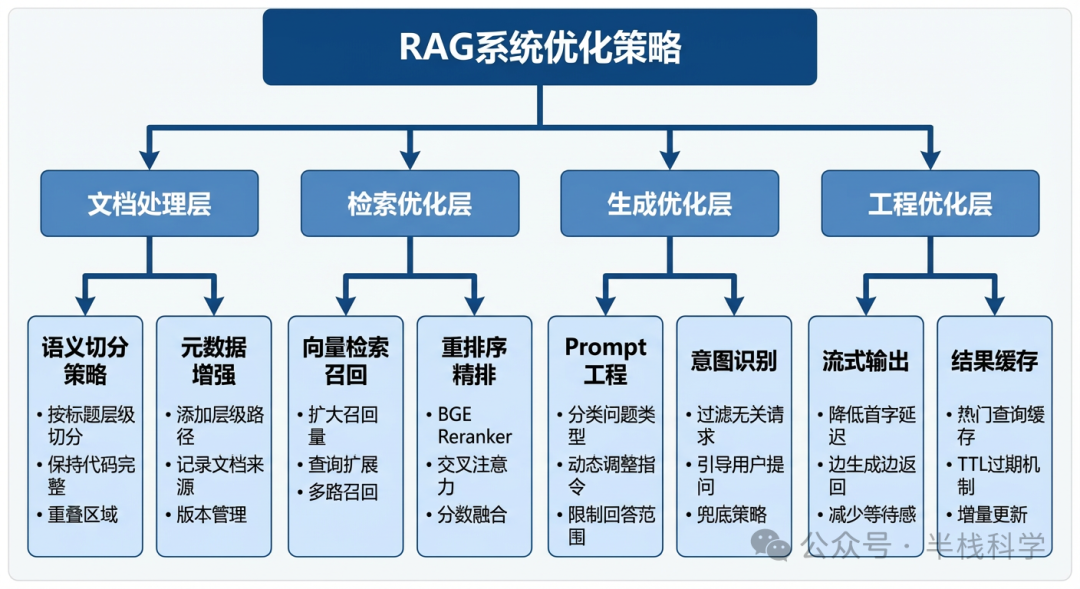
一、RAG到底在解决什么问题
在动手搭建之前,我想先聊聊 RAG(检索增强生成)这个概念,因为它很容易被误解。很多刚接触的朋友会把它想得太复杂,或者和大模型的微服务弄混。
大语言模型很强,但它有两个至今仍很明显的弱点:
第一,知识有截止日期。 GPT-4的训练数据有截止时间点,它不可能知道你们公司上周发布的新规范,也不知道昨天刚修复的那个BUG的具体解决方案。
第二,会“一本正经地胡说八道”。 当模型遇到它知识范围外的问题时,它往往不会老实说“我不知道”,而是会基于学过的通用知识,给你编一个看起来合理但其实是错误的答案。这就是所谓的“幻觉”(Hallucination)。
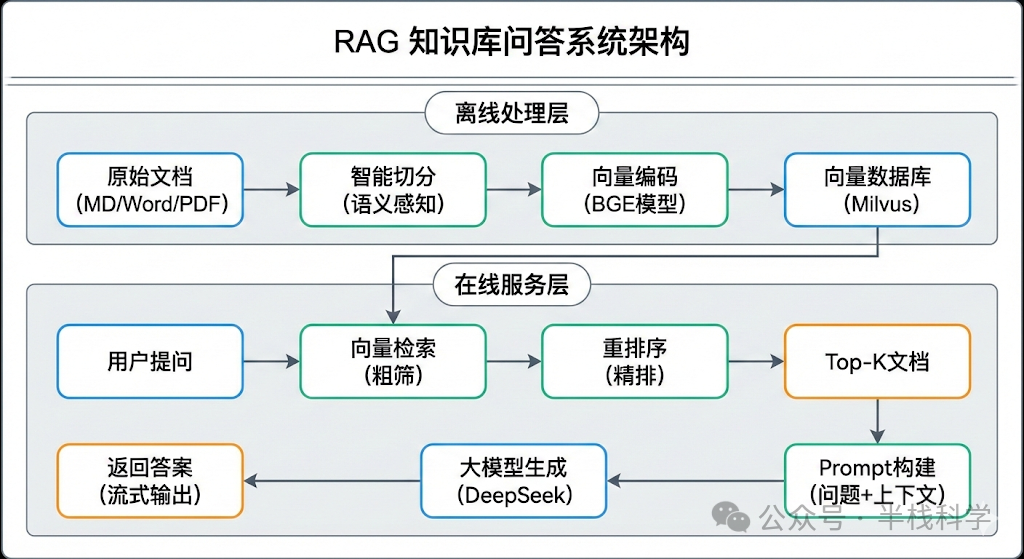
LangChain 等框架下的 RAG,核心思路其实很直接:别让大模型靠想象力答题,先帮它把参考资料找出来,让它照着资料回答。
具体来说分三步:
- 把你的私有文档(手册、规范、报告)切成语义上相对完整的小块,转换成向量存起来。
- 用户提问时,先把问题向量化,去数据库里检索出最相关的几个文档片段。
- 把用户问题和检索到的这些“参考资料”一起打包喂给大模型,让它基于这些具体材料生成答案。
听起来不复杂对吧?我当时也是这么想的,然后就在实战中踩了一堆坑。
二、第一个大坑:文档切分没那么简单
我最初的方案特别粗暴——直接用 LangChain 的 RecursiveCharacterTextSplitter,设置 chunk_size=500,overlap=50,以为就能把文档切好。
代码写起来确实很简单:
from langchain.text_splitter import RecursiveCharacterTextSplitter
def naive_split(text):
"""最初的简单切分方案——后来证明这是个坑"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=['\n\n', '\n', '。', '!', '?', ' ', '']
)
chunks = splitter.split_text(text)
return chunks
# 测试一下
sample_text = """
# MySQL主从切换操作手册
## 1. 前置检查
在执行主从切换之前,必须完成以下检查:
- 确认从库同步状态正常(Seconds_Behind_Master = 0)
- 确认没有正在执行的大事务
- 通知相关业务方,确认切换时间窗口
## 2. 切换步骤
2.1 在主库执行只读设置
SET GLOBAL read_only = 1;
2.2 等待从库完全同步
在从库执行 SHOW SLAVE STATUS,确认 Seconds_Behind_Master = 0
2.3 停止从库复制
STOP SLAVE;
RESET SLAVE ALL;
## 3. 回滚方案
如果切换失败,按以下步骤回滚...
