灰度发布与 A/B 测试核心方案
你有没有遇到过这种情况:辛辛苦苦开发了一个新功能,上线后却发现严重 bug,只能紧急回滚?或者信心满满地全量发布,结果告警狂响,用户投诉刷屏?
在支撑过数十个高并发项目后,我们可以明确一点:所有稳定的系统,都不是靠“一把梭哈”上线的。它们的秘诀在于两个核心策略:灰度发布和AB测试。
听着像玄学?其实它们的逻辑很简单,就像炒菜前先尝一口:
- 灰度发布是“保命模式”,看看会不会中毒(系统崩不崩)。
- A/B 测试是“增长引擎”,看看好不好吃(用户买不买账)。
今天我们就来深入探讨:灰度发布 vs A/B 测试,到底有什么区别?如何落地实现?为什么每个生产级系统都必须掌握它们?
虽然都是小范围测试,但二者的目标截然不同,就像两个不同工种的工人:
- 灰度发布是运维型思维——关心的是“系统稳不稳”,核心目标是降低上线风险。
- A/B 测试是产品型思维——关心的是“用户喜不喜欢”,核心目标是验证业务假设、提升转化率。
灰度发布与 A/B 测试 ,二者核心差异在哪?
很多同学一上来就埋头搞分流、写路由代码,最后可能发现方向错了。请先记住一句话:
- 灰度发布 = 保命通道
- A/B 测试 = 数据军火库
具体来说:
- 你要上线一个新版本,怕出问题?——用灰度发布。
- 你想知道按钮放左边还是右边转化更高?——用A/B 测试。
一个是运维思维,盯着监控面板;一个是产品思维,盯着数据报表。千万别把它们混为一谈。
核心差异对比
| 维度 |
灰度发布 |
A/B 测试 |
| 主要目的 |
验证系统稳定性,防止大规模故障 |
验证用户行为偏好,优化产品设计 |
| 关注指标 |
错误率、响应时间、CPU 使用率等技术指标 |
点击率、转化率、停留时长等业务指标 |
| 流量控制依据 |
内部标识(如灰度标签、IP 段、Header) |
用户属性(如地域、设备、登录状态) |
| 是否需要统计分析 |
不需要,重点是监控告警 |
必须,要进行数据对比和显著性检验 |
| 持续时间 |
较短(几小时到一两天) |
较长(几天到几周) |
| 是否支持快速回滚 |
必须支持 |
一般不强调,更注重实验完整性 |
流量切分逻辑与关注指标对比
| 对比维度 |
灰度发布 + 快速回滚 |
A/B 测试 |
| 核心目标 |
新功能别炸!确保系统稳定上线 |
哪个版本更赚钱?选转化最高的方案 |
| 流量逻辑 |
渐进式放量:5% → 20% → 50% → 全量 |
固定分组、长期并行,用户A永远看版本A |
| 关注指标 |
技术指标:错误率、延迟、CPU使用率 |
业务指标:点击率、转化率、留存率 |
| 结束条件 |
出错就立即回滚,恢复老版本 |
数据收集充分后决策,优胜劣汰 |
| 技术重点 |
快速流量切换、秒级回滚、多版本共存 |
用户标签、精准埋点、无偏统计、多组实验 |
简单总结:
灰度发布 = 控制风险,能随时撤退
A/B 测试 = 收集证据,选出最优方案
灰度发布与 A/B 测试的基本流程逻辑
下面这张图清晰地展示了从用户请求进入网关开始,到完成灰度发布或A/B测试决策的完整流程逻辑。
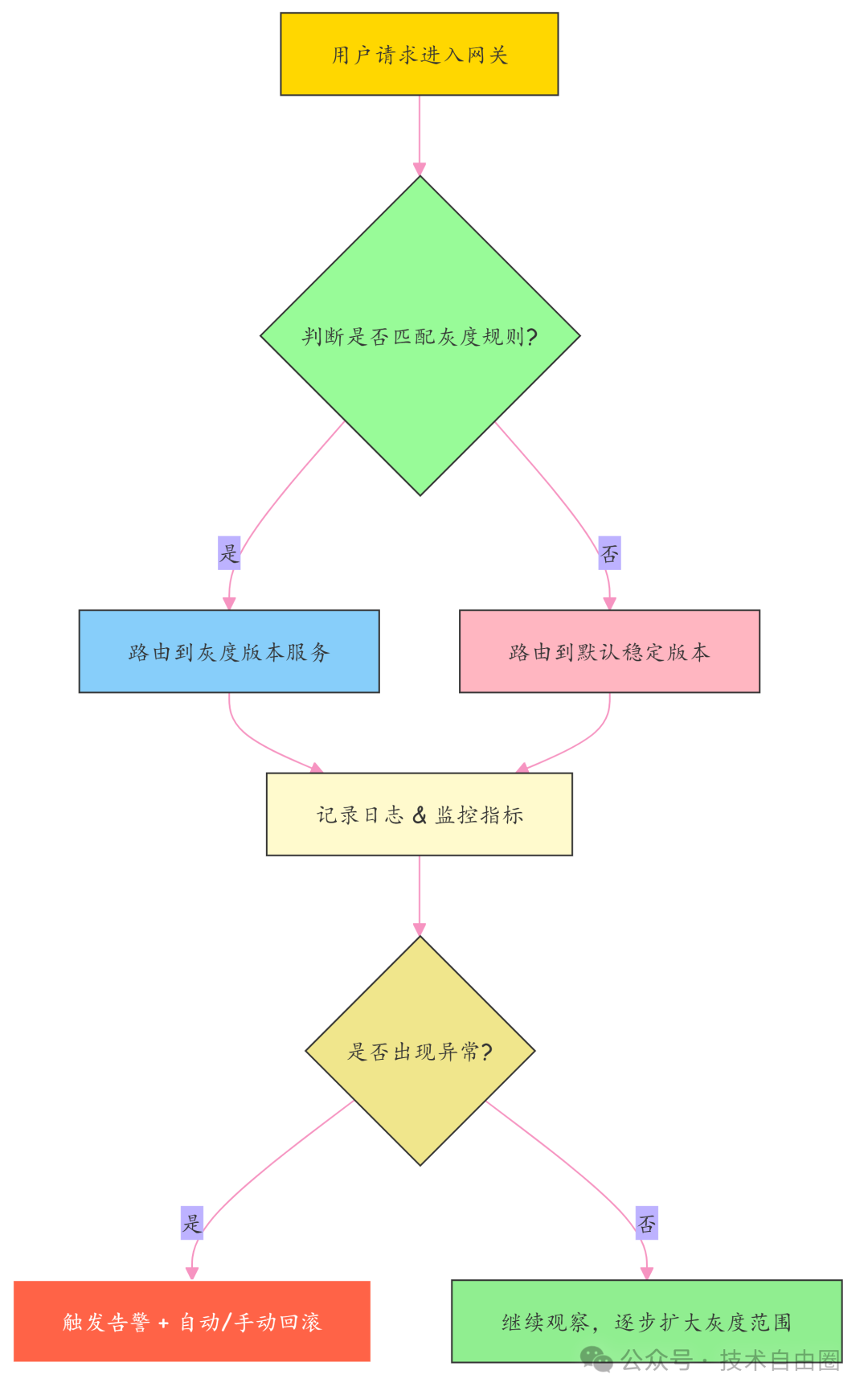
记住核心:
上线不怕出事,靠的是灰度;产品不怕做错,靠的是 A/B 测试。架构师的价值,就是把“不确定”变成“可控”。
目标导向决定一切
- 灰度发布是“保命模式”:它的第一使命是防止新代码把线上搞崩。哪怕新功能再炫,只要核心指标(如P99延迟)恶化,就必须立刻回滚。
- A/B 测试是“增长引擎”:它不怕小毛病,怕的是选错方向。即使某个版本性能稍差,但若能带来10%的转化率提升,也可能成为最终选择。
