在上一节探讨了访问延迟错乱的解决方案后,本节我们将目光转向访存时序性中另外两个棘手的问题:访问冲突和预测执行导致的错乱。对这两个问题的剖析与解决,将为“访存时序性”这个系列话题画上一个阶段性的句号。
解决访问冲突错乱问题
首先要明确,访问冲突的本质其实与严格的时序关联不大。它源于多个处理器核心(Core)试图同时向同一内存地址执行 store(写入)操作。硬件层面通常会为对同一地址的操作进行排序,确保所有访问都能完成,但硬件仅依据其接收指令的顺序或内部的仲裁机制来抉择先执行哪一笔。这种机制就可能导致操作乱序,最终写入的数据与程序员预期的逻辑顺序不符。
解决这类问题的经典方案依然是加锁。通过锁机制将可能产生冲突的临界区代码保护起来,确保同一时刻只有一个核心能执行该段代码,从而序列化对共享变量的访问。

上图清晰地对比了无锁与有锁场景下的指令执行流程。在无锁情况下,Core1和Core2可以同时加载(load)、递增(inc)、存储(store)addr0 的值,这必然导致最终结果的不确定性。而在有锁情况下,每个核心在操作前必须先获得锁(Lock()),操作完成后通过内存屏障指令(如 sfence)确保所有访存操作对其它核心可见,最后再释放锁(unlock()),从而保证了操作的原子性与顺序性。
解决预测执行错乱问题
让我们回顾之前提到的预测执行例子。Core2 基于分支预测,提前加载了 addr0 的值到寄存器 reg3,但后续条件判断发现预测失败(addr1 的值并非预期值)。此时,Core2 使用了基于错误预测路径所加载的 addr0 旧值参与运算,导致了数据不一致。
解决预测执行带来的数据错乱,锁机制同样有效。将可能被预测执行错误加载的共享变量访问放入临界区,即可确保在锁的保护下,任何核心(包括正在做预测执行的核心)都必须遵守正确的程序逻辑顺序来访问数据,从而避免了使用“脏”的预测数据。
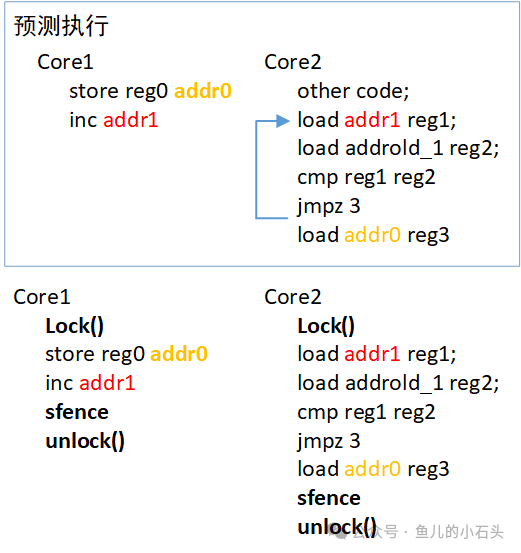
如上图所示,在引入锁机制后,无论 Core1 对 addr0 和 addr1 的更新操作,还是 Core2 中对 addr1 的读取和条件判断,都被约束在锁定义的临界区内。Core2 在获得锁之前,无法执行 load addr0 reg3 这条可能被预测的指令,从而从根本上杜绝了使用错误预测值的可能性。
总结与回顾
至此,我们关于访存时序性引发的几类主要问题及其解决方案的探讨就告一段落了。(注:系列标题虽沿用“缓存”,但讨论的问题实质是处理器整体的内存访问模型,此处暂不做标题修正)。
我们来做一个简短的回顾:当程序中存在共享变量时,在多核并发环境下,几乎都需要引入锁(或等价的同步原语)来保证访问的互斥性,防止冲突。同时,在释放锁之前,务必使用合适的内存屏障指令(如sfence),以确保本核心的所有访存操作都已完成并全局可见,从而维护内存一致性。
当然,现代处理器和编译器等软件栈包含了大量复杂的优化策略(如流水线、乱序执行、缓存预取等)来提升效率,它们与内存模型的交互极为精妙。这部分内容超出了本文的范畴,就不再赘述,以免画蛇添足。理解这些基础的内存同步原理,是深入计算机体系结构和内存管理更高级主题的坚实一步。如果你对这类底层技术讨论感兴趣,欢迎在云栈社区继续交流探索。 |  发表于 2026-1-31 00:58:12
|
查看: 143|
回复: 0
发表于 2026-1-31 00:58:12
|
查看: 143|
回复: 0