"""
chunks = naive_split(sample_text)
for i, chunk in enumerate(chunks):
print(f'Chunk {i+1}:')
print(chunk[:100] + '...' if len(chunk) > 100 else chunk)
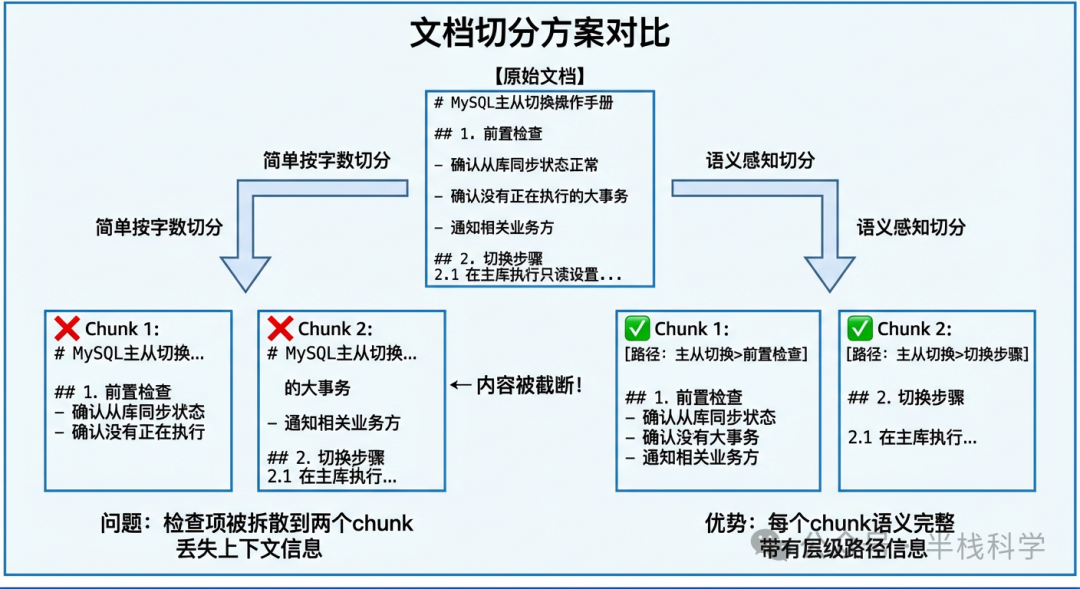
看起来没毛病是吧?但实际用起来问题大了。有一次用户问:“MySQL切换前需要做哪些检查?”,系统返回的检索片段是这样的:
确认没有正在执行的大事务
- 通知相关业务方,确认切换时间窗口
## 2. 切换步骤
2.1 在主库执行只读设置
SET GLOBAL read_only = 1;
发现问题了吗?这个片段恰好从“前置检查”这个列表的中间切开了!“确认从库同步状态正常”这一条被切到了上一个chunk里。结果用户问需要做哪些检查,我们喂给大模型的参考资料里,第一条关键检查项就缺了一半。
核心教训:机械地按字数切分,会严重破坏文档的语义完整性。
后来我改成了基于语义结构的切分策略:
import re
from typing import List, Dict
class SmartDocumentSplitter:
"""语义感知的文档切分器
核心思路:尊重文档的原有结构,按标题、段落等语义边界切分"""
def __init__(self, max_chunk_size=800, min_chunk_size=100):
self.max_chunk_size = max_chunk_size
self.min_chunk_size = min_chunk_size
def split_markdown(self, text: str) -> List[Dict]:
"""针对Markdown文档的切分
保持标题层级结构,每个chunk都带上完整的上下文路径"""
chunks = []
current_headers = {1: '', 2: '', 3: ''} # 记录当前的标题层级
# 按行处理,识别标题和内容
lines = text.split('\n')
current_content = []
for line in lines:
# 检测Markdown标题
header_match = re.match(r'^(#{1,3})\s+(.+)$', line)
if header_match:
# 遇到新标题,先保存之前的内容
if current_content:
chunk_text = '\n'.join(current_content).strip()
if len(chunk_text) >= self.min_chunk_size:
chunks.append({
'content': chunk_text,
'headers': dict(current_headers),
'context_path': self._build_context_path(current_headers)
})
current_content = []
# 更新标题层级
level = len(header_match.group(1))
title = header_match.group(2)
current_headers[level] = title
# 清除下级标题
for l in range(level + 1, 4):
current_headers[l] = ''
current_content.append(line)
else:
current_content.append(line)
# 如果当前内容超过最大长度,强制切分(但尽量在段落边界)
content_so_far = '\n'.join(current_content)
if len(content_so_far) > self.max_chunk_size:
chunk_text = content_so_far.strip()
chunks.append({
'content': chunk_text,
'headers': dict(current_headers),
'context_path': self._build_context_path(current_headers)
})
current_content = []
# 别忘了最后一段
if current_content:
chunk_text = '\n'.join(current_content).strip()
if len(chunk_text) >= self.min_chunk_size:
chunks.append({
'content': chunk_text,
'headers': dict(current_headers),
'context_path': self._build_context_path(current_headers)
})
return chunks
def _build_context_path(self, headers: Dict) -> str:
"""构建层级路径,比如:MySQL主从切换 > 前置检查"""
path_parts = [h for h in [headers[1], headers[2], headers[3]] if h]
return ' > '.join(path_parts) if path_parts else '未分类'
def enrich_chunk_with_context(self, chunk: Dict) -> str:
"""关键技巧:给每个chunk加上上下文前缀
这样即使单独看这个片段,也能知道它属于哪个章节"""
context = f'[文档路径:{chunk[\"context_path\"]}]\n\n'
return context + chunk['content']
