在高并发场景下,比如典型的电商秒杀、直播、社交 feed、数据库读写密集型服务,性能问题往往随之而来。

系统的性能瓶颈通常集中在CPU、内存与I/O(Input/Output)这三个核心资源上。具体哪一项会成为首要瓶颈,则高度依赖于应用本身的特性、系统架构设计以及实际运行环境。
磁盘I/O瓶颈
磁盘,尤其是传统机械硬盘(HDD),通常是整个系统中速度最慢的部件。其随机读写能力可能只有几百 IOPS(每秒输入输出操作数)。即便是固态硬盘(SSD),IOPS也多在几万到几十万级别。相比之下,内存操作是纳秒(10^-9秒)级,而CPU运算更是皮秒(10^-12秒)级,差距巨大。
高并发往往意味着海量的随机I/O操作。例如秒杀系统中的库存扣减、订单系统的频繁创建与状态更新、日志系统的密集写入,以及数据库的索引扫描、事务日志(redo log)和二进制日志(binlog)刷盘。这些操作很容易在瞬间将I/O吞吐打满。
典型表现:
- 使用
iostat 命令查看,会发现 %util(磁盘利用率)指标接近100%,await(平均I/O等待时间)飙升到几十甚至几百毫秒。
- 在
top 命令的输出中,wa(I/O wait,等待I/O的CPU时间百分比)数值会非常高。
- 数据库层面,慢查询数量激增,系统整体TPS(每秒处理事务数)突然下降。
一个经典的案例就是 MySQL 在高并发写入场景下。当配置 innodb_flush_log_at_trx_commit=1 以保证最高级别的持久性时,每次事务提交都需要同步将redo log写入磁盘(涉及双写缓冲等机制),磁盘I/O很容易成为首个也是最主要的性能瓶颈。
CPU瓶颈
当CPU成为瓶颈时,表现为一个或多个处理器核心的利用率长期接近或达到100%,系统整体响应时间随着并发请求的增长而显著上升。计算密集型业务,如数据加密解密、图像/视频转码处理、复杂的业务逻辑运算等,更容易触发CPU瓶颈。
判定方法包括监控CPU使用率、观察是否发生频繁的上下文切换(context switch),以及查看系统负载(load average)是否异常升高。
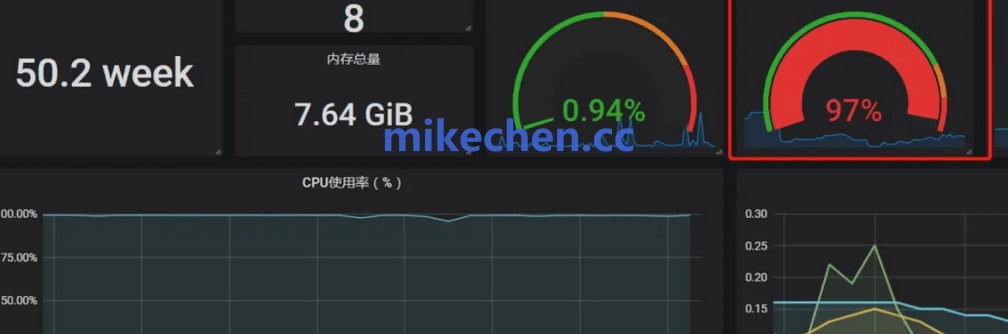
缓解策略:
- 优化算法和代码:从根源上减少不必要的计算量。
- 使用并行/异步处理:充分利用多核能力,避免阻塞。
- 扩大CPU资源:升级更多核心或更高主频的处理器。
- 利用硬件加速:对于特定计算(如矩阵运算、加密),考虑使用GPU或专用芯片(如DPU)。
- 减少冗余计算:通过缓存计算结果等方式避免重复工作。
内存瓶颈
内存瓶颈的表现形式多样,主要包括可用物理内存不足、操作系统频繁进行内存换页(swap)操作、垃圾回收(GC)时间异常延长、乃至直接的内存分配失败,这些都会导致服务响应延迟增加甚至直接不可用。
有状态服务、依赖大量内存缓存(如 Redis)的应用,或是存在内存泄漏问题的场景,都容易触发内存瓶颈。
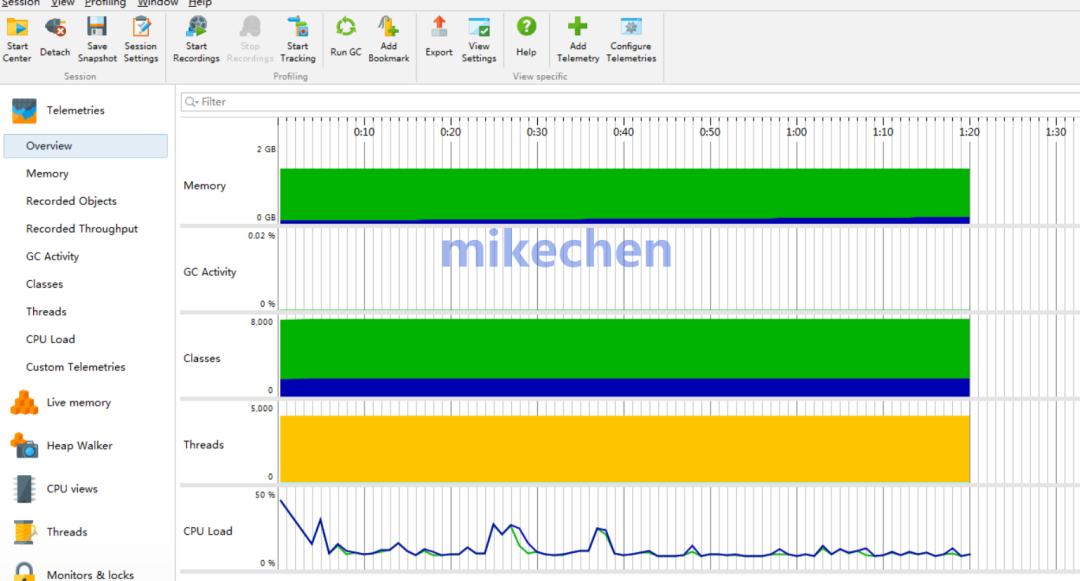
判定可通过监控内存使用率、交换区(swap)使用量、分析GC日志以及观察内存分配失败率来实现。
缓解措施:
- 增加物理内存:最直接的方式,但需考虑成本与扩展性。
- 优化内存数据结构与缓存策略:例如,使用更节省内存的数据结构,或调整缓存淘汰算法(如LRU)。
- 使用外部存储:将非热点的数据从内存移至分布式缓存 或数据库,减轻内存压力。
- 改进垃圾回收参数与内存管理策略:针对Java等有GC的语言,合理设置堆大小、选择适合的垃圾收集器等。
总结
在高并发系统的性能调优中,识别核心瓶颈是第一步。磁盘I/O因其物理限制常成为数据库类应用的“阿喀琉斯之踵”;CPU瓶颈则在计算密集任务中凸显;而内存瓶颈则与数据规模、缓存策略和代码质量紧密相关。
现实中,瓶颈往往不会孤立存在。例如,I/O等待高会导致CPU空闲(wa高),而频繁的GC又会挤占CPU计算资源。因此,需要结合具体的监控工具(如 top, vmstat, iostat, APM工具)进行综合研判。
如果你想深入探讨更多关于系统架构或MySQL性能调优的实践,欢迎在云栈社区与更多开发者交流经验。 |  发表于 2026-1-27 05:51:51
|
查看: 195|
回复: 0
发表于 2026-1-27 05:51:51
|
查看: 195|
回复: 0
