在大型语言模型(LLM)飞速发展的今天,其强大的智能来源很大程度上可以追溯到其基础架构——Transformer。本文将以一个翻译案例为线索,深入浅出地解析Transformer的工作原理与核心构造,涵盖分词、嵌入、位置编码,并重点剖析注意力机制等核心组件,最后介绍当前主流旗舰模型采用的混合专家(MoE)等前沿架构设计。
为了更直观地理解,我们将结合一个具体案例,看看Transformer模型是如何将“Transformer is powerful.”翻译成“Transformer很强大。”的。这个过程将帮助我们解答几个核心问题:机器如何理解文字?如何理解文字顺序?又如何理解词与词之间的关联关系?

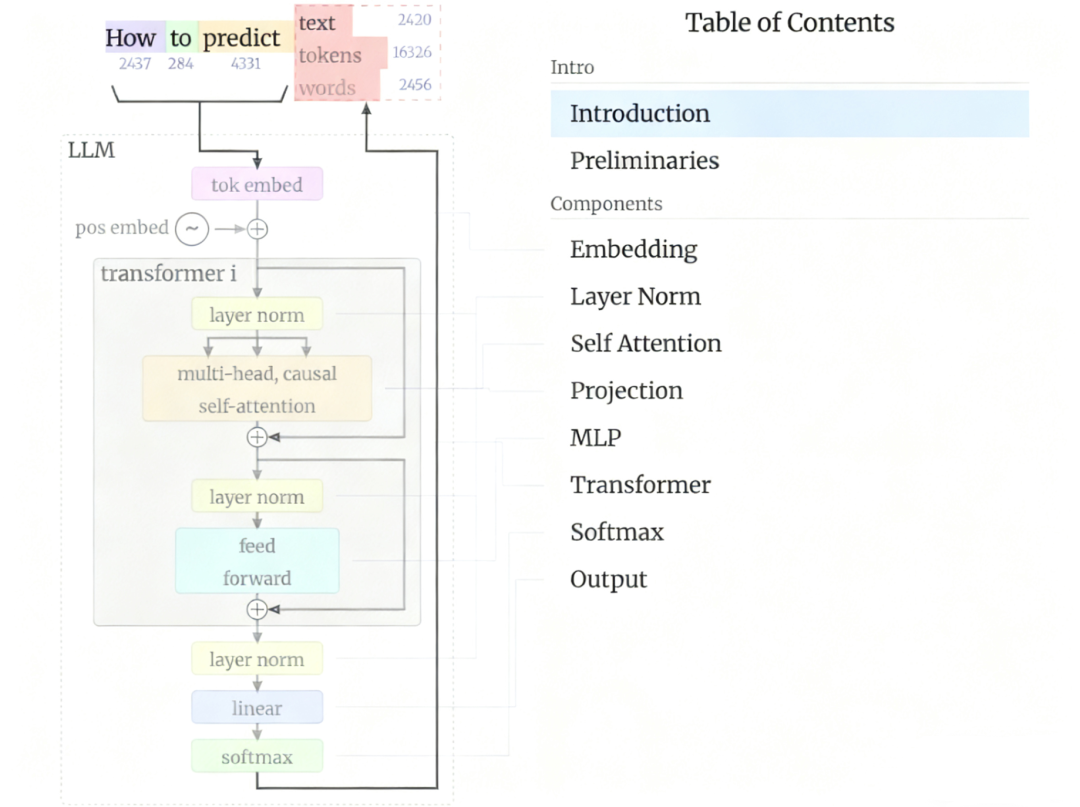
LLM架构解析
2017年提出的Transformer架构是现代深度学习模型的基石。其核心架构图展示了其基本思想,而核心创新在于自注意力机制。
当前主流的LLM(如GPT系列)多采用Decoder-only的Transformer架构。它由多个相同的层堆叠而成,每一层通常包含一个带掩码的多头自注意力层和一个前馈神经网络(FFN)。这种设计允许模型并行处理序列,极大地提升了训练效率。
在构建和训练这样一个模型时,数据、模型、训练三个环节缺一不可。数据的处理尤为关键,它决定了模型能从“原材料”中提取多少有效信息。理解数据处理,特别是文本的表示方式,是深入理解Transformer的第一步。
Token数据流示例
以翻译“Transformer is powerful.”到“Transformer很强大。”为例,当解码器已经生成“Transformer很”并准备预测下一个词“强”时,数据在模型内部的流转过程如下:
