在人工智能技术日新月异的今天,大语言模型、状态空间模型等复杂神经网络已成为推动技术发展的核心引擎。然而,这些模型所依赖的复合操作——即由多个基础操作(如矩阵乘法、归一化、逐元素变换)组合而成的结构化模块——正在对现有的AI硬件优化提出严峻挑战。
传统的数据流优化框架往往仅针对单一操作进行建模,或在分布式计算场景中忽视集体通信的成本,导致其难以应对现代大规模、分布式训练的复合操作需求。更关键的是,随着模型规模持续扩大,计算往往需要分布在多个计算核心甚至多个加速器之间,频繁的集体通信(如 All-Reduce、All-Gather)成为不可忽视的性能瓶颈。
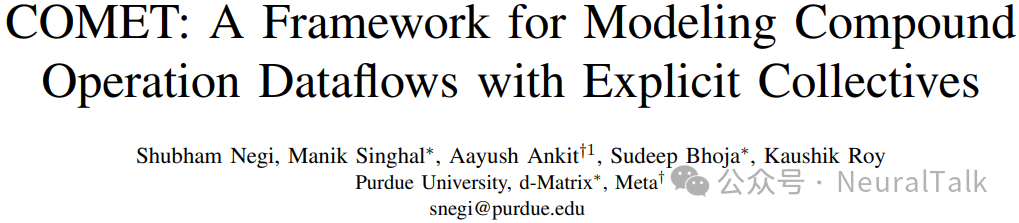
为此,来自普渡大学、d-Matrix 与 Meta 的研究团队提出了一种全新的框架——COMET(Compound Operation Modeling with Explicit Collectives),旨在系统性建模与优化面向机器学习加速器的复合操作数据流。
该框架不仅首次显式建模集体通信成本,还提出了一种细粒度的性能分析模型,能够准确捕捉复合操作内部的数据依赖与通信开销。
本文将深入解读 COMET 的核心创新、工作方法、实验评估及其对 AI 硬件设计的影响。
一、复合操作与集体通信:为何成为性能瓶颈?
1.1 什么是复合操作?
在现代神经网络中,许多层被设计为复合操作,即将多个基础操作组合为一个模块,以提升模型的模块化、效率与表达能力。典型的例子包括:
- 自注意力机制:包含矩阵乘法(GEMM)、Softmax 归一化、缩放操作;
- 归一化层(如 LayerNorm):包含统计量计算、仿射变换等非 GEMM 操作。
这些复合操作虽提升了模型表达能力,但也引入了数据局部性差、中间张量存储开销大、通信同步复杂等问题。
1.2 集体通信在分布式计算中的关键角色
当复合操作需要在多核或多加速器间分布式执行时,不同计算单元之间需通过集体通信来同步中间结果。常见的集体操作包括:
- All-Reduce:所有节点参与规约,结果广播给所有节点;
- All-Gather:所有节点收集其他节点的数据;
- Reduce-Scatter:规约后分散到不同节点;
- Broadcast:将数据从一节点广播到所有节点。
这些操作在分布式训练与推理中频繁发生,其延迟与能耗直接影响整体系统效率。
1.3 现有框架的不足