# 实际使用示例
splitter = SmartDocumentSplitter(max_chunk_size=800)
chunks = splitter.split_markdown(sample_text)
print(f'切分后共 {len(chunks)} 个片段\n')
for i, chunk in enumerate(chunks):
print(f'=== Chunk {i+1} ===')
print(f'路径:{chunk[\"context_path\"]}')
print(f'内容预览:{chunk[\"content\"][:150]}...')
print()
这样切出来的效果就好多了。每个chunk都带有明确的路径信息,例如“MySQL主从切换操作手册 > 前置检查”。大模型在回答时就能更准确地理解这段内容在文档整体结构中的位置。
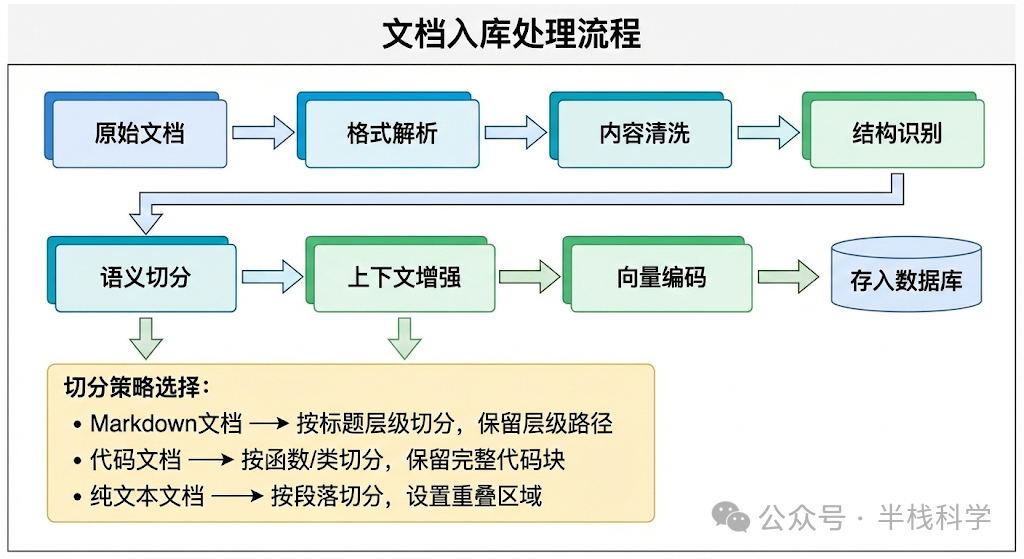
当然,这个方案也不是万能的。对于那些格式不规范的老文档(比如没有清晰标题的纯文本),切分效果还是会打折扣。后来我们针对不同类型的文档(Markdown、Word、PDF、代码文件)做了差异化的切分策略,这是后话。
三、第二个大坑:向量检索的语义鸿沟
解决了切分问题,下一步就是向量化和检索了。我选择了开源的 BGE(BAAI General Embedding)模型做Embedding,用 Milvus 做向量数据库。
第一版的检索代码很直白:
from sentence_transformers import SentenceTransformer
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType, utility
import numpy as np
class VectorStore:
"""向量存储和检索"""
def __init__(self, model_name='BAAI/bge-base-zh-v1.5'):
# 加载Embedding模型
self.model = SentenceTransformer(model_name)
self.dim = 768 # BGE base模型的向量维度
# 连接Milvus
connections.connect('default', host='localhost', port=19530)
def create_collection(self, collection_name: str):
"""创建集合"""
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name='content', dtype=DataType.VARCHAR, max_length=4096),
FieldSchema(name='context_path', dtype=DataType.VARCHAR, max_length=512),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=self.dim)
]
schema = CollectionSchema(fields, description='知识库文档')
collection = Collection(collection_name, schema)
# 创建索引
index_params = {
'metric_type': 'COSINE',
'index_type': 'IVF_FLAT',
'params': {'nlist': 128}
}
collection.create_index('embedding', index_params)
return collection
def insert_documents(self, collection_name: str, chunks: list):
"""插入文档"""
collection = Collection(collection_name)
contents = [chunk['content'] for chunk in chunks]
context_paths = [chunk['context_path'] for chunk in chunks]
# 批量生成Embedding
embeddings = self.model.encode(contents, normalize_embeddings=True)
collection.insert([contents, context_paths, embeddings.tolist()])
collection.flush()
print(f'成功插入 {len(chunks)} 条文档')
def search(self, collection_name: str, query: str, top_k: int = 5):
"""基础检索"""
collection = Collection(collection_name)
collection.load()
# 生成查询向量
query_embedding = self.model.encode([query], normalize_embeddings=True)
results = collection.search(
data=query_embedding.tolist(),
anns_field='embedding',
param={'metric_type': 'COSINE', 'params': {'nprobe': 16}},
limit=top_k,
output_fields=['content', 'context_path']
)
return results[0]
基础功能没问题。但跑起来后,我发现了另一个让人抓狂的现象——用户的口语化提问和文档的正式表述之间存在巨大的“语义鸿沟”。
举个例子:
- 用户问:“数据库挂了怎么办?”