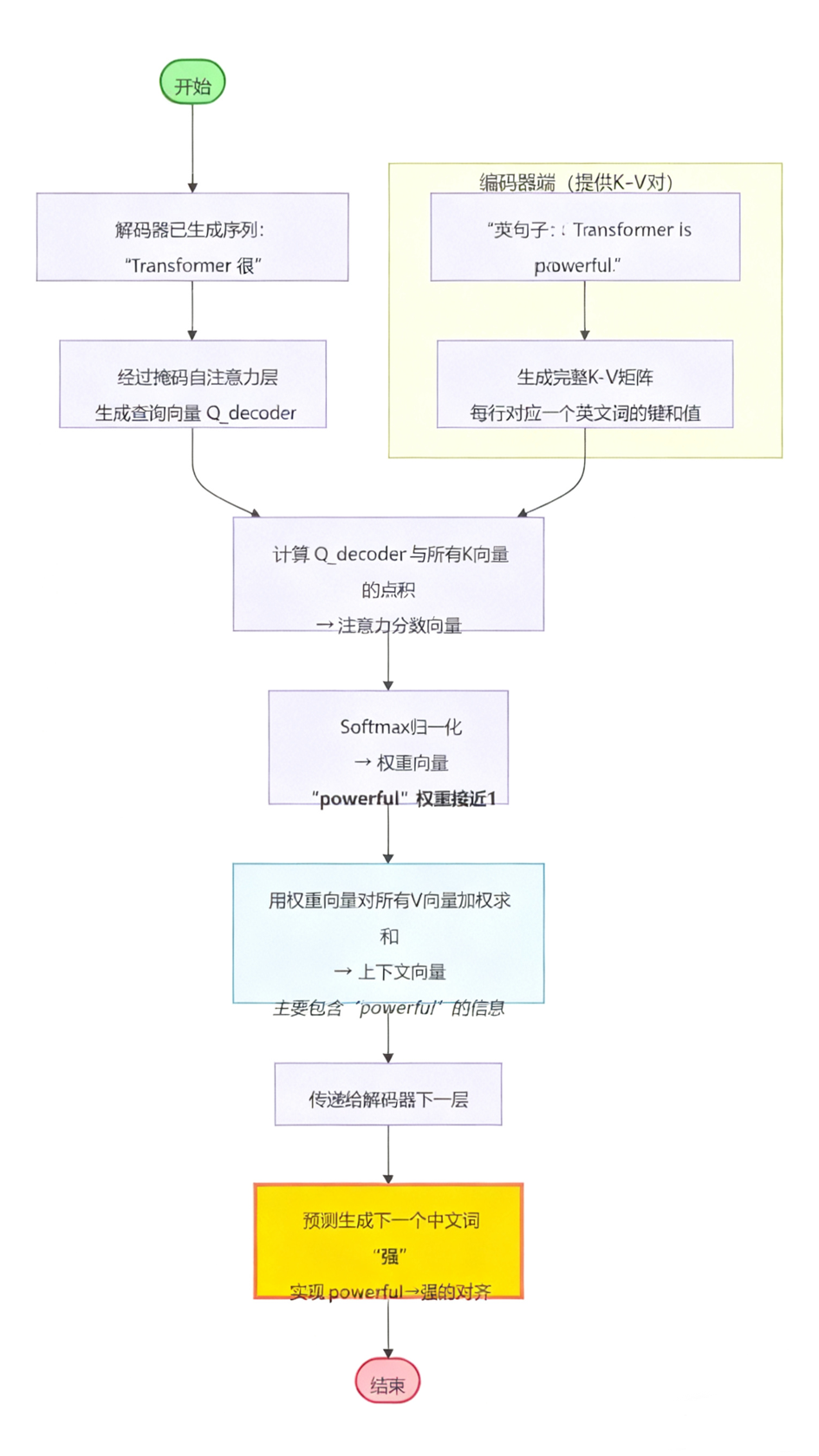
- 生成查询(Q)向量:已生成的序列“Transformer 很”经过解码器处理,生成一个代表当前状态的查询向量 Q_decoder。
- 提供键值(K, V)向量:编码器已为英文句子生成完整的键(K)和值(V)向量矩阵。
- 计算注意力权重:模型计算 Q_decoder 与所有英文词K向量的点积,得到注意力分数,再经Softmax归一化为权重。理想情况下,对应“powerful”的权重会非常高。
- 加权求和生成上下文向量:用该权重对所有英文词的V向量进行加权求和,得到一个主要包含“powerful”信息的上下文向量,用于最终预测“强”。
至此,我们走完了Transformer单层处理的核心流程。接下来,让我们拆解其中的每一个关键“零件”。
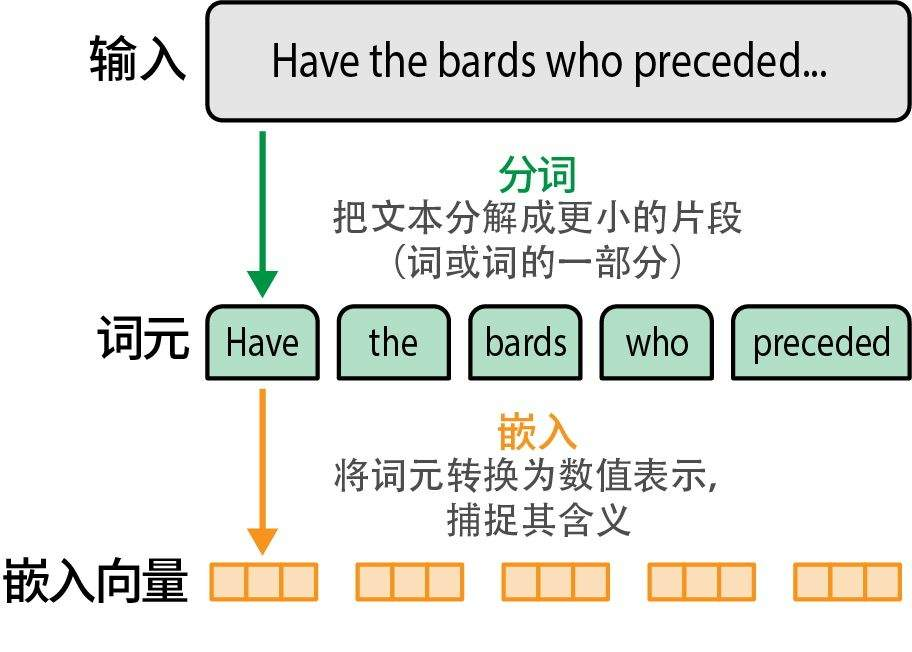
分词(Tokenization)
分词是将连续文本切割成模型能处理的基本单元(Token)的过程。例如,“Transformer is powerful.” 可能被分词为 [“Transformer”, “ is”, “ powerful”, “.”]。


一种直观的理解是,分词为模型建立了一本“字典”的目录。模型的预测过程,可以看作是根据上下文,在这本字典中寻找最相关的下一个词。
当然,如果只是随机查找,模型将无法产出有意义的文本。我们通过后续的词嵌入、位置编码、注意力机制以及海量数据的训练,让这种“查找”变得有规律、有逻辑。
嵌入(Embedding)
