
过去数月,我们在快手内部围绕真实的业务需求场景,深入探索了 Java 后端 AI Coding 的落地方案。经过一系列实践与迭代,主站团队已成功将真实需求的 AI 代码采纳率逐步提升至 60%~90%。我们不仅沉淀出了一套面向后端的“码图”框架,更初步摸索出一种人与 AI 协同的 AI Native 研发范式。本文将结合一个具体的真实案例,深入剖析 Java 后端 AI Coding 的核心难点,并分享我们的解决方案与思考。
一、从一个真实案例说起
在实际项目开发中,我们曾碰到这样一个需求:在一个现有的后台管理页面里,需要新增一个筛选条件,同时新增若干个字段用于列表展示。乍一看,这只是一个典型且复杂度不高的增删改查需求。
然而,当我们真正开始拆解任务时,才发现它远非表面那么简单。这个需求横跨了完整的服务端调用链路,涉及以下关键环节:
- Controller 层负责接收、封装与校验请求参数;
- Service 层需要协同多个服务进行数据查询与处理;
- DAO 层执行核心的列表数据查询与总数统计;
- VO / Helper 层负责数据的组装与结构映射;
- DB 层则可能需要进行字段评估甚至结构调整。
最终,仅仅是“新增筛选”和“新增展示”这两个看似微小的改动点,实际涉及的工作量却相当可观:共需调整 7 个类,进行 8 处关键代码修改,并且必须确保多层隐式依赖关系保持一致。
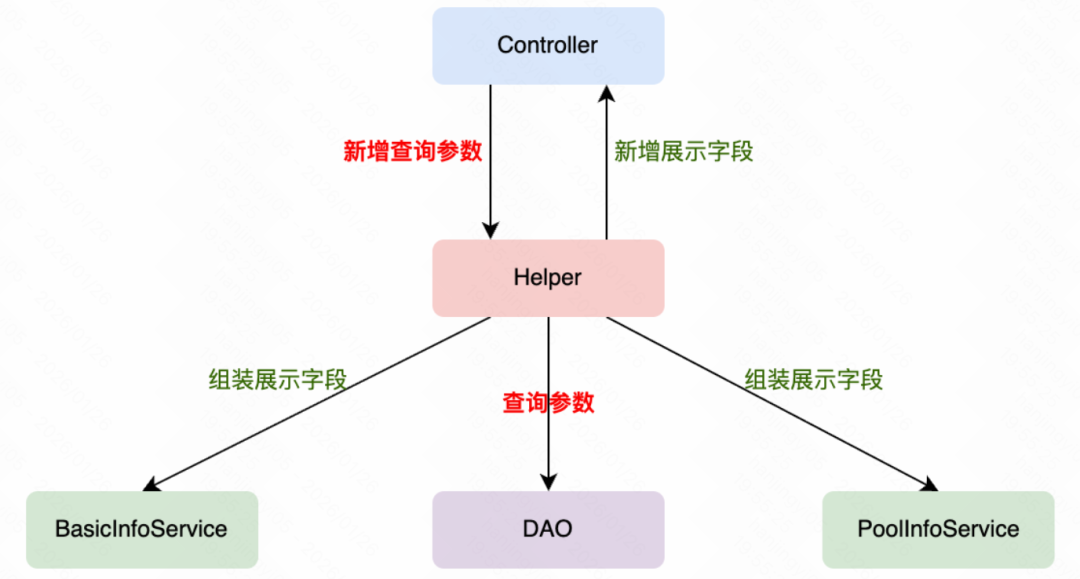
简单的改动流程示意图
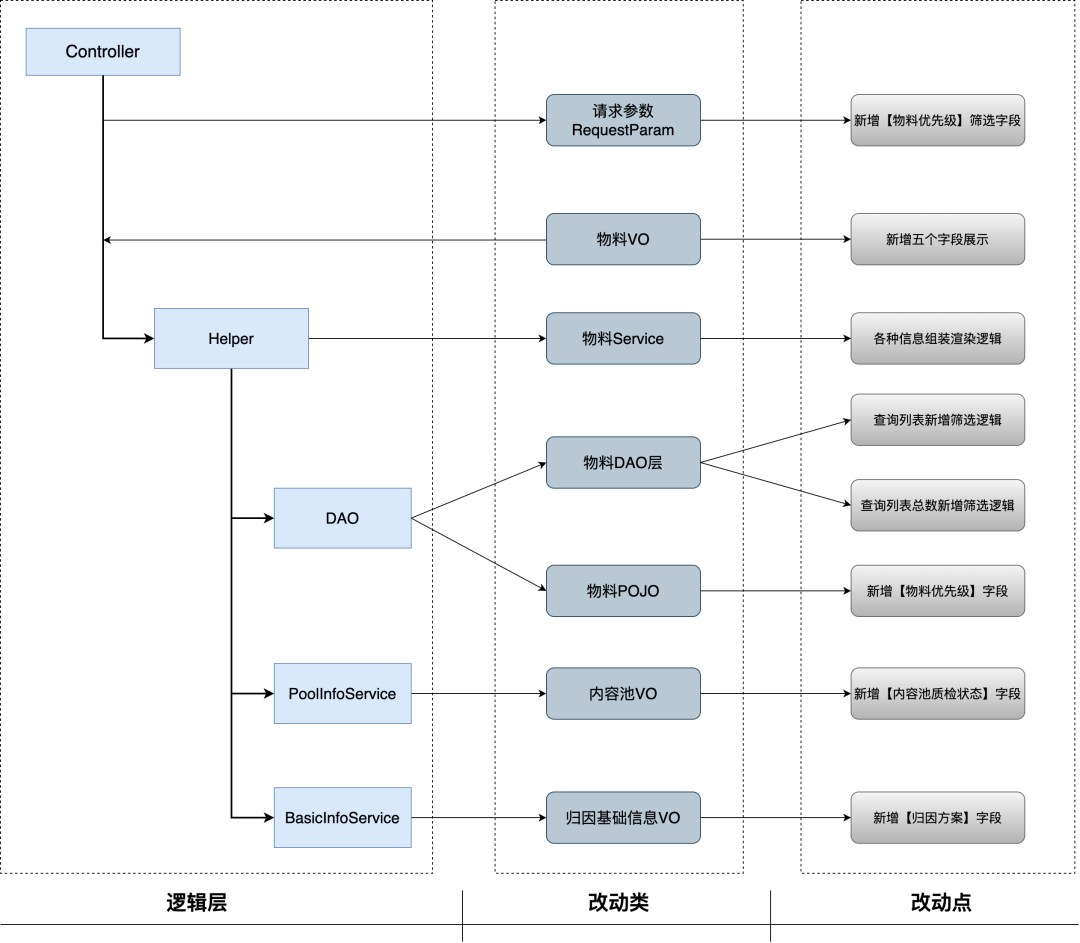
详细的调用链路图
1、把业务需求直接“扔给 AI”会发生什么?
