息”,随即调用 Google Search API,获取结果并整合成答案。它能读取实时文档、查询数据库,打破了训练数据的时空限制。
Level 2:策略型问题解决者 (Strategic Problem-Solver)
L2 实现了从“被动执行”到“主动规划”的质变。这一层级需要更精密的 系统架构 来支撑其规划和状态管理能力。
- 核心能力: 具备 上下文工程 (Context Engineering) 与推理规划能力。它能管理注意力焦点,处理复杂的多步骤任务。
- 场景: “在公司和客户办事处之间找一家 4 星以上的咖啡馆”。Agent 会自动拆解任务:计算地理中点(调用地图)-> 搜索周边店铺(调用本地搜索)-> 筛选评分 -> 输出建议。
Level 3:协作式多 Agent 系统 (Collaborative Multi-Agent)
此时,Agent 不再单打独斗,而是演化为“专家团队”。
- 特点: Agent 将其他 Agent 视为工具进行调度。
- 架构: 类似企业组织架构。一个“项目经理 Agent”接收任务,将其拆解并分发给“市场专家 Agent”、“文案 Agent”和“前端开发 Agent”。例如新品发布任务,各子 Agent 分别负责调研、撰稿和页面搭建,最后由主 Agent 验收整合。
Level 4:自我进化系统 (Self-Evolving System)
这是目前 Agent 进化的巅峰:具备 元认知 (Metacognition) 与自我构建能力。
- 特点: 当现有工具或团队无法满足需求时,它能自主构建新的工具或 Agent。
- 表现: 项目经理 Agent 发现缺乏情感分析能力,它会调用“Agent Creator”工具,现场编写提示词与逻辑,生成一个“舆情分析专家 Agent”,经过自动化测试验证后,将其纳入团队投入生产。
四、 开发范式转移:从“搬砖工”到“导演”
在 Agent 时代,开发者的角色发生了根本性转变。过去,开发者是“搬砖工(Bricklayer)”,需要硬编码每一行逻辑;现在,开发者更像是 “导演(Director)”。
导演的核心职责:
- 设定剧本: 编写核心系统提示词(System Prompt)和行为宪法。
- 选角: 为 Agent 配置最合适的工具集(Tools)和 API 权限。
- 背景设定: 注入必要的领域知识库(Knowledge Base)。剩下的演绎,将交由这个具备自主性的“演员”去动态完成。
五、 AgentOps:构建可信赖的智能系统
为了让 Agent 在企业环境中稳定运行,我们需要一套类似于 DevOps 的运维体系,称为 AgentOps。
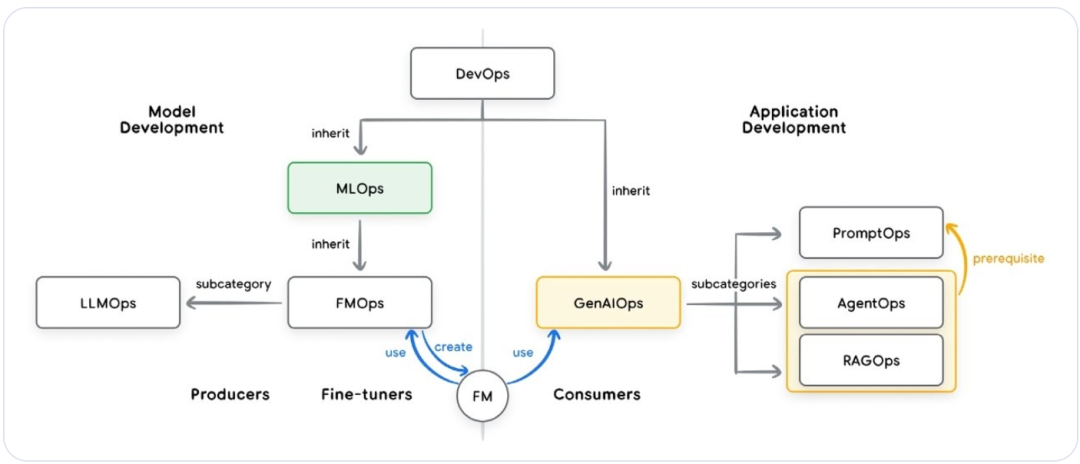
图 3:DevOps、MLOps 与 GenAIOps 的关系
以下是基于来源对 AgentOps 核心组成部分的深度解析:
1. 从“通过/失败”到“质量评估(LM Judge)”
在传统软件中,测试很简单:输出要么等于预期,要么不等于。但在智能体领域,语言是复杂的,答案往往没有唯一标准。
- LM 评委 (LM Judge): 开发者不再使用简单的单元测试,而是使用一个功能更强大的模型(如 Gemini 2.5 Pro)作为“评委”,按照预定义的准则(如:事实准确性、语气是否得体、是否遵循指令)对智能体的输出进行打分。
- 黄金数据集 (Golden Dataset): 为了确保评估的连贯性,需要构建包含理想问题与答案的“黄金数据集”,并由领域专家进行审核。
2. 指标驱动开发(指标驱动开发)
AgentOps 强调衡量真正重要的业务指标,而不仅仅是技术指标。
- KPI 体系: 评估不仅看回复是否正确,还看任务完成率、用户满意度、单次交互成本以及对业务目标(如收入或留存率)的实际贡献。
- 部署决策 (Go/No-Go): 在发布新版本前,通过在整个评估数据集上运行测试,将新旧版本的得分进行直接对比,从而消除猜测,确保每一次迭代都是进步的。
3. 使用 OpenTelemetry 进行深度调试
当智能体表现异常时,开发者需要回答“为什么”。
- 追踪 (Traces): AgentOps 利用 OpenTelemetry 标准记录智能体的“思维轨迹(Trajectory)”。
