虚函数的性能影响,并非我们简单想象的那样。
它通常不会让你的程序卡成幻灯片,但它会在你最需要速度的计算核心层,悄无声息地瓦解现代CPU与编译器的强大优化能力。作为开发者,我们可以用一句话概括其使用哲学:在UI、网络、架构等业务层,可以放心使用虚函数;但在渲染、物理计算、矩阵运算等计算层,必须避免使用。
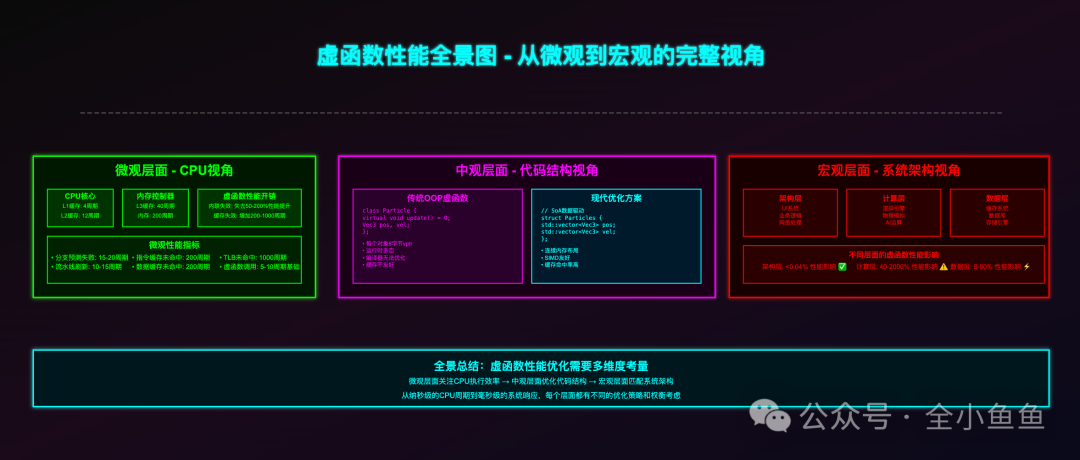
下面,我们来深入探讨为什么“仅仅多一次间接调用”的观点并未触及问题的本质。
一、虚函数的性能瓶颈究竟在哪
许多人认为“虚函数就是查一次表,多跳转一次,能有多慢”,这种理解流于表面。

真正的症结并非那多出的几条汇编指令,而在于它让现代编译器和CPU最强大的优化手段几乎全部失效。
1、表层开销:内存访问不稳定
一个典型的虚函数调用过程如下:
mov rax, [obj] ; 取对象地址
mov rax, [rax] ; 取 vptr(虚表指针)
call [rax + offset] ; 调用函数
如果对象和其虚函数表(vtable)都幸运地驻留在L1缓存中,额外的延迟大约只有1~2纳秒,几乎可以忽略不计。然而,如果对象是刚new出来的,或者不同派生类的虚表散落在内存各处,那么访问vptr或vtable条目很可能触发缓存未命中(Cache Miss),延迟会瞬间飙升数十甚至上百倍。
更糟糕的是,这种开销极不稳定。同一段代码,在不同数据分布下的性能表现可能天差地别。
2、深层代价:三大优化杀手
第一,内联优化失效。 普通函数调用可以被编译器内联,彻底消除调用开销,并开启跨函数优化的大门。例如:
int square(int x) { return x * x; }
int y = square(5); // 编译器直接优化为: y = 25
但虚函数必须在运行时决议,编译器对此无能为力。结果就是函数调用开销被保留,寄存器分配变差,无用的“死代码”也无法被消除。
或许有人会说,开启链接时优化(LTO)和配置文件引导优化(PGO)后,编译器可能猜出具体类型并进行优化。但这只在极其有限的场景下成立,在追求极致性能的核心计算路径上,绝不能依赖这种不确定的侥幸。
第二,打断CPU流水线。 现代CPU高度依赖确定性和可预测性。普通函数调用地址固定,分支预测成功率接近100%。而虚函数的跳转地址取决于对象的运行时类型,CPU只能进行猜测。一旦猜错,整条流水线都需要被清空并重新填充,在高频紧凑的循环中,这种预测失败的代价会累积成巨大的性能损失。
第三,加剧缓存失效。 一个典型的使用模式是基类指针数组:
std::vector<Base*> objects;
for (auto* obj : objects) {
obj->update(); // 虚调用
}
这些对象通常在堆上随机分配,内存访问模式碎片化,CPU的硬件预取器难以有效工作,每次访问都可能遭遇Cache Miss。如果派生类众多,它们的vtable地址也可能不连续,甚至访问vtable本身都可能触发缓存未命中。
二、如何在代码中做出正确选择
