在分布式系统中,MySQL 常作为可靠的持久化数据源,Redis 则以高性能优势担当缓存角色。但由于两者是独立的存储组件,写操作过程中任何一步的失败、延迟或并发冲突,都可能导致数据不一致。
需要明确的是,分布式环境下实现强一致性(任意时刻读取均为最新数据)代价极高,且会严重牺牲性能。因此实践中更倾向于追求 最终一致性 —— 允许短暂的数据不一致,通过合理策略确保数据最终同步。
一、数据不一致的根源
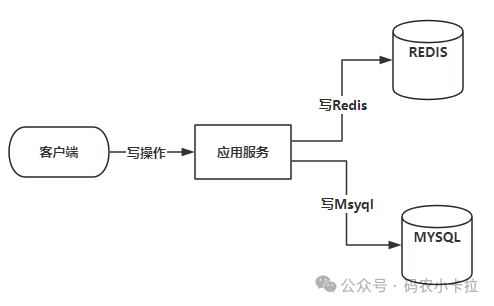
MySQL 与 Redis 数据不一致的核心原因是写操作无法原子性地同步执行,具体场景包括:
- 写 MySQL 成功,但写 Redis 失败:Redis 残留旧数据;
- 写 Redis 成功,但写 MySQL 失败:Redis 存在数据库中不存在的“脏数据”;
- 并发读写冲突:一个线程更新数据库后未同步缓存,另一个线程已读取旧缓存并复用。
二、核心实现策略与模式
(一)Cache-Aside Pattern(旁路缓存模式)
这是最常用、最经典的缓存策略。核心原则是“应用直接交互数据库与缓存,缓存不作为写入必经之路”,兼顾性能与简洁性。
1. 读写流程
- 读流程:
- 接收读请求,优先查询 Redis;
- 缓存命中(数据存在):直接返回结果;
- 缓存未命中:从 MySQL 查询数据,将数据写入 Redis 后返回(供后续读取复用)。
- 写流程:
- 接收写请求,优先更新 MySQL 数据;
- 删除 Redis 中对应的缓存(而非更新缓存)。
2. 关键设计:为何删除缓存而非更新?
- 性能优化:若数据不常被读取,更新缓存会浪费资源(数据库写+缓存写双重开销);
- 并发安全:并发写场景下,缓存更新顺序可能与数据库不一致,导致旧数据残留;而删除操作是幂等的(多次删除效果一致),安全性更高。
3. 一致性保障与局限
通过“先更数据库,再删缓存”减少不一致窗口,但仍存在理论风险:
- 线程 A 执行数据库更新;
- 线程 B 读取数据时缓存已被删除,从数据库读取到 A 未提交的旧数据;
- 线程 B 将旧数据写入 Redis;
- 线程 A 完成数据库更新并删除缓存。
不过该场景概率极低,因数据库写操作(涉及锁、日志)通常比读操作耗时更长,并发冲突概率较小。
(二)Write-Through / Read-Through Pattern(穿透读写模式)
该模式下,缓存层(或独立服务)全权负责与数据库交互,应用仅需与缓存通信,逻辑对应用透明。
1. 读写流程
- 写流程:应用写入缓存,缓存组件同步写入数据库,两者均成功后返回;
- 读流程:应用读取缓存,未命中时缓存组件自动从 MySQL 加载数据并填充缓存,再返回结果。
2. 优缺点
- 优点:一致性优于旁路缓存,应用无需关注数据库交互,逻辑简洁;
- 缺点:写性能较差(每次写操作必须同步数据库),需成熟缓存中间件支持(如 Redis 扩展组件)。
(三)Write-Behind Pattern(异步写回模式)
这是穿透写模式的异步优化版,核心是“牺牲一致性换极致写性能”。
1. 核心逻辑
应用写入缓存后立即返回成功,缓存组件在后续某个时间点(如攒够批量数据、定时触发)异步批量更新至 MySQL。
2. 优缺点
- 优点:写性能极高,适合高并发写场景;
- 缺点:数据丢失风险(缓存宕机可能导致未同步数据丢失),一致性最弱,仅适用于计数、点赞等允许少量数据丢失的场景。
三、进阶方案:强化最终一致性
针对旁路缓存模式的潜在缺陷,可通过以下方案进一步缩小不一致窗口。
(一)延迟双删
核心思路是“两次删除缓存,清理并发写入的旧数据”,弥补单删缓存的不足。
1. 执行流程
- 线程 A 更新 MySQL 数据;
- 线程 A 第一次删除 Redis 缓存;