现有的数据流优化框架(如 Timeloop、TileFlow)大多侧重于单一操作或简单融合,缺乏对集体通信的显式建模,也未能充分考虑复合操作内部的数据依赖与内存访问模式。这导致在分布式、多核场景下的性能预测失真,优化空间受限。
二、COMET 的核心创新:显式集体表示与细粒度成本模型
COMET 的核心贡献可归纳为两点:
- 提出一种显式集体表示方法,将集体通信作为数据流的一部分进行建模;
- 设计一种细粒度的成本模型,涵盖计算、内存访问、通信及操作间依赖。
2.1 显式集体表示
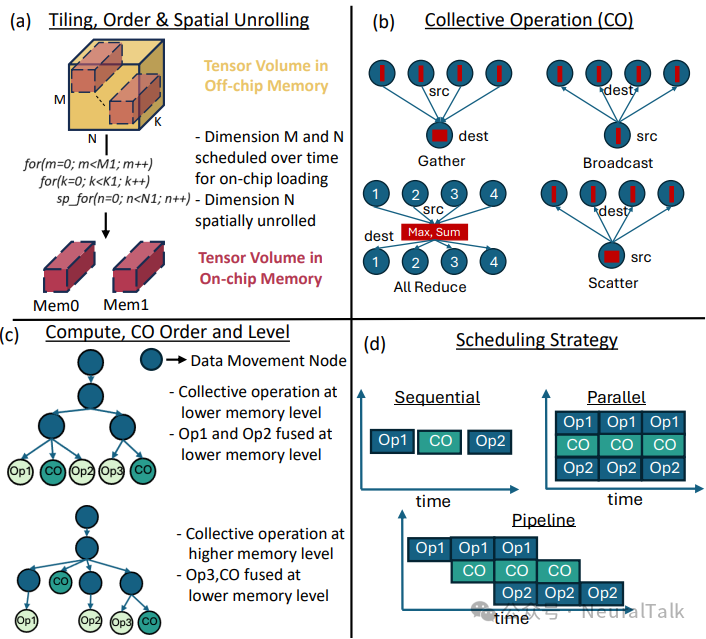
COMET 将复合操作的数据流建模为一个四维设计空间,涵盖:
- 循环分块、排序与空间展开策略;
- 集体操作类型与执行位置;
- 操作间执行顺序与融合层级;
- 跨计算单元的调度策略。
在 COMET 的中间表示中,每个张量在每一级内存层次上都拥有独立的循环嵌套,从而支持对不同张量数据移动与复用的精细控制。集体操作节点被显式插入到数据流图中,并附有以下属性:
ColOpType:集体操作类型;Tensor:操作的张量;ReduceOp:规约操作(如 max、add);Src/Dest:源与目标内存层级。
这种表示方法使得 COMET 能够灵活探索不同的集体策略,例如在全局缓冲区(GB)级别执行 All-Reduce,或在输出缓冲区(OB)级别执行更轻量的 Gather 操作。
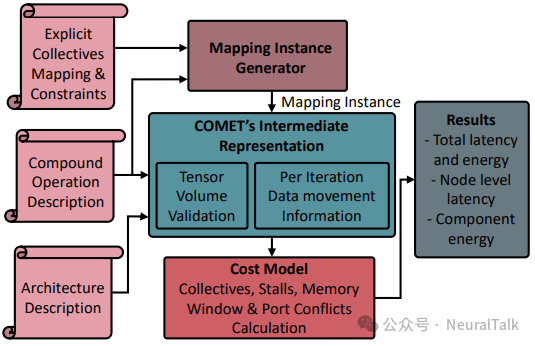
2.2 复合操作示例:GEMM-Softmax 的显式集体表示
以典型的复合操作GEMM 后接 Softmax为例,其 Softmax 被分解为多个子操作,并在多集群间分布式执行。
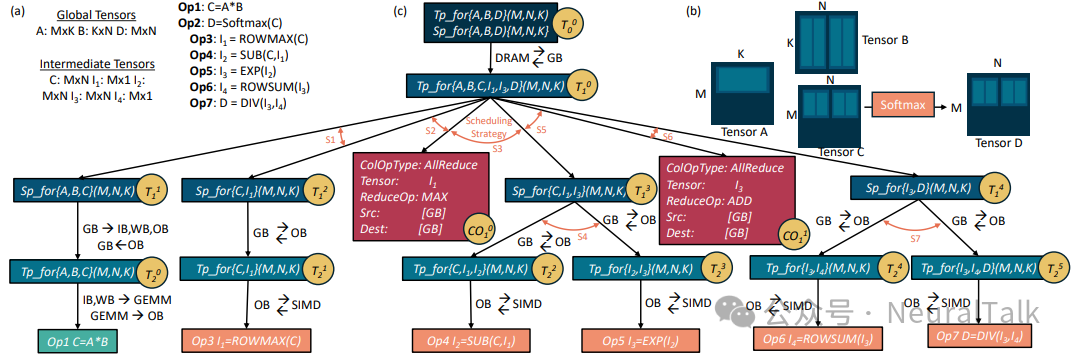
在分布式执行中,Softmax 需要获取整行张量的最大值与求和值,这要求跨集群执行两次 All-Reduce。COMET 通过显式插入集体节点如CO₁⁰和CO₁¹,进而来建模这一通信过程,从而能够在后续优化中调整其执行位置或替换为其他集体类型如 Gather,以权衡通信开销与内存占用。
2.3 细粒度成本模型
COMET 的成本模型涵盖延迟与能耗两方面,并特别强化了对以下因素的建模:
(1)内存传输延迟
COMET 采用双缓冲假设,支持内存传输与计算重叠。其内存传输延迟模型如下:
T_mem_transfer = DV / BW