- 文档标题是:“MySQL服务异常恢复操作手册”
这两个在语义上高度相关,但由于用词差异(“挂了” vs “异常”),它们的向量相似度可能并不高。更麻烦的是,有时真正相关的文档在向量检索中只排在第3或第4位,排在前面的是一些“看起来”相关但实际不切题的片段。如果我只取Top 3喂给大模型,关键信息就漏掉了。
后来我采用了一个更可靠的策略:两阶段检索——先用向量检索做“粗筛”召回,再用重排序模型做“精排”。
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
class EnhancedRetriever:
"""增强版检索器:向量检索 + 重排序"""
def __init__(self, vector_store: VectorStore):
self.vector_store = vector_store
# 加载重排序模型(BGE Reranker效果不错)
self.reranker_tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-base')
self.reranker_model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-base')
self.reranker_model.eval()
def retrieve_with_rerank(self, collection_name: str, query: str,
initial_top_k: int = 20, final_top_k: int = 5):
"""两阶段检索:
1. 向量检索召回 initial_top_k 个候选
2. 用重排序模型精排,返回 final_top_k 个结果"""
# 第一阶段:向量检索(召回更多候选)
initial_results = self.vector_store.search(collection_name, query, top_k=initial_top_k)
if not initial_results:
return []
# 准备重排序
candidates = []
for hit in initial_results:
candidates.append({
'content': hit.entity.get('content'),
'context_path': hit.entity.get('context_path'),
'vector_score': hit.score # 保留向量检索得分,用于调试
})
# 第二阶段:重排序
rerank_scores = self._compute_rerank_scores(query, [c['content'] for c in candidates])
for i, score in enumerate(rerank_scores):
candidates[i]['rerank_score'] = score
# 按重排序分数排序
candidates.sort(key=lambda x: x['rerank_score'], reverse=True)
return candidates[:final_top_k]
def _compute_rerank_scores(self, query: str, documents: list) -> list:
"""计算query和每个文档的相关性分数"""
scores = []
with torch.no_grad():
for doc in documents:
# Reranker的输入格式是 [query, document]
inputs = self.reranker_tokenizer(
[[query, doc]],
padding=True,
truncation=True,
max_length=512,
return_tensors='pt'
)
outputs = self.reranker_model(**inputs)
score = outputs.logits.squeeze().item()
scores.append(score)
return scores
def retrieve_with_query_expansion(self, collection_name: str, query: str,
llm_client, top_k: int = 5):
"""进阶技巧:查询扩展
用大模型改写用户问题,生成多个变体,再合并检索结果"""
# 让大模型帮我们扩展查询
expansion_prompt = f"""请将下面这个问题改写成3个不同的表达方式,保持意思相同但用词不同。
每行输出一个改写结果,不要序号,不要其他解释。
原问题:{query}
"""
expanded_queries = llm_client.generate(expansion_prompt).strip().split('\n')
expanded_queries = [q.strip() for q in expanded_queries if q.strip()]
# 加上原始查询
all_queries = [query] + expanded_queries[:3] # 最多取3个扩展查询
print(f'扩展后的查询:{all_queries}') # 调试用
# 对每个查询分别检索
all_candidates = {}
for q in all_queries:
results = self.vector_store.search(collection_name, q, top_k=10)
for hit in results:
content = hit.entity.get('content')
if content not in all_candidates:
all_candidates[content] = {
'content': content,
'context_path': hit.entity.get('context_path'),
'best_score': hit.score,
'hit_count': 1
}
else:
# 被多个查询命中的文档,增加权重
all_candidates[content]['hit_count'] += 1
all_candidates[content]['best_score'] = max(
all_candidates[content]['best_score'],
hit.score
)
# 综合评分:命中次数 * 最高得分
candidates = list(all_candidates.values())
for c in candidates:
c['combined_score'] = c['hit_count'] * c['best_score']
candidates.sort(key=lambda x: x['combined_score'], reverse=True)
return candidates[:top_k]
查询扩展这招特别好用。比如用户问“数据库挂了怎么办”,大模型可能会扩展成:
- MySQL服务故障如何处理?