流量控制方式不同
- 灰度发布通常是按比例递增放量,这是一个阶段性、单向推进的过程。
第一步:5% 用户走新版本(观察)
第二步:没问题 → 放到20%
第三步:继续验证 → 到50%
第四步:确认安全 → 全量切换
- A/B 测试则是固定分组、长期并行,以保证用户体验和数据一致性。
用户A(ID尾号奇数)→ 一直看版本A
用户B(ID尾号偶数)→ 一直看版本B
回滚 vs 决策
- 灰度发布一旦发现错误率飙升、超时增多,立即触发自动回滚机制,保障服务可用性是第一要务。
- A/B 测试不会轻易“回滚”,即使某个版本表现差,也会等实验周期结束、数据充分后,由产品或数据团队基于分析结果做出决策。
二者可以结合使用吗?当然可以!
现实中,更聪明的做法是:先灰度发布验证稳定性,再开启A/B测试比拼效果。
举个例子:
你上线了一个新的推荐算法。
第一步:灰度发布给5%用户,监控服务是否扛得住(CPU、内存、错误率)。
第二步:确认稳定后,再对这5%用户做A/B测试,比较新旧算法的点击率。
第三步:数据达标 → 扩大灰度范围 → 再次A/B测试 → 最终全量。
这就叫“稳中求胜”。
核心流程图
下面这张图,清晰展示了新版本上线后,选择灰度发布或A/B测试两种策略的核心路径和关键决策节点。
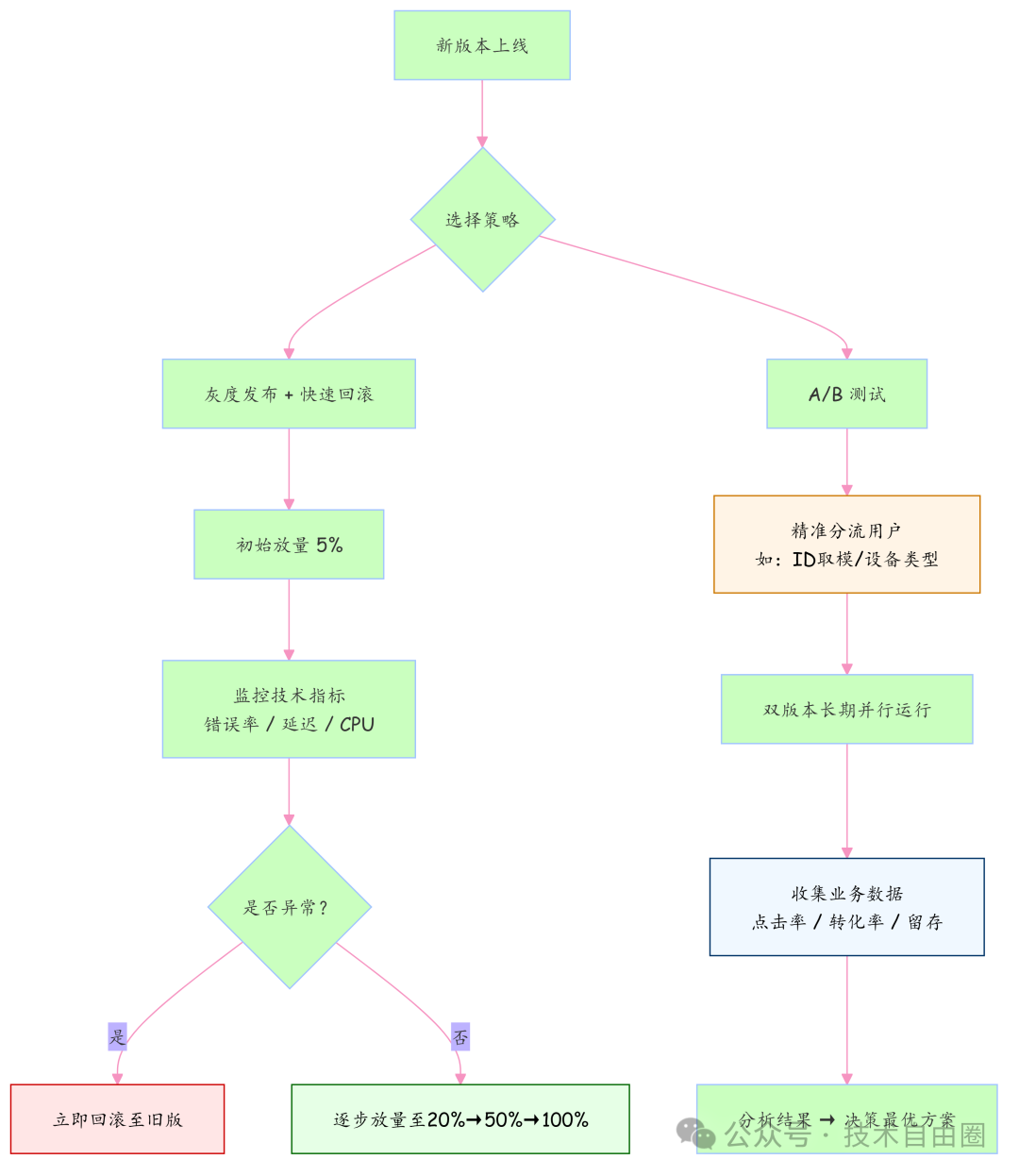
总结一句话:灰度发布是为了“不出事”,A/B 测试是为了“赚更多”。
一个管“技术稳定”,一个管“业务增长”;一个随时准备撤退,一个耐心等待数据说话。分清它们的本质,才能在架构设计中合理选用,甚至组合出击。
二、应用网关层灰度发布 + 快速回滚方案(Spring Cloud + Nacos)
写多了代码的小伙伴都知道:辛辛苦苦开发一个月的新功能,点下发布按钮那一刻,手都在抖——“这玩意儿会不会炸?”
别慌。今天我们就来搞一套生产级灰度发布 + 秒级回滚方案,让你上线像呼吸一样自然。这套方案基于 Spring Cloud Gateway + Nacos 的组合,纯配置驱动、零重启、可追溯、能兜底,是经过高并发场景验证的硬核实践。
应用网关层灰度发布三板斧
想象一下你要推出一道新菜。聪明的做法不是全店上线,而是先让10%的顾客尝鲜,看反馈和后厨压力,一旦有问题立马撤下。这就是灰度发布的精髓。
实现它,我们靠“三板斧”组合拳:
网关分流 + Nacos动态改规则 + 全链路监控兜底
1. 多版本服务部署 —— 新旧并行,物理隔离
不要做“替换式升级”。我们的做法是:v1.0 和 v2.0 同时跑,通过K8s的Label实现物理隔离。
- v1.0:稳定版,label 是
version=1.0
- v2.0:灰度版,label 是
version=2.0
好处是什么?即使 v2 出问题,v1 还稳稳地撑着大盘子,用户完全无感知。
核心原则:永远不要让你的新版本,成为整个系统的单点故障源。
2. 网关层流量切分 —— 用“用户ID”当骰子
真正的控制权在 Spring Cloud Gateway 手里。我们写一个自定义全局过滤器,拦截所有请求,根据策略决定路由去向。
分流规则设计:比例 + 白名单
- 按比例放量:比如当前只放 10% 流量进 v2.0
- 白名单优先:内部员工、测试同学强制走新版本,方便验证
具体做法:拿用户的 userId 来“掷骰子”。
比如 userId = 123456
哈希取模:Math.abs("123456".hashCode()) % 100 = 78
如果结果 < 当前灰度比例(比如10),进 v2;否则走 v1。