分词得到了离散的Token,但神经网络无法直接处理离散符号。词嵌入(Word Embedding)的任务就是将每个Token映射为一个连续的、稠密的向量,这个向量在高维空间中表征了该Token的语义。
可以将其类比为字典:分词是目录索引,而词嵌入是每个词的详细释义。向量维度越高,能编码的语义信息就越丰富,但计算代价也越大。例如,GPT-3的嵌入维度高达12288。
词嵌入的过程本质上是查表操作。下图展示了一个3个Token、48维的嵌入过程:
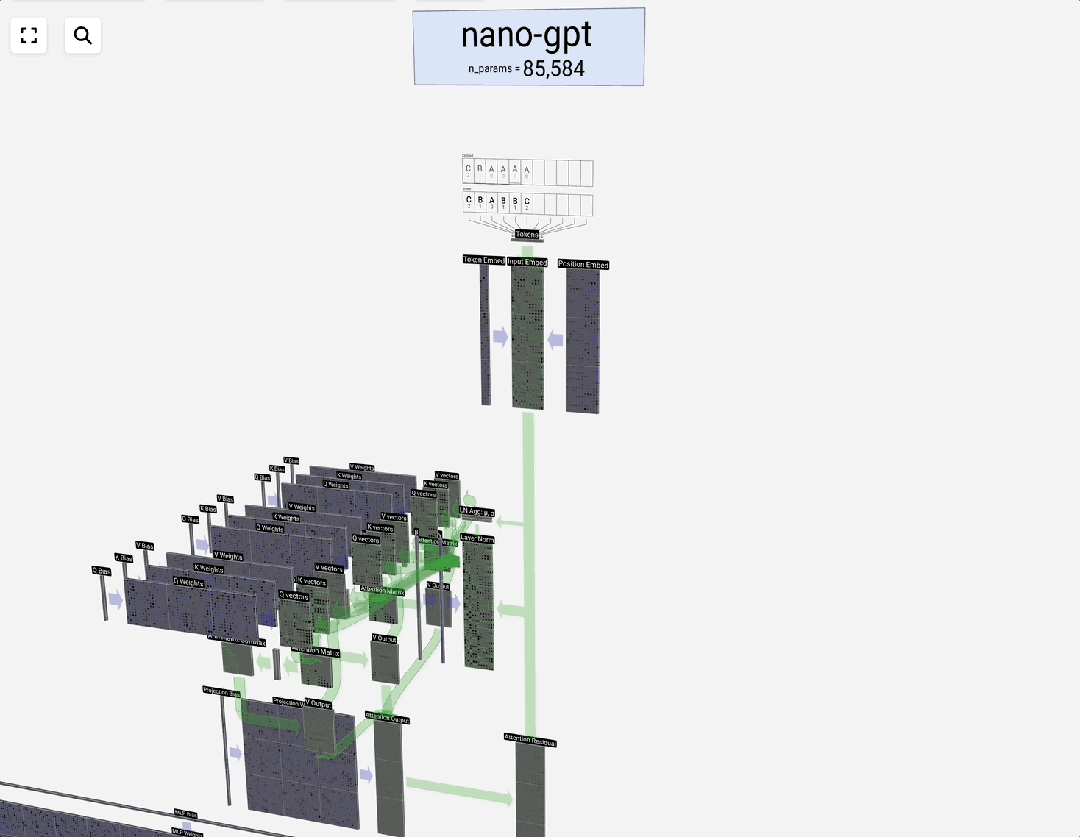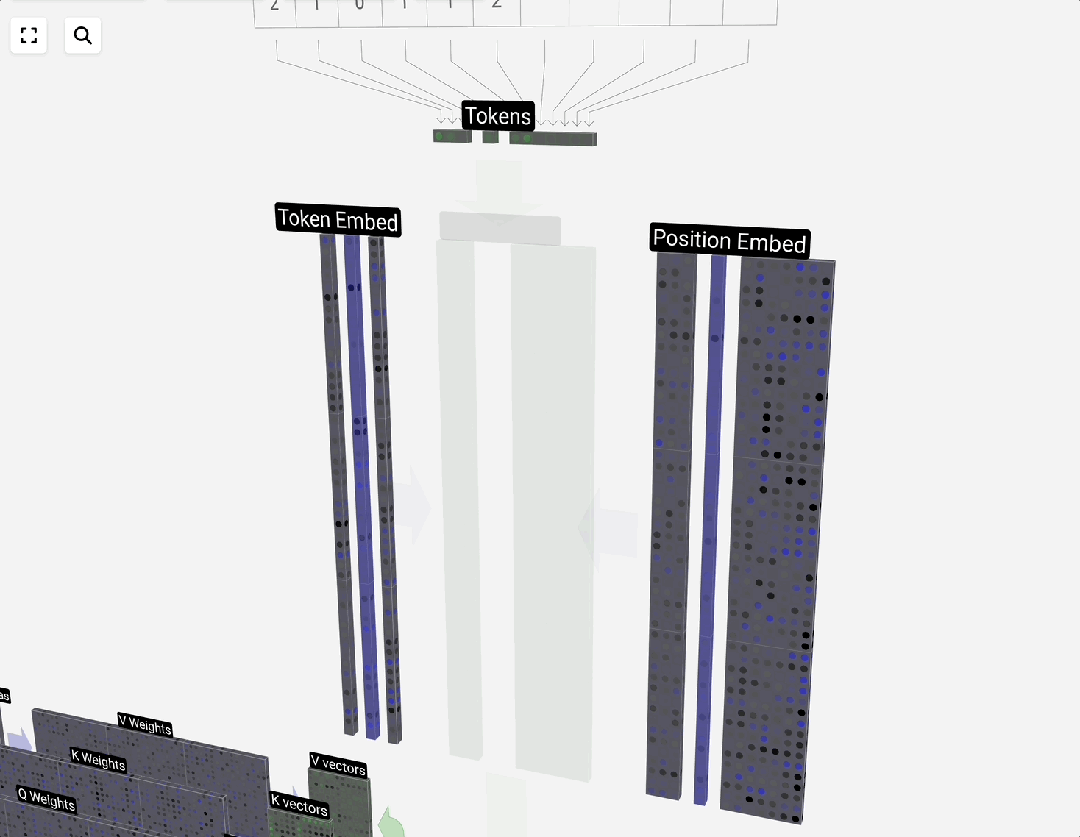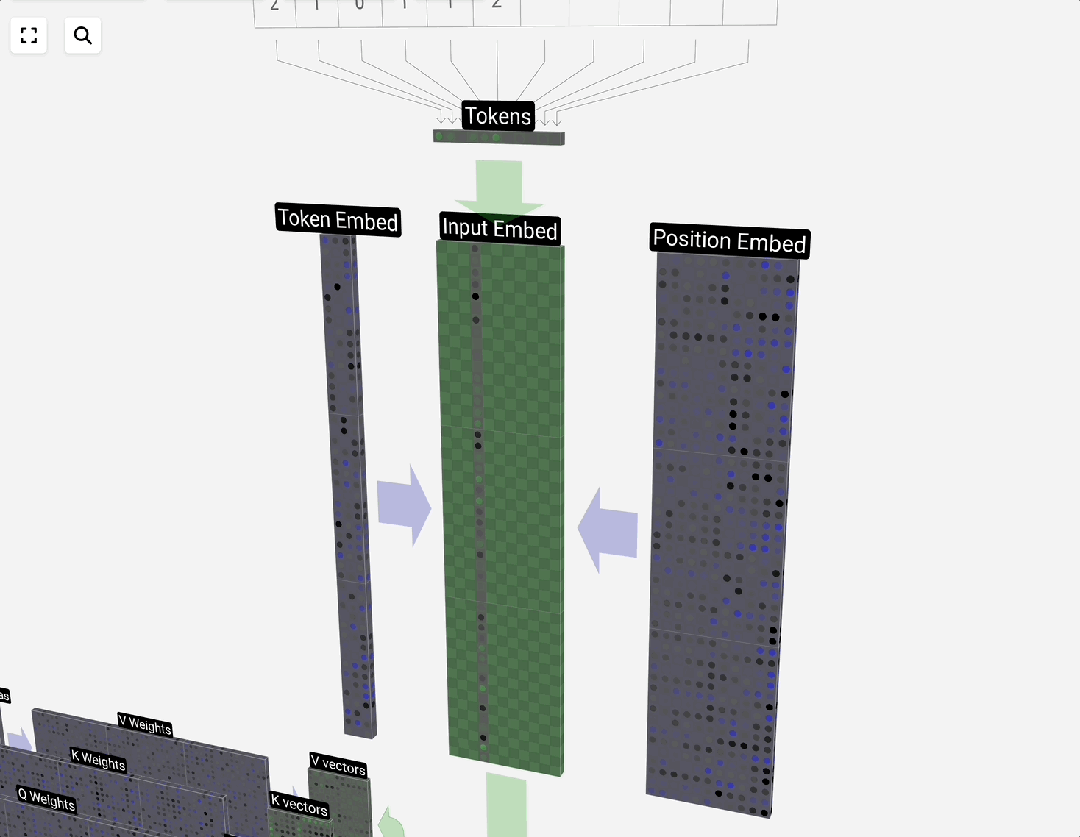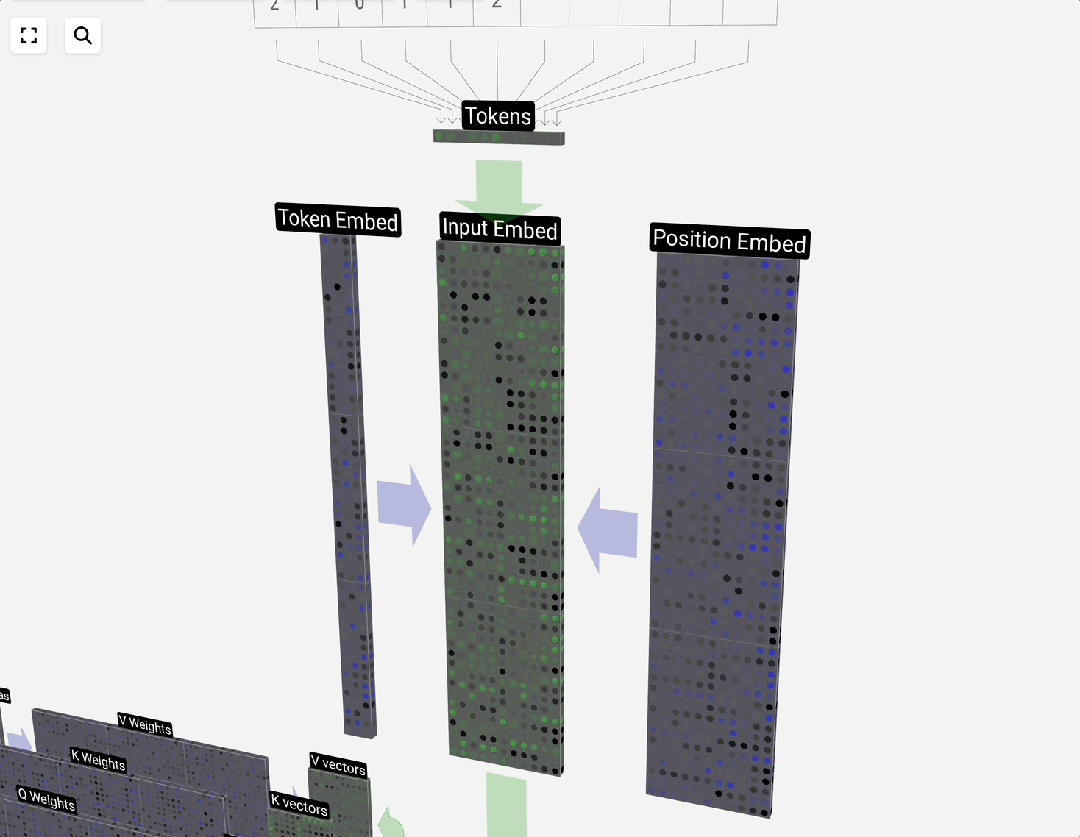
嵌入技术不仅限于文本,图像、音频等多模态数据也可以通过类似的“嵌入层”或预训练模型转换为向量表示,这是实现多模态大模型的基础。例如,OpenAI的CLIP模型就成功地将文本和图像嵌入到同一个向量空间。在更广泛的人工智能应用场景中,嵌入是实现数据“可计算”的关键第一步。
位置编码(Positional Encoding)
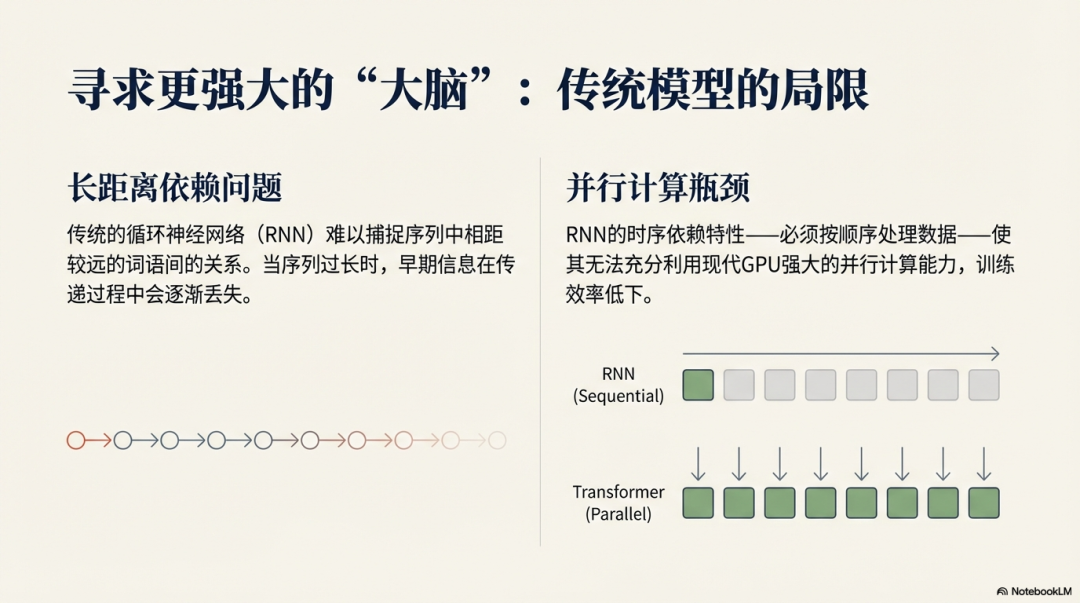
Transformer的并行处理能力使其无法像RNN那样天然感知序列顺序。位置编码的引入就是为了解决这个问题。它为序列中的每个位置生成一个唯一的、与词嵌入同维度的向量,然后与词嵌入向量相加,从而让模型知晓“狗咬人”和“人咬狗”的区别。
位置编码分为绝对位置编码和相对位置编码两大类,设计上需要能处理可变长度序列。添加了位置信息后,输入数据便可以送入注意力层进行计算。
