大模型发展迅猛,不管是擅长文本推理的OpenAI GPT系列,还是将Vibe Coding(意识编程)发挥到极致的Claude,亦或是在多模态领域表现亮眼的Gemini系列,都将人们对于AI的幻想拉高到一个新的境界。
闭源的LLM模型有OpenAI GPT系列、Claude系列、Google Gemini系列;开源的LLM模型有Meta Llama 2/3系列、Mistral AI系列,Qwen(通义千问)、DeepSeek系列。现阶段来看,开源的模型确实打不过闭源模型,闪耀在群“模”之巅的模型其训练数据、完整架构和多模态核心技术细节是保密的,这构成了其技术壁垒,纯粹的闭源模型以Anthropic(Claude系列)为代表,专注于为企业提供高度可靠、安全的闭源服务。
当然,像OpenAI和Google已采用“双轨制”,即维护开源和闭源两条产品线。OpenAI在2025年8月发布了开源模型GPT-OSS,是自2019年GPT-2后首次开源,采用宽松的Apache 2.0协议,允许商用和二次开发,性能接近其部分闭源模型,主打本地部署和企业定制;Google的双轨战略是让开源和闭源相互配合,开源“引流”,闭源“转化”,开发者可以先用免费、易得的Gemma入门和开发原型,当应用需要更强大的能力(如图像生成、复杂推理)时,可能会自然转向使用付费的Gemini API。OpenAI的市场策略从闭源转向开源,也是由于过去一年以Meta(LLama系列)和深度求索(DeepSeek)为代表的坚定开源派,在模型领域的亮眼表现。
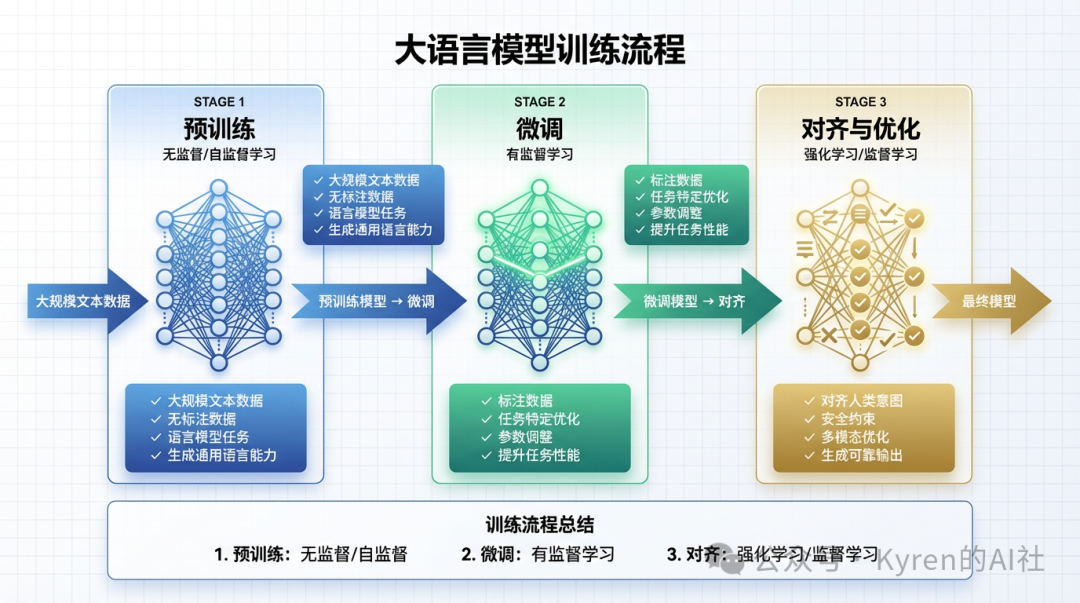
训练一个大语言模型的过程,可分为预训练 -> 微调 -> 对齐与优化。
预训练阶段的主要学习范式为无监督/自监督学习,模型从海量无标签文本中学习语言规律、世界知识、基础推理能力,生成基础模型如原始GPT-3;微调和对齐与优化阶段,模型采用监督学习及强化学习,将高质量有标签数据(指令-回复对、人类偏好排序)作为训练和反馈数据,让模型变得有用、无害、可控,能遵循指令,对齐后的聊天/任务模型如ChatGPT。