关键点:同一个用户,应始终命中同一版本,保证体验一致性。
自定义路由过滤器代码示例:
@Component
public class GrayReleaseFilter implements GlobalFilter, Ordered {
@Autowired
private ConfigService configService; // Nacos 配置客户端
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
String userId = getUserId(exchange); // 从请求头或 token 中提取用户ID
if (userId == null) {
return chain.filter(exchange); // 没有用户信息,走默认路由
}
try {
// 从 Nacos 动态获取灰度配置(JSON格式)
String config = configService.getConfig("gray-release-config", "DEFAULT_GROUP", 5000);
JSONObject configObj = JSON.parseObject(config);
int grayPercent = configObj.getIntValue("grayPercent"); // 灰度百分比,如10%
JSONArray whiteList = configObj.getJSONArray("whiteList"); // 白名单用户ID列表
// 规则1:白名单用户优先,直接走新版本
if (whiteList != null && whiteList.contains(userId)) {
return routeToVersion(exchange, chain, "2.0");
}
// 规则2:按哈希取模决定是否进入灰度
int hash = Math.abs(userId.hashCode()) % 100;
if (hash < grayPercent) {
return routeToVersion(exchange, chain, "2.0");
}
} catch (Exception e) {
// 异常时降级:走稳定版,防止雪崩
log.warn("灰度配置加载失败,降级到v1.0", e);
}
// 默认走老版本
return routeToVersion(exchange, chain, "1.0");
}
private Mono<Void> routeToVersion(ServerWebExchange exchange, GatewayFilterChain chain, String version) {
// 修改请求路径或 header,供下游服务识别版本
exchange.getRequest().mutate()
.header("X-Service-Version", version)
.build();
// 或者修改路由目标(需配合 Predicate 使用)
exchange.getAttributes().put("org.springframework.cloud.gateway.support.ServerWebExchangeUtils.GATEWAY_PREDICATE_ID_ATTR", "user-service-" + version);
return chain.filter(exchange);
}