- 数据库无法连接的解决方案?
- 数据库宕机恢复步骤?
用这几个扩展查询和原问题一起去检索,能大大提高召回相关文档的概率。
四、第三个大坑:Prompt工程的门道比想象中深
检索的问题解决了,下一步就是把检索到的上下文和用户问题一起喂给大模型生成答案。这一步我本以为最简单,没想到也踩了不少坑。
最初的Prompt特别朴素:
def build_naive_prompt(query: str, context_docs: list) -> str:
"""最初的简单Prompt——后来证明太天真了"""
context = '\n\n'.join([doc['content'] for doc in context_docs])
prompt = f"""根据以下参考资料回答用户问题。
参考资料:
{context}
用户问题:{query}
请回答:
"""
return prompt
这个Prompt有几个严重问题:
- 模型不知道何时该说“不知道”。 当参考资料里确实没有答案时,它还是会基于通用知识编造。
- 没有引导模型说明信息来源。 用户看到答案,无法追溯和验证是从哪篇文档里来的。
- 对于复杂问题,回答结构不够清晰。
后来迭代了很多版,最终稳定下来的生产级Prompt是这样的:
def build_rag_prompt(query: str, context_docs: list,
include_sources: bool = True) -> str:
"""生产环境使用的Prompt模板
关键设计:明确角色定位、限制回答范围、要求标注来源"""
# 格式化上下文,每段都标注来源
context_parts = []
for i, doc in enumerate(context_docs, 1):
source = doc.get('context_path', '未知来源')
context_parts.append(f'【资料{i},来源:{source}】\n{doc[\"content\"]}')
context = '\n\n\n\n'.join(context_parts)
prompt = f"""你是一个企业内部知识库助手,专门帮助员工查找和理解公司内部文档。
## 你的工作准则
1. **只根据提供的参考资料回答问题**,不要使用你自己的知识。
2. 如果参考资料中没有相关信息,请明确说“根据现有资料,我无法找到关于这个问题的信息”,并建议用户联系相关部门或换个关键词搜索。
3. 回答时请标注信息来源,格式如【资料1】,方便用户追溯原文。
4. 对于操作类问题,请按步骤清晰地列出;对于概念类问题,先给出简明定义再展开解释。
5. 如果不同资料中的信息有冲突,请指出差异并说明各自的适用场景。
## 参考资料
{context}
## 用户问题
{query}
## 回答要求
请根据上述参考资料回答用户问题。记住:
- 只使用参考资料中的信息
- 标注信息来源
- 没有把握的内容不要编造
"""
return prompt
关于Prompt工程,一个重要经验是:不要试图在一个Prompt里塞进所有指令。 一开始我把所有要求(准确、简洁、友好、专业、标注来源、分步骤……)都写进去,结果模型反而被绕晕了,顾此失彼。
后来的做法是:区分核心指令和优化指令。 核心指令必须保留,优化指令可以根据问题类型动态调整。
class PromptBuilder:
"""Prompt构建器:根据问题类型动态调整"""
# 核心指令——任何情况都必须包含
CORE_INSTRUCTIONS = """
1. 只使用参考资料中的信息回答,不要编造
2. 资料中没有的信息,明确说“无法找到相关信息”
3. 标注信息来源【资料X】
"""
# 操作类问题的额外指令
PROCEDURE_INSTRUCTIONS = """
回答格式要求:
- 按步骤编号列出(第一步、第二步...)
- 每个步骤要明确操作对象和操作动作
- 重要的警告或注意事项用⚠️标出
"""
# 概念解释类问题的额外指令
CONCEPT_INSTRUCTIONS = """
回答格式要求:
- 先用一句话给出核心定义
- 再详细解释关键点
- 如有必要,举例说明
"""
# 故障排查类问题的额外指令
TROUBLESHOOT_INSTRUCTIONS = """
回答格式要求:
- 先列出可能的原因
- 针对每个原因给出排查方法
- 给出解决方案或规避建议
"""
@classmethod
def build(cls, query: str, context_docs: list, question_type: str = 'general') -> str:
"""根据问题类型构建Prompt"""
# 简单的问题分类逻辑(实际项目中可以用分类模型)
if question_type == 'auto':
question_type = cls._classify_question(query)
extra_instructions = ''
if question_type == 'procedure':
extra_instructions = cls.PROCEDURE_INSTRUCTIONS
elif question_type == 'concept':
extra_instructions = cls.CONCEPT_INSTRUCTIONS
elif question_type == 'troubleshoot':
extra_instructions = cls.TROUBLESHOOT_INSTRUCTIONS