关键在于判断你的代码位于系统架构的哪个层面。
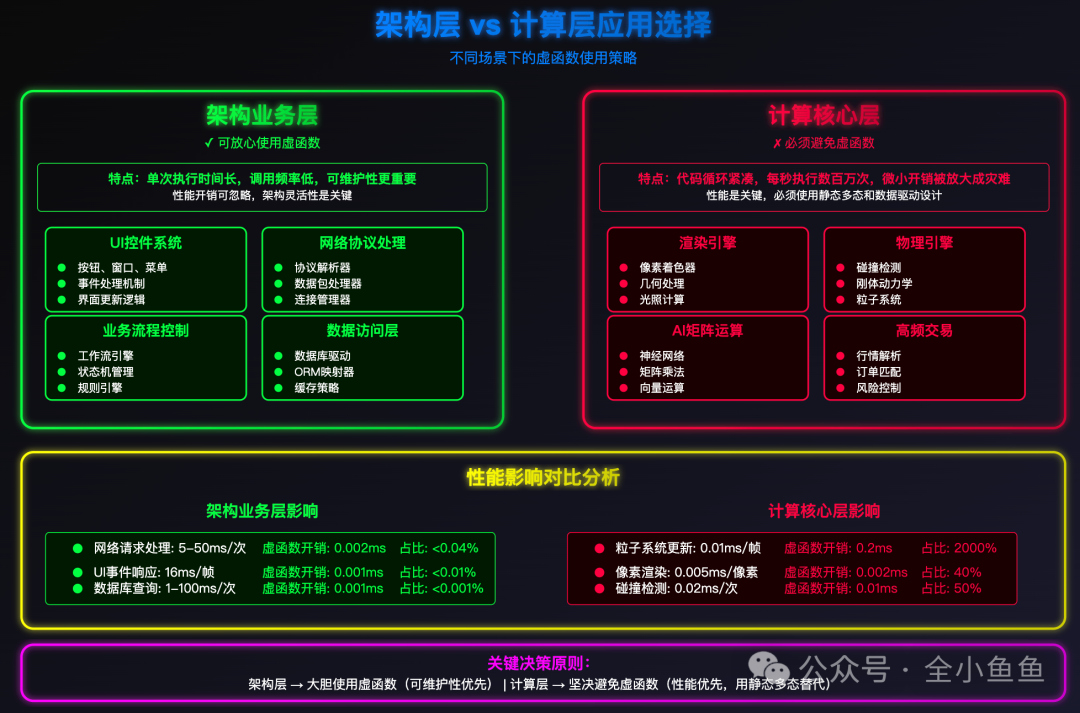
1、架构与业务层:可放心使用
在这些层面,单次操作执行时间长,或调用频率相对较低。此时,代码的可维护性和架构灵活性往往比微小的性能开销更重要。
典型场景包括:
- UI控件系统(按钮、窗口、菜单)
- 网络协议处理器和回调
- 业务流程控制器与状态机
- 数据库驱动接口
例如,处理网络数据包:
class PacketHandler {
public:
virtual ~PacketHandler() = default;
virtual void handle(const Packet& p) = 0;
};
class LoginHandler : public PacketHandler {
void handle(const Packet& p) override {
// 解析登录包
}
};
void network_loop() {
while (running) {
auto packet = recv();
get_handler(packet.type)->handle(packet); // 虚调用,开销可接受
}
}
在这里,虚函数带来的那点纳秒级开销,相比网络IO的毫秒级延迟完全可以忽略。它消除了大量的if-else判断,让代码结构更清晰,扩展性更强。在这种场景下,拒绝使用虚函数反而可能是一种设计上的缺陷。
2、计算核心层:必须避免使用
这里是性能的生死线。代码循环紧凑,每秒可能被执行数百万甚至数十亿次。任何微小的开销都会被循环放大成灾难。
典型场景有:
- 渲染引擎中的像素着色与几何处理
- 物理引擎中的碰撞检测与粒子系统更新
- AI推理中的矩阵乘法与向量运算
- 高频交易系统中的行情解析
例如,一个粒子系统更新循环:
class Particle {
public:
virtual void update(float dt) = 0;
Vec3 pos, vel;
};
// 每帧更新10万个粒子
for (auto* p : particles) {
p->update(delta_time); // 虚调用,是性能杀手
}
即使每次虚调用只多花2纳秒,10万次就是200微秒。这还不算因分支预测失败和缓存失效带来的额外惩罚,后者往往更严重。
替代方案一:数据驱动设计(SoA)
放弃传统的面向对象思维,采用结构体数组(Structure of Arrays, SoA)的数据布局。
struct ParticleSystem {
std::vector<Vec3> positions;
std::vector<Vec3> velocities;
std::vector<uint8_t> types;
};
void update_fire(ParticleSystem& sys, float dt) {
for (size_t i = 0; i < sys.positions.size(); ++i) {