在没有任何额外上下文和工具辅助的情况下,我们尝试直接将需求描述交给 AI,让它“帮忙改代码”。结果并不理想,暴露出的问题非常典型。
问题一:漏改——只看到函数,看不到流程
在该案例中,列表查询和计算总数是紧密关联、成对出现的逻辑。但 AI 在修改时,只调整了列表查询的条件,却完全遗漏了总数统计的逻辑。这直接导致前端分页信息与实际数据量严重不符。这表明,AI 虽然能处理局部代码逻辑,但缺乏对整体业务流程的把握能力。
问题二:错改——不理解数据结构与职责边界
新增的展示字段实际上来自多个不同的 Service,需要经过 Helper 层统一组装后才能返回。然而,AI 无法知晓哪些字段已存在于 Service 的返回中,也不清楚每个字段应该归属于哪一层的 VO 数据结构。最终生成的代码要么留下大量“TODO”或默认值,要么将字段错误地写入顶层对象,从而破坏了原有的数据架构设计。
上述问题分布在 Controller、Service、DAO、VO 各层,但究其根本,原因是一致的:AI 只能感知到被提供的局部上下文,无法感知到完整的调用链条以及隐式的依赖关系。 它能正确地修改一个函数,却无法判断这个函数是否与其他逻辑成对出现、修改是否需要沿着调用链同步传播,更不理解数据在不同层级中的真实语义和归属。
二、后端AI Coding难在哪里?
行业内普遍共识是,前端 AI Coding 的发展领先于后端。那么,为什么后端 AI Coding(尤其是 Java 领域)的推进速度相对缓慢?在不断探索中我们认识到:AI 理解前端工程,如同“搭积木”般直观;而面对后端工程,则仿佛置身于一座结构复杂的“迷宫”。如何让 AI 顺利穿越这座迷宫,正是后端 AI Coding 需要攻克的核心难题。
与前端“所见即所得”的开发模式截然不同,后端 AI Coding 面临的核心挑战在于:PRD(产品需求文档)并不等价于后端可直接执行的“工程事实”。 实际上,后端工程真正的复杂度几乎全部隐藏在 PRD 之外,这些关键信息散落在成百上千个文件、模块与配置之中,PRD 既不可能也难以完整呈现。
2.1 PRD并不是后端可以直接执行的“工程语言”
从一份 PRD 出发,经验丰富的研发人员能够自然地完成一系列“脑补”工作:明确哪些改动属于后端范畴、确定请求的入口位置、判断是否涉及数据库操作、评估是否需要联动其他模块、查找系统中是否已存在相似逻辑以供参考等。
然而,这些对人类而言属于开发常识的信息,对 AI 来说却如同巨大的信息断层。 PRD 通常只会表述“前端需要改动,后端接口也要扩展字段”,却不会进一步说明:后端的开发边界具体在哪里?改动是发生在 Controller 层、某个定时任务,还是一个 RPC 接口?字段是来源于数据库、下游服务,还是历史计算结果?这次改动是否会对缓存、搜索引擎索引或异步数据处理链路产生影响?