context = cls._format_context(context_docs)
prompt = f"""你是企业内部知识库助手。
## 必须遵守的规则
{cls.CORE_INSTRUCTIONS}
{f'## 回答格式{extra_instructions}' if extra_instructions else ''}
## 参考资料
{context}
## 用户问题
{query}
请回答:
"""
return prompt
@classmethod
def _classify_question(cls, query: str) -> str:
"""简单的问题分类(基于关键词)"""
procedure_keywords = ['怎么做', '如何操作', '步骤', '流程', '怎样']
concept_keywords = ['是什么', '什么是', '定义', '解释', '区别']
troubleshoot_keywords = ['为什么', '报错', '失败', '异常', '问题', '故障']
query_lower = query.lower()
if any(kw in query_lower for kw in procedure_keywords):
return 'procedure'
elif any(kw in query_lower for kw in concept_keywords):
return 'concept'
elif any(kw in query_lower for kw in troubleshoot_keywords):
return 'troubleshoot'
else:
return 'general'
@classmethod
def _format_context(cls, context_docs: list) -> str:
"""格式化上下文"""
parts = []
for i, doc in enumerate(context_docs, 1):
source = doc.get('context_path', '未知来源')
parts.append(f'【资料{i},来源:{source}】\n{doc[\"content\"]}')
return '\n\n\n\n'.join(parts)
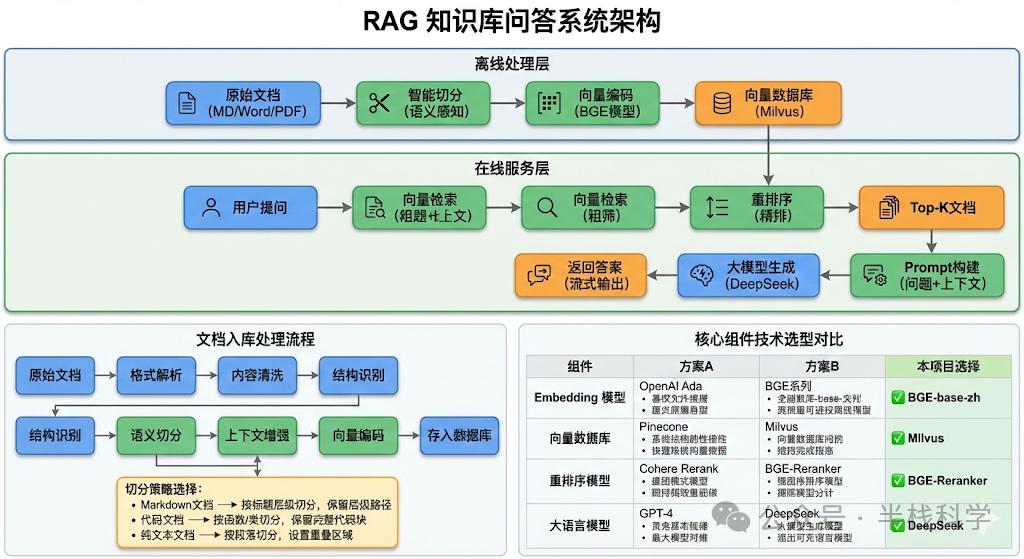
五、串起来:完整的RAG Pipeline
前面讲了一堆细节,现在把它们串成一个完整的Pipeline:
from openai import OpenAI
from typing import List, Dict, Optional
import json
class RAGPipeline:
"""完整的RAG处理流程
文档切分 -> 向量化存储 -> 检索 -> 重排序 -> 生成回答"""
def __init__(self,
llm_base_url: str = 'https://api.deepseek.com',
llm_api_key: str = 'your-api-key',
llm_model: str = 'deepseek-chat'):
# 初始化各个组件
self.splitter = SmartDocumentSplitter(max_chunk_size=800)
self.vector_store = VectorStore()
self.retriever = EnhancedRetriever(self.vector_store)
# 初始化LLM客户端(这里用DeepSeek,也可以换成其他的)
self.llm_client = OpenAI(base_url=llm_base_url, api_key=llm_api_key)
self.llm_model = llm_model
self.collection_name = 'knowledge_base'
def ingest_documents(self, documents: List[Dict]):
"""文档入库
documents格式:[{'title': '文档标题', 'content': '文档内容', 'source': '来源'}]"""
print(f'开始处理 {len(documents)} 篇文档...')
all_chunks = []
for doc in documents:
# 在内容前加上标题,帮助切分器识别结构
full_content = f"# {doc['title']}\n\n{doc['content']}"
chunks = self.splitter.split_markdown(full_content)
# 给每个chunk加上文档来源信息
for chunk in chunks:
chunk['source_doc'] = doc.get('source', doc['title'])
all_chunks.extend(chunks)
print(f'切分后共 {len(all_chunks)} 个片段')
# 创建集合并插入
self.vector_store.create_collection(self.collection_name)
self.vector_store.insert_documents(self.collection_name, all_chunks)
print('文档入库完成!')