- 线程 A 休眠特定时间(如 500ms-1s,根据业务读写耗时估算);
- 线程 A 第二次删除 Redis 缓存。
2. 优缺点
- 优点:简单有效,可大幅降低并发读写导致的不一致;
- 缺点:休眠时间难以精确设定(过短仍有冲突风险,过长降低写入吞吐量)。
(二)消息队列异步删除
通过消息队列解耦缓存删除与数据库更新,确保删除操作可靠执行。
1. 执行流程
- 应用更新 MySQL 数据;
- 向消息队列(如 RocketMQ, Kafka)发送“删除缓存”消息;
- 消费者消费消息,执行 Redis 缓存删除;若删除失败,消息队列会自动重试,保证操作至少执行一次。
2. 核心优势
- 解耦主业务链路:缓存删除不阻塞数据库更新,提升写性能;
- 可靠性保障:重试机制避免缓存删除失败导致的不一致。
(三)数据库 Binlog 同步(最优解)
这是业界最成熟、对业务侵入最小的方案,核心是利用 MySQL 的二进制日志(Binlog)实现增量数据同步。
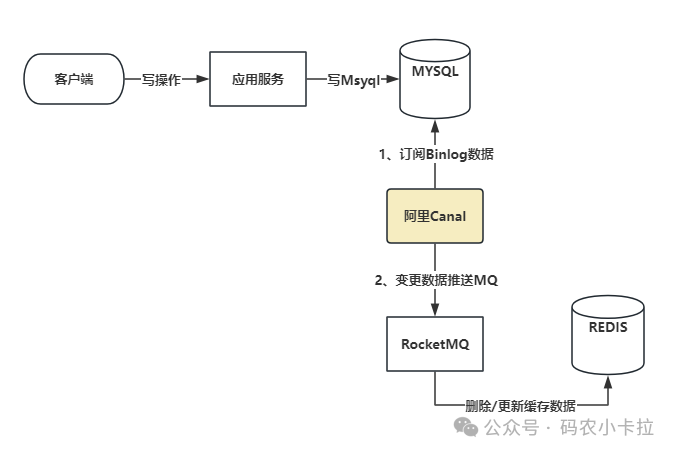
1. 工作原理
- 业务系统正常写入 MySQL,MySQL 自动生成 Binlog(记录数据增删改详情);
- 中间件(如 Canal、Debezium)伪装成 MySQL 从库,订阅并解析 Binlog;
- 中间件根据 Binlog 变更内容,调用 Redis API 执行缓存更新或删除;
- 全程无需业务代码介入,缓存同步由中间件独立完成。
2. 核心优势
- 业务无侵入:应用仅需关注数据库写入,无需处理缓存逻辑;
- 高性能:同步过程异步执行,不影响主业务链路;
- 一致性强:Binlog 记录数据库真实变更,确保缓存与数据库最终一致,且同步顺序与数据库一致。
3. 局限
- 架构复杂度提升:需维护 Canal 等中间件及同步链路;
- 存在毫秒级到秒级同步延迟(可接受的最终一致性范围)。
四、最佳实践与选择建议
(一)策略对比表
| 策略 |
一致性保证 |
性能 |
复杂度 |
适用场景 |
| Cache-Aside + 单删缓存 |
最终一致性(微弱风险) |
高 |
低 |
绝大多数场景首选,读多写少 |
| Cache-Aside + 延迟双删 |
更优的最终一致性 |
中 |
低 |
对一致性要求稍高,可接受写延迟 |
| Write-Through |
强一致性 |
中 |
中 |
写多读少,一致性要求极高 |
| Binlog 同步 |
最终一致性(推荐) |
高 |
高 |
大型项目、高一致性要求、需解耦业务 |
(二)通用建议
- 优先选择简单方案:大多数场景下,Cache-Aside 模式(先更库、再删缓存)已足够,无需过度设计;
- 进阶优化:若不一致窗口无法接受,先引入延迟双删或消息队列异步删除,成本低、见效快;
- 终极方案:业务规模扩大后,升级为 Binlog 同步方案,平衡一致性与业务解耦;
- 必备安全网:为 Redis 缓存设置过期时间(TTL),即使同步逻辑故障,旧数据也会自动失效,兜底最终一致性;
- 对齐业务容忍度:与产品确认一致性要求,多数场景下 1-2 秒的延迟用户无感知,无需追求强一致性。
总结
MySQL 与 Redis 数据双写一致性的核心是“放弃强一致性,追求最终一致性”,并根据业务场景选择适配策略:简单场景用旁路缓存,高要求场景用 Binlog 同步。同时通过“删除缓存而非更新”“设置 TTL”等细节优化,在性能与一致性之间找到最佳平衡。
实际落地时,需优先考虑方案的简洁性与可维护性,避免为过度追求一致性而牺牲系统性能。关于更多分布式系统与高可用架构的探讨,欢迎在 云栈社区 进行交流。 |  发表于 2026-1-26 13:19:23
|
查看: 215|
回复: 0
发表于 2026-1-26 13:19:23
|
查看: 215|
回复: 0