其中DV为每迭代传输数据量,BW为带宽。总延迟还包括强制停顿(Compulsory Stall,CS)与可选停顿(Optional Stall,OS),以捕捉数据填充与排空阶段的空闲时间。
(2)集体操作延迟
集体操作的延迟 T_collective,由内存访问延迟 T_col_mem 与片上网络(NoC)延迟 T_col_noc 共同构成:
T_collective = T_col_mem + T_col_noc
T_col_noc = 2 * (hops * t_router + (DV/W) * t_eng)
其中hops为通信跳数,W为 NoC 通道宽度,t_router与t_eng分别为路由与排队延迟。
(3)操作间依赖与调度
COMET 支持多种调度策略(顺序、流水线、并行),并通过冲突检测模型捕捉资源共享竞争带来的额外延迟。例如,在顺序调度中,节点总延迟为子节点延迟之和;在流水线调度中,则为最慢子节点延迟加上冲突停顿时间。
三、COMET 的工作流程与实现
COMET 的整体工作流程如上图所示,用户需提供三方面输入:
- 工作负载描述:复合操作的结构与张量形状;
- 硬件架构描述:内存层次、计算单元、NoC 拓扑;
- 映射约束:循环分块、展开、融合等限制。
系统首先生成满足约束的映射实例,验证其内存容量是否合规,随后构建包含集体操作的中间表示,最终通过成本模型评估延迟与能耗。
四、相关工作比较
COMET 并非首个关注复合操作优化的框架,但其在集体通信建模与细粒度依赖分析方面实现了显著突破。
| 框架 |
目标 |
是否支持集体建模 |
是否支持非 GEMM 单元 |
主要局限 |
| Timeloop |
单操作数据流优化 |
否 |
有限 |
无法处理复合操作 |
| TileFlow |
复合操作融合优化 |
隐式 |
否 |
忽略数据暂存低效 |
| LoopTree |
融合中间张量权衡 |
否 |
否 |
缺乏通信成本建模 |
| COMET |
复合操作+集体通信 |
显式 |
是 |
全面覆盖计算、内存、通信 |
- Timeloop:专注于单操作映射优化,假设理想流水线,忽略启动与排空阶段延迟;
- TileFlow:通过树状分析建模融合数据流,但未显式建模集体操作,且假设单一计算单元;
- LoopTree:探索中间张量保留与重计算的权衡,适用于内存受限场景,但未扩展至分布式执行。
COMET 在继承这些框架优点的同时,通过显式集体表示与增强的成本模型,实现了对现代分布式 AI 工作负载更准确的性能预测与优化。
五、实验评估:COMET 如何提升性能?