注意力机制
编码器(Encoder)或解码器中的自注意力层是Transformer的“智慧”核心。它允许序列中的任意一个Token直接与所有其他Token进行交互,从而捕捉长距离依赖关系。
为什么需要注意力? 想象在预测下一个词时,模型需要知道当前上下文里哪些词是重要的参考。注意力机制就像是一个动态的、可学习的“聚焦”过程。
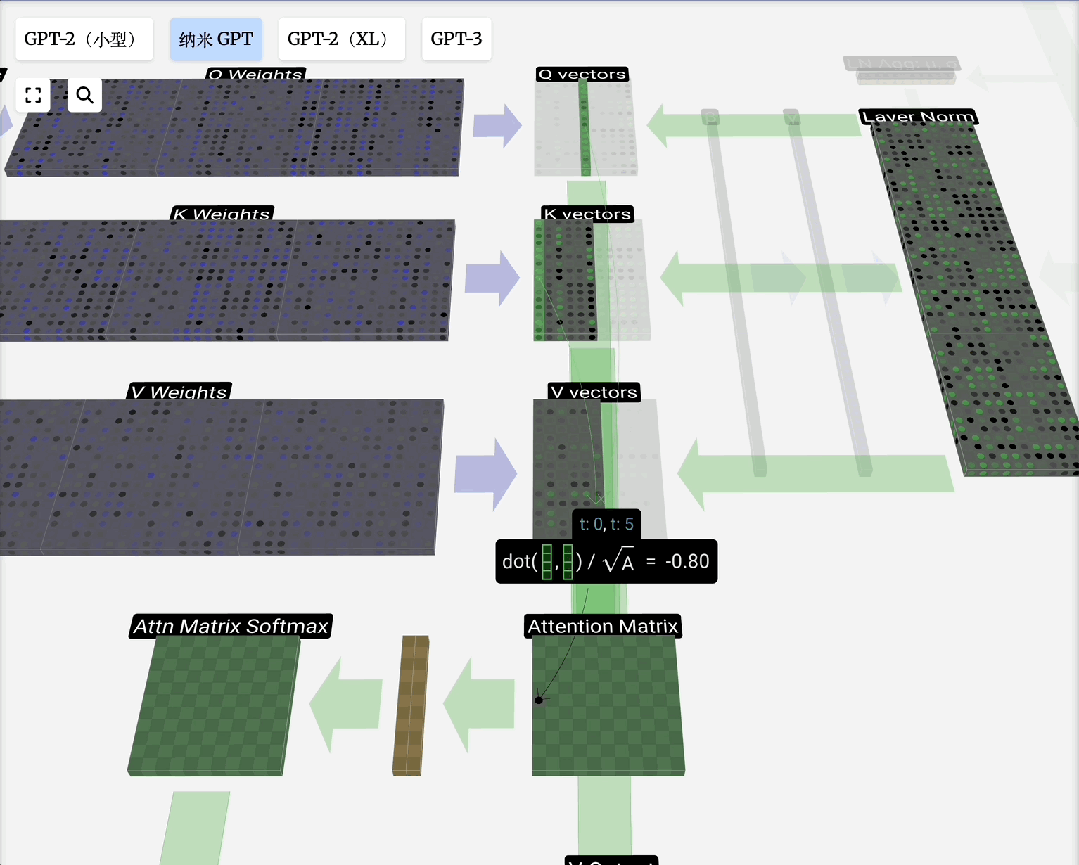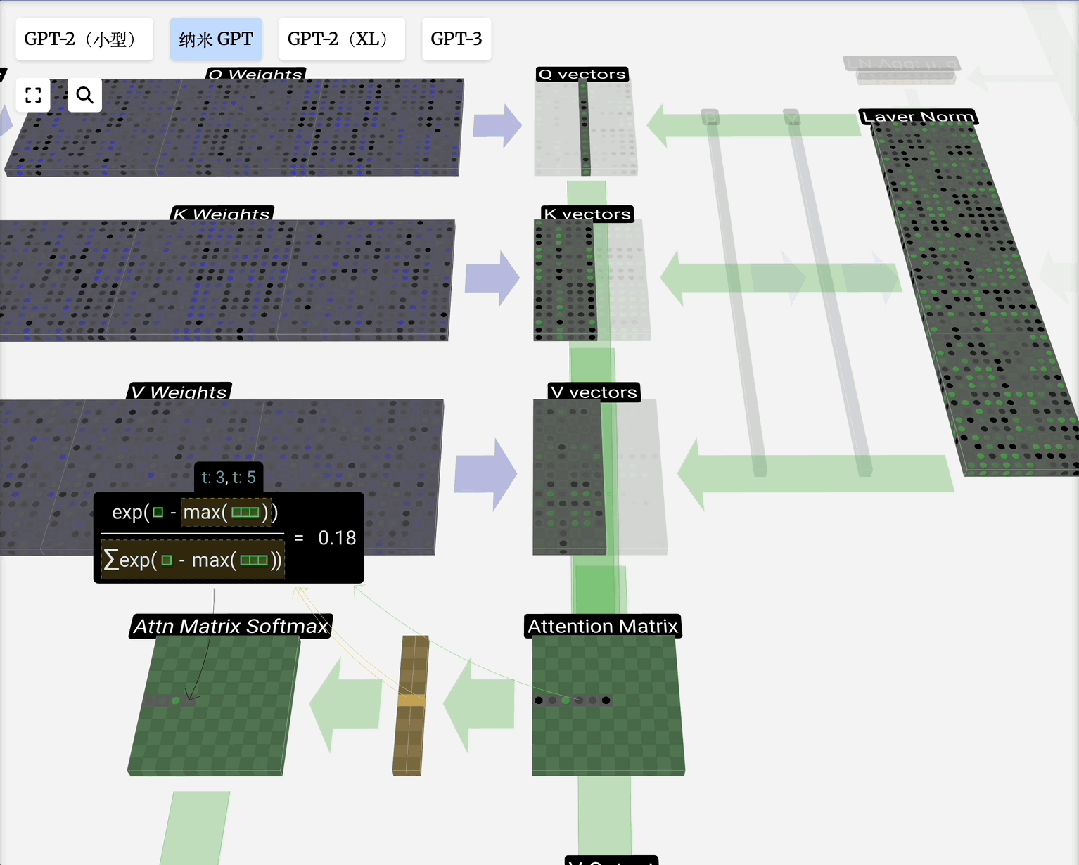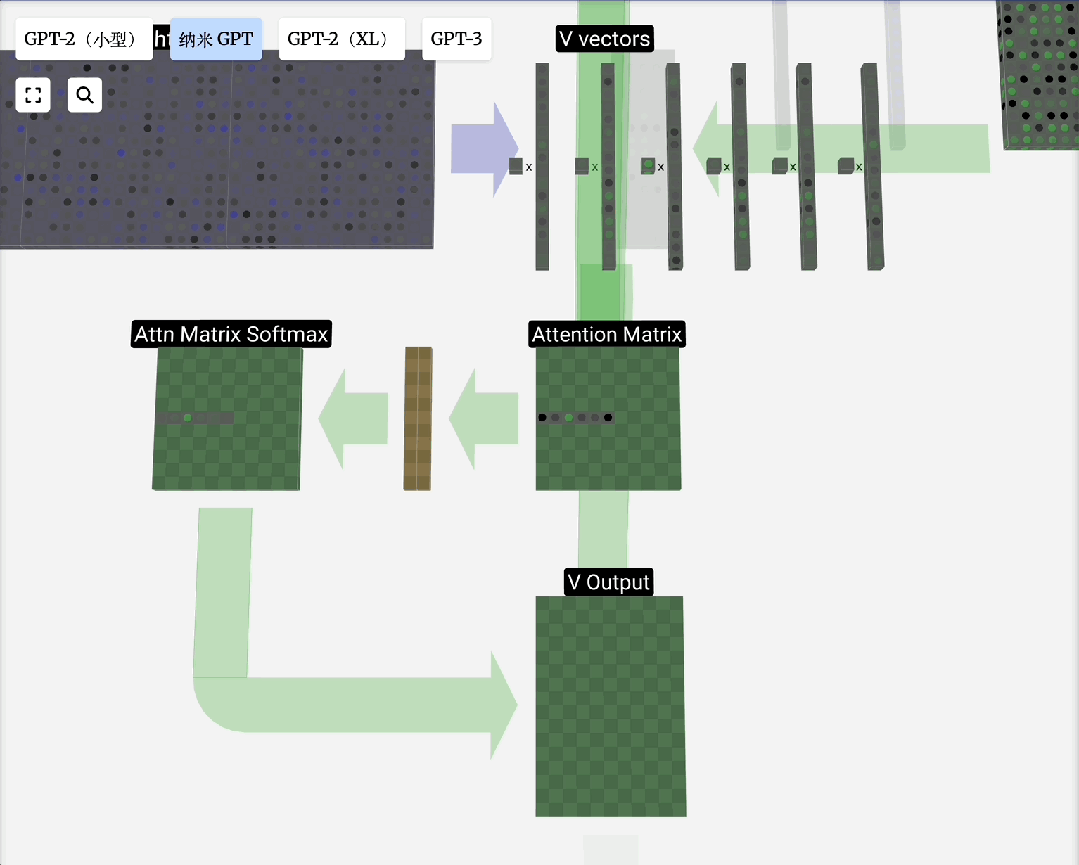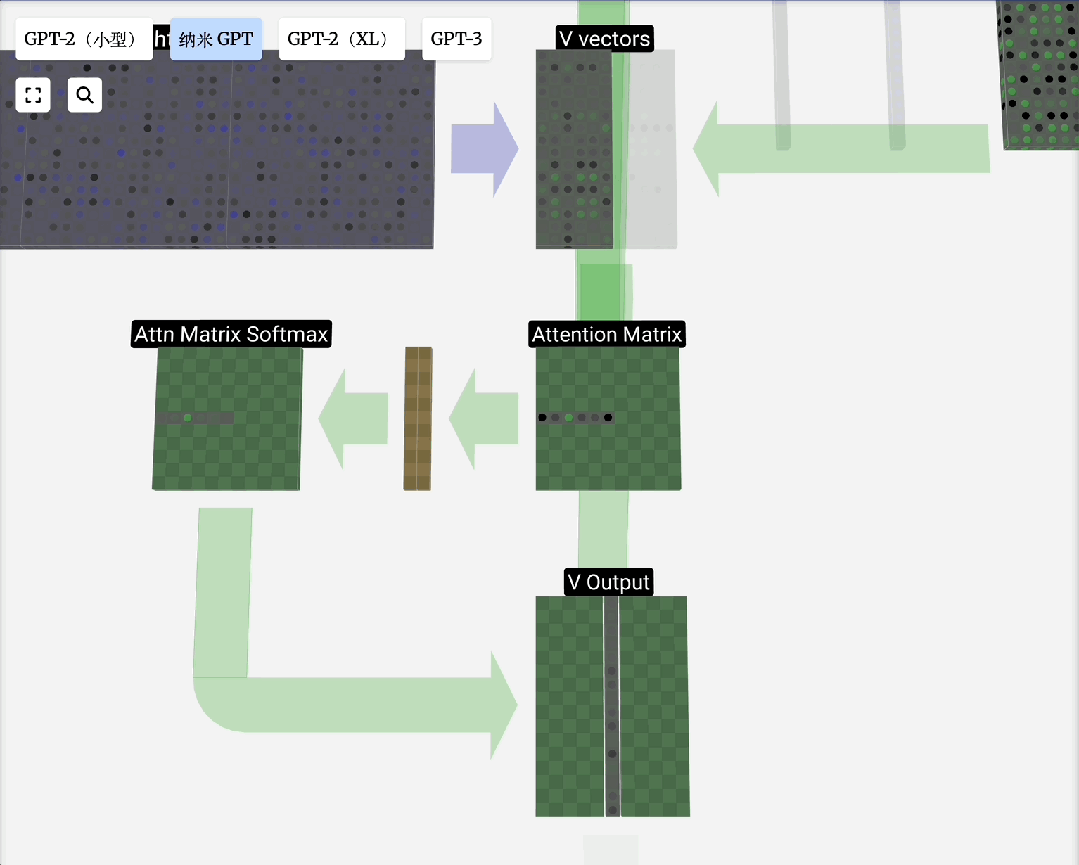
自注意力原理:对于输入序列中的每个元素,自注意力机制会计算一个上下文向量。该向量是序列中所有元素向量值的加权和,权重由当前元素与其他元素的相关性(通过点积计算并归一化)决定。
从RNN到自注意力:传统的RNN编码器需要将整个序列压缩成一个固定向量,容易丢失长程信息。而Transformer的自注意力机制允许解码器(或编码器自身)平等地访问序列中所有位置的信息,并通过权重分配来区分重要性。
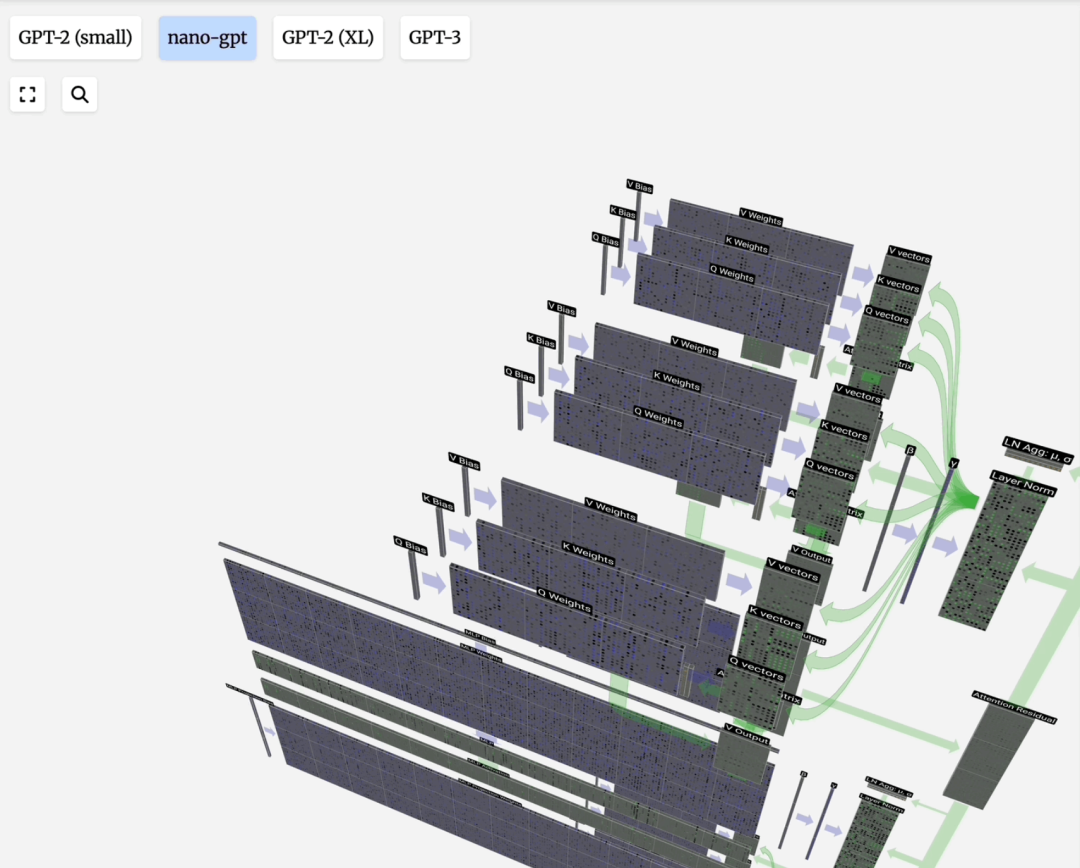
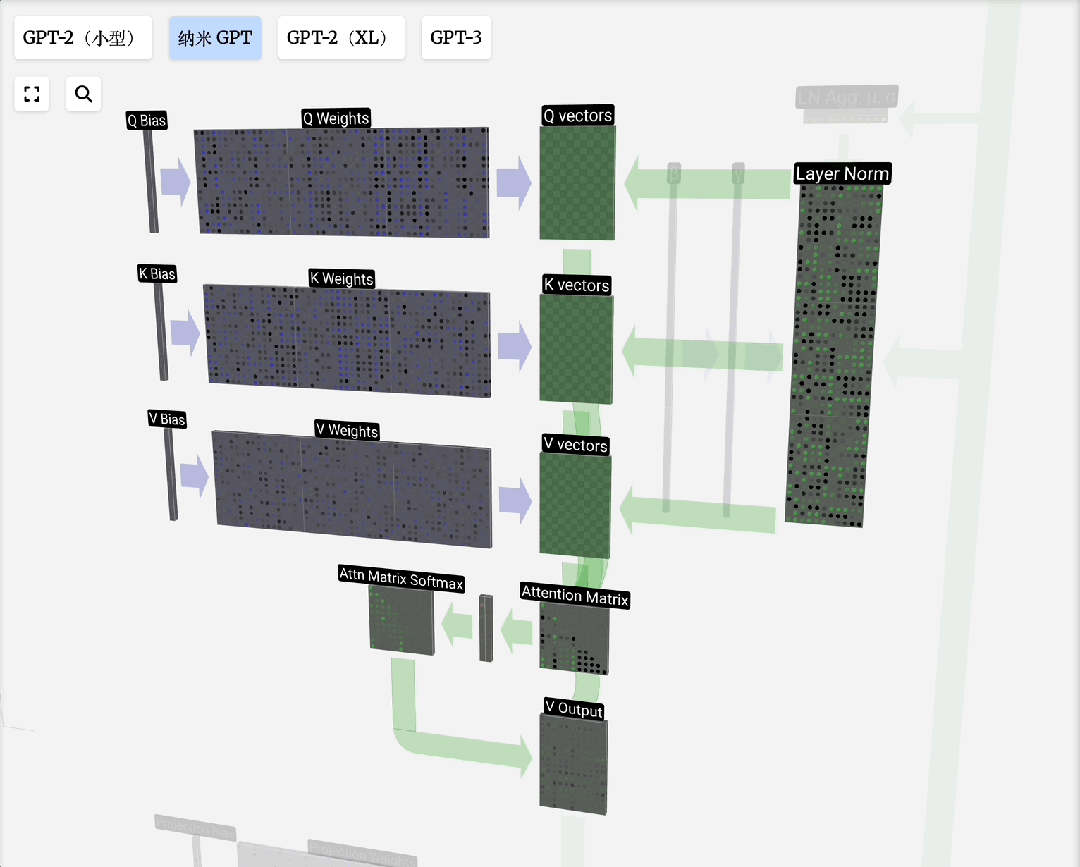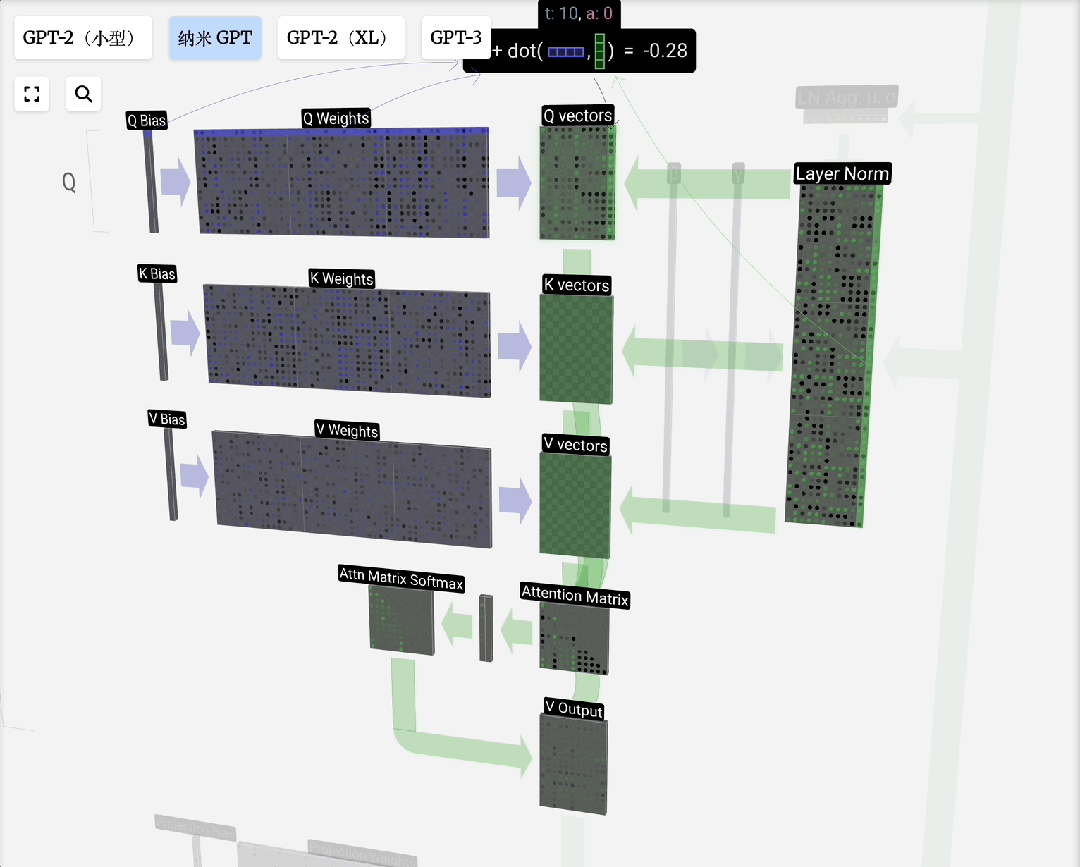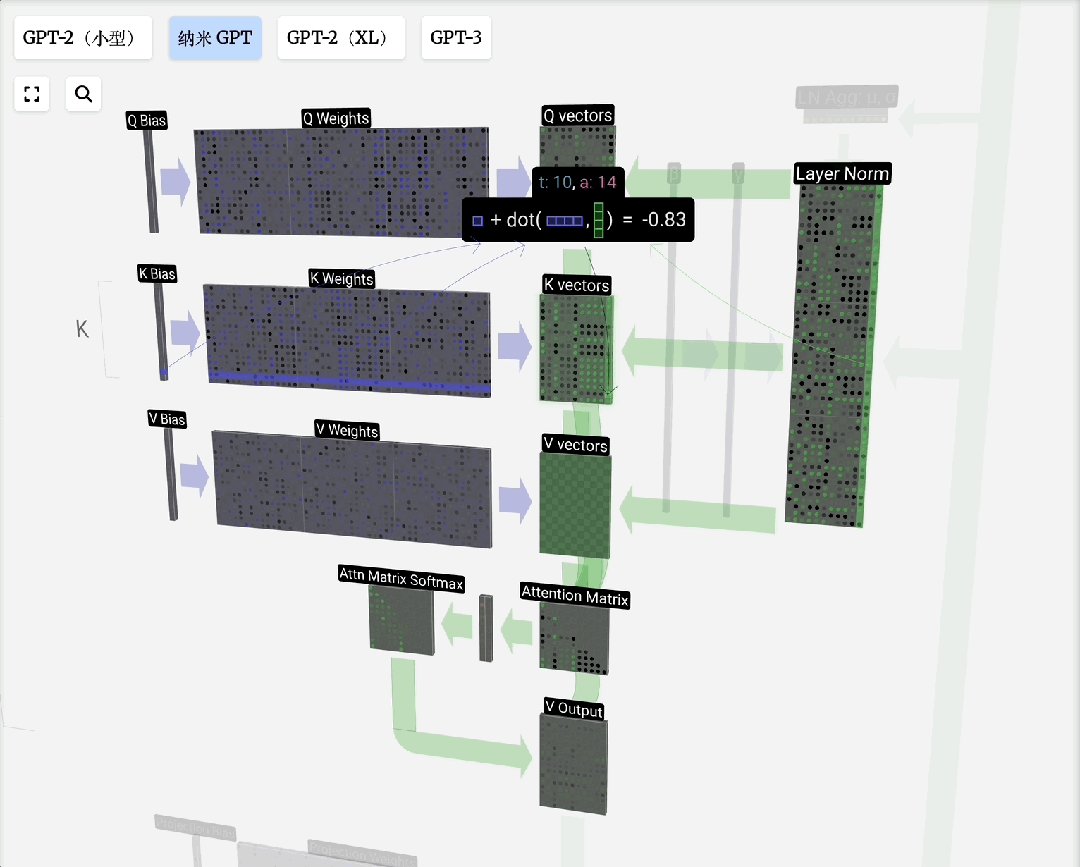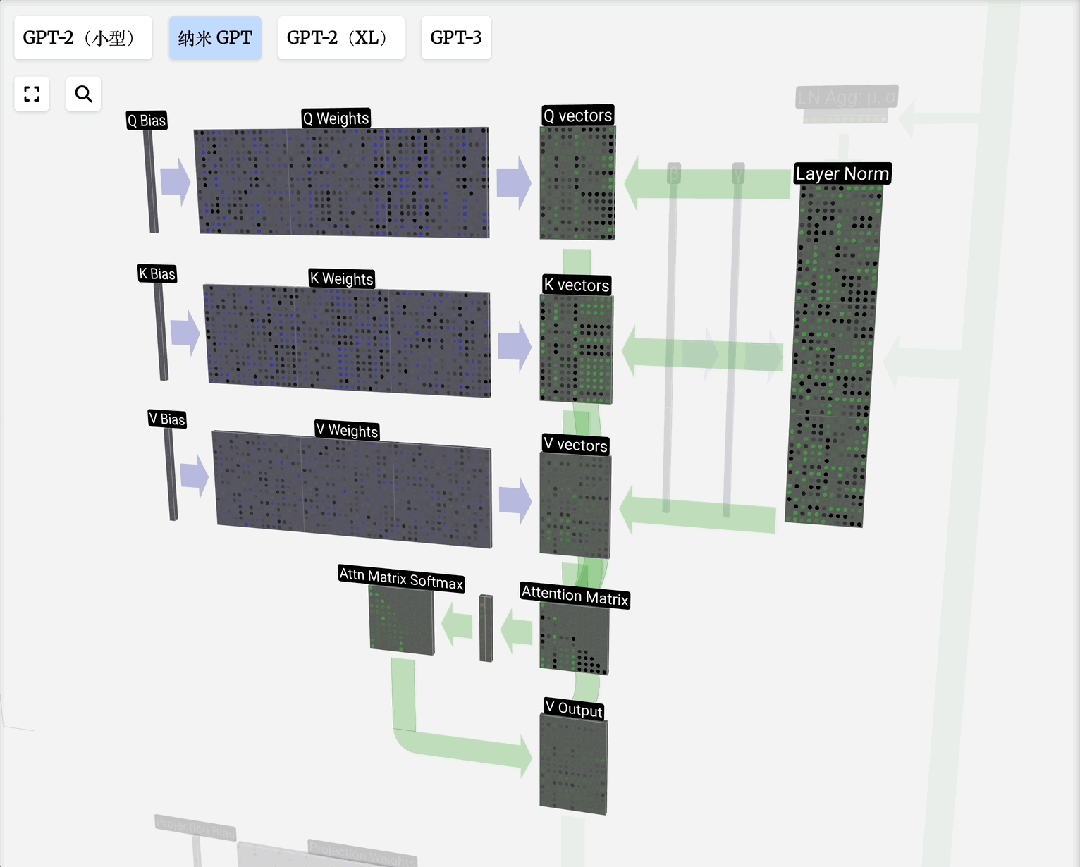