- 全过程透明化: 通过 Trace,你可以看到发送给模型的精确提示词、模型内部的推理过程、它选择调用的工具、生成的参数以及观察到的原始返回数据。这让调试不再是开“黑盒”,而是像查看代码运行日志一样清晰。
4. 闭环的人类反馈 (Human Feedback)
AgentOps 将人类反馈视为最宝贵的资源,而非干扰。
- 疫苗效应: 当用户点击“踩”或提交错误报告时,AgentOps 流程会捕获这个真实的边缘案例,将其转化为评估数据集中的一个永久测试用例。这样做不仅修复了当前的错误,还“接种了疫苗”,确保系统以后再也不会犯同类错误。
5. 持续进化的操作框架
智能体的开发更像是在“导演”一场戏,而不是“搬砖”盖房。
- 模型路由与升级: AgentOps 建立了一套灵活的框架,可以根据任务复杂度自动路由到不同的模型(如复杂的任务给 Pro,简单的给 Flash),并能在新模型出现时快速进行评测和无缝替换,而无需重构整个系统架构。
- 环境治理: 在企业级应用中,AgentOps 还负责管理智能体的身份(Agent Identity)、权限控制以及防止“智能体乱象(Agent Sprawl)”的中心化治理。
AgentOps小结
为了让你更直观地理解 AgentOps,可以参考这个比喻:如果开发传统软件像是在编写一个计算器,你只需要通过点击按钮测试 1+1 是否等于 2;那么 AgentOps 就像是在执教一支足球队。你无法精准预判球员在场上的每一个动作,但你可以通过制定战术手册(提示词工程)、提供专业装备(工具集成)、录像回放分析(Trace 追踪)以及根据比赛结果调整训练计划(反馈闭环),来确保球队最终能赢得比赛。
六、 L4 有多强?前沿案例:算法进化论
AlphaEvolve (算法进化 Agent)
这是 L4 级“自我进化”能力的巅峰体现。AlphaEvolve 不仅仅是写代码,它是在进行自主科学发现(Agentic Discovery)。它将大模型的创造力与进化算法的筛选机制相结合,解决连人类专家都束手无策的算法难题。
- 核心机制:双脑驱动的“数字达尔文主义” AlphaEvolve 的工作方式模仿了生物进化论,由两款不同特性的 Gemini 模型协同驱动:
- 发散(Variation): 使用速度极快的 Gemini Flash 作为“变异引擎”,快速生成大量代码变体,探索广泛的可能性空间。
- 深思(Refinement): 使用推理能力更强的 Gemini Pro 作为“优化引擎”,对有潜力的方案进行深度修改和逻辑完善。
- 自然选择(Selection): 所有生成的算法都会被投入一个严苛的自动化评估环境(Evaluator),只有表现超越上一代的代码才能“存活”下来,成为下一代进化的父本。
- 震撼业界的成就:
- 打破 56 年数学记录: 在矩阵乘法领域,它自主发现了一种针对 4x4 矩阵的新算法,仅需 48 次乘法运算(此前人类保持了 56 年的记录是 49 次),直接改写了基础数学教科书。
- 优化全球基础设施: 它重写了 Google 数据中心(Borg)的任务调度算法。这个由 AI 发明的简短启发式算法,为 Google 节省了 0.7% 的全球计算资源——在大规模算力时代,这笔节省是天文数字。
- 反哺 AI 自身: 它甚至优化了 TPU 芯片的底层 Verilog 电路设计,并将 Transformer 模型中的 FlashAttention 内核速度提升了 32.5%,从而让下一代 AI 的训练速度更快。
本质区别: 传统的 Copilot 是帮你写出已知的算法,而 AlphaEvolve 是帮你发现未知的算法。
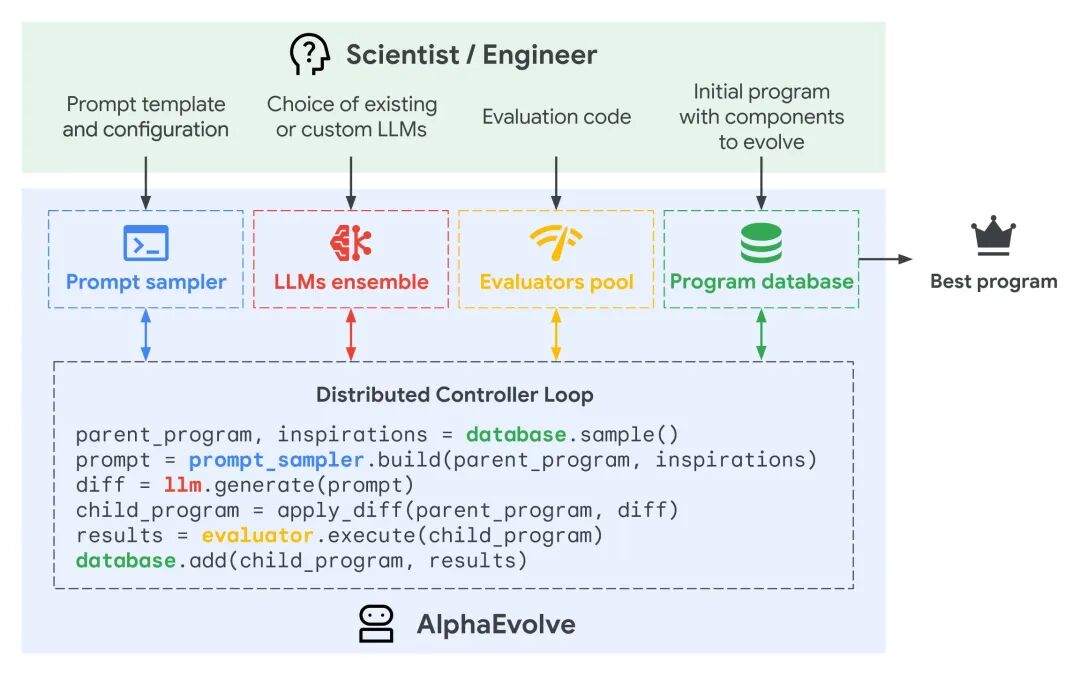
AlphaEvolve 系统架构图
AlphaEvolve 为发现更快矩阵乘法算法提出的变更列表。在本例中,AlphaEvolve 提出了对多个组件进行大规模变更,包括优化器和权重初始化、损失函数以及超参数扫描。这些变化非常不简单,进化过程中需要 15 次突变。
AlphaEvolve 代码进化过程截图
七、 总结:你的新队员已就位
Agent不再只是软件,它们正在成为我们团队中“灵活、博学且不知疲倦的新成员”。