这些在日常开发中属于后端交付的最小必要信息,对 AI 而言,并非是“没看清楚”,而是压根就没有被提供。
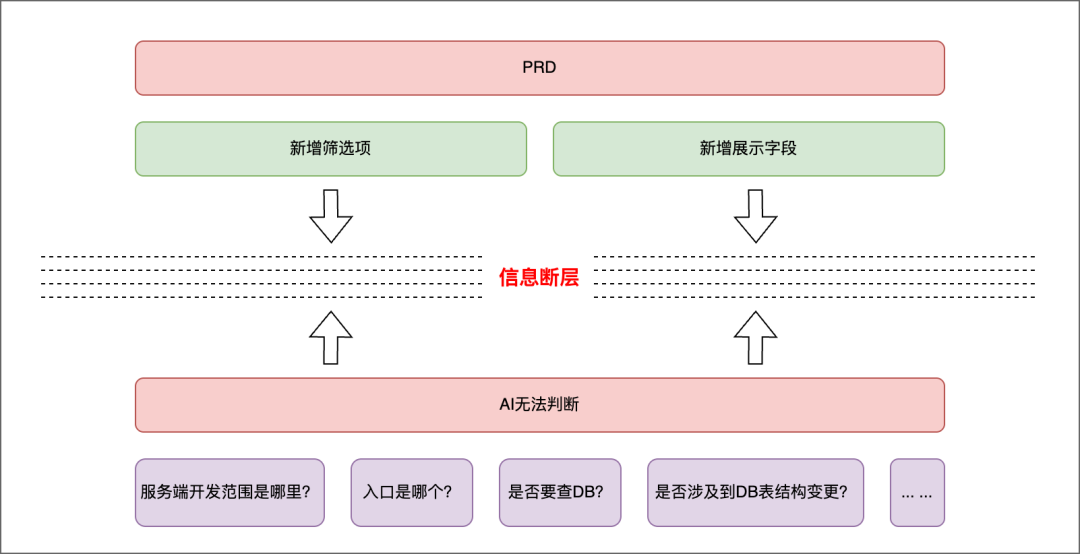
PRD与AI理解之间的信息断层
2.2 后端真正的复杂度,几乎全部藏在 PRD 之外
更为关键的是,后端的复杂度并非直观地体现在接口签名上,而是深藏在业务流程和隐式约束之中。 以一次常见的“数据提交”操作为例,在真实的分布式系统架构里,其背后往往涉及一连串复杂逻辑:
- Service 内部的同步 RPC 调用;
- 本地数据库事务控制与回滚逻辑;
- 数据库写入操作及由此产生的 binlog;
- 异步消息链路的触发(如发送 Kafka 消息、更新 Elasticsearch 索引、刷新分布式缓存);
- 跨模块的数据最终一致性与状态收敛。
这些逻辑构成了后端工程的“主体结构”和血脉,但 PRD 既不会也无法对这些复杂流程进行详细描述。这就导致 AI 虽然能够看到“需要修改某个接口”,却完全无法预见一次简单的改动会在整个系统中引发多少连锁反应。
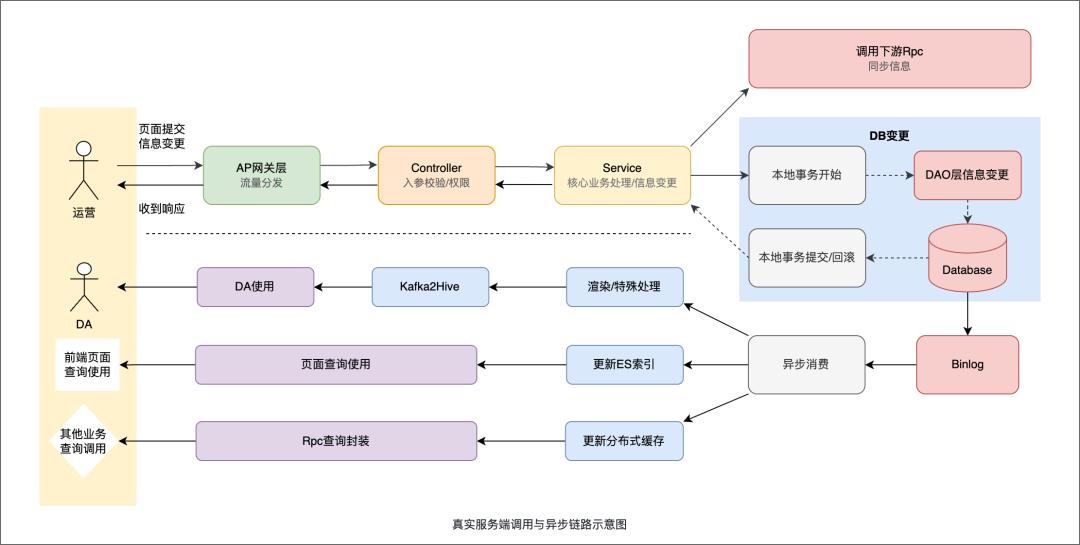
真实服务端调用与异步链路示意图
三、从 Context 到 Control :后端 AI Coding 的两阶段演进
在探索 Java 后端 AI Coding 的实践中,我们并非一帆风顺,而是经历了两次明显的“卡住—反思—重构”过程。回顾这两次演进,背后对应着两个逐渐清晰的认知:
- 第一阶段,我们致力于解决 AI 能否看到系统全貌(Context)的问题;
- 第二阶段,则聚焦于即便 AI 能看到系统全貌,能否实现稳定、可靠执行(Control)的挑战。
3.1 第一阶段:解决上下文(Context)问题
回顾前文的案例,核心问题是:AI 能修改局部代码,却无法理解这些代码在整个系统中的位置。 这并非模型不够“聪明”,而是因为它缺乏像人类研发者那样的系统级视角。这种视角,在后端工程中,源于对三件事的理解:
- 代码是如何分层组织的;
- 各类代码元素(类、方法、字段)之间是如何关联的;
- 一次具体需求,会沿着怎样的调用路径与数据流进行传播。
3.1.1 明确代码层级结构
在研发人员的认知里,一个后端工程天然存在多种划分方式。从职责视角看,Controller、Service、DAO、Helper 各自承担明确的职责;从系统边界视角看,又可划分为本服务、下游依赖服务以及公共组件。
然而,这些划分往往仅存在于团队的“共识”之中,并未被机器显式地感知和理解。因此,我们的第一步并非急于让 AI 写代码,而是将这些隐性的层级结构显性化,明确每一层的职责、规定哪些层之间允许直接交互、识别哪些改动天然具有“扩散效应”。
以下是从两种不同视角梳理的代码层级结构:

按照系统内部功能职责划分

按照系统边界和服务/组件间职责划分
3.1.2 从“类文件”到“代码元素”
仅仅知道“这是 Service,那是 DAO”还远远不够。在真实的工程改动中,变化并非发生在“类”这个粗粒度层面,而是发生在更细粒度的代码元素之间。比如,一个方法调用了谁、一个字段被哪些逻辑依赖、一个构造器是否隐式影响了初始化流程。
因此,我们进一步将分析的粒度下沉到类内部的字段、方法、构造器以及它们之间的关系上,目的是让 AI 能够理解“修改这一行代码,究竟会牵动系统中的哪些地方”。
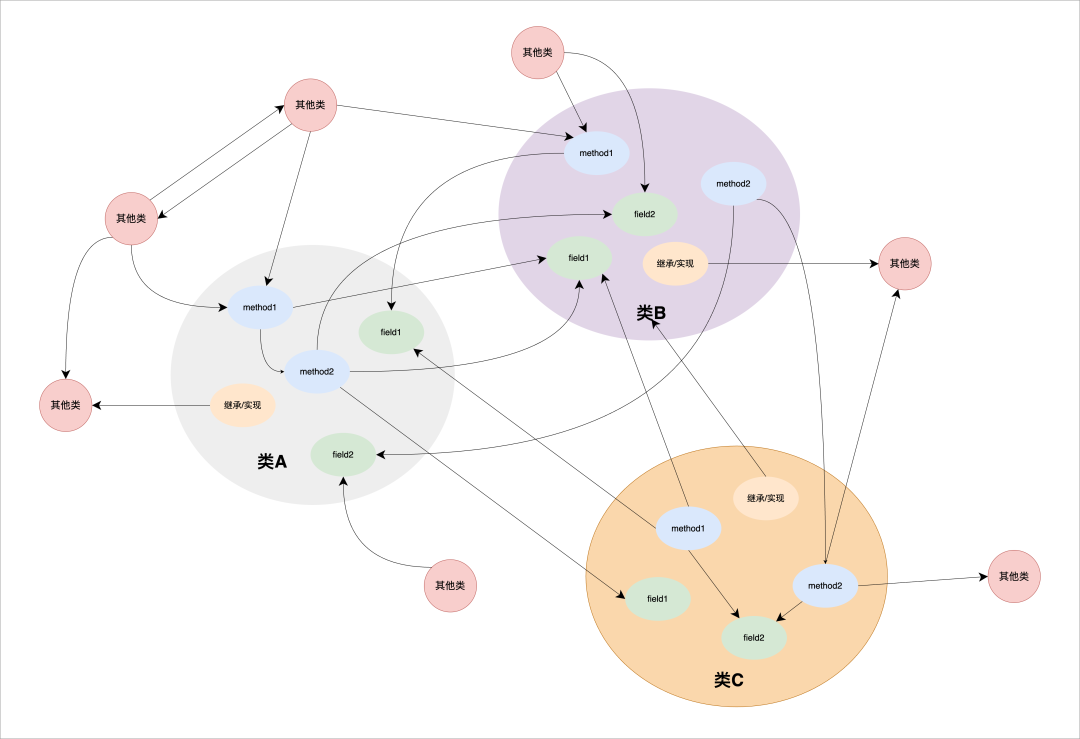
类及其内部元素关系示意
3.1.3 构建“代码元素关系图谱”(Code Graph)
当我们将关注点从“文件”转向“代码元素及其关系”后,一种更自然的抽象方式出现了:整个代码库本质上就是一张庞大的有向依赖图。其中,节点代表字段、方法、构造器等具体代码元素;边则代表调用、引用、继承、实现等关系。