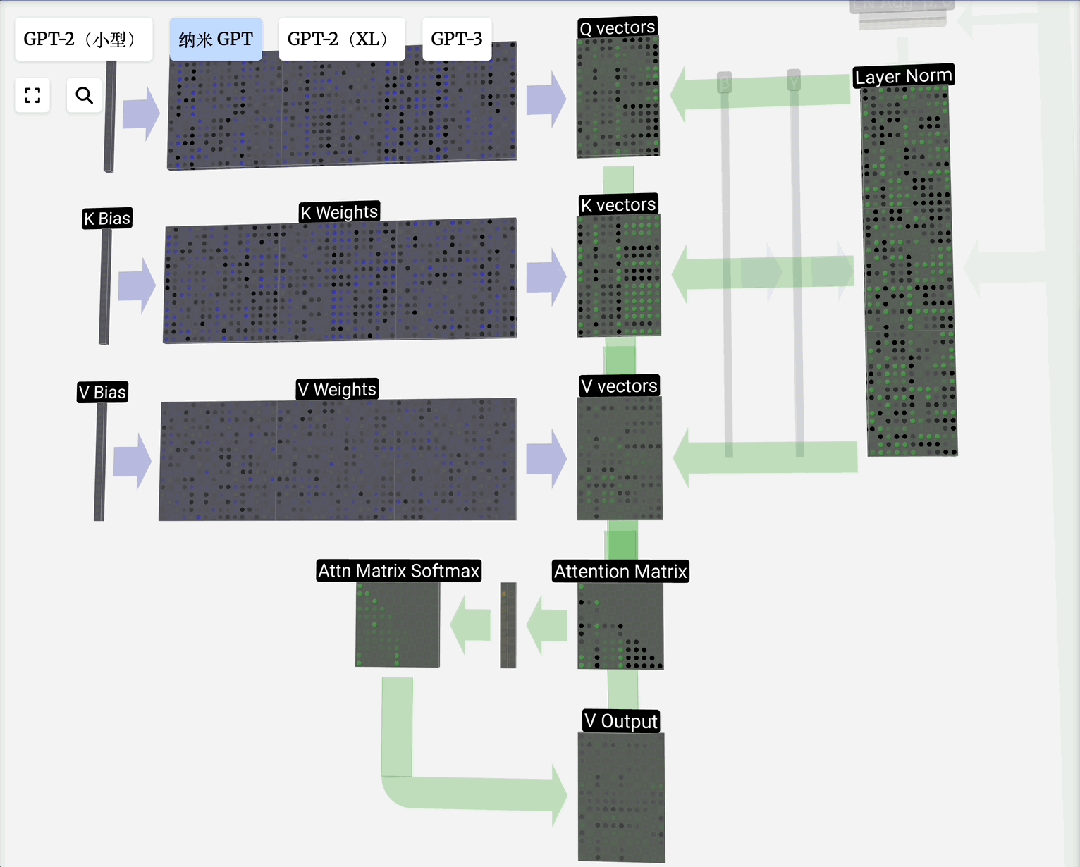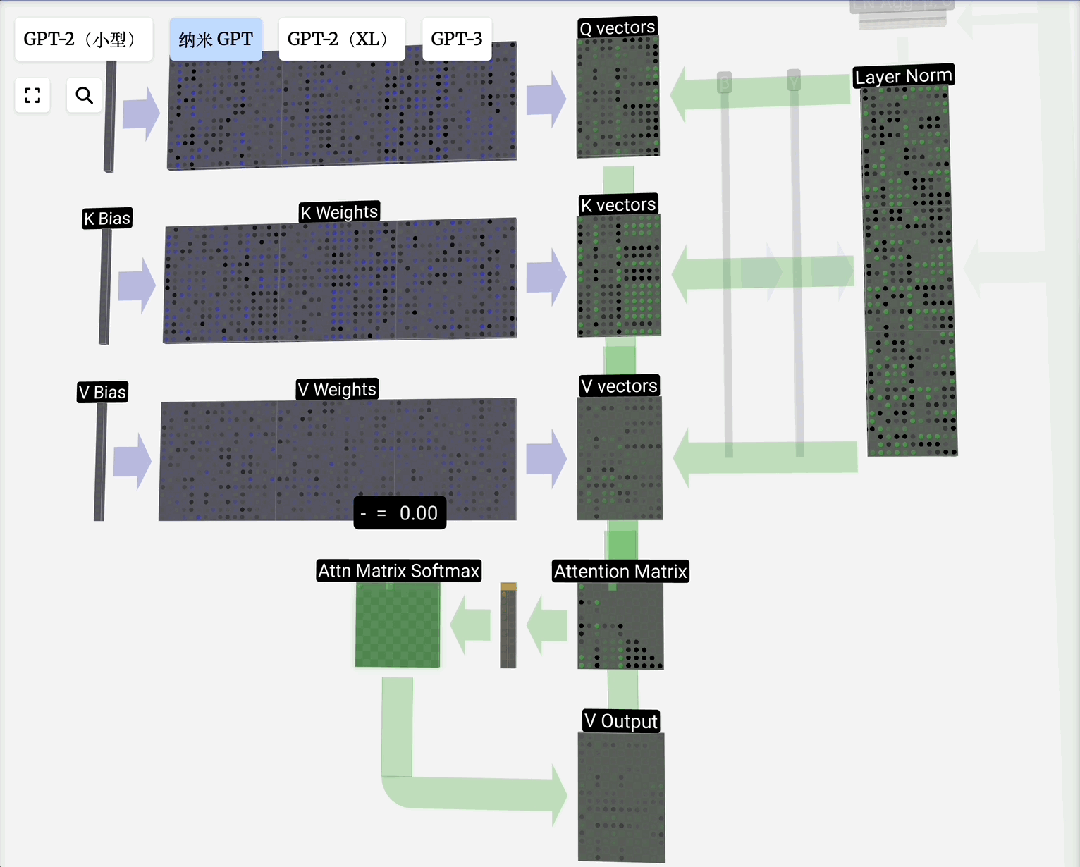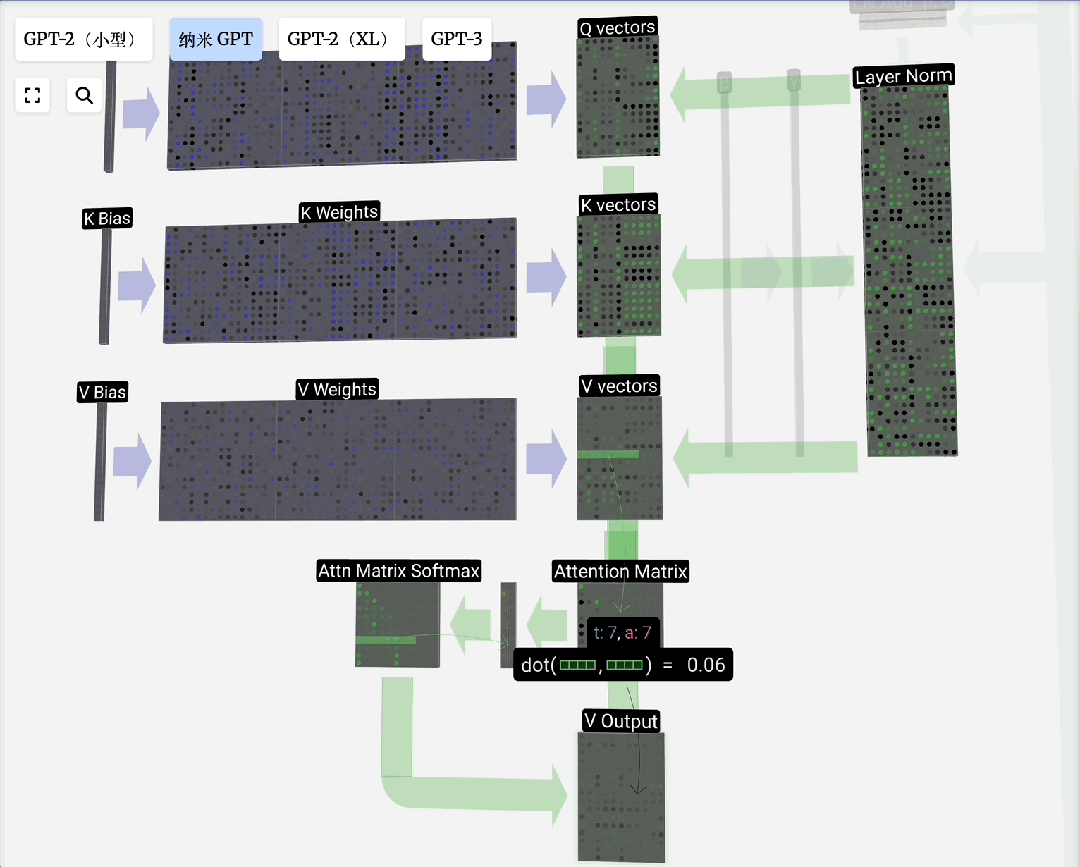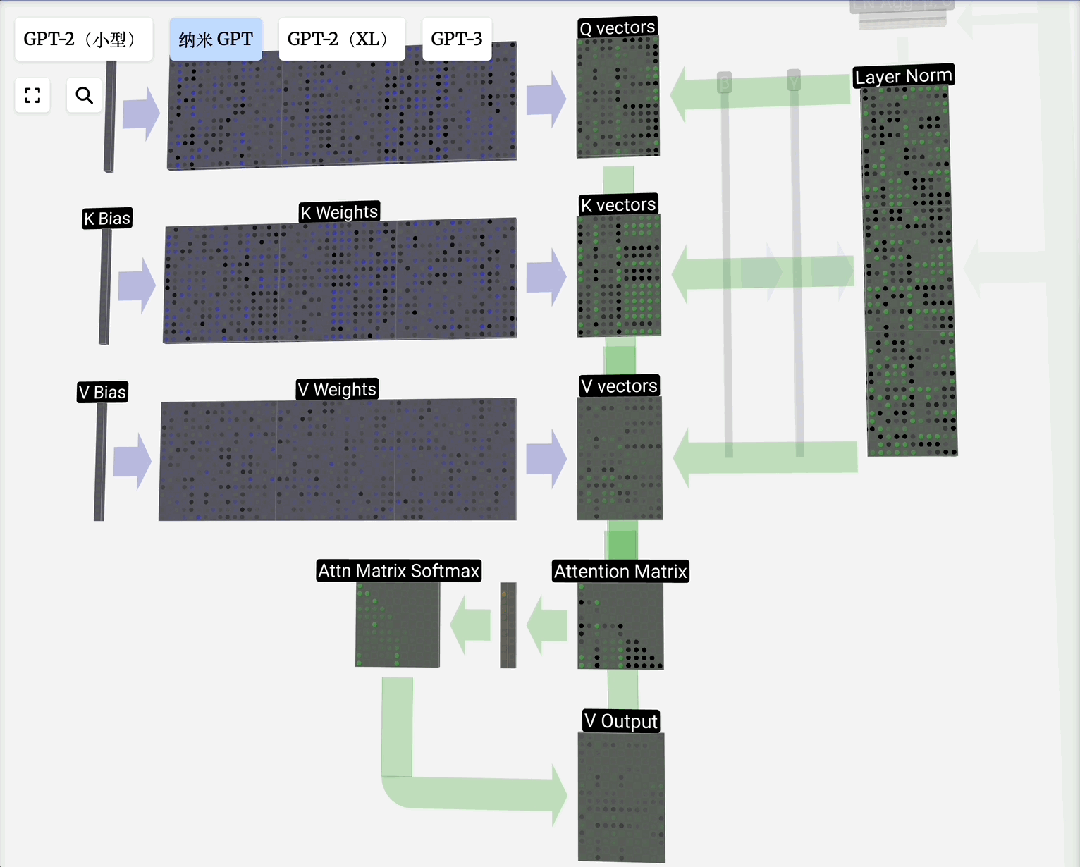
缩放点积注意力:这是自注意力的标准形式。“点积”用于计算相关性;“缩放”(除以向量维度的平方根)是为了防止点积结果过大导致Softmax梯度消失;“归一化”(Softmax)则是为了得到和为1的注意力权重。
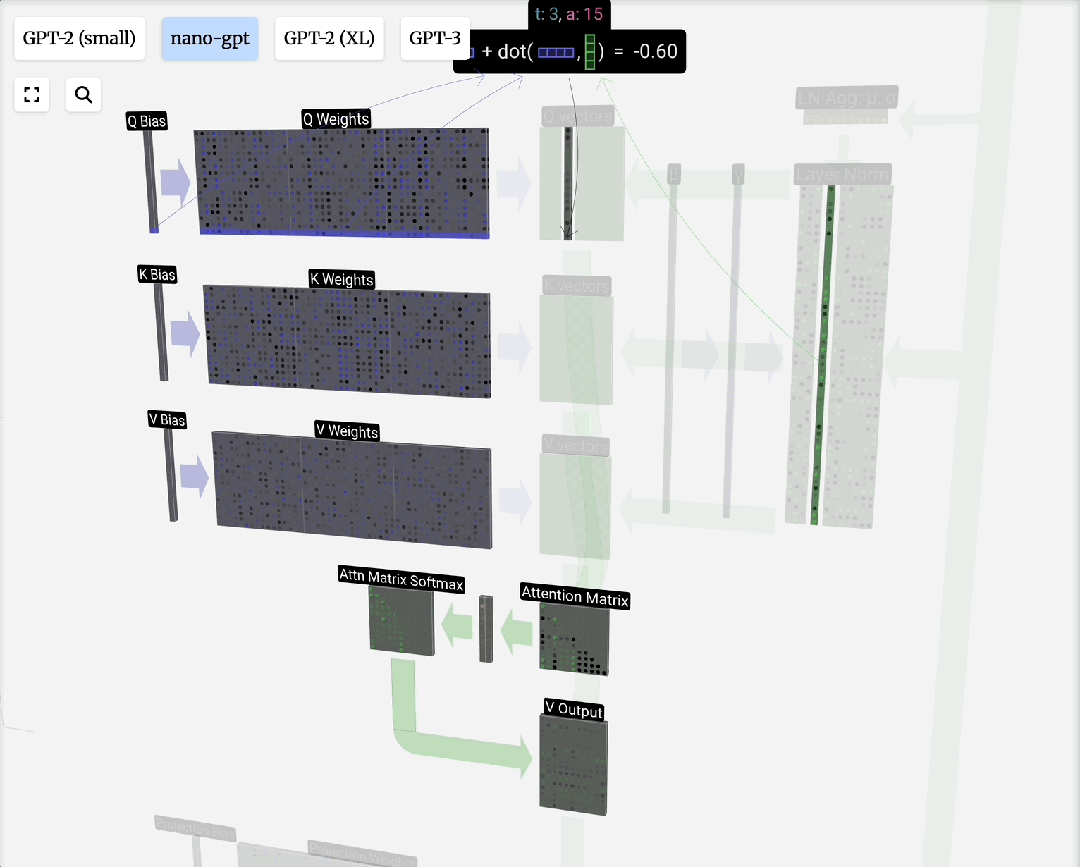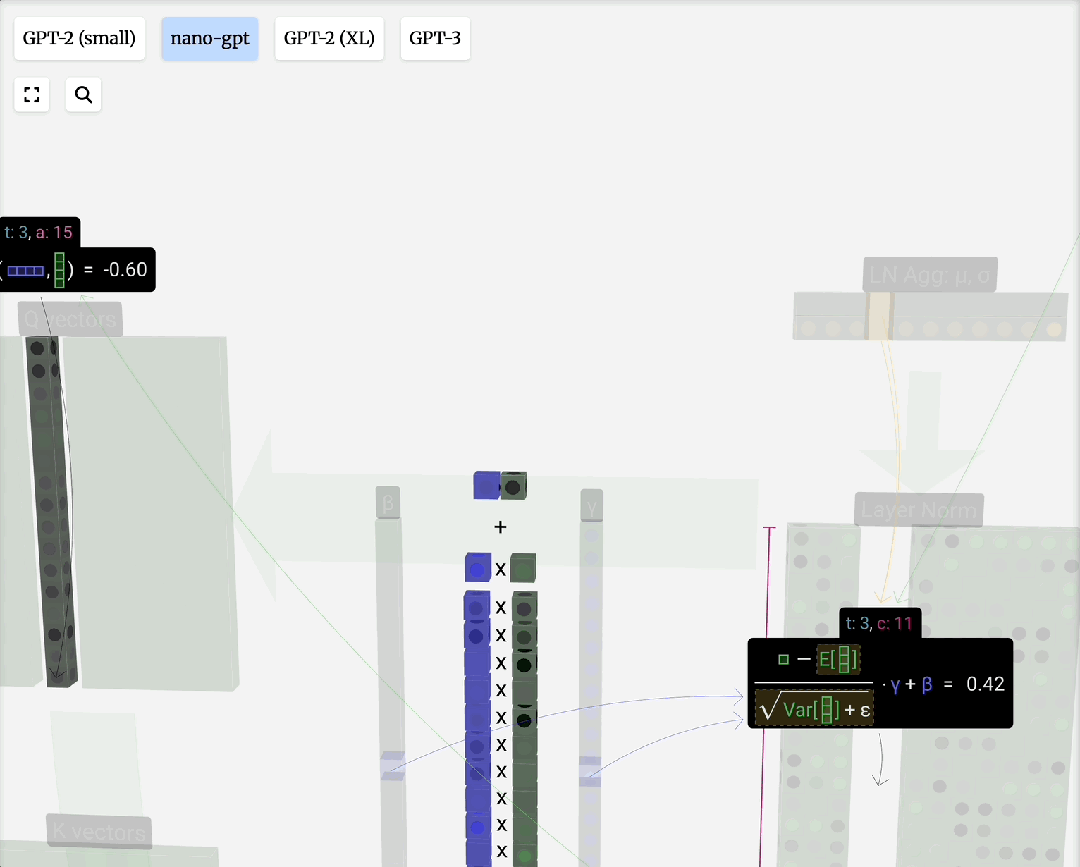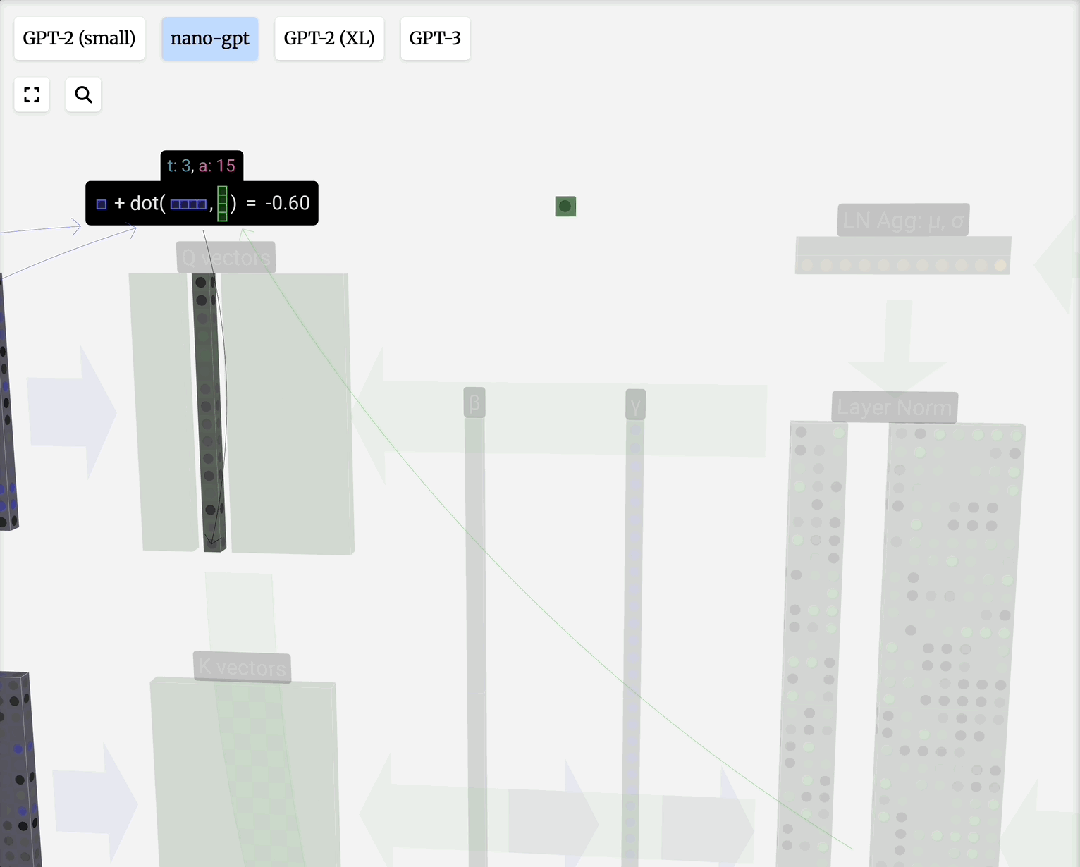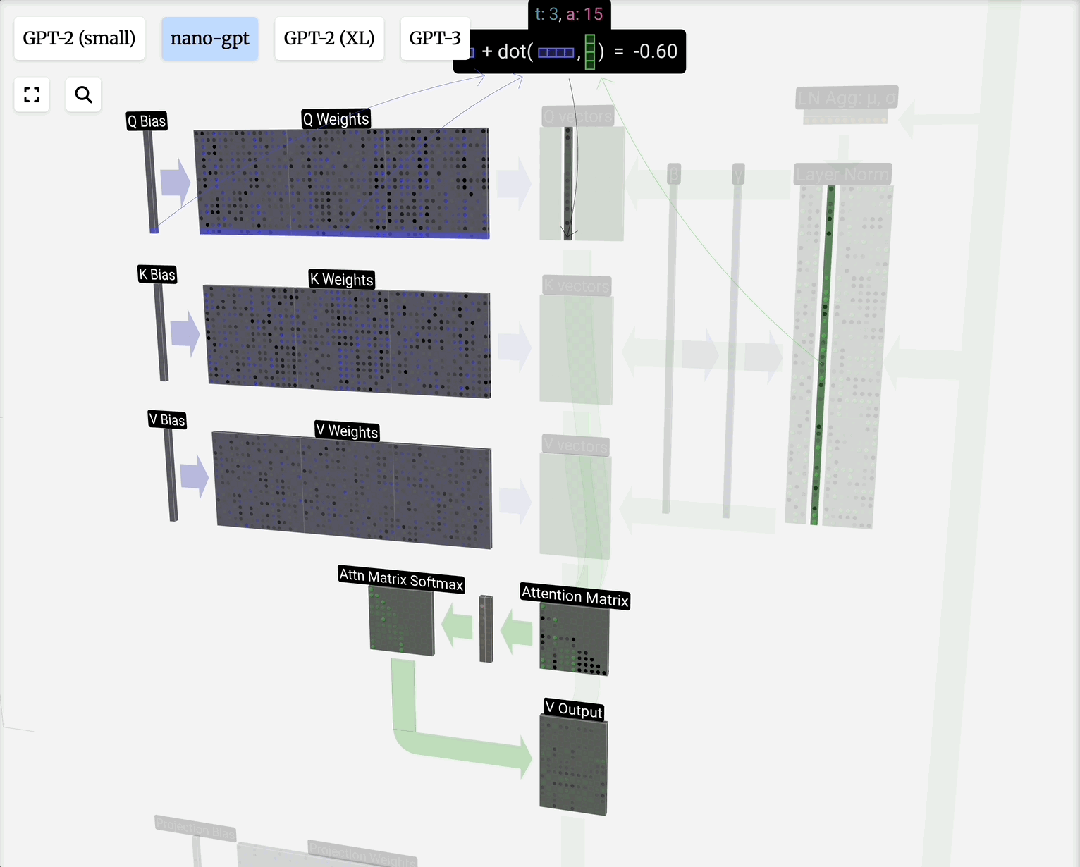
Q, K, V的由来:这个概念借鉴自信息检索。模型为每个输入Token生成三组向量:
- 查询(Query):当前Token发出的“询问”。
- 键(Key):每个Token的“标识”,用于匹配查询。
- 值(Value):每个Token的“实际内容”。
注意力过程即:用Q去匹配所有K,得到权重,然后用权重对V进行加权求和,得到输出。引入可训练的权重矩阵W_q, W_k, W_v来生成Q, K, V,使得模型能够从数据中学习如何更好地计算注意力。
因果注意力:在语言生成任务中,解码器必须避免“看到未来信息”。因果注意力(或掩码注意力)通过遮盖当前Token之后的所有位置来实现这一点,确保预测只能基于已生成的历史序列。
