Flink CDC 如今已成为实时数据同步的标配工具,在面试中更是高频考点。掌握其核心原理,不仅能清晰回答问题,更能体现你解决实际问题的能力。以下就针对最常被问到的三个问题,进行深入拆解。
Flink CDC 如何实现“无锁读取”?会影响生产数据库吗?
这是一个关于实现原理和影响评估的问题。Flink CDC 实现“无锁”的核心,在于它并非通过传统查询方式访问数据库表。
✅ 核心原理
Flink CDC(Change Data Capture)基于 Debezium 引擎,通过读取数据库底层的日志文件来捕获数据变更,而不是执行 SELECT 查询:
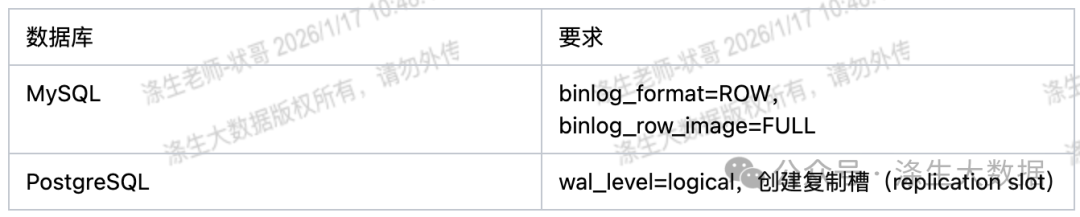
- MySQL:读取 binlog(需开启 ROW 格式)
- PostgreSQL:读取 WAL(Write-Ahead Log)
- Oracle / SQL Server:通过 LogMiner 或 CDC 功能
整个过程 不访问业务表的数据页,因此无需对表加锁(无论是表锁还是行锁),对线上 OLTP 系统的侵入性极低。
✅ 前提条件
要成功开启这一读取模式,源数据库需要满足特定的配置要求,这也是面试官可能追问的细节:
✅ 性能影响评估
对于生产数据库的影响,我们可以从几个维度来评估:
- CPU/IO 开销:极低。CDC 任务仅解析日志流,不触发数据库的查询优化器和执行计划。
- 网络带宽:与数据库产生的变更数据量成正比,通常可以通过压缩来减少传输量。
- 磁盘风险:需要重点监控源库的 binlog 或 WAL 日志保留策略,避免日志因消费不及时而堆积,导致磁盘爆满。
在准备 面试 回答时,一个结合具体业务数据的例子会更有说服力。例如:“我们在生产环境使用 Flink CDC 同步核心订单表(日增约 5000 万条),监控显示源数据库的 CPU 使用率波动始终低于 2%,完全满足业务对数据库稳定性的 SLA 要求。”
Flink CDC 如何保证 Exactly-Once 语义?
这个问题考察的是对 Flink 状态一致性机制的理解。Flink CDC 作为 Source 算子,其一致性保障深度依赖于 Flink 框架的 Checkpoint 机制。
✅ 端到端 Exactly-Once 的实现机制
- 状态快照:在 Flink 作业进行 Checkpoint 时,Flink CDC Source 会将当前消费的日志位点(例如 MySQL 的
binlog filename 和 position)作为状态保存到状态后端(如 RocksDB)。
- 故障恢复:当任务因故障重启时,Flink 会从最近一次成功的 Checkpoint 恢复状态,CDC Source 便能准确地从之前记录的位点开始重新消费数据,避免数据丢失或重复。
- 下游配合:要实现真正的端到端精确一次,还要求 Sink 端支持幂等写入或事务提交,例如写入支持事务的 Kafka、使用 Unique 模型的 Doris,或使用 Hudi 的 MOR 表。
流程可以简化为:[MySQL] → (binlog) → [Flink CDC Source] → [Flink Job] → [Kafka/Doris],其中 Checkpoint 负责保存并恢复消费位点。
❌ 常见误区
仅依靠数据库驱动或连接器的 auto-commit 功能,只能实现 At-Least-Once(至少一次)语义。
✅ 正确做法
必须启用并合理配置 Flink 的 Checkpoint 机制(建议间隔设为 30 秒到 1 分钟)。
以下是一个 MySQL CDC Source 的配置示例,注意需要在构建 Source 的同时,在 Flink 环境中启用 Checkpoint:
MySqlSource.<String>builder()
.hostname("localhost")
.port(3306)
.databaseList("inventory")
.tableList("inventory.products")
.username("flinkuser")
.password("flinkpw")
.deserializer(new JsonDebeziumDeserializationSchema())
.build();
// 同时在 ExecutionEnvironment 或 StreamExecutionEnvironment 中启用 checkpoint
env.enableCheckpointing(60_000); // 60秒
结合具体技术栈的回答示例:“我们通过配置 Flink 的 Checkpoint(间隔60秒),配合下游 Doris 表的 Unique Key 模型,实现了从 MySQL 到数据仓库的端到端 Exactly-Once 语义,后续数据对账做到了零误差。”
全量 + 增量如何无缝衔接?会不会丢数据?
这个问题关注 Flink CDC 在初始化同步大表时的数据一致性能力。传统工具需要手动协调全量和增量阶段,而 Flink CDC 2.0+ 引入了更优雅的解决方案。
✅ Flink CDC 2.0+ 的“增量快照”机制
该机制(Incremental Snapshot)实现了全量初始化与增量追加大数据的自动、平滑衔接:
- 启动标记:任务启动瞬间,先记录当前 binlog 的精确位点,作为“高水位线”(high watermark)。
- 全量读取:根据表的主键将全表数据划分为多个 chunk,并行读取。这个过程支持断点续传。
- 增量切换:全量读取完成后,自动从之前记录的“高水位线”开始消费 binlog,进入增量同步阶段。
- 变更处理:在全量读取过程中,如果源表产生了新的数据变更,这些变更会被 binlog 记录。在增量阶段,这些变更会被正确重放,从而确保 没有任何数据丢失。
✅ 关键配置(MySQL)
启用此功能需要在构建 CDC Source 时设置相应的 Debezium 属性:
.debeziumProperties(
PropertiesUtil.propertiesOf(
"snapshot.mode", "initial",
"scan.incremental.snapshot.enabled", "true", // 启用增量快照
"scan.incremental.snapshot.chunk.size", "8192" // 每个分片的大小
)
)
✅ 数据一致性保障
- 全量一致性:全量读取利用数据库的 MVCC 机制(如 InnoDB),获取一个一致性快照,避免脏读。
- 无缝衔接:增量阶段从精确的“高水位线”开始,与全量数据既无重叠也无间隙。
- 内存可控:通过分块读取,即使是亿级大表同步,也不会导致内存溢出。
一个有经验的回答可以这样组织:“我们曾用 Flink CDC 同步一个超过 2 亿行的用户维度表。全量初始化耗时约 1.5 小时,任务自动切换至增量模式,监控显示切换瞬间没有产生数据缺口,业务侧对同步过程完全无感知。”
✅ 核心要点总结
为了方便记忆与面试陈述,可以将以上三个问题的核心关键词与回答要点总结如下:

深入理解 Flink CDC 的这些机制,不仅能让你在 大数据 开发的面试中游刃有余,更是设计稳定、高效实时数据管道的基础。希望这篇解析能帮助你在技术道路上更进一步。如果你想查看更多实战经验或与同行交流,欢迎访问 云栈社区 的相关板块。
 发表于 2026-1-30 18:32:56
|
查看: 250|
回复: 0
发表于 2026-1-30 18:32:56
|
查看: 250|
回复: 0