private String getUserId(ServerWebExchange exchange) {
// 示例:从请求头中获取
String token = exchange.getRequest().getHeaders().getFirst("Authorization");
if (token != null && token.startsWith("Bearer ")) {
// 解析 JWT 获取 userId(简化处理)
return parseUserIdFromToken(token.substring(7));
}
return null;
}
@Override
public int getOrder() {
return -100; // 优先于大多数过滤器执行
}
}
关键点说明:
- 利用 Nacos 实时拉取配置,不用重启也能调策略。
userId.hashCode() % 100 保证同用户始终命中同一版本。- 出现异常?自动降级到 v1.0,绝不拖垮系统。
生产级代码准则:永远假设配置会读失败、网络会超时。加上降级逻辑,才是合格的代码。
3. Nacos 动态配置 —— 不重启,随时调比例
以前改配置得打包、发版、重启。现在完全不需要!我们把灰度参数放在 Nacos 配置中心里,格式如下:
{
"grayPercent": 10,
"whiteList": ["user1001", "admin-test"]
}
只要在 Nacos 控制台修改 grayPercent 的值,网关就能实时感知变化(配合监听机制)。
- 第一天:5% 用户尝鲜 → 观察监控
- 第三天:没问题 → 改成 20%
- 第五天:全量上线 → 改成 100%
整个过程,零重启、零停机、平滑过渡。
4. 快速回滚机制 —— 紧急逃生通道
再稳的系统也可能翻车,所以必须设置“紧急逃生通道”。我们准备三条退路,按速度排序:
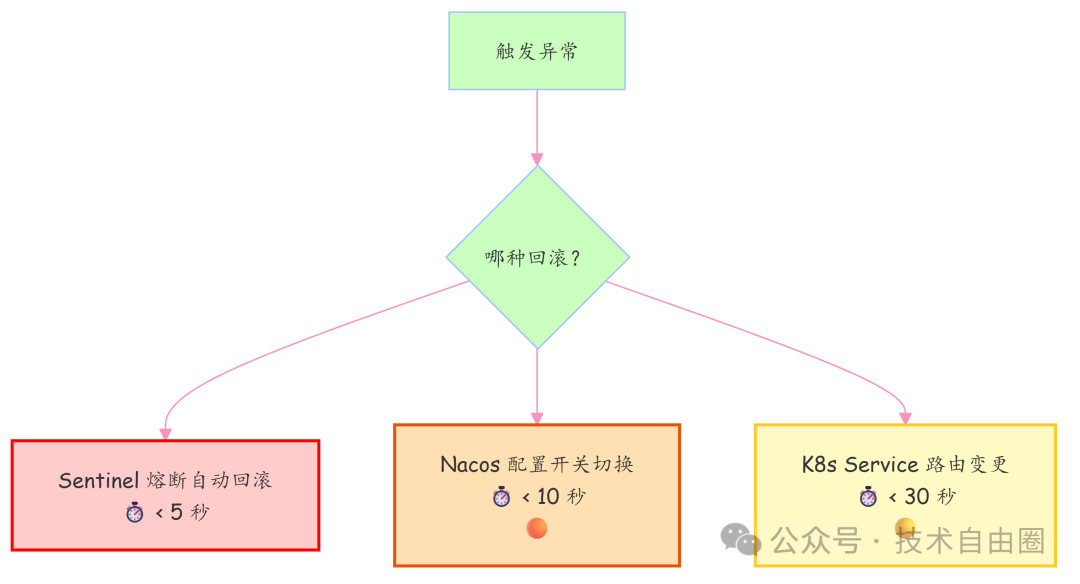
Sentinel 熔断回滚(最快)
接入 Sentinel,在关键接口设熔断规则(如错误率 > 5%),自动切断对 v2 的调用,请求全部 fallback 到 v1 接口。响应时间:< 5 秒。
@SentinelResource(value = "userService/getProfile",
blockHandler = "handleBlock",
fallback = "fallbackGetProfile")
public UserProfile getProfile(String uid) {
// 调用 v2 版本逻辑
}
public UserProfile fallbackGetProfile(String uid, Throwable t) {
// 回退到调用 v1 接口
return userServiceV1.getProfile(uid);
}
Nacos 配置开关(最常用)
最简单的办法:把 Nacos 中的 grayPercent 直接改成 0。下次网关读配置,就不会再转发任何请求到 v2。成本低、操作快。
K8s Service 切换(兜底大招)
遇到严重事故(如内存泄漏),直接修改 K8s Service 的 selector,只选择 v1.0 的 Pod,将 v2.0 彻底隔离。
# service.yaml
selector:
app: user-service
version: "1.0" # ← 只选 v1.0,v2.0 彻底隔离
一句话总结:回滚方式越多,心里越踏实。别把鸡蛋放在一个篮子里。
5、小结:为什么选“网关层灰度”?