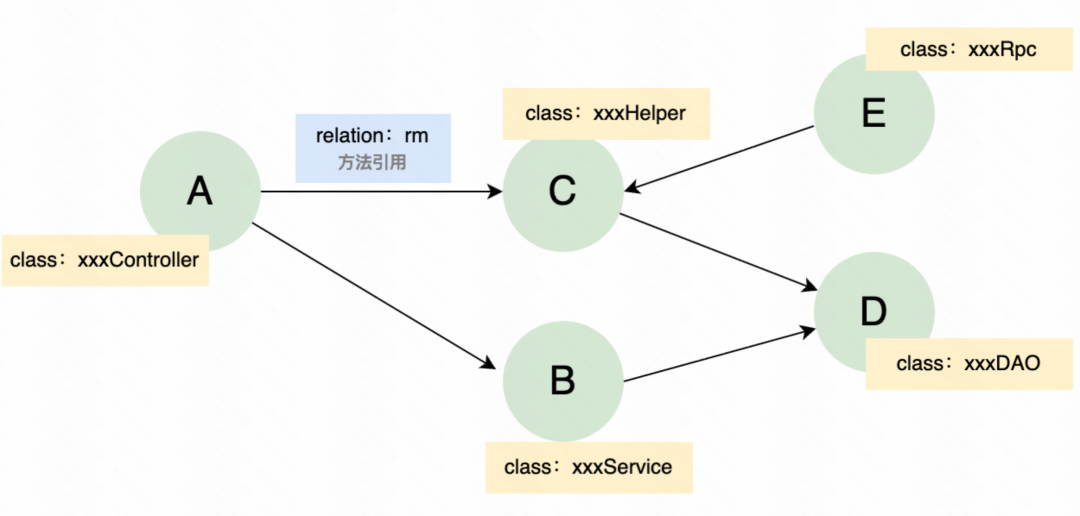
简化的代码元素关系图示例
我们选择从项目编译后的字节码入手,来构建这张代码元素关系图谱,并将其持久化存储到图数据库中。这样做的好处是,系统的“隐式结构”第一次变成了可查询、可遍历、可计算的实体。
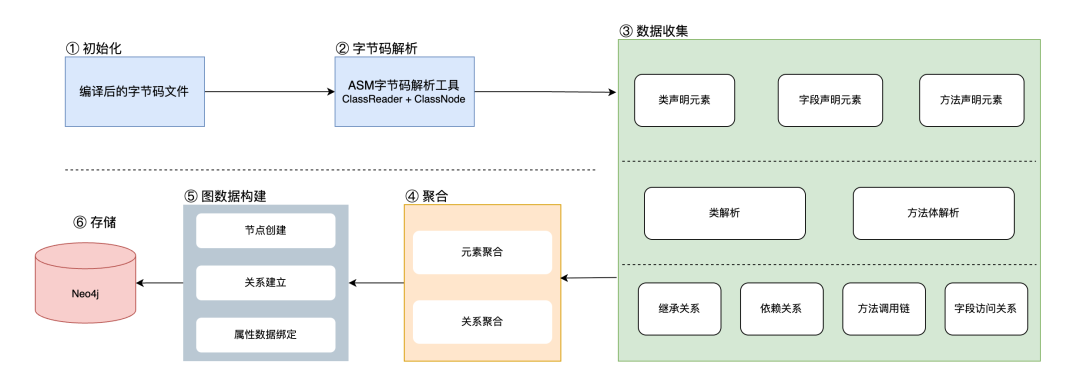
从字节码构建代码图谱的流程
3.1.4 从图谱到智能:AI 借助代码图谱获得系统视角
当代码关系以图的形式存在后,AI 不再需要“猜测”系统结构。通过图数据库查询语言(如 Cypher),AI 可以明确地知道:一个类的上下游依赖有哪些、一个方法被哪些调用路径所使用、一次代码改动可能的影响范围有多大。这一步,标志着 Context 不再只是静态的文本描述,而是结构化、可推理的工程事实。
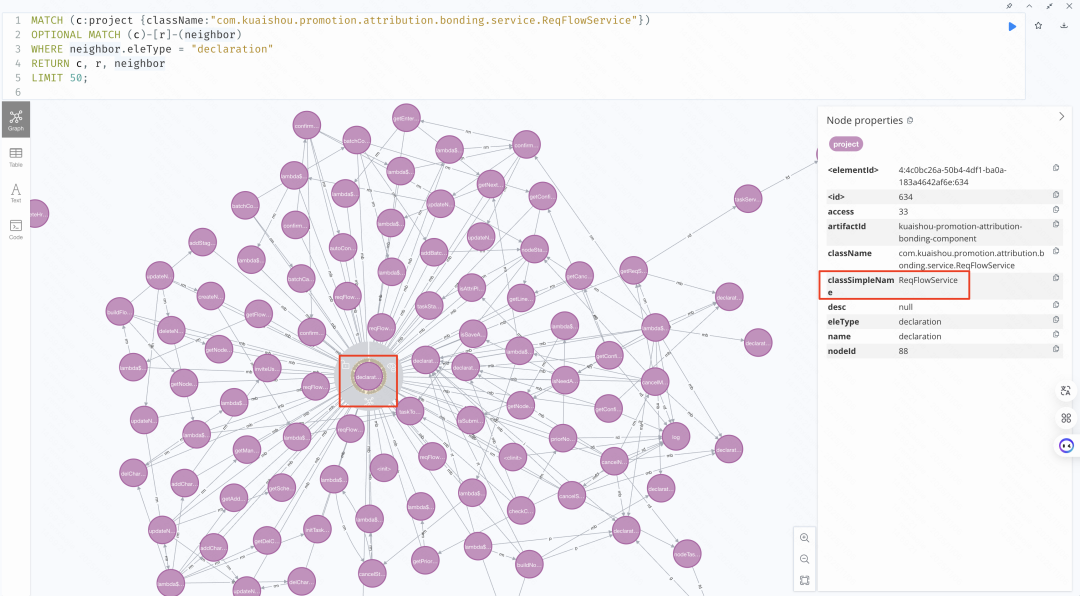
通过Cypher查询代码图谱
最终,我们解决 Context 问题的整体设计分为三层:内容基座层、信息补充层以及大模型执行层。
- 内容基座层:将整个代码库抽象为代码元素关系图谱,把工程事实转化为可计算的结构。
- 信息补充层:引入面向 AI 的 Context 约束与规范(如可用字段、关系约束、使用规范),补齐 AI 做出准确判断所需的关键信息,同时对其“发挥空间”进行合理控制。
- 大模型执行层:大模型基于代码图谱生成精确的 Cypher 查询,通过查询结果获取上下游依赖、影响范围与修改路径,在明确的约束和规范下做出工程级决策。
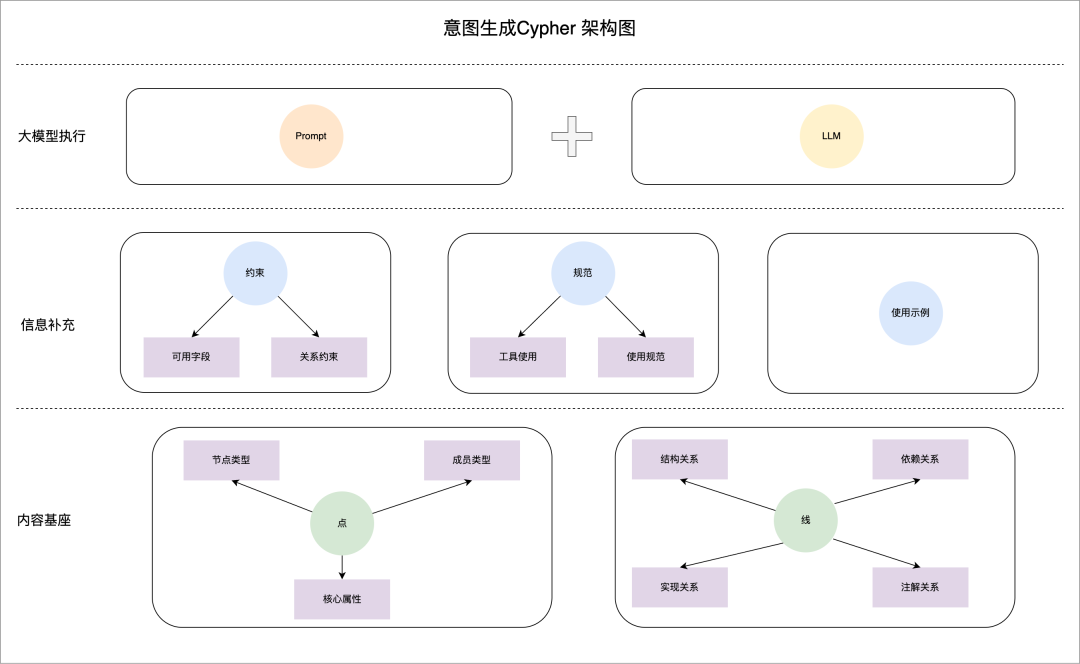
意图生成Cypher查询的架构图
3.2 第二阶段:解决可控性(Control)问题
成功解决 Context 问题后,AI Coding 的效果确实有了显著提升。但很快,新的挑战接踵而至。
