本文对DeepSeek-V3.2-Speciale与Google Gemini 3 Pro两款模型进行了对比测试,核心考察其在特定提示词(Prompt)下生成HTML5肉鸽游戏(Roguelike)的代码能力。
测试背景与参数
- 模型版本:
- Gemini 3 Pro:使用官方网页版(非Studio)。
- DeepSeek-V3.2-Speciale:通过官方提供的OpenAI兼容协议API调用。
- 推理参数:Temperature设置为0.7,Top_p在0.5-0.6之间(因后续调整,具体值未记录)。
测试一:追求“最短代码”的Prompt
Prompt内容:帮我用最短的代码实现一个纯H5肉鸽游戏,刷怪每达到一定条件获得三选一能力,怪不断变强,能力可以叠加变化,地图随机变化,自行分析并扩展需求,然后实现它!
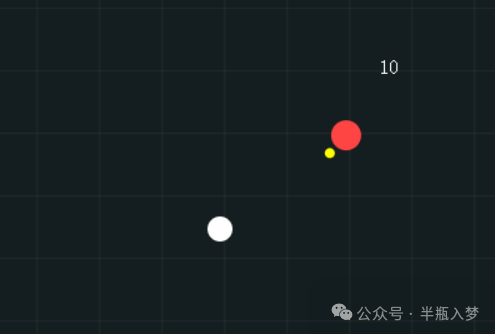
Gemini 3 Pro 结果
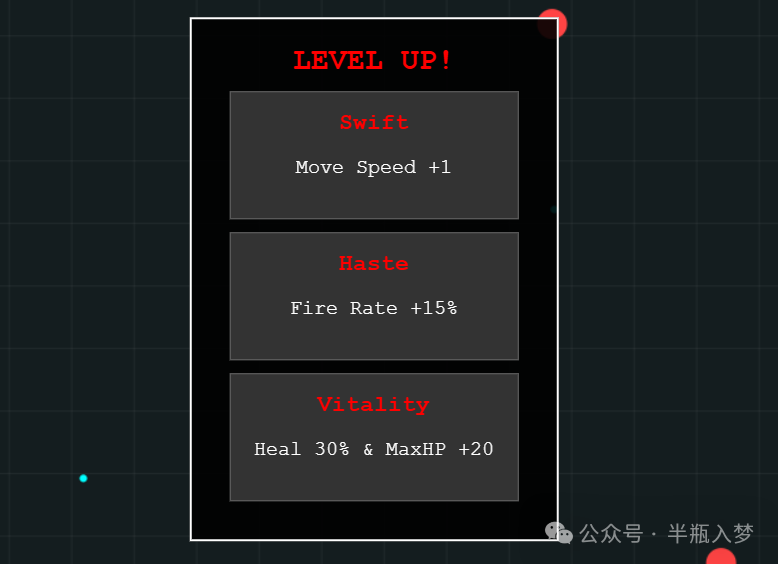
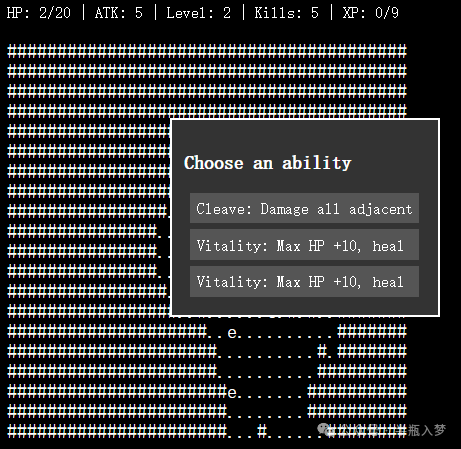
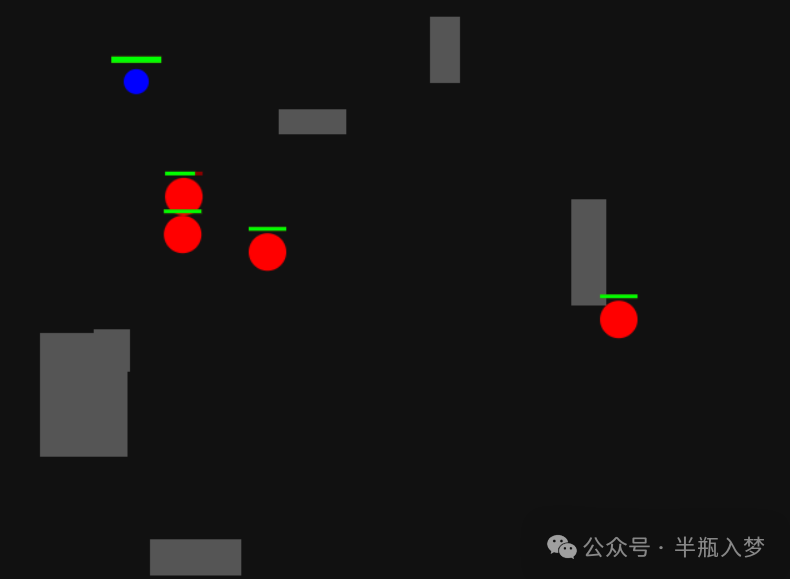
DeepSeek-V3.2-Speciale 结果
测试二:无代码长度限制的Prompt
Prompt内容:帮我实现一个纯H5肉鸽游戏,刷怪每达到一定条件获得三选一能力,怪不断变强,能力可以叠加变化,地图随机变化,自行分析并扩展需求,然后实现它!
(移除了“最短的代码”限制)
设计思考:起初担心“最短代码”的要求会限制Gemini的发挥,因此设计了两组提示词进行对比。实际结果表明,此限制反而约束了DeepSeek-V3.2-Speciale的生成能力,Gemini则表现稳定。
结果对比:
分析:
- Gemini 3 Pro:在无限制条件下,生成的游戏增加了地形系统和开始界面,内容更丰富。
- DeepSeek-V3.2-Speciale:生成的游戏也变得复杂,同样增加了开始界面和地形。但在
JavaScript前端实现上,整体UI和画面美观度一般,且角色子弹需要点击鼠标手动释放(而非自动)。游戏保留了肉鸽抽卡机制。
- 可玩性:DeepSeek版本依然可以通关,但整体偏难;Gemini版本则为无限循环模式。测试中Gemini版本首次运行时在抽卡后出现游戏卡死的Bug,修复后正常。考虑到网页版参数可能不可控,此Bug不纳入核心评价因素。
测试工具与趣事
本次测试在实施过程中遇到了一些工程挑战。最初尝试在Coze和Dify平台上进行,但发现Dify存在约10分钟的超时限制(可能与OpenAI协议兼容插件有关,且当时插件尚未适配DeepSeek-V3.2-Speciale)。即使修改了所有环境超时设置也无法绕过。最终,采用Trea平台新推出的Solo模式,耗时约1.5小时完成了测试Web应用的构建与部署。这也从侧面反映了当前人工智能应用开发中工具链适配的实际情况。
总结
从生成结果的综合体验来看,Gemini 3 Pro的表现更为出色,其生成的游戏在完整性、美观度和可玩性上均胜出一筹。需要指出的是,DeepSeek-V3.2-Speciale本身并非针对通用对话或日常使用场景优化。在第一个Prompt测试中,其长达十分钟的“思维链”推理过程确实产出了与众不同的游戏设计思路,且实现了一次点亮并具备基础可玩性(使用DeepSeek-V3.2-Think模型测试同类Prompt则生成bug较多)。本次测试为提示词工程在实际项目中的应用提供了具体案例,期待DeepSeek后续大版本迭代能带来更多突破。 |  发表于 2025-12-3 23:48:09
|
查看: 210|
回复: 0
发表于 2025-12-3 23:48:09
|
查看: 210|
回复: 0