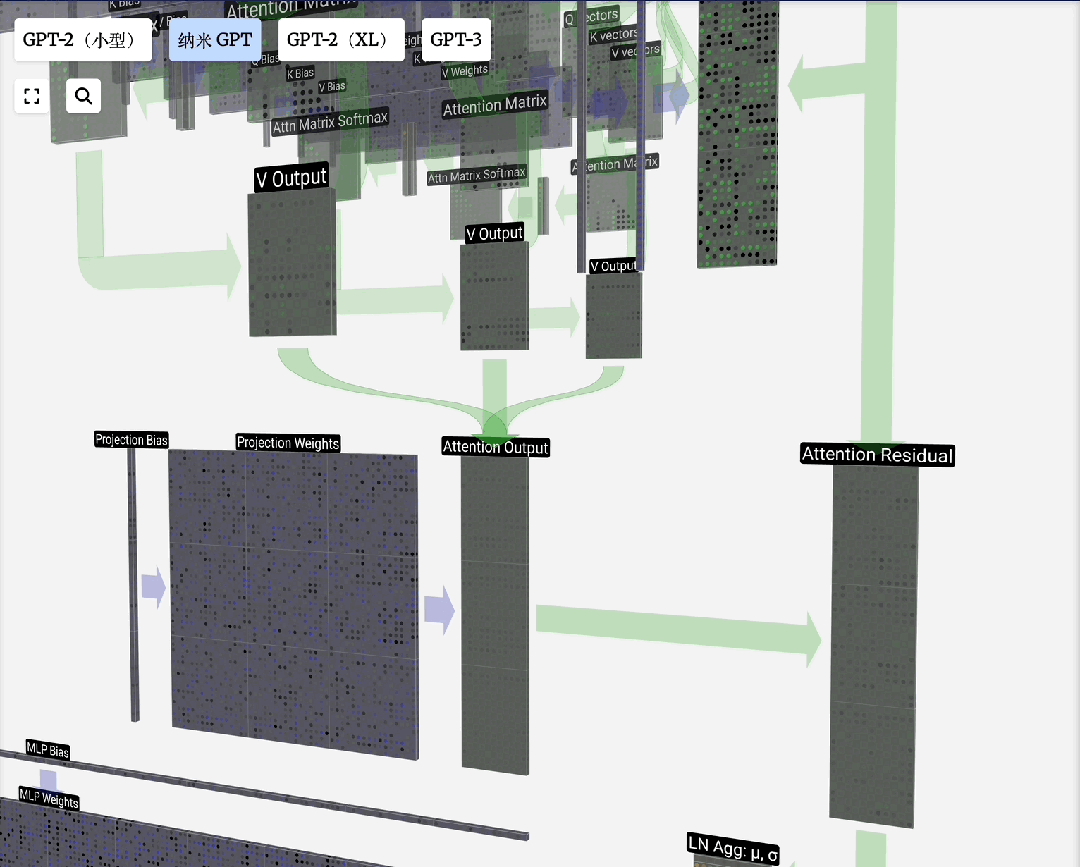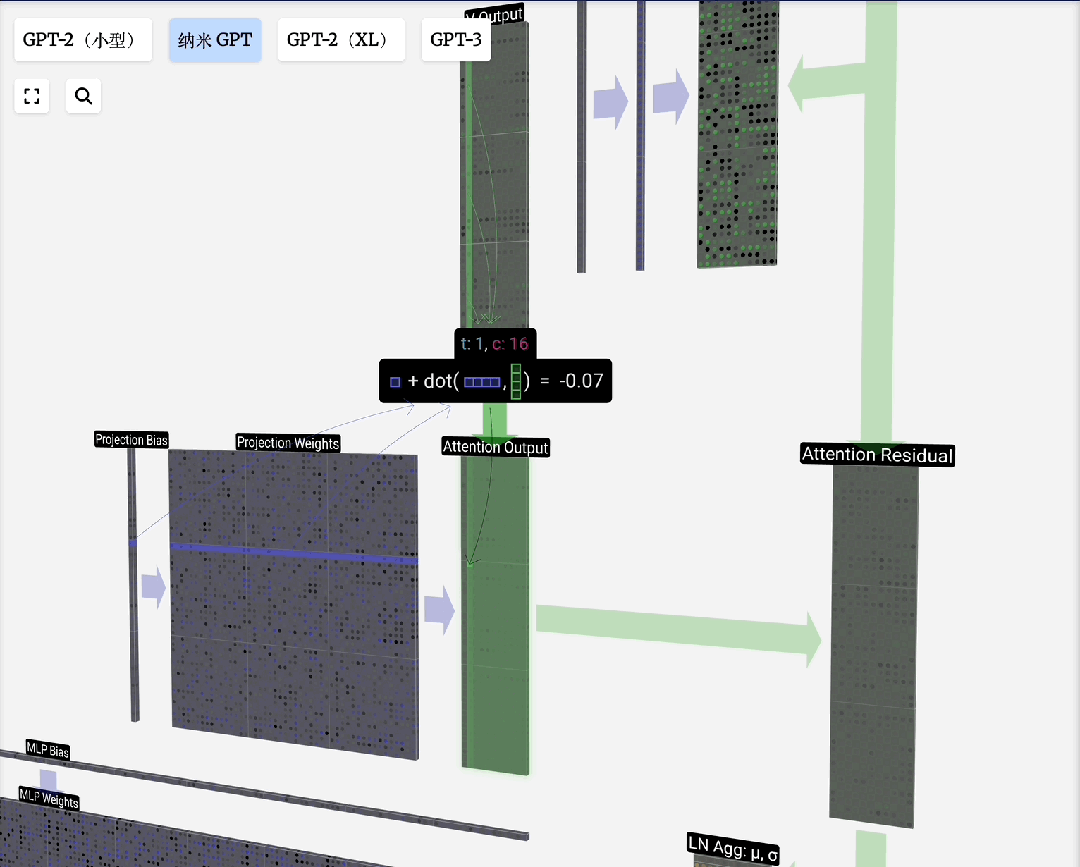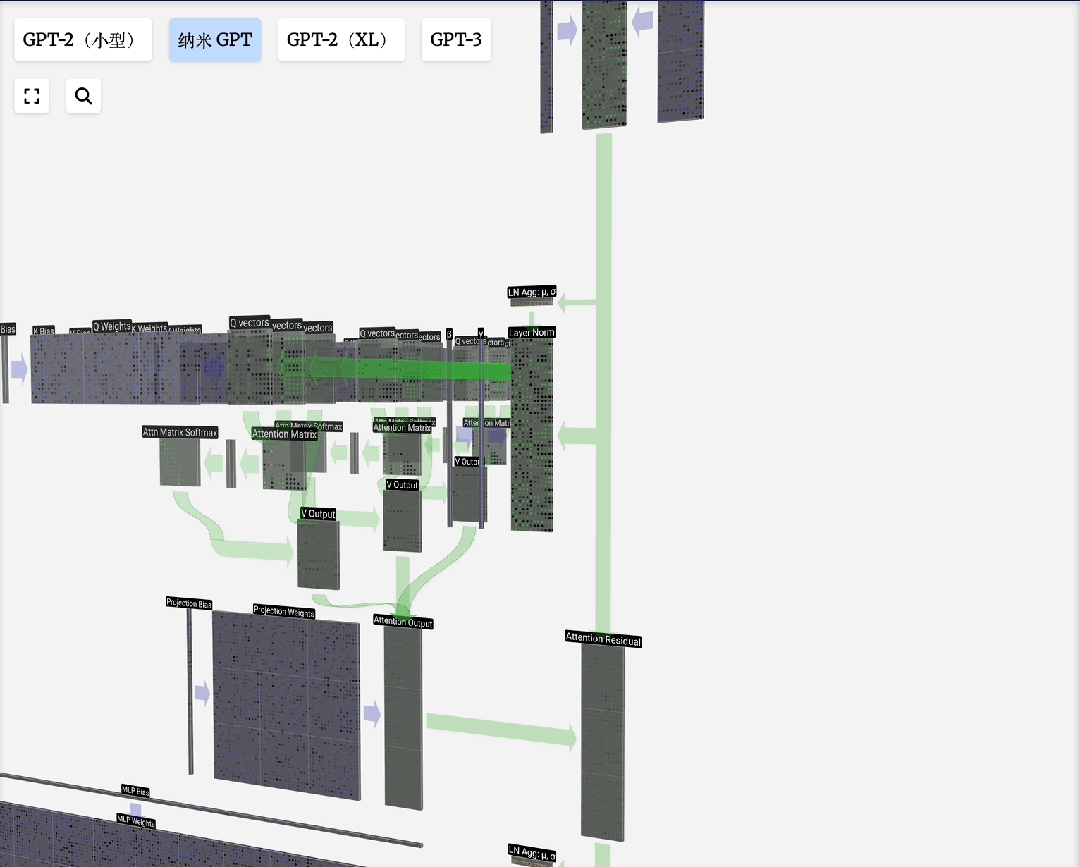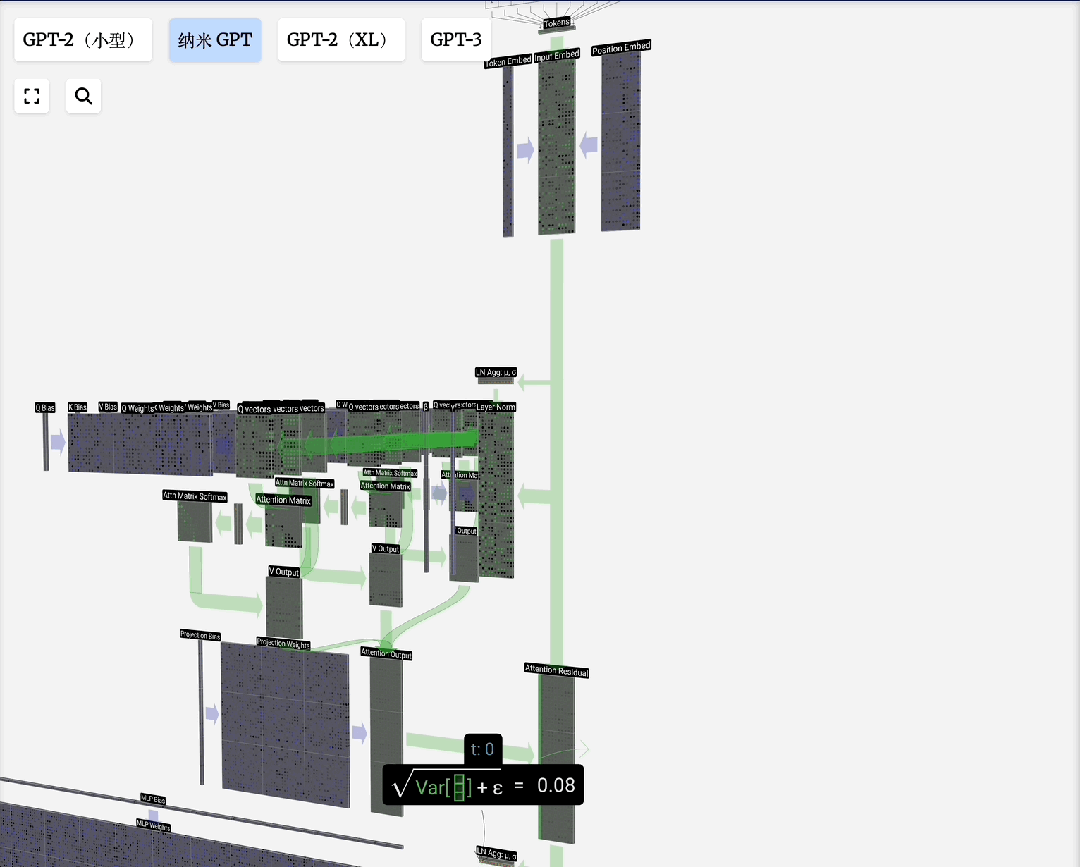
多头注意力:单一注意力机制可能只关注一种模式。多头注意力并行运行多个独立的注意力“头”,每个头可以学习关注不同方面的信息(例如,一个头关注语法,另一个头关注语义),最后将结果合并,使模型具有更强大的表示能力。
下图展示了一个注意力头数为3的计算过程分解:
FFN/MLP(前馈神经网络)
在注意力层之后,Transformer层通常包含一个前馈神经网络(FFN),也称为多层感知机(MLP)。它是一个简单的全连接网络,通常包含两个线性变换和一个非线性激活函数(如GELU)。
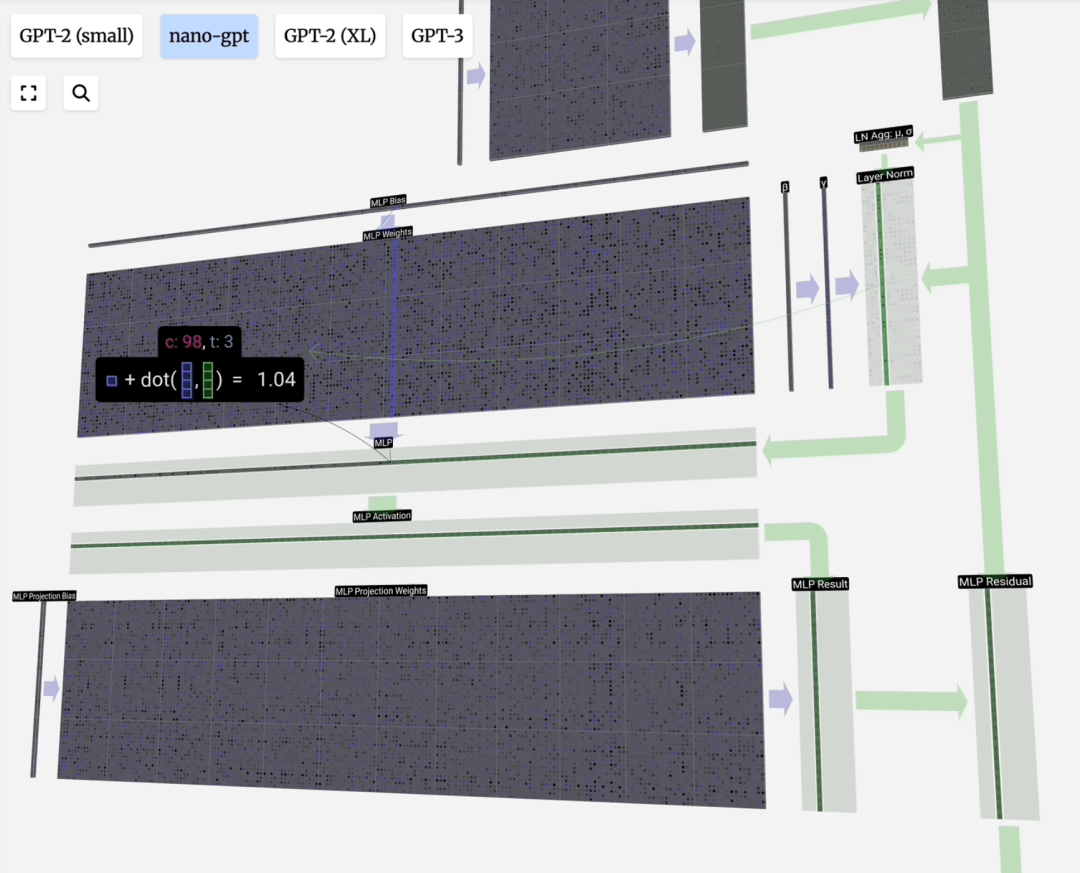
FFN的作用是对注意力层的输出进行进一步的非线性变换和特征提取,增强模型的表达能力。计算过程通常为:FFN(x) = W_2 · GELU(W_1 · x + b_1) + b_2。
一个完整的Transformer模型由多个上述的层(注意力+FFN)堆叠而成。深层网络可以学习更抽象、更复杂的特征。较低层可能学习语法和局部依赖,较高层则可能捕捉更高级的语义和全局关系。
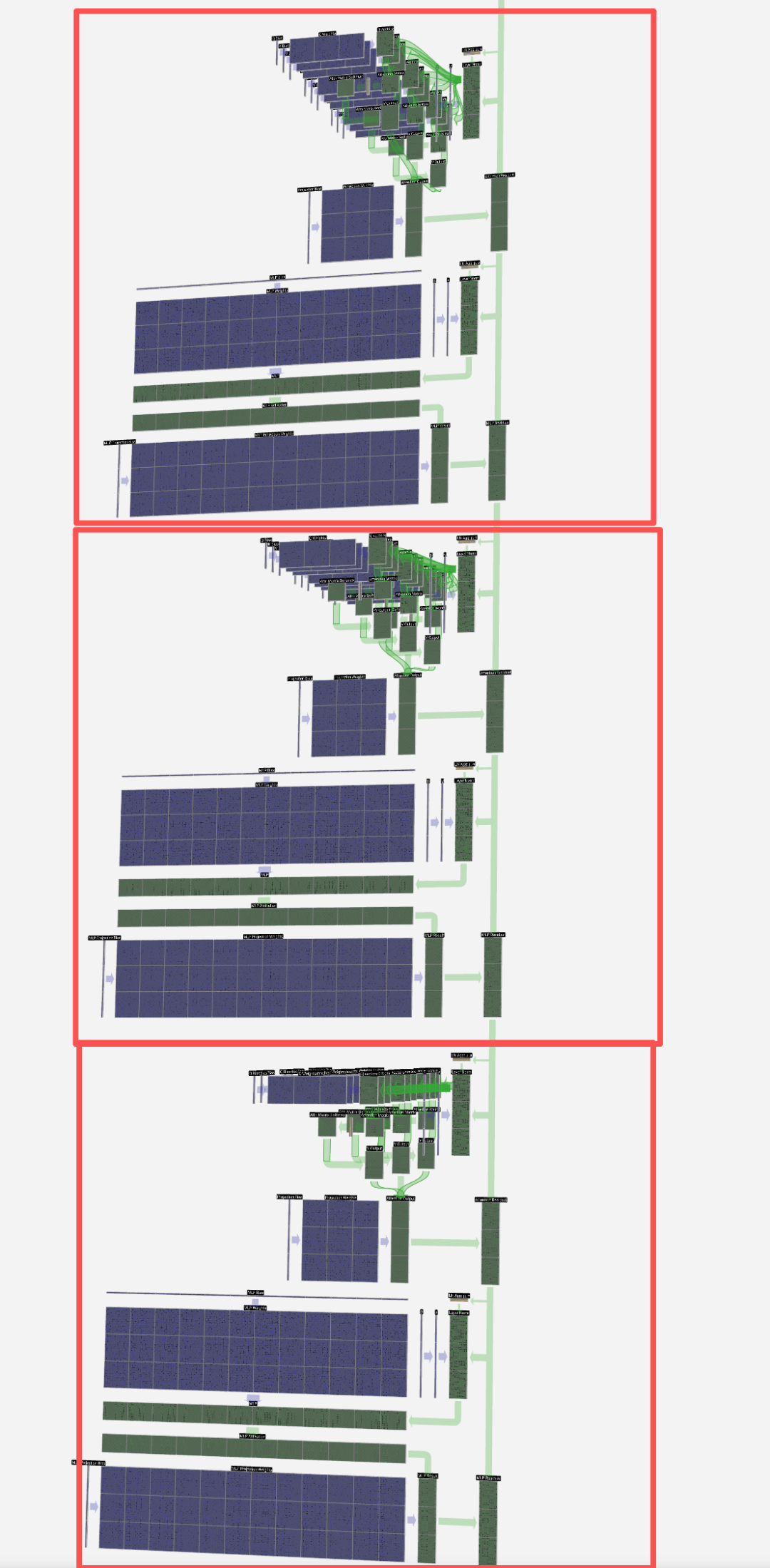