if (sys.types[i] != 0) continue; // 按类型筛选
sys.velocities[i].y -= 9.8f * dt;
sys.positions[i] += sys.velocities[i] * dt;
}
}
这种布局让同类型数据在内存中连续存储,极大提升了CPU缓存命中率和预取效率,并且循环体内的函数可以被完美内联。
替代方案二:静态多态(CRTP)
使用奇异递归模板模式(Curiously Recurring Template Pattern, CRTP)实现编译期多态,实现零运行时开销。
template<typename Impl>
class ParticleBase {
public:
void update(float dt) {
static_cast<Impl*>(this)->update_impl(dt);
}
};
class FireParticle : public ParticleBase<FireParticle> {
public:
void update_impl(float dt) {
vel.y -= 9.8f * dt;
pos += vel * dt;
}
Vec3 pos, vel;
};
std::vector<FireParticle> particles;
for (auto& p : particles) {
p.update(dt); // 编译期确定,可内联,无虚表开销
}
这种方法既提供了清晰的泛型接口结构,又保留了极致性能,是C++中高阶的优化技巧。
三、实战建议:先确保正确,再追求性能
切勿因过度恐惧性能而用一堆switch-case写出难以维护的“面条代码”,也绝不要在渲染循环中误用虚函数导致帧率崩溃。

合理的工程实践路径应该是:
1、在业务层大胆使用虚函数
充分利用其带来的解耦、易测试、易扩展的优势,这是面向对象多态的核心价值所在。
2、上线前进行性能剖析(Profiling)
使用perf、VTune等专业工具找到真正的性能瓶颈。只有当你发现虚函数调用出现在热点(Hotspot)排行榜前三时,才需要针对性地进行重构。
3、针对性地选择重构方案
- 同质数据:采用SoA数据驱动设计。
- 已知的有限异构类型:使用
std::variant。
- 需要泛型接口且类型已知:使用CRTP静态多态。
虚函数本质上是一个权衡工具:它用一点确定的运行时开销,换取巨大的架构灵活性。我们见过太多开发者为了规避微不足道的开销,将清晰的代码结构复杂化;也见过在物理引擎核心循环中使用虚函数,导致帧率从60帧暴跌至10帧的案例。
核心就在于明确认知其适用与禁忌的边界。 你是否也曾经历过,在热点循环中使用了虚函数,性能剖析工具一开,发现CPU时间大都消耗在了虚表的跳转上?欢迎在云栈社区分享你的实战经验与优化心得。
 发表于 2026-1-25 18:20:51
|
查看: 229|
回复: 0
发表于 2026-1-25 18:20:51
|
查看: 229|
回复: 0