用一个生动的比喻描述训练模型就是:预训练(非监督)阶段,让一个孩子沉浸式地阅读图书馆里所有的书,通过上下文自学词汇、语法和常识。他拥有了丰富的知识,但还不知道如何与人有效交流或回答问题;微调和对齐阶段,就像给这个孩子请一位导师,导师通过具体的问答练习(SFT)和反馈评分(RLHF),教会他如何清晰、安全、有帮助地将学到的知识表达出来,成为一名优秀的“助手”。非监督/自监督学习构建了LLM的“大脑”和“知识库”,而监督学习(结合强化学习)则塑造了LLM的“性格”和“沟通方式”,使其从一个知识库转变为一个实用的助手。
2025年初,大语言模型的生产级技术栈已形成一套稳定且成熟的范式,主要包括三个阶段:
预训练(以2020年左右的GPT-2/3为代表),赋予模型基础语言能力与世界知识;
监督式微调(以2022年左右的InstructGPT为代表),教会模型遵循指令与执行任务;
基于人类反馈的强化学习(RLHF,同样约2022年),使模型的输出更符合人类偏好与价值观。
这一技术组合在相当长的时间内始终是构建可用、可靠的LLM主流路径。直到2025年,一个全新的阶段,基于可验证奖励的强化学习(RLVR),成为事实上的重要突破,并被证实纳入技术架构。
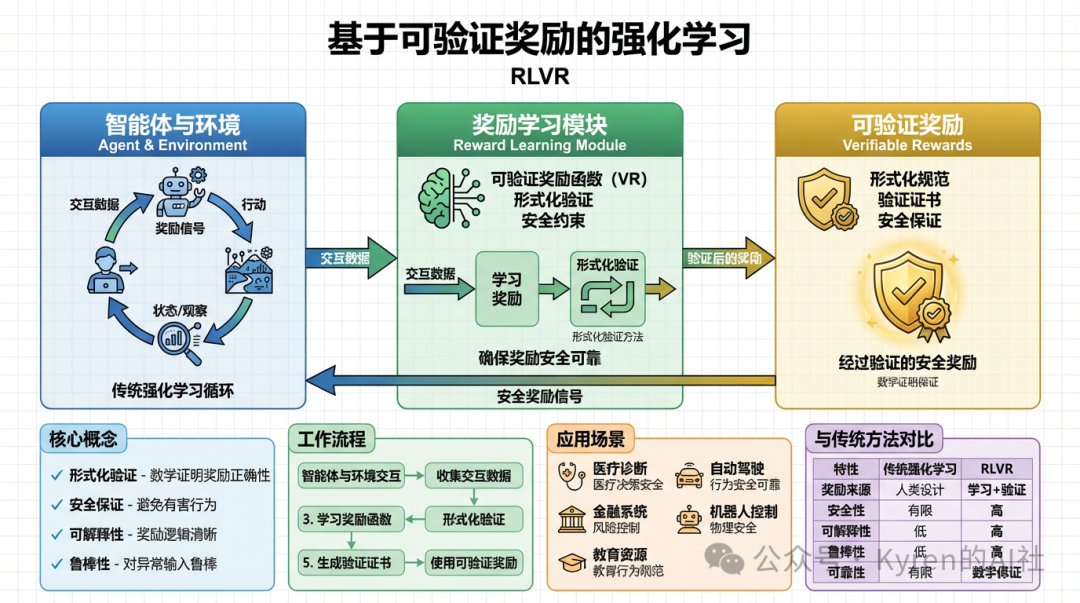
RLVR的核心是让LLM在数学推导、编程解题等可自动验证的环境中进行训练。模型必须针对明确、客观的奖励函数(例如答案是否正确、代码能否通过测试)进行优化,从而自发地发展出类似人类的推理策略:学会将复杂问题分解为多个中间步骤,尝试不同的解题路径,并在迭代中验证与调整。
与SFT和RLHF不同,RLVR依赖的是客观、难以被博弈的奖励信号,这使得训练可以进行更长时间、更稳定的优化。同时,RLVR的计算效率相对较高,因此各实验室将原本用于预训练的部分算力转移到了这一阶段。其结果便是,2025年LLM能力的显著提升,主要不再源于模型规模的扩大,而是来自于大幅延长的强化学习训练时间。
想象你要培养一位顶尖的厨师,三位风格迥异的导师将先后登场。
第一位导师:SFT(监督式微调),手把手教菜谱的大厨。
师傅手把手教徒弟,有明确的示范,但可能缺乏灵活性。在一间标准化的厨房里,导师为你演示每一道经典菜肴的标准做法。“看好了:红烧肉,第一步,五花肉切两厘米见方块。第二步,冷水下锅焯水。第三步......”。你严格按照他的步骤操作,直到复刻出一模一样的成品。SFT微调能够让你精准模仿,你学会了“做什么”以及“怎么做”,没有示范,你就无从下手。如果客人说“不要糖”,你可能会不知所措,缺乏变通。