每一层处理完毕后,数据会传递到下一层,经过层层抽象,最终由输出层映射为词汇表上的概率分布,从而预测出下一个Token。
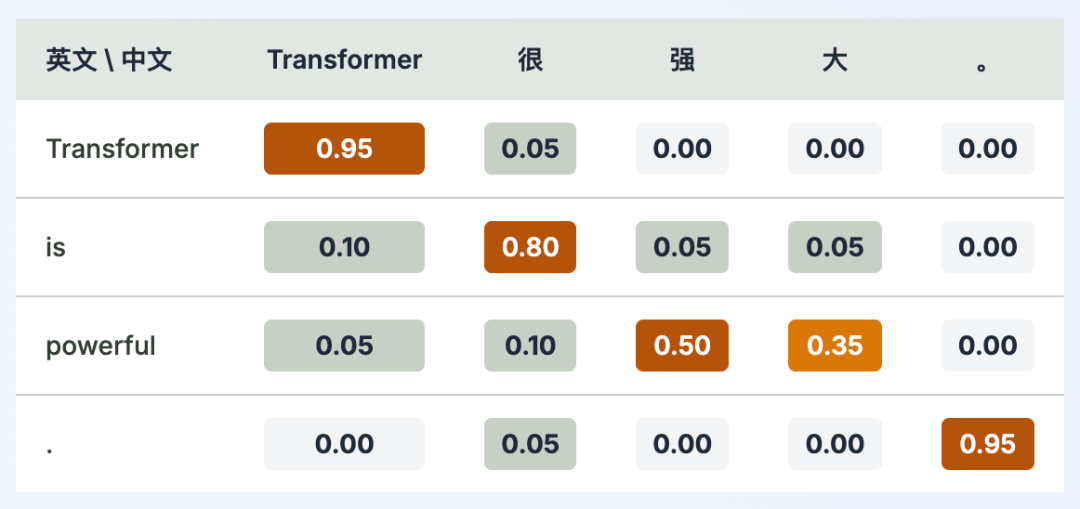
案例讲解:逐步生成翻译
现在,让我们模拟解码器自回归地生成“Transformer很强大。”的全过程:
- 输入:
<START>。模型结合编码器输出,预测第一个词为“Transformer”。
- 输入:
<START> Transformer。模型处理已生成部分,并通过注意力关注源句,决定将“is”译为程度副词“很”。
- 输入:
<START> Transformer 很。模型注意力高度集中于“powerful”,并开始翻译,首先生成“强”。
- 输入:
<START> Transformer 很 强。模型继续处理,完成“强大”的翻译,生成“大”。
- 输入:
<START> Transformer 很 强 大。模型识别句子结束,生成中文句号“。”。
整个过程可以通过注意力权重热图可视化,清晰展示源语言与目标语言词之间的对齐关系。
当前开源旗舰LLM架构
进入2025年,开源大模型生态蓬勃发展,版本迭代与架构创新速度惊人。
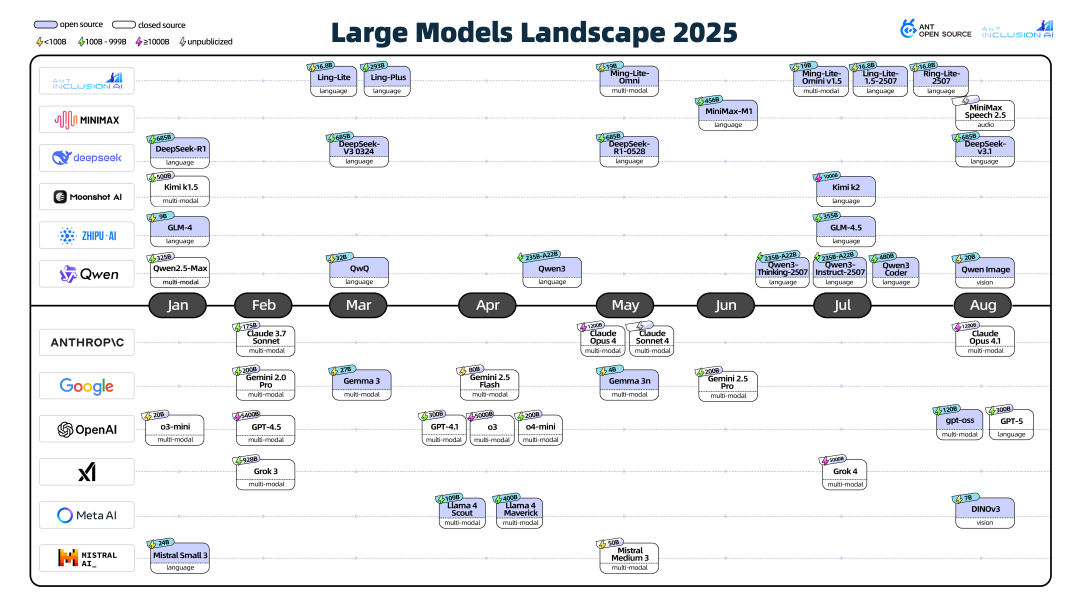
尽管创新不断,当前顶尖的LLM架构主体仍是基于Decoder-only Transformer进行优化。主要的演进体现在以下几个方面:

1. 混合专家(MoE)架构的普及
为了在控制计算成本的前提下扩展模型参数,MoE架构被广泛应用。如DeepSeek-V3,它用一组专家(如256个)替代传统的FFN,每次推理只激活少数几个(如9个),实现了“参数大而计算量小”的效果。