研究团队在边缘与云两种加速器架构上评估了 COMET,覆盖三种典型复合操作:GEMM-Softmax、GEMM-LayerNorm与自注意力。
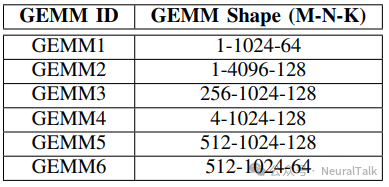
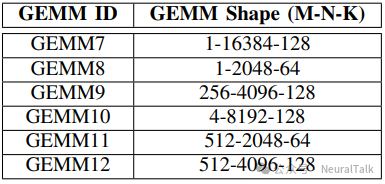
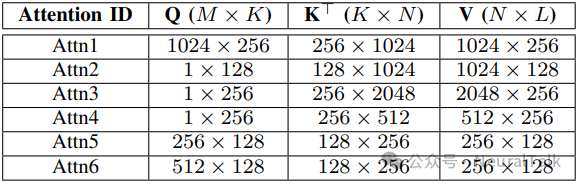
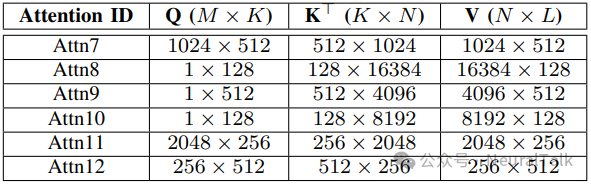
5.1 硬件配置
5.2 成本模型验证
与 Timeloop 和 TileFlow 的对比如下图所示:
- 与 Timeloop 对比:COMET 在单操作能量预测上高度一致,但延迟预测略高,因其包含了启动与排空阶段的停顿;
- 与 TileFlow 对比:COMET 在复合操作中预测能量略低,因其更准确地捕捉了中间张量复用;延迟预测更高,因其建模了操作间依赖导致的强制停顿。

5.3 集体策略的影响
COMET 支持两种集体策略:
- 分布式映射(distSM/distLN):在多个集群间执行集体操作;
- 标准映射(SM/LN):将非 GEMM 操作限制在单个集群内,避免跨集群集体通信。
下图显示,分布式映射在大型 GEMM 中因频繁集体操作导致延迟上升;而标准映射虽减少通信,但可能因单核执行成为 SIMD 瓶颈。

5.4 融合映射的收益
下图对比了不同融合策略与未融合基线的性能:
- 全融合(Fused-GEMM-distSM/distLN)在大多数情况下实现最低延迟;
- 部分融合(Fused-distSM)因仍需跨操作数据传输,性能次之;
- 未融合基线因频繁读写 DRAM,延迟与能耗最高。
COMET 优化后的数据流在几何平均上实现:
- GEMM-Softmax:1.42 倍加速;
- GEMM-LayerNorm:3.46 倍加速;
- 自注意力:1.82 倍加速。
5.5 自注意力案例研究
下图显示,完全融合的 FlashAttention(FA)在延迟与能耗上均优于未融合(UA)与部分融合(PFA)版本,尤其在云平台上收益显著。
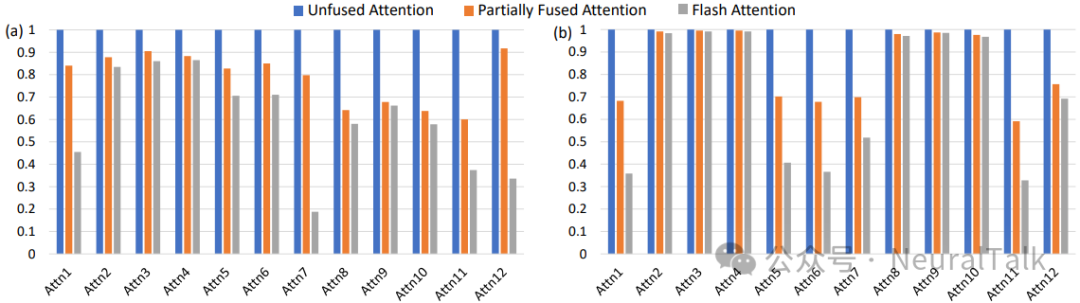
六、总结与展望
COMET 通过显式集体表示与细粒度成本建模,为复合操作在分布式机器学习加速器上的数据流优化提供了系统性框架。其不仅填补了现有工具在集体通信建模方面的空白,还为硬件-软件协同设计提供了重要指导。
未来工作可沿以下方向拓展:
- 支持更多集体算法:如拓扑感知集体、分层集体等;
- 扩展至训练场景:涵盖反向传播与梯度同步;
- 集成自动搜索算法:结合强化学习或进化算法进行映射空间探索;
- 支持新型硬件:如存内计算、光互连等新兴架构。
COMET 的出现标志着 AI 硬件优化进入集体感知时代,为下一代大模型的高效部署奠定了重要基础。对于希望深入了解前沿AI系统优化与硬件设计的开发者,欢迎到云栈社区交流探讨。
 发表于 2026-1-27 02:59:01
|
查看: 137|
回复: 0
发表于 2026-1-27 02:59:01
|
查看: 137|
回复: 0