def query(self,
question: str,
chat_history: Optional[List[Dict]] = None,
top_k: int = 5,
use_rerank: bool = True) -> Dict:
"""处理用户查询
返回:{'answer': '回答内容', 'sources': [引用的来源], 'retrieved_docs': [检索到的文档]}"""
# 1. 检索相关文档
if use_rerank:
retrieved_docs = self.retriever.retrieve_with_rerank(
self.collection_name, question,
initial_top_k=20, final_top_k=top_k
)
else:
results = self.vector_store.search(self.collection_name, question, top_k=top_k)
retrieved_docs = [{
'content': hit.entity.get('content'),
'context_path': hit.entity.get('context_path'),
'score': hit.score
} for hit in results]
if not retrieved_docs:
return {
'answer': '抱歉,我没有找到与您问题相关的资料。您可以尝试换个关键词,或联系相关部门获取帮助。',
'sources': [],
'retrieved_docs': []
}
# 2. 构建Prompt
if chat_history:
prompt = build_conversational_prompt(question, retrieved_docs, chat_history)
else:
prompt = PromptBuilder.build(question, retrieved_docs, question_type='auto')
# 3. 调用LLM生成回答
response = self.llm_client.chat.completions.create(
model=self.llm_model,
messages=[{'role': 'user', 'content': prompt}],
temperature=0.3, # 知识库问答用较低的temperature
max_tokens=2000
)
answer = response.choices[0].message.content
# 4. 提取引用的来源
sources = list(set([doc.get('context_path', '未知来源') for doc in retrieved_docs]))
return {
'answer': answer,
'sources': sources,
'retrieved_docs': retrieved_docs
}
# 使用示例
if __name__ == '__main__':
# 初始化Pipeline
rag = RAGPipeline(
llm_base_url='https://api.deepseek.com',
llm_api_key='your-api-key',
llm_model='deepseek-chat'
)
# 准备测试文档
test_documents = [
{
'title': 'MySQL主从切换操作手册',
'content': """
## 1. 前置检查
在执行主从切换之前,必须完成以下检查:
- 确认从库同步状态正常(Seconds_Behind_Master = 0)
- 确认没有正在执行的大事务
- 通知相关业务方,确认切换时间窗口
## 2. 切换步骤
### 2.1 在主库执行只读设置
SET GLOBAL read_only = 1;
### 2.2 等待从库完全同步
在从库执行 SHOW SLAVE STATUS,确认 Seconds_Behind_Master = 0
### 2.3 停止从库复制并提升为主库
STOP SLAVE;
RESET SLAVE ALL;
SET GLOBAL read_only = 0;
## 3. 切换后验证
- 确认新主库可以正常写入
- 确认应用连接已切换到新主库
- 监控新主库的性能指标
""",
'source': 'DBA团队文档'
}
]
# 入库
rag.ingest_documents(test_documents)
# 测试查询
result = rag.query('MySQL切换前需要做哪些检查?')
print('=' * 50)
print('问题:MySQL切换前需要做哪些检查?')
print('=' * 50)
print(f'\n回答:\n{result[\"answer\"]}')
print(f'\n参考来源:{result[\"sources\"]}')
六、上线后的一些经验教训
系统上线到现在,期间又踩了不少坑,这里挑几个印象最深的说说。
教训一:用户的问题千奇百怪
我们在设计时假设用户会问“MySQL怎么做主从切换”这种正常问题。但实际上呢?
- 有人问:“上次那个事故怎么处理的来着?”——没有任何上下文。
- 有人问:“帮我写个SQL。”——这根本不是知识库问答,这是代码生成。