3.2.1 单Agent,无法稳定承载复杂任务
当我们尝试用一个大模型(单Agent)串联起需求理解、方案推导、代码生成、多文件修改这整个复杂流程时,问题开始集中爆发:上下文长度迅速膨胀,Prompt 变得冗长而脆弱,不同阶段的信息相互干扰,模型的“幻觉”开始在看似合理的地方出现。这让我们意识到:Context 解决的是“看不看得到”的问题,但并没有解决“看到之后能不能被稳定、可靠地使用”的难题。
3.2.2 从 Prompt 驱动,到代码驱动的 Multi-Agent
真正的转折点在于我们放弃了“一个万能 Prompt 解决所有问题”的思路,转而引入了 Multi-Agent / SubAgent 的协作架构。该架构的核心目标有两个:一是严格控制单个 Agent 的上下文长度和职责范围,避免信息过载;二是让不同阶段、不同类型的任务彼此隔离,减少相互干扰。
在这种架构下:
- 主控 Agent 只负责任务的宏观拆解与最终结果的汇总。
- 各个子 Agent 则专注于单一的、明确的目标(如图谱检索、语义检索、方案生成)。
- 具体的代码修改动作,交由 kwaipolit(快手内部自研的 Copilot 工具)在严格的工程约束下完成,而非由大模型自由生成。
如此一来,整个工作流从“由冗长的 Prompt 驱动”转向了 “由清晰的任务代码和 API 调用驱动” ,整个过程的确定性和可控性得到了质的提升。

Multi-Agent 主流程示意图
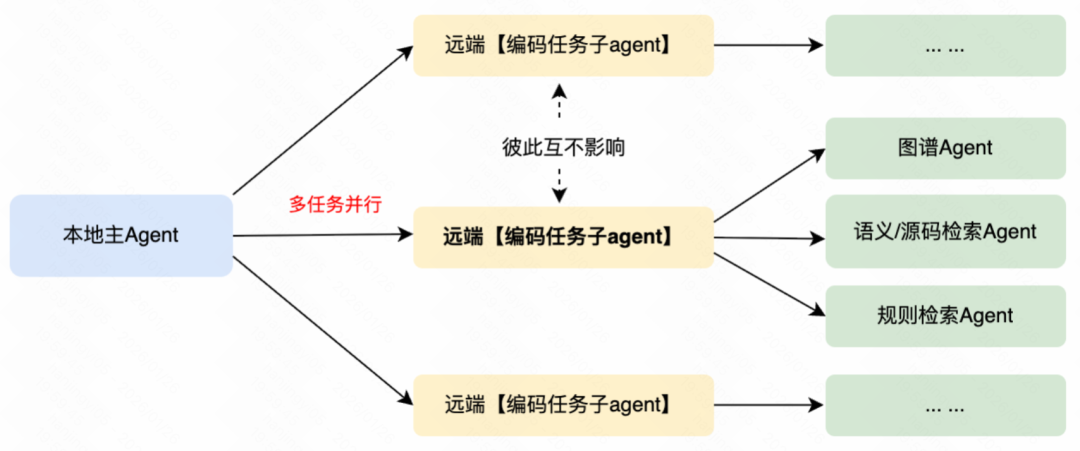
Multi-Agent 并行执行流程示意
四、从“写代码”到“设计执行”:后端 AI Coding 的新范式
前面我们讨论了如何通过 Context 和 Control 让 AI 在后端工程中“看得见、走得稳”。接下来要探讨的是,当 AI 真正具备了工程级的可靠执行能力后,工程师的角色和工作内容会发生怎样的根本性变化?