| 维度 |
优势 |
| 实施成本 |
不需要改 K8s Ingress,开发即可搞定 |
| 精准控制 |
可基于用户、设备、地域等维度分流 |
| 快速迭代 |
配置驱动,分钟级调整策略 |
| 安全回滚 |
多重保险机制,不怕翻车 |
适用场景:业务逻辑复杂、需精细控制流量、强调用户体验的产品型项目(如电商、社交App)。
三、应用网关层 A/B 测试方案
新功能上线后,老板问:“转化率涨了吗?”结果一查数据,不升反降。这时候才后悔没有先做小范围实验。
所以,我们要用数据说话——A/B 测试搞起来!本质是:把用户分成几组,给他们看不同的版本,然后对比效果。
系统层面的做法是:
用户请求 → 网关根据用户标签决定访问哪个版本 → 记录行为数据 → 对比分析得出最优解。
整个过程依赖四个核心组件:用户标签系统、规则引擎、埋点统计、动态开关。
1. 用户标签获取:识别用户身份
要想精准分组,得先了解用户。通常从两个地方获取用户标签:
- 用户中心服务:实时调用接口查询(适合少而精的数据)。
- Redis 缓存:提前缓存常用标签(性别、城市、会员等级),查询更快。
// 模拟从 Redis 获取用户标签
String userId = request.getHeader("X-User-ID");
String userTagsJson = redisTemplate.opsForValue().get("user:tags:" + userId);
// 解析成对象
UserTags tags = JSON.parseObject(userTagsJson, UserTags.class);
建议:高频访问的标签一定要缓存,避免拖慢网关响应速度。
2. 规则引擎分流:决定实验分组
有了用户标签,下一步就是“分配任务”。这依靠规则引擎来判断,就像一个“智能闸机”。
| 常见的规则示例: |
条件 |
分流目标 |
| 年龄 18-25 且 性别=女 |
走新页面样式(B 组) |
| 地域=北京、上海、深圳 |
参与新按钮测试 |
| 其他所有人 |
默认走老版本(A 组) |
如果没匹配上任何规则?那就随机分配一组,保证样本均衡。
public String determineVersion(HttpServletRequest request) {
// 1. 获取用户标签
String userId = request.getHeader("X-User-ID");
UserTags tags = getUserTagsFromCache(userId);
if (tags == null) {
return "default"; // 没有标签,默认走老版
}
// 2. 匹配规则:18-25岁女性走新版
if ("female".equals(tags.getGender())
&& tags.getAge() >= 18
&& tags.getAge() <= 25) {
return "new_version";
}
// 3. 兜底:随机分配(50%概率)
return Math.random() < 0.5 ? "default" : "new_version";
}
提示:实际项目中可使用 Drools 或自研轻量规则引擎,支持动态配置,无需改代码。
3. 埋点统计:记录用户行为
关键动作处必须“埋点”记录,以衡量转化效果。
前端埋点示例:
ga('send', 'event', 'homepage_button_click', {
version: 'B', // 当前用户看到的是B版本
userId: '12345',
timestamp: Date.now()
});
后端记录示例(发送到Kafka):
Map<String, Object> event = new HashMap<>();
event.put("eventType", "order_placed");
event.put("userId", userId);
event.put("version", assignedVersion); // A 或 B
event.put("timestamp", System.currentTimeMillis());
kafkaTemplate.send("ab_test_events", event);
