如果你经常用大模型处理正经工作——比如分析整个代码仓库、归纳成百上千份文档、进行长周期研究,或者试图把一整年的聊天记录一次性扔给模型——那你一定撞到过同一面南墙:上下文不够用。
即便最前沿的大模型,其上下文窗口已扩展到几十万甚至上百万 token,看起来非常唬人。可一旦内容过长、任务复杂度提升,模型立刻开始健忘、走神、胡编乱造,陷入所谓的“上下文腐烂”(Context Rot)困境。
最近,MIT CSAIL 的研究团队发表了一篇论文,提出了一种反直觉但极其优雅的解法:他们不再试图“扩大上下文窗口”,而是选择直接“绕开”它。这项研究在 云栈社区 的技术讨论区也引发了广泛关注。他们开创了一个新范式——Recursive Language Models(递归语言模型,RLM)。

用一句话概括其核心思想:不是让模型一次性“读完所有内容”,而是教会模型如何“反复翻书、分块思考、递归调用自己”。
核心问题:不只是“上下文太短”
论文开篇便点破了一个常被行业忽视的现实:大模型的有效上下文长度,远小于其标称的最大上下文长度。
更致命的是,上下文越长、任务越复杂,模型的性能崩溃得越快。
- 完成“在草堆里找一根针”(Needle-in-a-Haystack)这类简单检索任务,模型尚能应付。
- 需要进行整篇文档的综合理解与判断时,性能开始明显退化。
- 当任务要求“几乎每一行信息都参与推理”时,模型的表现直接翻车。
作者将这种现象总结为 Context Rot(上下文腐烂)——问题的根源并非模型不够聪明,而是注意力机制在长距离、高密度信息中出现了系统性的失效。
因此,真正要解决的难题不是 “如何塞进更多 token?”,而是:“模型凭什么要一次性记住所有东西?”
RLM:一个充满“程序员思维”的解决方案
核心思想:将“长文本”视为环境,而非输入
传统 LLM(大语言模型) 的工作方式是线性的:收集所有内容 -> 塞进 prompt -> 一次性计算完毕。
RLM 则完全颠覆了这个流程:超长文本本身不进入模型,而是被放置在“外部环境”中。
那么具体如何实现呢?论文中的实现方式相当克制,甚至显得有些“朴素”:
- 启动一个 Python REPL 环境。
- 将超长文本作为一个变量
P 存储在该环境中。
- 告知模型:文本有多长,并且你可以通过编写代码来查看、切分、搜索它。
- 关键一步:模型通过编写代码来“操作文本”,而不是直接“读取文本”。
- 在必要时,模型可以递归调用另一个模型实例(或自身)来处理分解出的子任务。
你可以将 RLM 理解为一个会写代码、会拆解任务、还能不断“自我分身”进行协作的大模型。
与“总结 / RAG / Agent”的本质区别
论文对现有主流的长文本处理方案进行了犀利点评:
-
总结式压缩(Summarization)是有害的
总结行为默认了一个前提:某些细节可以被遗忘。但在高信息密度的复杂任务中,这个前提往往不成立,丢失的细节可能就是关键。
-
检索增强生成(RAG)只能解决“找得到”,解决不了“算得对”
许多复杂任务并非简单的信息检索,而是要求对几乎所有文本进行组合、变换、对齐和交叉验证,RAG 对此力不从心。
-
传统智能体(Agent)仍受限于上下文窗口
即使它能进行多轮模型调用,本质上依然是在有限的 token 空间内“打转”。
而 RLM 的关键突破在于:上下文的管理策略,不再由预设的系统规则或工程架构决定,而是交由模型根据任务动态决定。
模型可以自主规划:先用正则表达式过滤无关信息,再将文本合理分块,然后递归调用自身处理子块,接着验证中间结果,最后拼接出最终答案。它本质上不是在“阅读”文本,而是在“编程式地操作”文本环境,这代表了一种更高阶的 人工智能 推理能力。
实际效果如何?