第二位导师:RLHF(基于人类反馈的强化学习),洞察品味的餐厅经理。
在一家真实营业的餐厅,导师不再给你菜谱,而是让你自由发挥做菜,然后端给客人品尝。你兴冲冲做了一道创新的麻辣蛋糕。客人甲尝了一口皱起眉,客人乙勉强吃完,客人丙觉得有趣。导师收集了这些模糊的偏好,告诉你:“总体反馈不太好,太奇怪了。下次试试更温和的创新。”
通过无数次这样的反馈,你逐渐摸清了大多数客人的口味边界:什么程度的新奇会被接受,什么样的搭配会让人不适。
模型的对齐偏好学习的是“什么让人喜欢”,而不是“什么是标准答案”,好坏标准来自复杂、有时矛盾的人类感受。
第三位导师:RLVR(基于可验证奖励的强化学习),追求真理的科学狂人。
在一个配有精密测量仪器的分子料理实验室,导师给你布置的任务都有无可争议的客观标准。“用这些食材,做出凝固点恰好为零下1度的凝胶。”你无法凭感觉或讨好谁成功。你必须:
- 提出假设:“也许用海藻胶和钙离子反应......”
- 设计实验步骤,并详细记录每一次温度、配比的变化
- 仪器会自动检测每一步的化学物理反应是否合理,最终凝胶的凝固点是否精准达标
在这里,奖励不是“好吃”,而是“符合客观规律”。为了找到办法,你被迫学会了:
- 拆解问题:把大目标分解成可验证的小步骤
- 假设与验证:像科学家一样思考“如果...那么...”
- 自我纠错:在步骤中发现矛盾,立刻回头重想
模型的奖励来自自然规律或逻辑规则本身,无法被讨好或博弈。
RLVR引入了一个全新的能力调控维度:思考时间与推理深度。模型可以通过生成更长的中间推理轨迹来提升任务表现,使得其能力与测试时所投入的计算量成正比。这一特性创造了新的扩展定律,为用户提供了直观的控制手段——更长的“思考”往往意味着更可靠、更深入的结果。
OpenAI于2024年底推出的o1模型首次向世界展示了RLVR的潜力,而2025年初的o3版本则标志着一个明显的转折点。用户能够清晰地感受到,模型不再仅仅是“直接给出答案”,而是展现出具有步骤、验证与调整的内在推理过程,标志着LLM从“响应生成”迈向“思考生成”的新时代。这项技术突破,也让我们看到了模型训练领域未来更丰富的发展方向。对这类前沿AI技术话题的深入探讨,也欢迎访问云栈社区进行交流。
 发表于 2026-1-27 05:49:32
|
查看: 164|
回复: 0
发表于 2026-1-27 05:49:32
|
查看: 164|
回复: 0