数据最终汇总到大数据平台(如 Hive, ClickHouse),通过BI工具分析得出结论。
4. 测试管控与终止:动态开关
实验不能无限期进行,需要一个“遥控器”随时关闭。Nacos 配置中心再次派上用场。
在 Nacos 中配置开关:
ab_test:
enabled: true
experiment_name: "homepage_redesign"
winner_version: "" # 暂时空着,等结果出来再填
网关定时拉取配置,一旦发现 enabled: false,立刻停止分流,所有人回归默认版本。下面流程图展示了网关层的A/B测试分流逻辑。
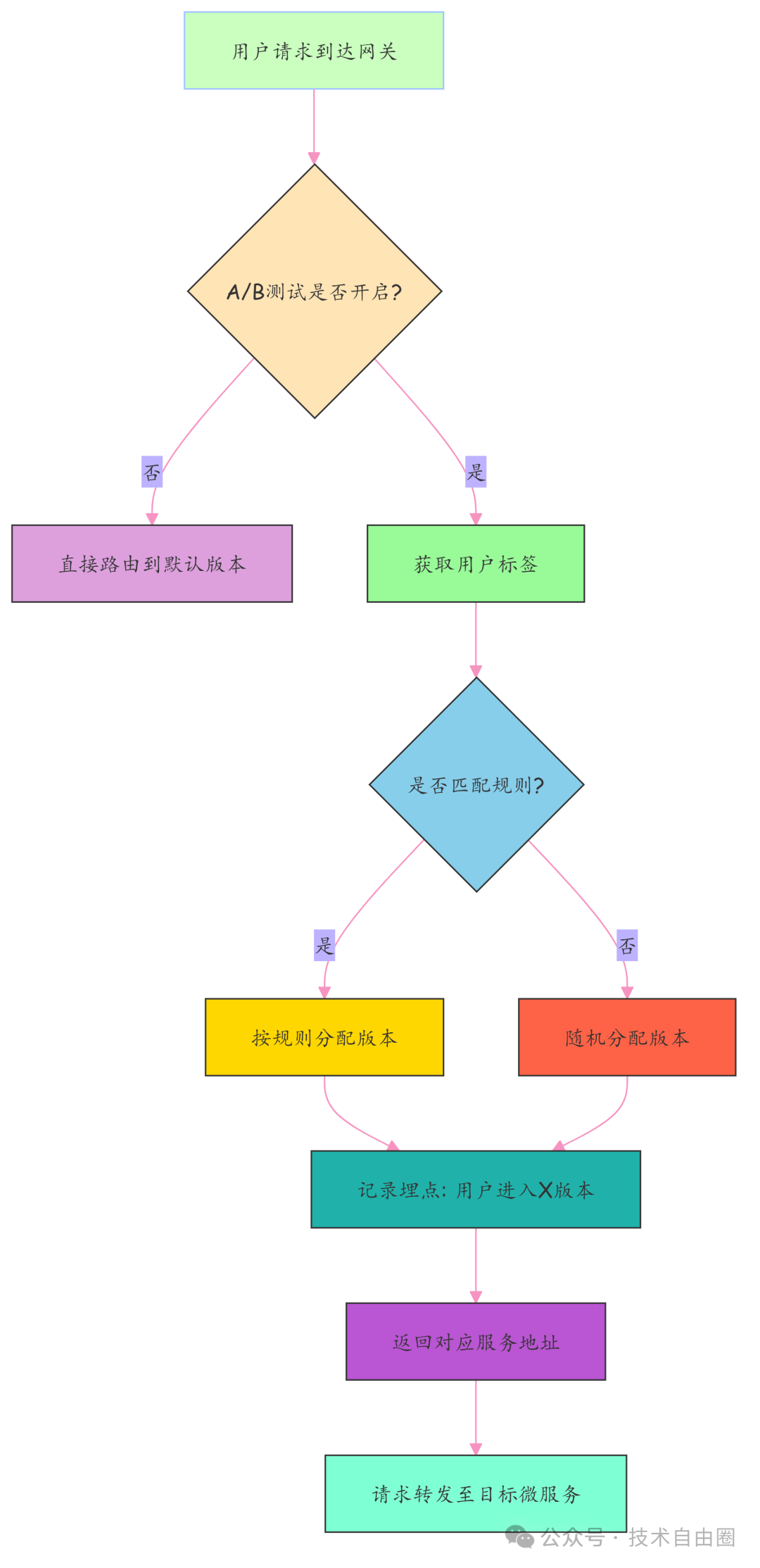
最后,等待数据积累充足,分析报告出炉:
- 如果 B 版完胜 → 更新
winner_version: "B",准备全量上线。
- 如果效果不佳 → 直接关掉实验,回退到原始方案。
一句话总结:应用网关层的 A/B 测试,就是利用用户画像和规则引擎,在流量入口精准切分人群,通过埋点收集行为数据,最终用事实决定“谁才是最优解”。
四、灰度发布与 A/B 测试流量切分规则如何共存?
核心原则:不是把两者硬塞进一个系统,而是安排好“谁先谁后、谁管谁、谁兜底”的规矩。
核心原则:四条铁律
| 原则 |
通俗解释 |
为什么重要? |
| 1. 优先级:A/B 测试 > 灰度发布 > 默认版本 |
请求先判断是否为A/B测试用户,再判断是否为灰度用户,都不是才走默认版。 |
避免实验数据被污染,保证灰度验证可控。 |
| 2. 标签隔离 |
为Pod打上明确标签,如 abtest-group: group-a 或 abtest-group: gray-canary。 |
防止A/B和灰度Pod在路由时“张冠李戴”。 |
| 3. 配置中心化 |
所有分流规则(比例、分组)只存储在Nacos中,动态生效。 |
改比例不用发版,调流量不用重启,上线快、回退快。 |
| 4. 全链路可观测 |
请求头自动注入 X-Route-Type: abtest/gray/default,贯穿日志、监控、链路追踪。 |
出问题时,一眼看出报错来自哪个通道,排查效率翻倍。 |
关键点:A/B 测试优先级必须高于灰度发布! 否则实验数据会被灰度流量污染。
技术实现:三步落地
步骤1:Pod 标签升级
在K8s Deployment中为不同用途的Pod明确打标,新增 abtest-group 标签与 version 并存。
# A/B 测试组 A 的 Pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: service-order-ab-a
spec:
template:
metadata:
labels:
app: order-service
version: v2.0
abtest-group: group-a # 关键!标明身份
spec:
containers:
- name: app
image: registry/order:v2.0
步骤2:网关统一规则引擎 —— 流量“过三关”
Spring Cloud Gateway 过滤器改造为三段式决策流:
- 第一关(最高优先级):查询A/B测试身份(如请求头
X-AB-Test-ID)。
- 第二关:查询灰度身份(如请求头
X-Gray-User: true)。
- 第三关(兜底):都不匹配,路由到默认老版本服务。
关键是在每一步都设置 X-Route-Type 属性,为全链路监控打下基础。
步骤3:K8s Service 路由增强 —— 精准投递
为A/B测试和灰度发布创建独立的Service,通过 selector 精准匹配对应标签的Pod。
# A/B 测试专用 Service
apiVersion: v1
kind: Service
metadata:
name: order-service-ab
spec:
selector:
abtest-group: group-a # 只匹配带这个标签的 Pod
ports:
- port: 8080
效果:网关发到 order-service-ab 的请求,K8s只会转发给 group-a 的Pod——零误触、零污染。
关键点:一定要用独立 Service + label selector 实现物理隔离!