4.1 当AI成为工程执行者,工程师在做什么
在传统的研发模式下,工程师往往一人分饰三角:需求理解者、方案设计者和具体实现者。而在后端 AI Coding 成熟之后,这三者开始出现清晰的角色分离。在新的研发范式中,AI 不再仅仅是“补全代码的辅助工具”,而是转变为可靠的“工程执行者”;而工程师的核心职责,则开始前移并上移,聚焦于更高价值的设计与决策。
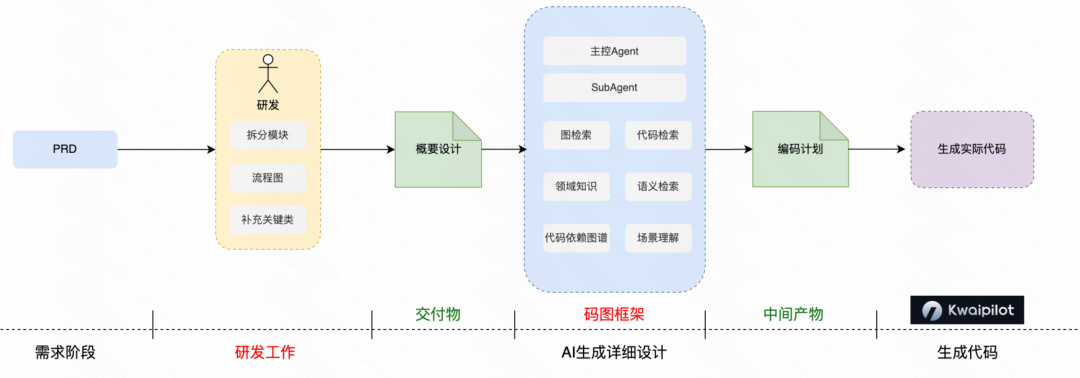
AI Coding 全流程与角色演进
在新的研发流程中,工程师不再直接编写最终的业务代码,而是将主要精力集中在以下三方面:
- 从 PRD 中拆解模块边界:明确哪些改动属于同一个工程问题,哪些是独立的不同子问题,为后续的自动化工作划定清晰的范围。
- 运用流程图描述主干逻辑:通过 Mermaid 等工具,把核心的调用路径、数据流和状态转换显性化,让复杂的系统逻辑一目了然。
- 补齐关键参考类与入口信息:提供系统中现有的、与本次改动相关的“锚点”类或方法,帮助 AI 系统快速定位工程上下文。
通过完成上述工作,工程师最终产出的是一份 “概要设计” ,而非一行行实现代码。这份概要设计就如同建筑行业的施工蓝图,为后续的自动化工程实施提供了清晰、无歧义的指导。
在概要设计交付之后,后续工作便交由 AI 系统自动执行。核心主控 Agent 读取这份设计文档,调度多个子 Agent 分别完成图检索、代码检索、语义检索,进行深度的场景理解与动作决策,最终生成一份可执行、可校验的“编码计划”。最后,在 IDE 中,编码计划被转化为真实的代码修改。
简而言之,在新范式下,人类工程师负责“想清楚要做什么以及为什么这么做”(设计),而 AI 则负责“在严格的工程约束下把事情高效、准确地做完”(执行),二者优势互补,各司其职。
在新的研发范式下,前文那个最初落地失败的案例,其工程师产出的概要设计示例如下:
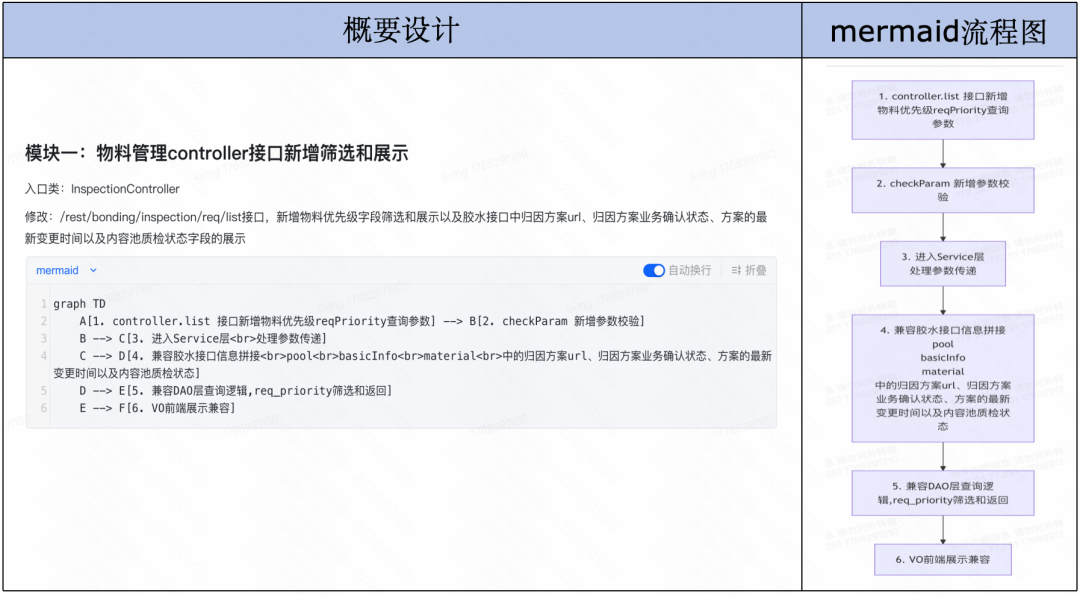
案例的概要设计与Mermaid流程图
4.2 整体架构:“码图”框架
这套新研发范式并非停留在理论或流程约定,而是由一整套称为 “码图” 的工程架构所托底。
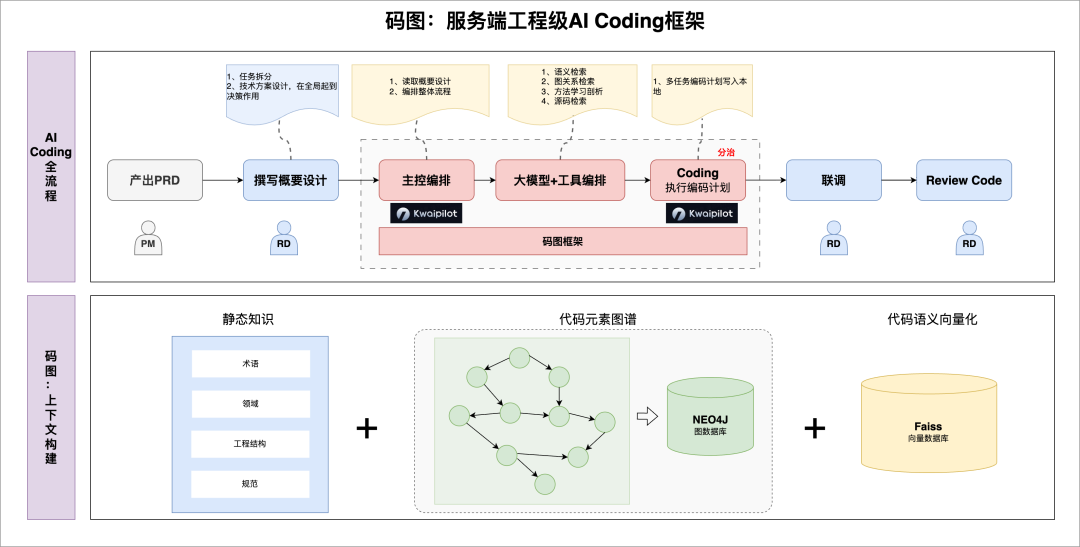