- 还有人问:“在吗?”——意图不明。
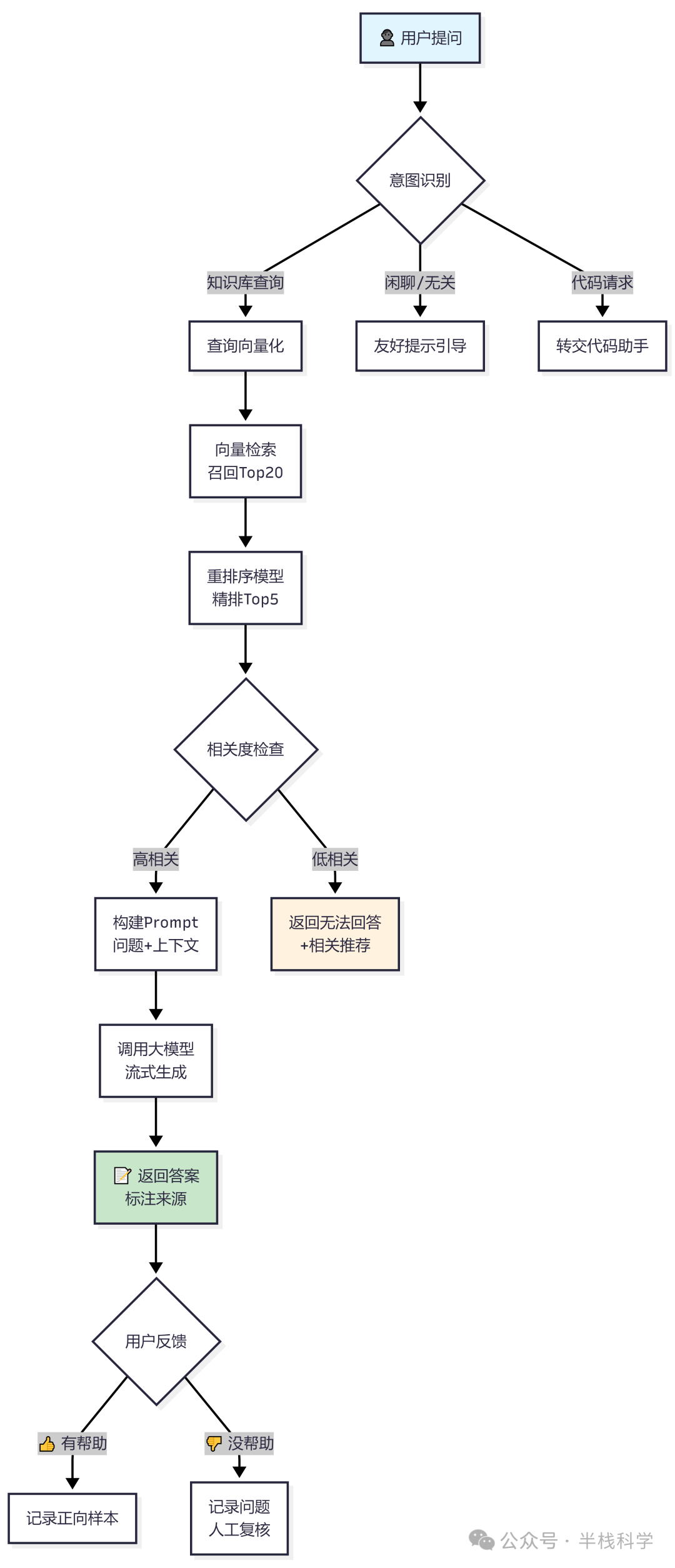
后来我加了一个意图识别层,先用一个简单的分类模型判断用户问题是否属于知识库问答的范畴,对于非知识库意图(如闲聊、代码请求),给一个友好的提示而不是硬着头皮去检索,体验反而更好。
教训二:冷启动时的尴尬
系统刚上线时,知识库文档不多,覆盖场景有限。用户问了几个问题都答不上来,体验很差,就不来用了。
解决办法:
- 上线前先梳理高频问题,确保至少这些“保底问题”能回答好。
- 增加问题收集功能,对于答不上来的问题,记录下来反馈给内容团队,驱动文档补充。
- 设计兜底策略——如果检索不到高相关度内容,就展示“相关推荐”,把一些语义相似度尚可的文档标题列出来,引导用户自己查看。
教训三:文档更新的同步问题
知识库的文档是会更新的。如果向量数据库里还存着老版本的内容,用户检索到的就是过时信息。
我们最后的方案是:
- 每个文档入库时记录版本号和更新时间。
- 定期(每周)全量重新入库。
- 对于紧急更新的重要文档,支持手动触发单篇重入库。
七、性能优化:让系统不那么慢
RAG 系统有个通病——慢。整个流程:编码、检索、重排序、LLM生成,加起来可能要好几秒。几个关键的优化措施:
import asyncio
from functools import lru_cache
import hashlib
class OptimizedRAG:
"""性能优化版RAG"""
def __init__(self):
# 缓存热门查询的结果
self.query_cache = {}
self.cache_ttl = 3600 # 1小时过期
@lru_cache(maxsize=1000)
def _compute_query_embedding(self, query: str):
"""Embedding结果缓存
同样的问题不用重复计算向量"""
return self.model.encode([query], normalize_embeddings=True)[0]
def _get_cache_key(self, query: str) -> str:
"""生成缓存key"""
return hashlib.md5(query.lower().strip().encode()).hexdigest()
async def stream_query(self, question: str):
"""流式输出
不用等整个回答生成完,边生成边输出"""
retrieved_docs = await asyncio.to_thread(
self.retriever.retrieve_with_rerank,
self.collection_name, question, 20, 5
)
prompt = PromptBuilder.build(question, retrieved_docs, question_type='auto')
# 使用流式API
stream = self.llm_client.chat.completions.create(
model=self.llm_model,
messages=[{'role': 'user', 'content': prompt}],
temperature=0.3,
stream=True # 开启流式
)
for chunk in stream:
if chunk.choices[0].delta.content:
yield chunk.choices[0].delta.content
流式输出这一点特别重要。 用户问完问题后,马上就能看到回答在“打字”输出,心理上就不会觉得那么慢了。
八、回顾与思考
把这套系统从“被骂下线”做到成为团队日常工具,前后折腾了不少时间。坑踩得挺多,但收获也很大。
几点核心总结:
1. RAG不是万能的,选好适用场景
RAG适合有明确知识库、答案需要可追溯的场景。如果你的需求是让大模型发挥创意(比如写文案、做脑暴),那RAG反而是个约束。
2. 文档切分和检索是根基
大家往往把注意力放在大模型本身,觉得用更强的模型就能解决问题。但实际上,如果前面的切分和检索做得不好,给模型的“米”是碎的、不对的,再强的模型也是“巧妇难为无米之炊”。
3. Prompt工程真的是门手艺
同样的检索结果,不同的Prompt可能带来天壤之别的回答效果。这个没什么捷径,就是多试、多看bad case、多迭代。
4. 上线只是开始
真正的挑战在上线之后。用户的各种“奇葩”输入、文档的持续更新、性能的优化、效果的监控……每一项都是持续的工作。
最后,分享一下这套系统目前的一些核心指标:
- 日均查询量:200+次
- 平均响应时间:2.3秒(开启流式后,首字符延迟约0.8秒)
- 用户满意度(通过回答后的点赞/点踩收集):约72%
- 无法回答的比例:约22%(这部分会定期分析,推动文档补充)
数字不算特别亮眼,但比起之前那个没人用的关键词搜索系统,已经是质的飞跃了。做技术的路上总是坑坑洼洼,把这些实战经验分享出来,希望能帮到正在探索 RAG 的你。如果你也在做类似的项目,或者有更好的想法,欢迎在云栈社区交流探讨。
 发表于 2026-3-6 17:32:05
|
查看: 277|
回复: 0
发表于 2026-3-6 17:32:05
|
查看: 277|
回复: 0