冲突兜底与监控
冲突处理:自动降级
| 场景 |
处理方式 |
示例 |
| 同一请求同时满足A/B和灰度条件 |
强制走A/B(优先级更高),灰度规则静默忽略 |
用户既有 X-AB-Test-ID,又有 X-Gray-User → 只走A/B |
A/B测试关闭(配置设为 enabled: false) |
自动降级为灰度规则;若灰度也关 → 再降级为默认版本 |
A/B下线后,原用户自然流入灰度或老版本 |
| 网关规则解析失败 / Nacos 连不上 |
启用本地缓存规则 + 默认fallback(如全量走默认) |
即使Nacos宕机,网关仍可用最近一次有效配置 |
全链路监控:全程带“身份证”
在整个链路上注入并透传 X-Route-Type,让它成为流量的“电子通行证”。
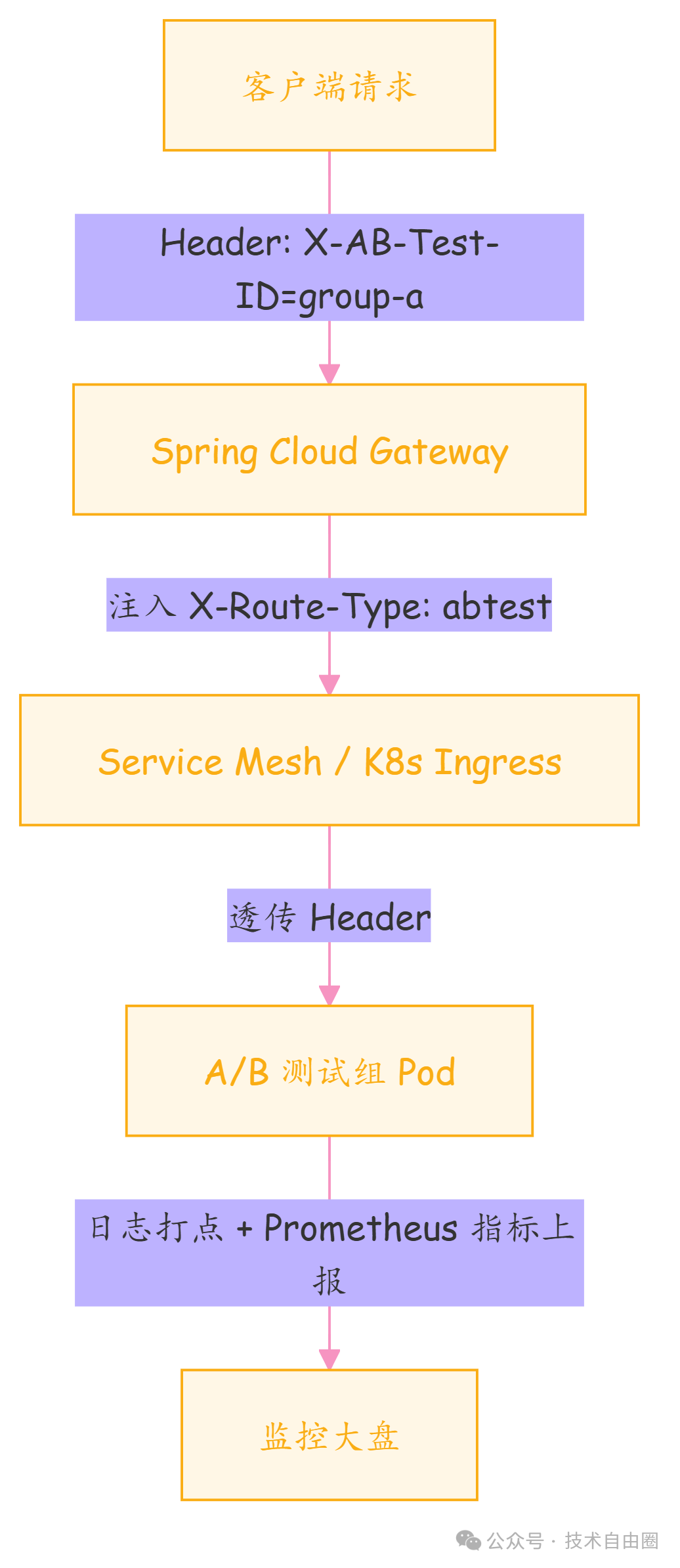
监控落地动作:
- 日志:所有服务打印日志时,强制输出
route_type=abtest 字段。
- Prometheus:自定义指标如
service_route_requests_total{route_type="abtest", service="order"},实时监控各通道流量。
- 链路追踪:在 Span 中添加
route_type 标签,快速定位问题所属通道。
- 告警:当某类流量突降或持续为0,立即通知负责人。
本节小结:灰度与A/B测试共存,不靠人肉协调,而靠铁律立规矩、三步加规则、监控保兜底实现有序协同。如果你想了解更多关于微服务和云原生环境下的高级流量治理模式,可以深入探索相关技术社区。
五、容器层灰度方案:K8s Ingress + Deployment
除了应用层的方案,在 Kubernetes 环境中,我们可以通过 Ingress + Deployment 的组合实现更底层、与业务解耦的“容器层”灰度发布。这套方案特别适合想要快速、安全上线的微服务场景。
前提条件
要玩转这套方案,需满足几个前提:
- 流量能切分:集群必须部署支持权重分流的 Nginx Ingress Controller(增强版)。
- 已有稳定服务在运行:线上有稳定的 Deployment、Service 和 Ingress。
- 版本靠标签区分:新旧版本通过不同的 Label 来识别,例如
version: v1(老版本)和 version: canary(新版本)。
灰度发布实现流程
第一步:部署金丝雀版本(Canary)
先上线新版本,但不让它接收大量流量。
# canary-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-canary
spec:
replicas: 2 # 假设老版本有10个副本,这里起2个对应约20%流量
selector:
matchLabels:
app: myapp
version: canary
template:
metadata:
labels:
app: myapp
version: canary
spec:
containers:
- name: app
image: myapp:v2-new-feature
ports:
- containerPort: 8080
# canary-service.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp-canary-svc
spec:
selector:
app: myapp
version: canary
ports:
- protocol: TCP
port: 80
targetPort: 8080
第二步:配置带权重的 Ingress(核心)
创建附加的 Ingress 规则,按比例分流。
# canary-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myapp-canary-ingress
annotations:
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-weight: "10" # 10%流量导入新服务
spec:
rules:
- host: myapp.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: myapp-canary-svc