2. 注意力机制的优化
为了提升长上下文处理效率并降低KV缓存开销,出现了如分组查询注意力(GQA)、滑动窗口注意力等变体。DeepSeek-R1则采用了多头潜在注意力(MLA),将KV投影到低维空间缓存,节省内存。
3. 归一化等细节调整
如OLMo 2采用的QK-Norm(在注意力计算中对Q和K进行归一化),Gemma 3结合Pre-Norm和Post-Norm的尝试等,这些调整旨在稳定训练并提升模型性能。
4. 超越Transformer的探索
除了Transformer的自我革新,也有研究探索其他基础架构,如基于状态空间模型(SSM)的Mamba。一些模型(如腾讯混元)开始尝试 Transformer-Mamba混合架构,旨在结合二者的优势。
理解这些底层原理和架构演进,对于我们在实际中选择合适的模型、设计高效的AI应用系统至关重要。无论是进行Python编程实现模型训练,还是构建基于向量检索的RAG应用,扎实的理论基础都能帮助我们做出更优的决策。
总结
纷繁复杂的LLM应用形态(如提示工程、RAG、Agent框架)其本质常常是为了弥补模型当前能力的不足。随着模型本身能力的飞速进化,一些应用模式可能会简化甚至改变。
因此,模型能力是根本,应用形态是上层建筑。深入理解Transformer等核心模型的原理,知其长短优劣,才能更好地驾驭AI技术,洞悉其未来发展方向。当我们掌握了从注意力机制到MoE混合架构的设计精髓,便能在快速迭代的人工智能浪潮中,更从容地构建面向未来的智能应用。
 发表于 2025-12-3 23:45:39
|
查看: 191|
回复: 0
发表于 2025-12-3 23:45:39
|
查看: 191|
回复: 0