“码图”服务端工程级AI Coding框架
从系统视角看,整个码图体系被清晰地拆分为 准备阶段 与 实施阶段。
当编码计划生成后,系统便将最终的控制权交给 Kwaipilot,由其在具体的工程约束下,将计划转化为安全、合规的真实代码。
五、总结
计算机科学领域有一句广为流传的话:“任何复杂问题,都可以通过引入一个中间层来解决。” 在后端 AI Coding 的探索上,我们同样验证了这一点。在码图体系中,我们引入了两个关键的“中间层”:
- PRD → 概要设计:由人完成,用于保证需求理解的准确性与高层次架构决策的质量。
- 概要设计 → 编码计划:由独立的 SubAgent 系统完成,用于将人类的设计意图翻译为可执行、可自动化校验的工程步骤。
正是这两个中间层,把“模糊需求”与“具体代码”之间那段最容易失控、最依赖个人经验的“黑盒过程”,拆解成了 可理解、可验证、可约束的标准化工程路径。AI 也因此从“根据描述猜测并编写代码”,转变为“按照明确的工程计划严格执行代码生成”。
经过多轮方案迭代和真实生产环境的验证,我们逐渐形成了两个非常清晰且至关重要的共识:
第一,精准、结构化的 Context 是后端 AI Coding 能否成功落地的决定性因素。 如果缺乏上下文,AI 只能困在局部文件中进行补全和改写,如同盲人摸象,难以把握系统的全貌。只有当代码被图谱化、语义化、工程化之后,AI 才能真正获得系统级视角,从而承担起真实、复杂需求的实现工作。
第二,提升可控性(Control),是所有“AI Coding 产品”必须优先解决的核心能力。 可控性并非随着模型能力增强而自然获得,它是由模型能力、精妙的 Prompt/工具设计、稳固的系统框架以及严格的工程校验共同构成的一种 体系化能力。只有当 Context 被工程化地构建,AI 的行为被系统化地约束,AI 才第一次真正具备了成为“可靠工程执行者”的资格。
希望快手在后端 AI Coding 领域的这些实践与思考,能为同行们带来一些启发。技术的发展永远在迭代中前进,关于人与AI如何更好地协同创作,欢迎在云栈社区继续交流探讨。
 发表于 2026-1-31 01:51:55
|
查看: 238|
回复: 0
发表于 2026-1-31 01:51:55
|
查看: 238|
回复: 0