port:
number: 80
提示:此 Ingress 是“附加规则”,主 Ingress 依然接收剩余90%的流量。
第三步:逐步放大流量
| 观察监控指标(CPU、内存、错误率、响应时间),一切正常则逐步调整权重。 |
时间 |
权重调整 |
操作 |
| Day1 |
10 → 30 |
修改 weight,观察日志 |
| Day2 |
30 → 60 |
扩容 canary deployment 到 6 副本 |
| Day3 |
60 → 100 |
weight 调到 100,旧服务下线 |
最后,删除老的 Deployment 和 Service,将主 Ingress 指向新的 Service。
提示:每次调权重后,至少观察15分钟以上。
出事了怎么办?回滚!
场景一:还在灰度阶段(未全量)
操作三步走:
- 断流:把
canary-weight 设为 0。
- 扩容老版本:
kubectl scale deployment/myapp-stable --replicas=10。
- 清理新版本资源:删除 Canary 相关的 Deployment、Service、Ingress。
关键:永远不要直接删正在运行的 Deployment!
场景二:已经全量上线(新版本已接管)
使用 K8s 内置的 rollout 命令回滚。
# 回退到上一个版本
kubectl rollout undo deployment/myapp-stable
# 查看回滚状态
kubectl rollout status deployment/myapp-stable
# 回退到指定历史版本
kubectl rollout undo deployment/myapp-stable --to-revision=5
确保 Deployment 中设置了足够的历史版本保留数:revisionHistoryLimit: 10。
容器层方案的优势在于:与业务解耦、操作标准化、回滚速度快,非常适合集成到 CI/CD 流水线中。
六、两种灰度方案对比
我们介绍了两种实现路径,下面从多个角度进行对比,帮你决策何时该用哪个。
| 对比维度 |
Ingress + Deployment 方案(容器层灰度) |
应用网关层 + Nacos 方案(网关层灰度) |
| 架构复杂度 |
低,依赖 K8s 原生组件,运维成本低 |
高,需维护网关、Nacos、监控等组件 |
| 流量控制粒度 |
粗,仅支持全局比例分流 |
细,支持按用户/设备/地域等精细化哈希分流 |
| 配置灵活性 |
弱,需编辑 K8s YAML,无热更新 |
强,Nacos 动态下发配置,实时生效 |
| 问题定位能力 |
仅 Pod 级监控,无全链路视角 |
强,集成全链路追踪,精准定位跨服务异常 |
| 回滚效率 |
快,操作简单(改权重或rollout) |
多层回滚,需确保多组件配置一致性 |
| 适用场景 |
中小规模、需求简单、追求快速落地的业务 |
大规模、高复杂度、需要精细化控制与AB测试的核心业务 |
一句话总结:Ingress 方案是“快刀”,轻量高效;网关方案是“手术刀”,精密灵活。
最佳实践建议:
初期或简单场景,可以用 Ingress 方案快速跑通灰度流程。当业务发展到需要用户分群、AB实验、数据驱动决策时,再逐步引入网关和配置中心,进行平滑升级。
技术选型的本质,是在“能力”和“成本”之间找到最佳平衡点。
总结:新功能上线要牢记
凡是涉及“变更”,就必须有章法。记住核心心法:先灰度保命,再AB求胜。
- 灰度发布是保命符:通过小范围、渐进式放量,验证新版本的系统稳定性,确保随时可退。
- A/B测试是增长器:在稳定前提下,通过科学的对照实验,用数据验证业务价值,选出最优方案。
- 组合使用是王道:先对少量流量做灰度,验证通过后,在同一批流量上开启A/B测试,最终实现“稳中求胜”。
搞懂并熟练运用这两套方法论,你就能成为团队里那个“关键时刻靠得住”的人。这套思想不仅适用于Web后端,也广泛用于App发版、小程序更新乃至AI模型部署等场景。
希望这份来自一线实践的梳理,能帮助你在技术设计和面试回答中,充分展示深厚的“技术肌肉”。稳扎稳打,方能行稳致远。
 发表于 2026-1-25 18:16:52
|
查看: 519|
回复: 0
发表于 2026-1-25 18:16:52
|
查看: 519|
回复: 0