通过 Google 的这套分级体系,我们可以清晰地看到 AI 是如何一步步从“书呆子”变成“全能管家”的。未来的成功不在于你写了多长的 Prompt,而在于你如何构建这一套严谨的架构。对深度学习和 AI 系统架构感兴趣的开发者,可以在 云栈社区 的 人工智能 和 后端 & 架构 板块找到更多深度讨论与资源。
最后送大家一个比喻: 如果传统的软件是一个必须按轨道行驶的火车,那么智能体就像是一辆配备了顶级导航员的自动驾驶赛车。你只需要告诉它终点在哪里(使命),它会自己观察天气(扫描环境)、规划最佳路线(深度思考)、控制油门转向(采取行动),并在遇到封路或意外时,灵活地绕行或调整方案(观察迭代),直到把你安全送到目的地。
引用
- Julia Wiesinger, Patrick Marlow, et al. 2024 “Agents”. Available at: https://www.kaggle.com/whitepaper-agents.
- Antonio Gulli, Lavi Nigam, et al. 2025 “Agents Companion”. Available at: https://www.kaggle.com/whitepaper-agent-companion.
- Shunyu Yao, Y. et al., 2022, 'ReAct: Synergizing Reasoning and Acting in Language Models'. Available at: https://arxiv.org/abs/2210.03629.
- Wei, J., Wang, X. et al., 2023, 'Chain-of-Thought Prompting Elicits Reasoning in Large Language Models'. Available at: https://arxiv.org/pdf/2201.11903.pdf.
- Shunyu Yao, Y. et al., 2022, 'ReAct: Synergizing Reasoning and Acting in Language Models'. Available at: https://arxiv.org/abs/2210.03629.
- https://www.amazon.com/Agentic-Design-Patterns-Hands-Intelligent/dp/3032014018
- Shunyu Yao, et. al., 2024, ‘τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains’, Available at: https://arxiv.org/abs/2406.12045.
- https://artificialanalysis.ai/guide
- https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/vertex-ai-model-optimizer
- https://gemini.google/overview/gemini-live/
- https://cloud.google.com/vision?e=48754805&hl=en
- https://cloud.google.com/speech-to-text?e=48754805&hl=en
- https://medium.com/google-cloud/genaiops-operationalize-generative-ai-apractical-guide-d5bedaa59d78
- https://cloud.google.com/vertex-ai/generative-ai/docs/agent-engine/code-execution/overview
- https://ai.google.dev/gemini-api/docs/function-calling
- https://github.com/modelcontextprotocol/
- https://ai.google.dev/gemini-api/docs/google-search
 发表于 2026-1-25 17:09:43
|
查看: 242|
回复: 0
发表于 2026-1-25 17:09:43
|
查看: 242|
回复: 0