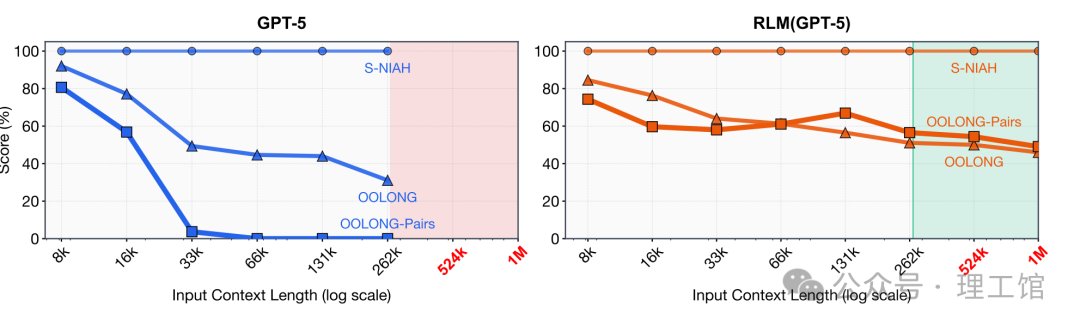
论文将 RLM 与强大的 GPT-5 进行了正面比较。
在超长输入场景(百万至千万级 token)下:
- 原生 GPT-5:要么因超出窗口限制而无法处理,要么性能呈断崖式下跌。
- 基于 GPT-5 构建的 RLM:
- 能够稳定处理 1000 万+ token 的输入。
- 在多个高难度长上下文任务上,性能提升最高达 2 倍。
- 每次查询的成本相当甚至更低。
尤其在 OOLONG-Pairs 这类要求“几乎每一行都参与推理”的极端任务上:
- 原生模型的表现近乎于零(F1 ≈ 0)。
- RLM 直接将性能提升至 58%。
这已经超越了简单的“性能优化”,堪称模型能力层级的跃迁。
可能带来的深远影响
这篇论文最厉害之处在于,它不是一个针对特定基准测试的“技巧”,而是一个可能引发系统范式变革的构想。
-
真正可用的“超长文本研究型 AI”
- 全量法律文书审查与分析
- 企业级全代码库的理解与重构
- 科研级别的海量文献整合与综述
- 长周期的财务审计与事件调查
这些以往必须依赖“人类专家+复杂工具链”才能完成的工作,开始有可能被单个模型系统攻克。
-
“上下文窗口”参数的战略意义可能减弱
长期以来,上下文窗口大小是模型厂商竞争的核心参数之一。RLM 这类范式如果成熟,可能使该参数逐渐失去战略决定性。相反,模型的推理策略、递归能力和环境交互水平将成为新的技术分水岭。
-
智能体(Agent)的设计逻辑将被重写
未来的高级智能体,可能不再是“多轮对话+工具调用”的简单组合,而是一个会编写程序、能调度自身计算资源、懂得管理信息密度的复杂推理系统。这触及了 计算机科学 中关于程序与逻辑的核心。
论文作者也诚实地指出了当前 RLM 的局限性:
- 推理路径可能存在不稳定性,单次查询成本波动较大。
- 当前的模型并非为 RLM 范式“专门训练”,其递归调用能力源自通用能力的涌现。
- 递归深度控制、并行化处理、异步执行等高级特性尚未得到系统探索。
但正是这些未竟之处,指明了巨大的探索空间。这很可能标志着 “推理即程序”(Reasoning as Programming) 理念又一次扎实的落地实践。其核心启示在于:AI 的下一步突破,或许不在于构建更大的模型,而在于探索如何更聪明地使用模型。
 发表于 2026-1-25 17:05:00
|
查看: 251|
回复: 0
发表于 2026-1-25 17:05:00
|
查看: 251|
回复: 0
